流程控制
一.垃圾回收机制
什么是垃圾回收机制
垃圾回收机制是python自带的一种机制,专门回收没有绑定变量名的垃圾数据,用来释放内存空间
策略一:引用计数
引用计数就是:变量名和数据值关联的次数
age = 18 #数据值18的引用计数为1
引用计数增加:
x = age #数据值18的引用计数为2
'把age的内存地址给了x,此时age和x都绑定了18 所以18的引用计数为2'
引用计数减少:
age = 20 #数据值18的引用计数变成1
'变量名age与数据值18解除绑定,再与20绑定,所以数据值18的引用计数从2变成了1'
del x #数据值18的引用计数变成0
'解除变量名m的绑定关系,所以数据值18没有变量名绑定,引用计数就从1变成了0'
【引用计数】:当数据值身上的引用计数为0,就会被垃圾回收机制回收。 不为0则不会被回收
缺陷:引用计数可能会造成循环引用问题
策略二:标记清除
标记清除策略主要是针对引用计数中循环引用问题而出的策略
循环引用:
l1=[1,2,3] #l1列表的引用计数为1
l2=[4,5,6] #l2列表的引用计数为2
l1.append(l2) #在l1列表后追加l2的数据,l2列表的引用计数变为2
l2.append(l1) #在l2列表后追加l1的数据, l1列表的引用计数变为2
del l1 #解除l1变量名与l1列表的绑定关系,l1列表的引用计数变为1
del l2 #解除l2变量名与l2列表的绑定关系,l2列表的引用计数变为1
'此时l1列表与l2列表身上的引用计数不为0且没有变量名绑定,则会一直占用内存空间!'
【标记清除】:当内存占用达到某个临界值时,将内存中所有数据值检查一遍,对存在循环引用的数据打上标记,之后一次性清除
缺陷:每隔一段时间会对所有数据进行检查然后统一清除,资源消耗过大且效率不高
策略三:分代回收
为了减轻标记清除带来的资源消耗过大问题出了分代回收策略
【分代回收】:分代回收一般分为三代:新生代、青春代、老年代。 对新定义变量的值放在新生代中,假设每隔5分钟检查一次,当多次检查发现该值仍在引用则把该值放到下一层青春代中。青春代的扫描频率低于新生代。老年代同理
可以把分代回收比喻成学校老师检查,差学生老师每5分钟看一眼有没有在开小差;中等生老师每隔10分钟看一眼;好学生老师每隔20分钟看一眼。
此时也反应出一个缺点:假如数据值刚转移到老年代就被解除绑定关系,那需要等好久才能检查到该数据值没被绑定,所以回收会有延迟
二.流程控制
流程控制:就是控制事物的执行流程。
事物的执行流程:
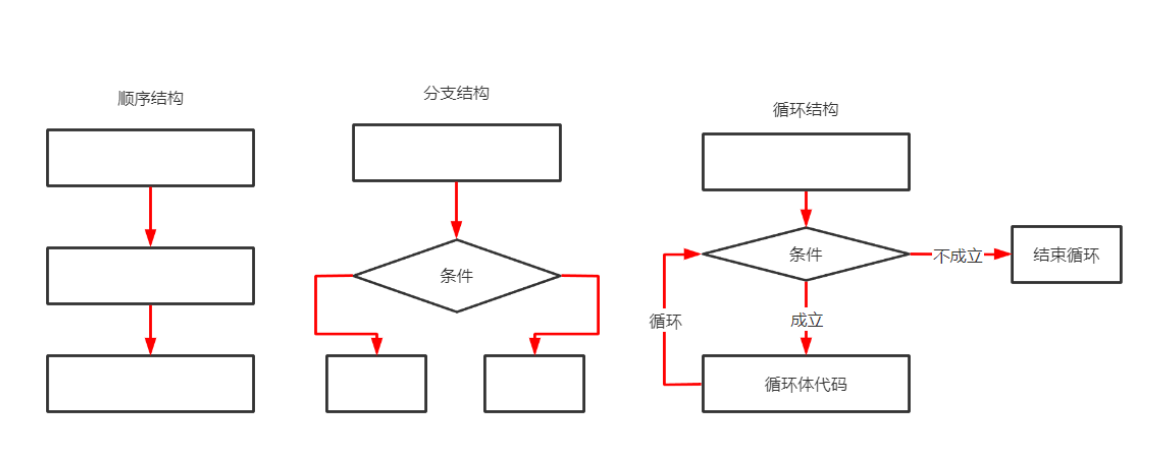
1.顺序结构
#从上到下依次执行代码
2.分支结构
#根据条件的不同执行不同代码
3.循环结构
#根据条件的不同决定是否重复执行代码
流程控制必备知识
1.python中使用代码的缩进来表示代码从属关系缩进一般为4个空格。缩进的子代码是否执行取决于上面没缩进的父代码。
2.目前只有if 、elif 、 else关键字可以拥有子代码。
3.当某行代码需要子代码时,结尾需跟冒号。
