Ds100p -「数据结构百题」51~60
纪念
数据结构一百题50题了呢,该过半周年啦~~~~
LYC和WGY半年的努力让这个几乎玩笑一般的系列到了现在。
今后也请多多关照啦。
祝愿dp100p早日过半
51.CF1000F One Occurrence
给定一个长度为\(n\)序列,\(m\)个询问,每次询问给定一个区间\([l,r]\),如果这个区间里存在只出现一次的数,输出这个数(如果有多个就输出任意一个),没有就输出0。\(n,m\le 5e5\)
题意简述
给定一个序列,每次询问输出一个区间 \([l,r]\) 中只出现一次的数。
题解
这道题其实比较有意思。他让你输出只出现一次的数,讲道理你让我维护个数都还好办,这个就比较好玩了。
我这里给出一种不用吸氧的卡常莫队做法。
其实莫队需要维护的东西很简单,就是一个数的出现次数,我们用一个数组 cnt 来记录。
每次我们算加贡献的时候,cnt 的计算方法很显然。我们同时维护一个栈,算加贡献的时候如果这个数的出现次数为1,我们就把他放到栈顶上去。我们顺手维护一个数组 pos 表示这个数在栈里的位置。
算减贡献的时候 cnt 的计算方法依旧显然。我们把栈顶元素放到删除的数的位置上即可。
每次询问的答案就是栈顶元素,由于不合法的情况输出零,所以没必要特判。
光这样是过不了的,会T飞。
我们需要一个针对于莫队的优化,叫做奇偶性排序优化(瞎编的一个名字),具体来说就是在对询问排序的时候分块的奇偶性,具体实现看代码。这种排序的方式理论来说有 \(\Theta(\frac{1}{2})\) 的常数。
这样还是会T。容易发现输出答案的循环可以用unroll循环展开,我设的unroll的参是10,已经能过了。
#include <cstdio>
#include <algorithm>
using namespace std;
const int Maxn = 5e5 + 5, Each = 720;
int n, m, top, isa[ Maxn ], cnt[ Maxn ], pos[ Maxn ], htl[ Maxn ], ans[ Maxn ];
struct Query_Node
{
int l, r, id, pos;
Query_Node( int L = 0, int R = 0, int ID = 0 ) { l = L, r = R, id = ID; }
} Q[ Maxn ];
inline int read( )
{
int a = 0, minus = 0;
char ch = getchar( );
while( !isdigit( ch ) )
{
if( ch == '-' ) minus = 1;
ch = getchar( );
}
while( isdigit( ch ) )
{
a = a * 10 + ch - '0';
ch = getchar( );
}
if( minus ) return -a;
else return a;
}
inline void write( int x )
{
if( x < 0 )
{
x = -x;
putchar( '-' );
}
if( x > 9 ) write( x / 10 );
putchar( x % 10 + '0' );
}
inline bool cmp( Query_Node rhs, Query_Node shr )
{
if( rhs.pos != shr.pos ) return rhs.l < shr.l;
else if( rhs.pos & 1 ) return rhs.r < shr.r;
else return rhs.r > shr.r;
}
inline void Make_Cont( int x, int t )
{
x = isa[ x ];
if( t == 1 ) ++ cnt[ x ];
else --cnt[ x ];
if( cnt[ x ] == 1 )
{
htl[ ++ top ] = x;
pos[ x ] = top;
}
else if( ( t == 1 ) ? ( cnt[ x ] == 2 ) : ( cnt[ x ] == 0 ) )
{
htl[ pos[ x ] ] = htl[ top ];
pos[ htl[ top ] ] = pos[ x ];
pos[ x ] = htl[ top -- ] = 0;
}
}
inline void Contribute( )
{
int l = 1, r = 0;
for( int i = 0; i < m; ++ i )
{
while( l < Q[ i ].l ) Make_Cont( l ++, 0 );
while( l > Q[ i ].l ) Make_Cont( -- l, 1 );
while( r < Q[ i ].r ) Make_Cont( ++ r, 1 );
while( r > Q[ i ].r ) Make_Cont( r --, 0 );
ans[ Q[ i ].id ] = htl[ top ];
}
}
signed main( )
{
n = read( );
for( int i = 1; i <= n; ++ i ) isa[ i ] = read( );
m = read( );
for( int i = 0; i < m; ++ i )
{
Q[ i ].l = read( );
Q[ i ].r = read( );
Q[ i ].id = i;
Q[ i ].pos = Q[ i ].l / Each;
}
sort( Q, Q + m, cmp );
Contribute( );
if( m <= 10 )
{
for( int i = 0; i < m; ++ i ) write( ans[ i ] ), putchar( '\n' );
return 0;
}
#pragma unroll 10
for( int i = 0; i < m; ++ i ) write( ans[ i ] ), putchar( '\n' );
return 0;
}
52.P5046 [Ynoi2019模拟赛]Yuno loves sqrt technology I

给你一个长为 \(n\) 的排列,\(m\) 次询问,每次查询一个区间的逆序对数,强制在线。
题意简述
无修改区间求逆序对。
题解
首先有一个显然的 \(\Theta(N\sqrt{N}\log_{2}N)\) 做法,由于过不了所以我就不废话。
其实有了 \(\Theta(N\sqrt{N}\log_{2}N)\) 的过不去做法,我们就可以根据这个思路然后预处理解决问题。
我们需要处理的信息有:
-
散块的逆序对数量
-
以块为单位的区间逆序对数量
那么我们需要处理的数组就有以下几个:
-
previous[i]表示 \(i\) 到 该块开头的逆序对数量。 -
suffix[i]同理。 -
block[i][j]表示前 \(i\) 个块中 \(\leq j\) 元素个数。 -
intervals[i][j]表示以块为单位的区间 \([i,j]\) 中的逆序对数量。
讲讲预处理方法。
-
previous[i]和suffix[i]的处理方法都很显然,可以一直扫着然后FWT扫就行。 -
block[i][j]可以递推,递推式为block[i][j]=block[i+1][j]+block[i][j-1]-block[i+1][j-1]+cont(i,j)。其中cont(i,j)表示计算对应块的逆序对数。 -
intervals[i][j]每次循环到块的开头继承上一个块的贡献即可。
计算贡献的方法很简单,归并即可。mrsrz讲得也挺清楚的,我这里就不再赘述,主要讲讲怎么卡常。
首先我们可以把主函数里的所有循环全部展开,经过实践参数传8的时候跑得比较快。
然后八聚氧先加上,luogu O2也开着。
再其次快读fread快输fwrite,这些都是卡常的标配。
然后就把能拿出来的结构体拿出来,实在不能就不管了。
然后去STL,pair vector能去就去。
然后long long开在正确的地方,不要无脑replace。
函数inline,循环register。虽然可能作用不大但是可以先加上。
然后调块长,经过无数次实践发现取150~170较为优秀。
然后加了过后发现就算rp再好也只有60pts。
然后谷歌搜索硫酸的化学式H₂SO₄,给评测机喂硫酸(idea来自SyadouHayami)。
然后本来交了5页都过不了,这下再交两次就过了。
// 省略八聚氧
#include <cstdio>
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int Maxn = 1e5 + 5;
const int Maxm = 650;
const int each = 160;
int n, m, blocks, Lp[Maxn], Rp[Maxn], isa[Maxn], head[Maxn], tail[Maxn], sorted[Maxn], belong[Maxn], previous[Maxn], suffix[Maxn], block[Maxm][Maxn];
long long intervals[Maxm][Maxn];
struct Holy_Pair
{
int first, second;
bool operator < (const Holy_Pair& rhs) const
{
return first < rhs.first;
}
} current[Maxn];
struct Fenwick_Tree
{
int fwt[Maxn];
inline void Modify(int x, int v)
{
for (; x + 5 <= Maxn; x += x & -x) fwt[x] += v;
}
inline int Query(int x)
{
int ret = 0;
for (; x; x ^= x & -x) ret += fwt[x];
return ret;
}
} FWT;
#define io_e '\0'
#define io_s ' '
#define io_l '\n'
namespace Fast_IO
{
... // 省略快读
} // namespace Fast_IO
using Fast_IO::read;
using Fast_IO::write;
inline Holy_Pair make_pair(int first, int second)
{
Holy_Pair ret;
ret.first = first;
ret.second = second;
return ret;
}
inline int Merge_Vct(int rhs[], int shr[], int szl, int szr)
{
int itl = 1, itr = 1;