4.同属于一个父代码的子代码们缩进量需一致。
5.相同缩进量的代码无主次之分,按照顺序结构依次执行。
1.分支结构
1.单if分支
if 条件:
条件成立后执行的子代码
练习:
如果:女人的年龄>30岁,打印“阿姨好”
age = int(input('输入女人年龄:'))
if age > 30:
print('阿姨好')
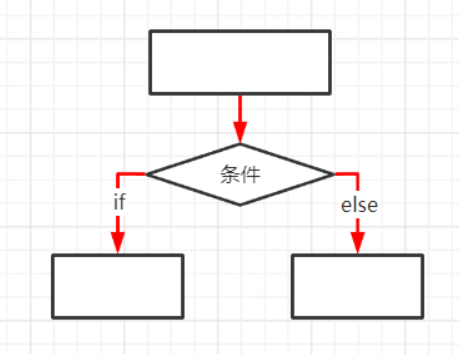
2.if..else分支
if 条件:
条件成立后执行的子代码
else:
条件不成立执行的子代码
练习:
如果:女人的年龄>30岁 打印“阿姨好”,否则打印“小姐姐好”
age = int(input('输入女人年龄:'))
if age > 30:
print('阿姨好')
else:
print('小姐姐好')
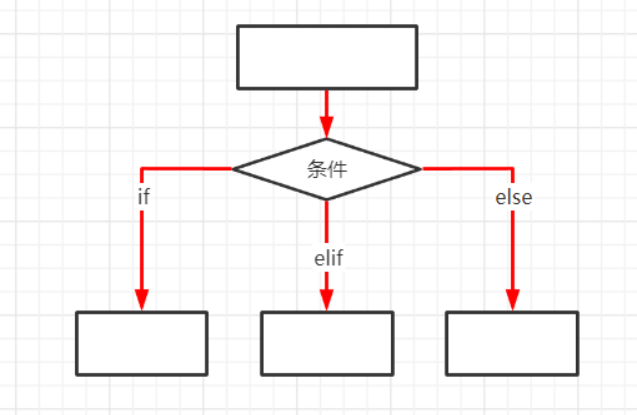
3.if..elif..else分支
if 条件1:
条件1成立后执行的子代码
elif 条件2:
条件1不成立,条件2成立后执行的子代码
else:
以上条件都不成立后执行的子代码
#三个一起使用时永远只会走一个分支
#elif可以写多个
#elif 和 else不能单独使用,必须结合if一起使用
练习:
如果:成绩>=90,那么:优秀
如果成绩>=80且<90,那么:良好
如果成绩>=70且<80,那么:普通
其他情况:很差
score = int(input('输入学生成绩>>:'))
if score >= 90:
print('优秀')
elif score >= 80:
print('良好')
elif score >= 70:
print('普通')
else:
print('很差')
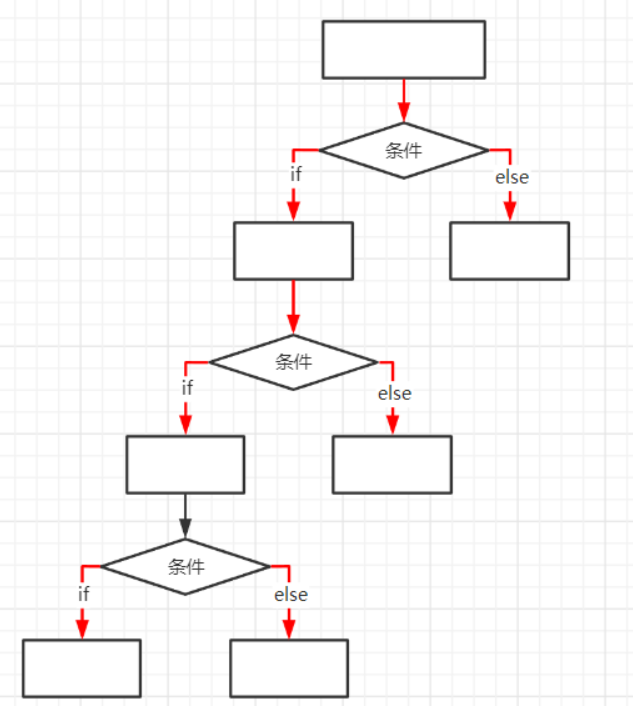
4.if的嵌套
if 条件1:
条件1成立执行的子代码
if 条件2:
条件2也成立后执行的子代码
if 条件3:
条件3也成立后执行的子代码
else:
条件3不成立执行的子代码
else:
条件2不成立执行的子代码
else:
条件1不成立执行的子代码
#if后可以继续跟if else可以最后再补但是需注意缩进量是否与父代码一致
练习:
如果:看到妹子上去要微信(可能成功,可能失败),成功后邀请妹子看电影(可能成功,可能失败),成功后邀请妹子回家看猫翻跟头(可能成功,可能失败)
is_wechat = input('是否要到微信(y/n):')
is_movie = input('是否约到看电影(y/n):')
is_home = input('是否约到回家看猫翻跟头(y/n):')
if is_wechat == 'y':
print('成功要到微信')
if is_movie == 'y':
print('成功约到看电影')
if is_home == 'y':
print('成功约到回家看猫翻跟头')
else:
print('没约到回家看猫翻跟头')
else:
print('没约到看电影')
else:
print('没要到微信')
2.循环结构
1.while循环
while 条件:
条件成立后执行的循环体代码
'''
1.先判断条件是否成立,成立则执行循环体代码
2.循环体代码执行完会再回到条件判断处判断是否成立
3.成立则继续执行循环体代码
4.直到条件不成立才会结束循环
'''
#循环打印“你好”
while True:
print('你好')
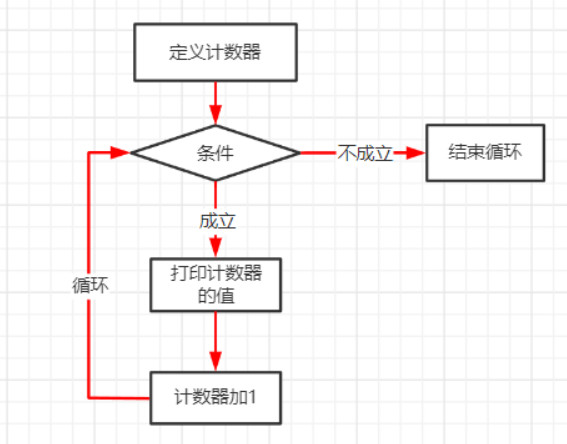
结束循环体的两种方式
1.利用计数器固定循环次数
#循环打印5次“你好”
count = 1
while count < 6:
print('你好')
count += 1
2.在循环体内部添加关键字强制结束
⛅while + break的使用
强制结束循环体代码
#循环打印1-10,打印到5结束打印
count = 1 #定义计数器
while count < 11: #循环打印次数为10
print(count) #打印计数器
count += 1 #计数器自增1
if count == 6: #当计数器等于6时
break #强制结束循环
#结果为:1 2 3 4 5
⛅while + continue的使用
当执行到continue时结束本次循环,并回到循环体条件判断处开始下一次循环
#循环打印1-5,到3跳过并继续打印
count = 1 #定义计数器
while count < 6: #循环打印次数为5
print(count) #打印计数器
count += 1 #计数器自增1
if count == 3: #当计数器=3时
count += 1 #计数器自增1
continue #结束本次循环开始下一次循环
#结果为:1 2 4 5
⛅while + else的使用
循环体代码没有被break强制结束,循环体代码全部执行完就会执行else子代码
count = 1
while count < 6:
print(count)
count += 1
else:
print('循环体代码全部执行完且没有被break!则执行else')
#结果为: 1 2 3 4 5 循环体代码全部执行完且没有被break!则执行else
死循环
死循环就是让程序无限执行某个代码文件,此时CPU使用率会持续上升直到满负荷重启。代码中不允许出现死循环
count = 10
while True:
count *= 100 # 计算机会循环执行*=100的结果值
循环的嵌套及全局标志位
当遇到while循环嵌套时需注意:
🔸1.一个break只能结束当前所在的那一层循环
🔸2.想一次性结束所有循环,有几个while循环嵌套就需要写几个break,注意break的位置在哪里(一般和下一个while平行,但互相没有主次之分)
当while循环嵌套较多时可以使用全局标志位:
while True:
print(111)
while True:
print(222)
while True:
print(333)
#以上循环嵌套当我想结束所有while循环时需要给各个while循环内加break结束所有循环,这样做效率太低且当循环体代码较多时加break时易分不清加在哪里!