int ret = 0, ctr = 1;
while (itl <= szl && itr <= szr)
{
if (rhs[itl] < shr[itr]) ++itl, ++ctr;
else
{
ret += szl - ctr + 1;
++itr;
}
}
return ret + szr - szr;
}
inline int Merge_Idx(int st1, int st2, int sz1, int sz2)
{
int ret = 0, id1 = st1 + 1, id2 = st2 + 1;
sz1 += st1, sz2 += st2;
while (id1 <= sz1 && id2 <= sz2)
{
if (sorted[id1] < sorted[id2]) ++id1;
else
{
ret += sz1 - id1 + 1;
++id2;
}
}
return ret;
}
inline void Behavior(int l, int r, long long &ans)
{
int itl = 0, itr = 0;
if (belong[l] == belong[r])
{
for (int i = head[belong[l]]; i <= tail[belong[r]]; ++i)
{
if (current[i].second >= l && current[i].second <= r) Rp[++itr] = sorted[i];
else if (current[i].second < l) Lp[++itl] = sorted[i];
}
if (l == head[belong[l]]) ans = previous[r] - Merge_Vct(Lp, Rp, itl, itr);
else ans = previous[r] - previous[l - 1] - Merge_Vct(Lp, Rp, itl, itr);
}
else
{
ans = intervals[belong[l] + 1][belong[r] - 1] + previous[r] + suffix[l];
for (int i = head[belong[l]]; i <= tail[belong[l]]; ++i)
{
if (current[i].second >= l)
{
Lp[++itl] = sorted[i];
ans += block[belong[r] - 1][1] - block[belong[r] - 1][sorted[i]] - block[belong[l]][1] + block[belong[l]][sorted[i]];
}
}
for (int i = head[belong[r]]; i <= tail[belong[r]]; ++i)
{
if (current[i].second <= r)
{
Rp[++itr] = sorted[i];
ans += block[belong[r] - 1][sorted[i] + 1] - block[belong[l]][sorted[i] + 1];
}
}
ans += Merge_Vct(Lp, Rp, itl, itr);
}
write(io_l, ans);
}
signed main()
{
read(n, m), blocks = (n - 1) / each + 1;
if (n <= 8)
{
for (int i = 1; i <= n; ++i)
{
read(isa[i]);
current[i] = make_pair(isa[i], i);
}
}
else
{
#pragma unroll 8
for (int i = 1; i <= n; ++i)
{
read(isa[i]);
current[i] = make_pair(isa[i], i);
}
}
if (blocks <= 8)
{
for (int i = 1; i <= blocks; ++i)
{
head[i] = tail[i - 1] + 1;
tail[i] = tail[i - 1] + each;
if (i == blocks) tail[i] = n;
}
}
else
{
#pragma unroll 8
for (int i = 1; i <= blocks; ++i)
{
head[i] = tail[i - 1] + 1;
tail[i] = tail[i - 1] + each;
if (i == blocks) tail[i] = n;
}
}
if (blocks <= 8)
{
for (int i = 1; i <= blocks; ++i)
{
memcpy(block[i], block[i - 1], sizeof(block[0]));
sort(current + head[i], current + 1 + tail[i]);
for (int j = head[i]; j <= tail[i]; ++j)
{
++block[i][isa[j]];
belong[j] = i;
sorted[j] = current[j].first;
}
int satisfy = 0;
for (int j = head[i]; j <= tail[i]; ++j)
{
FWT.Modify(isa[j], 1);
satisfy += FWT.Query(n) - FWT.Query(isa[j]);
previous[j] = satisfy;
}
intervals[i][i] = satisfy;
for (int j = head[i]; j <= tail[i]; ++j)
{
suffix[j] = satisfy;
FWT.Modify(isa[j], -1);
satisfy -= FWT.Query(isa[j] - 1);
}
}
}
else
{
#pragma unroll 8
for (int i = 1; i <= blocks; ++i)
{
memcpy(block[i], block[i - 1], sizeof(block[0]));
sort(current + head[i], current + 1 + tail[i]);
for (int j = head[i]; j <= tail[i]; ++j)
{
++block[i][isa[j]];
belong[j] = i;
sorted[j] = current[j].first;
}
int satisfy = 0;
for (int j = head[i]; j <= tail[i]; ++j)
{
FWT.Modify(isa[j], 1);
satisfy += FWT.Query(n) - FWT.Query(isa[j]);
previous[j] = satisfy;
}
intervals[i][i] = satisfy;
for (int j = head[i]; j <= tail[i]; ++j)
{
suffix[j] = satisfy;
FWT.Modify(isa[j], -1);
satisfy -= FWT.Query(isa[j] - 1);
}
}
}
if (blocks <= 8)
{
for (int dis = 1; dis <= blocks; ++dis)
{
for (int i = n - 1; i; --i) block[dis][i] += block[dis][i + 1];
for (int l = 1, r = dis + 1; r <= blocks + 1; ++l, ++r)
intervals[l][r] = intervals[l + 1][r] + intervals[l][r - 1] - intervals[l + 1][r - 1] +
Merge_Idx(head[l] - 1, head[r] - 1, tail[l] - head[l] + 1, tail[r] - head[r] + 1);
}
}
else
{
#pragma unroll 8
for (int dis = 1; dis <= blocks; ++dis)
{
for (int i = n - 1; i; --i) block[dis][i] += block[dis][i + 1];
for (int l = 1, r = dis + 1; r <= blocks + 1; ++l, ++r)
intervals[l][r] = intervals[l + 1][r] + intervals[l][r - 1] - intervals[l + 1][r - 1] +
Merge_Idx(head[l] - 1, head[r] - 1, tail[l] - head[l] + 1, tail[r] - head[r] + 1);
}
}
if (m <= 8)
{
long long lastans = 0;
for (int i = 0; i < m; ++i)
{
long long l, r;
read(l, r);
l ^= lastans;
r ^= lastans;
Behavior(l, r, lastans);
}
}
else
{
long long lastans = 0;
#pragma unroll 8
for (int i = 0; i < m; ++i)
{
long long l, r;
read(l, r);
l ^= lastans;
r ^= lastans;
Behavior(l, r, lastans);
}
}
return 0;
}
53.SP20644 ZQUERY - Zero Query
长度为\(n\)的序列,序列中的值为\(1\)或\(-1\)
有\(m\)个询问,询问在\([L,R]\)中区间和为\(0\)的区间的最大长度
题意简述
求区间中区间和为0的最长区间。
题解
首先前缀和基本操作,然后问题转化为:
给定询问区间 \([l,r]\),求区间中相同的数的最远间隔距离,即P5906。
考虑莫队来整。
可以维护两个东西,一个是 pre[x] 表示当前的询问区间 \([l,r]\) 中 \(x\) 最早出现的位置。
还有一个是 suf[x] 表示当前的询问区间 \([l,r]\) 中 \(x\) 最后出现的位置。
在莫队加贡献的时候这些很好整,分别像这样维护:
如果加贡献时出现了数 \(x\) 那么 pre[x]=p,\(p\) 表示加贡献时计算的位置。
suf[x] 同理。
那么询问的答案就是 \(\max_{i\in [l,r]}\{suf_{a_{x}}-pre_{a_{x}}\}\)。
中间有个特殊情况就是需要判断还没被更新过的时候,自己打代码的时候注意点。
然后发现一个神奇的事情:减贡献我们做不来了!
既然我们不会做减法,那就不做吧。
正常的莫队的询问区间左右指针 \(l,r\) 一般初值为 \(l=1,r=0\)。
我们这里换一种方式。
首先我们把询问分块,然后排序,这是莫队的常规操作。
然后再枚举每个块,我们首先处理询问的左端点在当前块中的询问,思考一下询问分块的排序方式就可以知道这种算法的正确性。
然后我们把指针的初值设为 \(l=R_{i}+1,r=R_{i}-1\),其中数组 \(R\) 表示块的左端点。
然后如果询问区间在一个块中就暴力。
由于询问区间在一个块中的询问我们已经暴力处理过了,所以剩下的询问右端点一定在其他块。
然后 \(r\) 指针正常右移,这一步只需要加贡献。
所以 \(l\) 指针只需要左移,我们就可以合并两次的贡献,就是这次询问的答案。
由于排序的规则,剩下的询问右端点一定在当前询问右端点的右边,所以我们的 \(r\) 指针可以不用管,就放到当前询问的位置。
但是 \(l\) 是无序的,所以我们需要撤销计算 \(l\) 产生的贡献,这很简单,不赘述。
这种算法叫回滚莫队。
但是这种trick我在之前一道莫队题中想到过,不过觉得太麻烦就没打。
后来发现有这个东西的板子,又重学了一遍。
还是挺好玩的吧,数据结构。
#include <cstdio>
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
#include <cmath>
using namespace std;
const int Maxn = 2e5 + 5;
int n, m, each, cube, isa[Maxn], pre[Maxn], nxt[Maxn], vio[Maxn], ans[Maxn], bel[Maxn], head[Maxn], tail[Maxn];
struct Query_Node
{
int l, r, id;
} Q[Maxn];
bool cmp(Query_Node rhs, Query_Node shr)
{
if (bel[rhs.l] == bel[shr.l]) return rhs.r < shr.r;
else return bel[rhs.l] < bel[shr.l];
}
void Contribute(int las = 0)
{
for (int k = 1; k <= cube; ++k)
{
int l = tail[k] + 1, r = tail[k], ret = 0;
vector < int > vctr;
for (int c = las + 1; bel[Q[c].l] == k; ++c)
{
int ql = Q[c].l, qr = Q[c].r, now = 0;
if (bel[ql] == bel[qr])
{
for (int i = ql; i <= qr; ++i) vio[isa[i]] = 0;
for (int i = ql; i <= qr; ++i)
{
if (!vio[isa[i]]) vio[isa[i]] = i;
else now = max(now, i - vio[isa[i]]);
}
ans[Q[c].id] = now;
las = c;
}
else
{
while (r < qr)
{
++r;
nxt[isa[r]] = r;
if (pre[isa[r]] == 0)
{
pre[isa[r]] = r;
vctr.push_back(isa[r]);
}
ret = max(ret, nxt[isa[r]] - pre[isa[r]]);
}
now = ret;
while (l > ql)
{
--l;
if (nxt[isa[l]] == 0) nxt[isa[l]] = l;
else ret = max(ret, nxt[isa[l]] - l);
}
while (l < tail[k] + 1)
{
if (nxt[isa[l]] == l) nxt[isa[l]] = 0;
++l;
}
ans[Q[c].id] = ret;
ret = now;
las = c;
}
}
for (unsigned i = 0; i < vctr.size(); ++i) pre[vctr[i]] = nxt[vctr[i]] = 0;
}
}
signed main()
{
scanf("%d %d", &n, &m);
++n;
each = pow(n, 0.5);
cube = (n - 1) / each + 1;
for (int i = 2; i <= n; ++i)
{
scanf("%d", &isa[i]);
isa[i] += isa[i - 1];
}
for (int i = 1; i <= n; ++i) isa[i] += 50005;
for (int i = 1; i <= cube; ++i)
{
head[i] = tail[i - 1] + 1;
tail[i] = tail[i - 1] + each;
for (int j = head[i]; j <= tail[i]; ++j) bel[j] = i;
if (i == cube) tail[i] = n;
}
for (int i = 1; i <= m; ++i)
{
scanf("%d %d", &Q[i].l, &Q[i].r);
Q[i].r += 1;
Q[i].id = i;
}
sort(Q + 1, Q + 1 + m, cmp);
Contribute();
for (int i = 1; i <= m; ++i) printf("%d\n", ans[i]);
return 0;
}
54.P5268 [SNOI2017]一个简单的询问
给你一个长度为 \(N\) 的序列 \(a_i\),\(1\leq i\leq N\),和 \(q\) 组询问,每组询问读入 \(l_1,r_1,l_2,r_2\),需输出
$ \text{get}(l,r,x)$ 表示计算区间 \([l,r]\) 中,数字 \(x\) 出现了多少次。
题意简述
求式子
题解
纯算式子nt行为,由于是出现次数,满足区间加减性,所以我们可以这样表达 \(\mathrm{get}(l,r,x)\)(省略 \(x\)):
那么我们代进原式,化一波式子:
则答案为:
考虑怎么更新,比如从 \(l\) 更新到 \(l+1\),则:
其中 \(\mathrm{cont}(a_{l})\) 表示 \(a_{l}\) 的出现次数。
则我们就知道怎么更新了,由于我们维护和的是前缀信息,所以姿势和普通莫队有点不一样。
维护两个数组 cntl[x] 和 cntr[y] 表示答案式子
中 \(F(x,y)\) 的值。
式子和表达可能有些玄学,自己意会一下吧。
#include <cstdio>
#include <algorithm>
using namespace std;
const int Maxn = 50000 + 5;
int n, m, q, each, cube, isa[Maxn], bel[Maxn], cntl[Maxn], cntr[Maxn];
long long now, ans[Maxn];
struct Query_Node
{
int l, r, id, typ;
Query_Node(int tl = 0, int tr = 0, int tid = 0, int tpyt = 0)
{
l = tl;
r = tr;
id = tid;
typ = tpyt;
}
} Q[Maxn << 2];
bool cmp(Query_Node rhs, Query_Node shr)
{
if (bel[rhs.l] == bel[shr.l]) return rhs.r < shr.r;
else return rhs.l < shr.l;
}
void Contribute()
{
int l = 0, r = 0;
for (int i = 1; i <= m; ++i)
{
while (l < Q[i].l)
{
++cntl[isa[++l]];
now += cntr[isa[l]];
}
while (l > Q[i].l)
{
--cntl[isa[l]];
now -= cntr[isa[l--]];
}
while (r < Q[i].r)
{
++cntr[isa[++r]];
now += cntl[isa[r]];
}
while (r > Q[i].r)
{
--cntr[isa[r]];
now -= cntl[isa[r--]];
}
ans[Q[i].id] += Q[i].typ * now;
}
}
signed main()
{
scanf("%d", &n);
each = 230;
for (int i = 1; i <= n; ++i)
{
scanf("%d", &isa[i]);
bel[i] = (i - 1) / each + 1;
}
scanf("%d", &q);
for (int i = 1; i <= q; ++i)
{
int l1, r1, l2, r2;
scanf("%d %d %d %d", &l1, &r1, &l2, &r2);
Q[++m] = Query_Node(r1, r2, i, 1);
Q[++m] = Query_Node(r1, l2 - 1, i, -1);
Q[++m] = Query_Node(l1 - 1, r2, i, -1);
Q[++m] = Query_Node(l1 - 1, l2 - 1, i, 1);
}
for (int i = 1; i <= m; ++i)
{
if (Q[i].l < Q[i].r) swap(Q[i].l, Q[i].r);
}
sort(Q + 1, Q + 1 + m, cmp);
Contribute();