is_flag = True
while is_flag:
print(111)
while is_flag:
print(222)
while is_flag:
print(333)
is_flag = False
#只需要添加一个全局标志位,且在最内层把该标志位的True改为False即可实现结束内外所有循环。
2.for循环
一般for循环可以实现的代码,while循环也可以做到。区别在于for循环取值(遍历)时要比while更方便!
for 变量名 in 待遍历的数据:
循环体代码
'''
从待遍历的数据中中取出一个值给变量名,从上到下执行循环体代码,然后再回到for开头取出第二的值...直到值取完
'''
1)while与for循环对比
循环打印列表中的数据值
l1 = [1,2,3,4]
#while
count = 0
while count < 4:
print(l1[count])
count += 1
'while需数出来列表中有几个数据值 然后定义计数器 循环条件小于数据值的数量 用列表索引取值每循环一次索引值自增1'
'当列表中数据值较多时while使用会非常不方便!'
#for
for i in l1:
print(i)
'for循环的变量名i会从给到他的数据值中从左到右依次赋值循环,直到没有数据值可给时自动结束(不需要给结束条件)。'
2)for循环的另一种用法
for i in 1,2,3:
print('z')
#结果为:打印了三行‘z’
由此可以得出 待遍历的数据可以有多个,相当于循环次数(如果是列表,则列表中有多少数据值循环多少次)
如果打印的是变量名,结果就是待遍历的数据值
如果打印的是其他数据值,结果就是循环打印几次该数据值
3)for循环支持遍历 [ 取值 ] 的数据类型
常见的有 字符串、列表、字典、元组、集合
遍历字符串时打印出来的是单个字符 且空格也算一个字符。
遍历字典时只有K键参与,V值默认不暴露
4)for结束循环体的方式
⛅for + break的使用
强制结束当前所在的循环体代码
#循环打印1-10,打印到5结束打印
for i in range(1, 11):
print(i)
if i == 5:
break
#结果为:1 2 3 4 5 各一行
'需注意打印位置的不同 产生的结果也不同 需了解执行流程才好判断'
⛅for + continue的使用
当执行到continue时结束本次循环,并回到循环体条件判断处开始下一次循环
#循环打印1-5,到3跳过并继续打印
for i in range(1,6):
if i==3:
continue