for (int i = 1; i <= q; ++i) printf("%lld\n", ans[i]);
return 0;
}
55.P3466 [POI2008]KLO-Building blocks
有 \(n\) 柱砖,每柱砖有一个高度,我们现在希望有连续 \(k\) 柱的高度是一样的。
你可以选择以下两个动作:
1:从某柱砖的顶端拿一块砖出来,丢掉不要了。
2:从仓库中拿出一块砖,放到另一柱,仓库是无限大的。
现在希望用最小次数的动作完成任务,除此之外你还要求输出结束状态时,每柱砖的高度。
题意简述
给定一个长度为 \(n\) 的序列,支持单点减一,单点加法的操作,问把一个长度为 \(k\) 的区间里的值变成同样的最小操作数。
题解
挺好的一道平衡树练手+猜结论题。(雾
化简一下题意,我们需要找到一个值 \(m\) 且 \(m\) 使得 \(\sum_{i=1}^{r}\mid a_{i}-x\mid\) 最小。
其中 \(r-l+1=k\)。
大约可以猜到这里需要取中位数。
感性理解一下,把 \(a_{l},a_{l+1},\cdots,a_{r}\) 排序后如果每个数要取最小只能取中位数。
可以当成一个结论式的东西积累起来。
那么我们就需要一个数据结构,支持插入,删除,查 \(k_{th}\)。
这里我选择的是Zip-Tree,也就是国内常说的FHQ-Treap。
具体的做法是,枚举每个长度为 \(k\) 的区间 \([l,r]\),首先我们把 \(a_{1},a_{2},\cdots,a_{k}\) 插入平衡树,然后根据 \(k\) 的奇偶性用 \(k_{th}\) 操作找到中位数(序列的中位数根据序列的长度奇偶性不同有区别)。
然后计算贡献即可,顺手记录一下区间的位置,方便输出答案。
贡献的计算可以分成大于中位数,小于中位数,等于中位数的情况。
#include <cstdio>
#include <cstdlib>
#include <ctime>
#include <climits>
#define int long long
const int Maxn = 1e5 + 5;
int n, k, rt, tot, isa[Maxn];
struct Treap
{
int l, r, siz, sum, key, val;
} t[Maxn];
int newnode(int val)
{
t[++tot].val = val;
t[tot].sum = val;
t[tot].key = rand();
t[tot].siz = 1;
return tot;
}
void maintain(int x)
{
t[x].siz = t[t[x].l].siz + t[t[x].r].siz + 1;
t[x].sum = t[t[x].l].sum + t[t[x].r].sum + t[x].val;
}
void Split(int now, int val, int &x, int &y)
{
if (now == 0) x = y = 0;
else
{
if (val >= t[now].val)
{
x = now;
Split(t[now].r, val, t[now].r, y);
}
else
{
y = now;
Split(t[now].l, val, x, t[now].l);
}
maintain(now);
}
}
int Merge(int x, int y)
{
if (x == 0 || y == 0) return x + y;
else
{
if (t[x].key > t[y].key)
{
t[x].r = Merge(t[x].r, y);
maintain(x);
return x;
}
else
{
t[y].l = Merge(x, t[y].l);
maintain(y);
return y;
}
}
}
int rt1, rt2, rt3;
void Insert(int val)
{
Split(rt, val, rt1, rt2);
rt = Merge(rt1, Merge(newnode(val), rt2));
}
void Remove(int val)
{
Split(rt, val, rt1, rt3);
Split(rt1, val - 1, rt1, rt2);
rt2 = Merge(t[rt2].l, t[rt2].r);
rt = Merge(rt1, Merge(rt2, rt3));
}
int Find_Kth(int rnk)
{
int now = rt;
while (now)
{
if (t[t[now].l].siz + 1 == rnk) break;
else if (t[t[now].l].siz >= rnk) now = t[now].l;
else
{
rnk -= t[t[now].l].siz + 1;
now = t[now].r;
}
}
return t[now].val;
}
int Query(int mid)
{
Split(rt, mid, rt1, rt3);
Split(rt1, mid - 1, rt1, rt2);
int lth = rt1, mth = rt3;
int cont_l = t[lth].siz * mid - t[lth].sum;
int cont_r = t[mth].sum - t[mth].siz * mid;
rt = Merge(rt1, Merge(rt2, rt3));
return cont_l + cont_r;
}
signed main()
{
srand((unsigned)(time(NULL)));
int MID, LEFT, RIGHT, ANS = LONG_LONG_MAX;
scanf("%lld %lld", &n, &k);
for (int i = 1; i <= n; ++i) scanf("%lld", &isa[i]);
for (int i = 1; i <= k; ++i) Insert(isa[i]);
int l = 1, r = k;
for (int i = k; i <= n; ++i)
{
int mid;
if (k & 1) mid = Find_Kth((k >> 1) + 1);
else mid = (Find_Kth(k >> 1) + Find_Kth((k >> 1) + 1)) >> 1;
int xxx = Query(mid);
if (ANS > xxx)
{
ANS = xxx;
MID = mid;
LEFT = l - 1;
RIGHT = r + 1;
}
l++, r++;
Remove(isa[l - 1]);
Insert(isa[r]);
}
printf("%lld\n", ANS);
for (int i = 1; i <= LEFT; ++i) printf("%lld\n", isa[i]);
for (int i = LEFT + 1; i <= RIGHT - 1; ++i) printf("%lld\n", MID);
for (int i = RIGHT; i <= n; ++i) printf("%lld\n", isa[i]);
return 0;
}
56.P5610 [Ynoi2013]大学
一个长为 \(n\) 的非负整数序列 \(a\),支持以下两个操作:
1 l r x:把区间 \([l,r]\) 中所有 \(x\) 的倍数除以 \(x\)。2 l r:查询区间 \([l,r]\) 的和。
本题强制在线,每次的 \(l,r,x\) 需要 xor 上上次答案,如果之前没有询问,则上次答案为 \(0\)。
题意简述
区间查 \(x\) 的倍数并除掉,区间查和。
题解
平衡树。
首先有个基本的想法就是按 \(a_{i}\) 开平衡树,即对于每个 \(a_{i}\) 都开一棵平衡树,共5e5棵,第 \(i\) 棵平衡树维护的值是所有 \(a_{i}\) 的倍数在原数组中的下标,用处后面讲。
注意到一个小性质,一个正整数 \(A\) 最多被整除 \(\log_{2}A\) 次,这个很好想,每次都至少减少一半。可以当成一个 trick 记下来。
整个区间的数最多被除 \(\sum_{i=1}^{n}\log_{2}a_{i}\) 次,区间和的操作可以用树状数组操作实现,则整体的操作复杂度为 \(\Theta(\sum_{i=1}^{n}\log_{2}a_{i}+\log_{2}a_{i})\)。
开头提到了对于每个 \(a_{i}\) 我们都开一棵平衡树,作用就体现在这里。因为如果要保证正确的时间复杂度,我们需要快速的找到需要执行操作的数。
这里我采用的是 FHQ-Treap。
我们可以用两次 split 操作在 \(x\) 的平衡树中提取出当前的询问区间,由于我们是以下标为平衡树维护的权值,所以我们用按值分裂即可提取出区间。
然后我们就在提取出的子树中 DFS 遍历,然后暴力操作,把操作后依然是 \(x\) 的倍数的数记录下来,操作完后用这个数组再建一棵临时树然后和之前 split 出来的子树一起合并回去。
【记得配图,解释一下】
操作之前记得预处理每个数的所有约数,这个简单,直接用 vector 即可。
#include <cstdio>
#include <cstdlib>
#include <algorithm>
#include <ctime>
#include <queue>
using namespace std;
typedef long long t_t;
const int Maxn = 1e5 + 5;
const int Maxa = 5e5 + 5;
int n, m, xxx, zip, tot, isa[Maxn], bin[Maxa], root[Maxa];
struct Treap
{
int l, r, key, val;
} t[Maxa * 230];
struct Fenwick_Tree
{
t_t bit[Maxn];
void ins(int x, t_t v)
{
for (; x <= n; x += x & -x) bit[x] += v;
}
t_t sum(int x)
{
t_t ret = 0;
for (; x; x -= x & -x) ret += bit[x];
return ret;
}
} fwt;
vector < int > vec[Maxa];
int newnode(int val)
{
t[++tot].val = val;
t[tot].key = rand();
return tot;
}
void split(int now, int val, int &x, int &y)
{
if (now == 0) x = y = 0;
else
{
if (t[now].val <= val)
{
x = now;
split(t[now].r, val, t[now].r, y);
}
else
{
y = now;
split(t[now].l, val, x, t[now].l);
}
}
}
int merge(int x, int y)
{
if (x == 0 || y == 0) return x | y;
if (t[x].key > t[y].key)
{
t[x].r = merge(t[x].r, y);
return x;
}
else
{
t[y].l = merge(x, t[y].l);
return y;
}
}
int build(int l, int r)
{
if (l > r) return 0;
int mid = (l + r) >> 1;
int now = newnode(bin[mid]);
t[now].l = build(l, mid - 1);
t[now].r = build(mid + 1, r);
return now;
}
void dfs(int now, int val)
{
if (now == 0) return ;
dfs(t[now].l, val);
if (isa[t[now].val] % val == 0)
{
fwt.ins(t[now].val, -isa[t[now].val]);
isa[t[now].val] /= val;
fwt.ins(t[now].val, isa[t[now].val]);
}
if (isa[t[now].val] % val == 0) bin[++zip] = t[now].val;
dfs(t[now].r, val);
}
int tx, ty, tp;
void change(int l, int r, int x)
{
if (x == 1) return ;
split(root[x], r, tx, tp);
split(tx, l - 1, tx, ty);
zip = 0;
dfs(ty, x);
root[x] = merge(tx, merge(build(1, zip), tp));
}
signed main()
{
srand((114514 - 1) / 3 - 4);
scanf("%d %d", &n, &m);
for (int i = 1; i <= n; ++i)
{
scanf("%d", &isa[i]);
fwt.ins(i, isa[i]);
xxx = max(xxx, isa[i]);
}
for (int i = 1; i <= n; ++i)
{
for (int j = 1; j * j <= isa[i]; ++j)
{
if (isa[i] % j == 0)
{
vec[j].push_back(i);
if (j * j != isa[i]) vec[isa[i] / j].push_back(i);
}
}
}
for (int i = 1; i <= xxx; ++i)
{
zip = 0;
for (unsigned j = 0; j < vec[i].size(); ++j) bin[++zip] = vec[i][j];
root[i] = build(1, zip);
}
for (int i = 0; i < m; ++i)
{
int t, l, r, x;
scanf("%d %d %d", &t, &l, &r);
if (t == 1)
{
scanf("%d", &x);
change(l, r, x);
}
else printf("%lld\n", fwt.sum(r) - fwt.sum(l - 1));
}
return 0;
}
57.CF803G Periodic RMQ Problem
给你一个序列\(a\) 让你支持
\(1\) \(l\) \(r\) \(x\) 区间赋值
\(2\) \(l\) \(r\) 询问区间最小值
我们觉得这个问题太水了,所以我们不会给你序列\(a\)
而是给你序列一个长度为\(n\) 的序列\(b\) ,把\(b\) 复制粘贴\(k\) 次就可以得到\(a\)
\(n\le10^5,k\le10^4,q\le10^5,b_i\le10^9\)
\(1\le l\le r\le n\times k\)
题目解释:
有一个由给定序列不断首尾拼接而成的序列(很长,存不下)。
要求实现两个操作:区间赋值和查询区间最小值。
这个序列很长不好操作,所以我们要进行离散化,缩小一下操作的范围。
把每个操作的左端点减一和右端点加入离散化数组\(pri\)(这里下标从1开始)。
离散化后第i个块的左端点是\(pri[i-1]+1\),右端点是\(pri[i]\)。(离散化还要插入\(0\)和最后一个位置的下标,不然有些位置没有被覆盖到)
但是离散化之后我们不知道每个离散化出来的块内的最小值,这样就无法初始化。
我们可以利用之前给出用来首尾拼接的序列求出来。
对每个块分类讨论:(设给定用来拼接的序列长为\(n\))
1).块长大于等于\(n\):
此时这个块已经覆盖了整个给定序列,那它的最小值直接就是给定序列的最小值。
2).块长小于\(n\):
又要分两种情况:
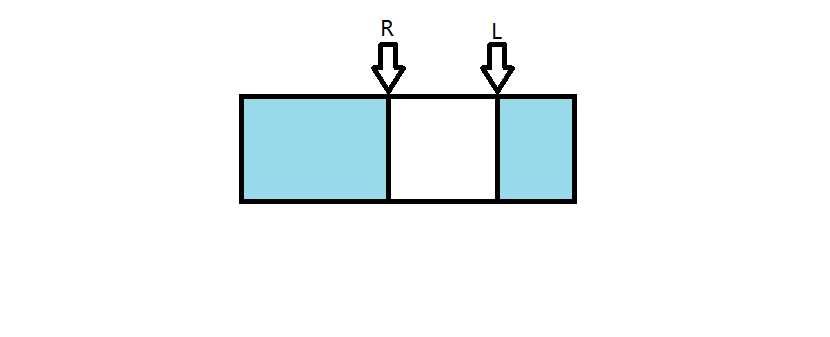
$\ \ \ \ $A).左端点投射到序列中的位置在右端点的后面(由于是由同一序列首尾拼接而成,我们可以把它们投射到一个序列上)。
$\ \ \ \ $就是说:这个块覆盖的给定序列的前面的一部分和后面的一部分。
$\ \ \ \ $就像这样:
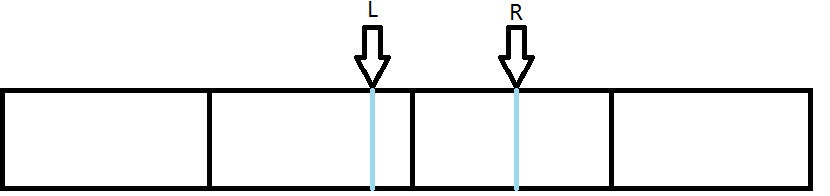
$\ \ \ \ $投射到给定序列上就像这样:
$\ \ \ \ \(那么我们直接查询(涂色的)这两段的最小值再取个\)min$就好了。
$\ \ \ \ \(其实就是从他们中间的序列尾(就是更上面的那张图L,R中间那条黑线)分开来求两边的最小值再取\)min$,就得到了他们之间的最小值。
$\ \ \ \ $B).左端点投射到序列中的位置在右端点的前面。
$\ \ \ \ $仿照上个情况,投射到序列上查询他们之间的最小值即可。
由于是以操作的左右端点做的离散化,所以一个块内要么一起被询问,要么一起被修改。
所以我们用上面的方法处理出这个离散化后的序列每个块的初始值之后,就可以用线段树把它当板题做了!
代码:
#include<cstdio>
#include<vector>
#include<algorithm>
using namespace std;
vector<int> pri;
const int INF=1e9+1;
int n,q,k,a[100010],ori[400010],op[100010],opl[100010],opr[100010],opx[100010],nodes[1000010],tag[2000010],s;
void buildori(int l,int r,int x)//对于给定序列的线段树建树。
{
if(l^r)
{
int mid=(l+r)>>1;
buildori(l,mid,x<<1);
buildori(mid+1,r,x<<1|1);
ori[x]=min(ori[x<<1],ori[x<<1|1]);
}
else ori[x]=a[l];
}
int findori(int l,int r,int x,int fr,int ba)//查询给定序列里的区间最小值。
{
if(l>ba||r<fr) return INF;
if(l>=fr&&r<=ba) return ori[x];
else
{
int mid=(l+r)>>1;
return min(findori(l,mid,x<<1,fr,ba),findori(mid+1,r,x<<1|1,fr,ba));
}
}
void build(int l,int r,int x)//对离散化后的序列建树。
{
if(l^r)
{
int mid=(l+r)>>1;
build(l,mid,x<<1);
build(mid+1,r,x<<1|1);
nodes[x]=min(nodes[x<<1],nodes[x<<1|1]);
}
else
{
if(pri[l]-pri[l-1]>=n) nodes[x]=ori[1];//情况1).
else
{
int one=(pri[l-1]+1)%n;
if(one==0) one=n;
int two=pri[l]%n;
if(two==0) two=n;
if(one>two) nodes[x]=min(findori(1,n,1,one,n),findori(1,n,1,1,two));//情况2).A).
else nodes[x]=findori(1,n,1,one,two);//情况2).B).