print(i)
#结果为:1 2 4 5 各一行
'需注意打印位置的不同 产生的结果也不同 需了解执行流程才好判断'
⛅for + else的使用
循环体代码没有被break强制结束,循环体代码全部执行完就会执行else子代码
count = 1
for i in range(3):
print(i)
else:
print('循环体代码全部执行完且没有被break!则执行else')
#结果为:0 1 2 循环体代码全部执行完且没有被break!则执行else 各一行
5)range方法
range可以理解为可以快速产生一个包含多个整数的列表
1)括号内只有一个数字,那就是从0到4结束(顾头不顾尾)
for i in range(5):
print(i)
#结果为:0 1 2 3 4 各一行
2)括号内有两个数字,第一个就是起始位置,第二个就是终止位置(顾头不顾尾)
for i in range(1,5):
print(i)
#结果为:1 2 3 4 各一行
3)括号内有三个数字,第一个是起始位置,第二个是终止位置,第三个是等差值(间隔)。同样顾头不顾尾
for i in range(1,10,3):
print(i)
#结果为:1 4 7 各一行
不同版本解释器的range方法区别
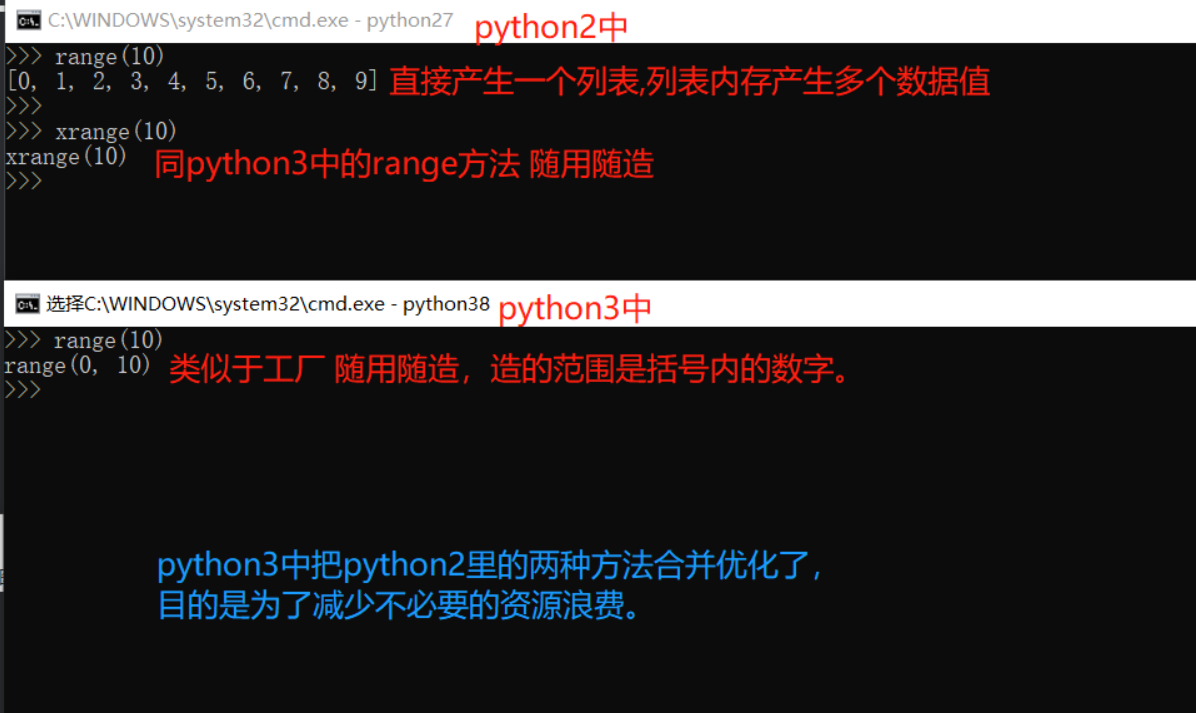
python2:
1)range()
直接产生一个列表,列表内存放多个数据值
2)xrange()
同python3中的range方法
python3:
1)range()
类似于一个工厂,什么时候要数据什么时候就创出来,范围是括号内的数字,目的:节省内存
6)range实战案例
网络爬虫
使用代码爬取网络上我们需要的数据
项目需求
爬取所有页面的数据(博客园)
找寻规律
https://www.cnblogs.com/
https://www.cnblogs.com/#p2
https://www.cnblogs.com/#p3
https://www.cnblogs.com/#p4
大胆猜测:第一页是 https://www.cnblogs.com/#p1
'''
分页的规律 不同的网址有所区别
1.在网址里面有规律
2.内部js文件动态加载
'''
尝试编写代码产生博客园文章前两百页的网址:
a='https://www.cnblogs.com/#p%s'
for i in range(1,201):
print(a % i)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号