}
}
}
//后面的就是模板操作。
void pushdown(int x)
{
if(tag[x])
{
nodes[x]=tag[x];
tag[x<<1]=tag[x<<1|1]=tag[x];
tag[x]=0;
}
}
void update(int l,int r,int x,int fr,int ba,int val)
{
if(l>ba||r<fr) return;
if(l>=fr&&r<=ba) tag[x]=val;
else
{
int mid=(l+r)>>1;
pushdown(x);
update(l,mid,x<<1,fr,ba,val);
update(mid+1,r,x<<1|1,fr,ba,val);
pushdown(x<<1);
pushdown(x<<1|1);
nodes[x]=min(nodes[x<<1],nodes[x<<1|1]);
}
}
int find(int l,int r,int x,int fr,int ba)
{
if(l>ba||r<fr) return INF;
pushdown(x);
if(l>=fr&&r<=ba) return nodes[x];
else
{
int mid=(l+r)>>1;
return min(find(l,mid,x<<1,fr,ba),find(mid+1,r,x<<1|1,fr,ba));
}
}
int main()
{
scanf("%d %d",&n,&k);
for(int i=1;i<=n;++i) scanf("%d",&a[i]);
buildori(1,n,1);
scanf("%d",&q);
pri.push_back(0);
pri.push_back(n*k);//插入0和最后一个位置的下标。
for(int i=1;i<=q;++i)
{
scanf("%d %d %d",&op[i],&opl[i],&opr[i]);
if(op[i]==1) scanf("%d",&opx[i]);
pri.push_back(opl[i]-1);
pri.push_back(opr[i]);//把每个操作的左端点减一和右端点加入离散化数组pri。
}
sort(pri.begin(),pri.end());
pri.erase(unique(pri.begin(),pri.end()),pri.end());
s=pri.size();
build(1,s,1);//0下标的位置没有前一个,所以从1开始建树。
for(int i=1;i<=q;++i)
{
//lower_bound返回大于等于给定值的下标,插入操作时是插入的opl[i]-1和opr[i],所以查询大于等于opl[i]的下标可以查询到opl[i]所在的块。
if(op[i]==1) update(1,s,1,lower_bound(pri.begin(),pri.end(),opl[i])-pri.begin(),lower_bound(pri.begin(),pri.end(),opr[i])-pri.begin(),opx[i]);
else printf("%d\n",find(1,s,1,lower_bound(pri.begin(),pri.end(),opl[i])-pri.begin(),lower_bound(pri.begin(),pri.end(),opr[i])-pri.begin()));
}
return 0;
}
58.P5305 [GXOI/GZOI2019]旧词
> 浮生有梦三千场
> 穷尽千里诗酒荒
> 徒把理想倾倒
> 不如早还乡
>
> 温一壶风尘的酒
> 独饮往事迢迢
> 举杯轻思量
> 泪如潮青丝留他方
>
> ——乌糟兽/愚青《旧词》
你已经解决了五个问题,不妨在这大树之下,吟唱旧词一首抒怀。最后的问题就是关于这棵树的,它的描述很简单。
给定一棵 \(n\) 个点的有根树,节点标号 \(1 \sim n\),\(1\) 号节点为根。
给定常数 \(k\)。
给定 \(Q\) 个询问,每次询问给定 \(x,y\)。
求:
\(\text{lca}(x,y)\) 表示节点 \(x\) 与节点 \(y\) 在有根树上的最近公共祖先。
\(\text{depth}(x)\) 表示节点 \(x\) 的深度,根节点的深度为 \(1\)。
由于答案可能很大,你只需要输出答案模 \(998244353\) 的结果。
这道题目非常简洁:要求 \(\sum_{i\le x}depth(lca(i,y))^k\) (都写在题面里了)
要直接解决这个问题是有点困难的,那么——
我们先看它的弱化版:[LNOI2014]LCA
要求 \(\sum_{i=l}^rdepth(lca(i,z))\)
少了个k次方呢!
首先转化一下 \(\sum_{i=l}^rdepth(lca(i,z))=\sum_{i=1}^rdepth(lca(i,z))-\sum_{i=1}^{l-1}depth(lca(i,z))\)
可以用前缀和来解决这个问题。
把每个询问拆成 \((1,l-1)\) 和 \((1,r)\) 分别解决。
那么我们可以按顺序把 \(1\) 到 \(n\) 的点加进来,同时计算加到每个点时的询问答案。
那么现在考虑加到第 \(i\) 个点时如何计算贡献。
先上张图举个例子~
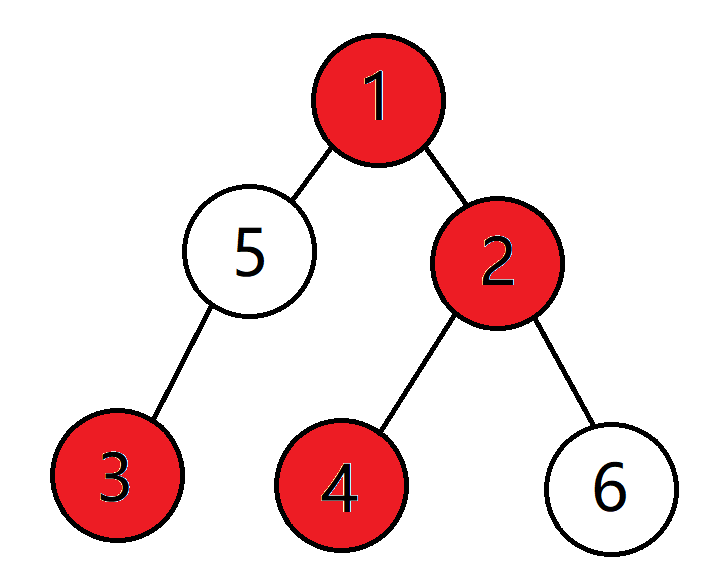
其中涂成红色的点就是已经加入的点。
我们先计算一下每个节点的子树中有多少已经加入的点,用 \(siz[x]\) 表示。没有加入的节点对当前询问肯定没有贡献。所以我们直接统计加入的节点就好了
那么 \(siz[1]=4\) , \(siz[2]=2\), \(siz[3]=1\), \(siz[4]=1\) , \(siz[5]=1\) , \(siz[6]=0\) .
现在考虑计算当前加入的节点到4的LCA深度和。
\(ans=siz[4]\times dep[4]+(siz[2]-siz[4])\times dep[2]+(siz[1]-siz[2])\times dep[1]\)
即加入的节点中在 \(4\) 的子树中的到 \(4\) 的 \(LCA\) 肯定为 \(4\)。在 \(2\) 的子树但不在 \(4\) 的子树中的到 \(4\) 的 \(LCA\) 肯定为 \(2\),在 \(1\) 的子树但不在 \(2\) 的子树中的到 \(4\) 的 \(LCA\) 肯定为 \(1\)。
把式子拆开化简得到:
\(ans=siz[4]\times (dep[4]-dep[2])+siz[2]\times (dep[2]-dep[1])+siz[1]\)
\(ans=siz[4]+siz[2]+siz[1]\)
于是我们发现其实答案就是该节点到根路径的节点子树大小之和。
普遍形式:设查询节点到根的路径为 \(\{v_1,v_2,v_3\dots v_k\}\)。
\(ans=siz[v_1]\times dep[v_1]+(siz[v_2]-siz[v_1])\times dep[v_2]+(siz[v_3]-siz[v_2])\times dep[v_3]+\dots +(siz[v_k]-siz[v_{k-1}])\times dep[v_k]\)
由于是到根节点的路径,所以 \(dep[v_i]=dep[v_{i+1}]+1\)
于是化简得
\(ans=siz[v_1]\times (dep[v_1]-dep[v_2])+siz[v_2]\times (dep[v_2]-dep[v_3])+siz[v_3]\times (dep[v_3]-dep[v_4])+\dots +siz[v_k]\times dep[v_k]\)
\(ans=siz[v_1]+siz[v_2]+siz[v_3]+\dots +siz[v_k]\)
就此得出结论:答案就是该节点到根路径的节点子树大小之和。
查询直接查询要查询的节点到根路径上的节点的子树大小之和。
加入节点时只有它到根的路径上的节点的子树大小加了一。
使用树链剖分加线段树维护即可。
回到本题
本题没有 \(l\) 的限制,所以我们不用前缀和拆询问处理了。
那么我们抬出之前的式子改成这道题的样子。
\(ans=siz[v1]\times dep[v1]^k+(siz[v2]-siz[v1])\times dep[v2]^k+(siz[v3]-siz[v2])\times dep[v3]^k+\dots+(siz[vk]-siz[vk-1])\times dep[vk]^k\)
化简一下,得到:
\(ans=siz[v_1]\times (dep[v_1]^k-dep[v_2]^k)+siz[v_2]\times (dep[v_2]^k-dep[v_3]^k)+siz[v_3]\times (dep[v_3]^k-dep[v4]^k)+\dots siz[v_k]\times dep[v_k]^k\)
可以发现,\(dep[v_2]\) 总等于 \(dep[v_1]-1\)(因为是从查询节点到根节点的路径嘛)。
所以对于\((dep[v_i]^k-dep[v_{i+1}]^k)\)这种东西,我们可以对它进行预处理。
设对于点i的预处理答案为 \(val[i]\)。
则答案为:
\(ans=siz[v_1]\times val[v_1]+siz[v_2]\times val[v_2]+siz[v_3]\times val[v_3]+...siz[v_k]\times val[v_k]\)
就是在线段树维护时多加一个权值的问题了。
在线段树的每个节点上附加一个权值,表示这个区间里所有点的 \(val\) 之和。
这样就可以区间修改和下传标记了。
跟上面那道弱化版差得不多吧~
代码:
//直接用LCA代码改的,可能有点迷惑(?
#include<cstdio>
#include<vector>
#include<algorithm>
using namespace std;
vector<long long> e[50010];
struct node
{
long long bas,sum,tag;//bas为附加的权值
}nodes[400010];
struct ask
{
long long pos,val,ID,nag;
}q[100010];
bool cmp(ask one,ask ano)
{
return one.pos<ano.pos;
}
long long n,m,s,opl,opr,opz,f,cnt,tot,waste,ans[50010],kkk,dep[50010],fa[50010],son[50010],siz[50010],hb[50010],dfn[50010],ton[50010],power[50010],bruh;
const long long mod=998244353;
long long qpow(long long bas,long long tim)//快速幂用来处理val
{
long long res=1,fur=bas;
while(tim)
{
if(tim&1) res=(res*fur)%mod;
fur=(fur*fur)%mod;
tim>>=1;
}
return res;
}
void dfs(long long x,long long las)
{
fa[x]=las;
dep[x]=dep[las]+1;
siz[x]=1;
long long b=0,s=0;
for(long long i=0;i<e[x].size();++i)
{
long long y=e[x][i];
dfs(y,x);
siz[x]+=siz[y];
if(siz[y]>b)
{
b=siz[y];
s=y;
}
}
son[x]=s;
}
void dfs2(long long x,long long las,long long heavy)//树剖dfs
{
if(heavy) hb[x]=hb[las];
else hb[x]=x;
dfn[x]=++cnt;
ton[cnt]=x;
if(son[x]) dfs2(son[x],x,1);
for(long long i=0;i<e[x].size();++i)
{
long long y=e[x][i];
if(y^son[x]) dfs2(y,x,0);
}
}
void pushdown(long long x)
{
if(nodes[x].tag)
{
//(siz[x]+a)*val[x]+(siz[y]+a)*val[y]+...+(siz[z]+a)*val[z]
//=siz[x]*val[x]+siz[y]*val[y]+...+siz[z]*val[z]+a*(val[x]+val[y]+...+val[z])
nodes[x].sum+=(nodes[x].bas*nodes[x].tag);
nodes[x].sum%=mod;
nodes[x<<1].tag+=nodes[x].tag;
nodes[x<<1].tag%=mod;
nodes[x<<1|1].tag+=nodes[x].tag;
nodes[x<<1|1].tag%=mod;
nodes[x].tag=0;
}
}
void build(long long l,long long r,long long x)//预处理val区间和
{
if(l^r)
{
long long mid=(l+r)>>1;
build(l,mid,x<<1);
build(mid+1,r,x<<1|1);
nodes[x].bas=(nodes[x<<1].bas+nodes[x<<1|1].bas)%mod;
}
else nodes[x].bas=power[dep[ton[l]]]-power[dep[ton[l]]-1];
// printf(" %lld %lld %lld\n",l,r,nodes[x].bas);
}
void update(long long l,long long r,long long x,long long fr,long long ba)
{
if(l>ba||r<fr) return;
if(l>=fr&&r<=ba) nodes[x].tag=(nodes[x].tag+1)%mod;
else
{
pushdown(x);
long long mid=(l+r)>>1;
update(l,mid,x<<1,fr,ba);
update(mid+1,r,x<<1|1,fr,ba);
pushdown(x<<1);
pushdown(x<<1|1);
nodes[x].sum=(nodes[x<<1].sum+nodes[x<<1|1].sum)%mod;
}
}
long long find(long long l,long long r,long long x,long long fr,long long ba)
{
if(l>ba||r<fr) return 0;
pushdown(x);
if(l>=fr&&r<=ba) return nodes[x].sum;
else
{
long long mid=(l+r)>>1;
return (find(l,mid,x<<1,fr,ba)+find(mid+1,r,x<<1|1,fr,ba))%mod;
}
}
void output(long long l,long long r,long long x)
{
pushdown(x);
printf(" %lld %lld %lld\n",l,r,nodes[x].sum);
if(l^r)
{
long long mid=(l+r)>>1;
output(l,mid,x<<1);
output(mid+1,r,x<<1|1);
}
}
void update_LCA(long long x,long long y)
{
long long fx=hb[x],fy=hb[y];
while(fx^fy)
{
if(dep[fx]<dep[fy])
{
swap(fx,fy);
swap(x,y);
}
update(1,s,1,dfn[fx],dfn[x]);
x=fa[fx];
fx=hb[x];
}
update(1,s,1,min(dfn[x],dfn[y]),max(dfn[x],dfn[y]));
}
long long find_LCA(long long x,long long y)
{
long long res=0;
long long fx=hb[x],fy=hb[y];
while(fx^fy)
{
if(dep[fx]<dep[fy])
{
swap(fx,fy);
swap(x,y);
}
res+=find(1,s,1,dfn[fx],dfn[x]);
res%=mod;
x=fa[fx];
fx=hb[x];
}
res+=find(1,s,1,min(dfn[x],dfn[y]),max(dfn[x],dfn[y]));
res%=mod;
return res;
}
int main()
{
scanf("%lld %lld %lld",&n,&m,&bruh);
s=n;
for(long long i=1;i<=n;++i) power[i]=qpow(i,bruh);
for(long long i=2;i<=n;++i)
{
scanf("%lld",&f);
e[f].push_back(i);
}
dfs(1,1);
dfs2(1,1,0);
build(1,s,1);
for(long long i=1;i<=m;++i)
{
scanf("%lld %lld",&opr,&opz);
q[++tot].ID=i;
q[tot].nag=1;
q[tot].pos=opr;
q[tot].val=opz;
}
sort(q+1,q+1+tot,cmp);
while(q[kkk].pos<=0&&kkk<=tot)
{
ans[q[kkk].ID]+=(q[kkk].nag*0);
++kkk;
}
for(long long i=1;i<=n;++i)
{
update_LCA(1,i);
while(q[kkk].pos<=i&&kkk<=tot)
{
ans[q[kkk].ID]+=(q[kkk].nag*find_LCA(1,q[kkk].val));
ans[q[kkk].ID]%=mod;
++kkk;
}
// puts("");
// output(1,s,1);
// puts("\n");
}
for(long long i=1;i<=m;++i) printf("%lld\n",((ans[i]%mod)+mod)%mod);
return 0;
}
59.CF643G Choosing Ads
- 给定一个长度为 \(n\) 的序列和一个整数 \(p\)。
- 有 \(m\) 个操作,操作要么是区间赋值,要么是询问区间内出现次数至少占 \(p\%\) 的数。
- 输出询问的答案时,可以包含错的数,也可以重复输出,但对的数一定要在答案中,且输出的数的个数不超过 \(\lfloor \frac{100}{p} \rfloor\)。
题意简述
够简单了。
题解
我觉得很有意思的一道题目。
第一个操作,嗯,不讲。
我们着重来看看第二个操作。
这个查询操作要我们输出所有出现次数的频率 \(\ge p\%\) 的数字。
先考虑一种特殊情况,即当 \(p>50\) 的情况,这时候这个问题的本质就成了求区间的绝对众数。
区间绝对众数有一个经典的 \(\Theta(1)\) 空间的做法,摩尔投票。
这里简单介绍一下摩尔投票法。
举个例子,序列 \(\texttt{7 5 7 6 7 7 4 7}\)。
我们定义两个变量 major,cnt。
我们遍历一遍序列:
起初 major=7,cnt=1。
然后 \(5\neq 7\),cnt--。
此时 cnt==0,我们令 major=5,cnt=1。
后面以此类推。
那么拓展到这道题目,我们的 p 最小是 20。
和普通的摩尔投票法类似,我们把 major,cnt 替换为 major[5],cnt[5],用数组来求出分别的众数。
不过这样做有可能会出现出现频率不符合答案规范的数存进来,不过反正良心出题人允许我们输出无意义内容,所以就不用管了。
然后考虑用一个数据结构来加速这个过程。
区间推平、查询首选线段树。
那么要维护的信息就很明显了。
每个结点维护一个摩尔投票的结构体,然后再维护一个区间推平的 tag。
最后 pushup 合并左右儿子贡献时,直接把右区间合并到左边来即可。
下传标记很简单,不过要注意下传时因为时区间推平,所以摩尔投票的结构体里的 cnt 部分要设为 r-l+1。
#include <cstdio>
#include <algorithm>
#include <cstring>
#include <assert.h>
using namespace std;
const int Maxn = 15e4 + 5;
int n, m, p, isa[Maxn];
struct Major_Voting // 摩尔投票的结构体
{
int major[5], cnt[5];
Major_Voting()
{
memset(major, 0, sizeof(major));
memset(cnt, 0, sizeof(cnt));
}
};
struct Segment_Tree
{
Major_Voting val;
int tag;
} t[Maxn << 2];
Major_Voting make_vote(int major) // 以 major 为关键字创建一个新的摩尔投票
{
Major_Voting ret;
memset(ret.major, 0, sizeof(ret.major));
memset(ret.cnt, 0, sizeof(ret.cnt));
ret.major[0] = major;
ret.cnt[0] = 1;
return ret;
}
Major_Voting merge(Major_Voting one, Major_Voting ano) // 合并区间,这一步的细节较多
{
Major_Voting ret = one;
for (int i = 0; i < p; ++i)
{
if (ano.cnt[i])
{
bool flag = 0;
for (int j = 0; j < p; ++j)
{
if (ret.major[j] == ano.major[i])
{
ret.cnt[j] += ano.cnt[i];
flag = 1;
break;
}
}
if (flag == 0)
{
for (int j = 0; j < p; ++j)
{
if (ret.cnt[j] == 0)
{
ret.major[j] = ano.major[i];
ret.cnt[j] = ano.cnt[i];
flag = 1;
break;
}
}
} // 把右区间的贡献算到左边来
if (flag) continue;
int line = 2e9;
for (int j = 0; j < p; ++j) line = min(line, ret.cnt[j]);
if (line >= ano.cnt[i])
{
for (int j = 0; j < p; ++j) ret.cnt[j] -= ano.cnt[i];
continue;
}
bool book = 0;
for (int j = 0; j < p; ++j)
{
if (ret.cnt[j] == line && book == 0)
{
ret.major[j] = ano.major[i];
ret.cnt[j] = ano.cnt[i] - line;
book = 1;
}
else ret.cnt[j] -= line;
} // 分类讨论最小值的处理
}
}
return ret;
}
void maintain(int p)
{
t[p].val = merge(t[p << 1].val, t[p << 1 | 1].val);
}
void spread(int p, int l, int r)
{
if (t[p].tag)
{
int mid = (l + r) >> 1;
t[p << 1].tag = t[p].tag;
t[p << 1 | 1].tag = t[p].tag;
t[p << 1].val = make_vote(t[p].tag);
t[p << 1].val.cnt[0] = mid - l + 1;
t[p << 1 | 1].val = make_vote(t[p].tag);
t[p << 1 | 1].val.cnt[0] = r - mid;
t[p].tag = 0;
}
}
void build(int p, int l, int r)
{
if (l == r)
{
t[p].val = make_vote(isa[l]);
return ;
}
int mid = (l + r) >> 1;
build(p << 1, l, mid);
build(p << 1 | 1, mid + 1, r);
maintain(p);
}
void change(int p, int l, int r, int x, int y, int v)
{
if (l > y || r < x) return ;
if (l >= x && r <= y)
{
t[p].tag = v;
t[p].val = make_vote(v);
t[p].val.cnt[0] = r - l + 1;
return ;
}
int mid = (l + r) >> 1;
spread(p, l, r);
if (mid >= x) change(p << 1, l, mid, x, y, v);
if (mid < y) change(p << 1 | 1, mid + 1, r, x, y, v);
maintain(p);
}
Major_Voting query(int p, int l, int r, int x, int y)
{
if (l > y || r < x) return make_vote(0);
if (l >= x && r <= y) return t[p].val;
int mid = (l + r) >> 1;
Major_Voting ret;
spread(p, l, r);
if (mid >= x) ret = merge(ret, query(p << 1, l, mid, x, y));
if (mid < y) ret = merge(ret, query(p << 1 | 1, mid + 1, r, x, y));
return ret;
} // 以上板子
signed main()
{
scanf("%d %d %d", &n, &m, &p);
assert(p >= 20 && p <= 100);
p = 100 / p;
for (int i = 1; i <= n; ++i) scanf("%d", &isa[i]);
build(1, 1, n);
for (int i = 0, t, l, r, x; i < m; ++i)
{
scanf("%d %d %d", &t, &l, &r);
if (t == 1)
{
scanf("%d", &x);
change(1, 1, n, l, r, x);
}
else
{
Major_Voting ans = query(1, 1, n, l, r);
printf("%d", p);
for (int i = 0; i < p; ++i) printf(" %d", ans.major[i]); // 因为题目的特殊性,我们可以随便乱输出
putchar('\n');
}
}
return 0;
}
60.P5071 [Ynoi2015]此时此刻的光辉
珂朵莉给你了一个长为 \(n\) 的序列,有 \(m\) 次查询,每次查询一段区间的乘积的约数个数 \(\bmod 19260817\) 的值。
我们知道一个结论:
若 \(n=\Pi_{i=1}^kp_i^{a_i}\)。
则 \(n\) 的约数个数为 \(\Pi_{i=1}^k(a_i+1)\)。
知道这个结论之后,我们就有一个 自 然 而 然 的想法:
用莫队维护每个质因数的出现次数和答案。
每加入或删除一个质因数,就先乘上它之前出现的次数加一的逆元,然后把出现次数加上或减去一之后再乘。
一算时间复杂度,每个数最多会有 \(9\) 个质因数,那么序列中会有 \(9\times 10^5\) 个数。莫队跑不过去。
但我们发现:小的质因数很多。我们可以抓住这一点进行优化。
由于只用知道每个质因数出现的次数就可以了。
我们可以把这些小的质因数都筛出来,做个前缀和,每次询问都单独统计乘上去。
这里我是把 \(\sqrt{10^9}\) 以内的质数都筛出来了(用来筛其他的大的质因数),然后把前 \(200\) 个的出现次数拿来做前缀和。
之前人傻了写线段树卡了半天常
代码:
#include<cstdio>
#include<vector>
#include<algorithm>
using namespace std;
#define lowbit(x) ((x)&(-(x)))
vector<int> p;
int prime[100010],cntot,tag[100010];
void search(int x)//线性筛质数
{
tag[1]=1;
for(int i=2;i<=x;++i)
{
if(!tag[i]) prime[++cntot]=i;
for(int j=1;j<=cntot&&prime[j]*i<=x;++j)
{
tag[i*prime[j]]=1;
if(i%prime[j]==0) break;
}
}
}
struct ask
{
int l,r,ID,lyc,wgy;//lyc和wgy表示这个询问在原序列上的左右端点,用来之后查询小的质因数的出现个数
}as[100010];
const int each=700,mod=19260817;
int n,m,a[100010],cnt[100010][201],nodes[100010][201],ton[201],pri[200010],belong[200010],ans[100010],in[100010],out[100010],inv[200010],tot,opl,opr,nowl,nowr,app[200010],cur=1;
bool cmp(ask one,ask ano)
{
if(belong[one.l]^belong[ano.l]) return belong[one.l]<belong[ano.l];
if(belong[one.l]&1) return one.r<ano.r;//奇偶排序
else return one.r>ano.r;
}
void read(int &hhh)
{
int x=0;
char c=getchar();
while((c<'0')|(c>'9')&&c^'-') c=getchar();
if(c^'-') x=c^'0';
char d=getchar();
while((d<='9')&(d>='0'))
{
x=(x<<1)+(x<<3)+(d^'0');
d=getchar();
}
if(c^'-') hhh=x;
else hhh=-x;
}
void writing(int x)
{
if(!x) return;
writing(x/10);
putchar((x%10)+'0');
}
void write(int x)
{
if(x<0)
{
putchar('-');
x=-x;
}
else if(!x)
{
putchar('0');
putchar('\n');
return;
}
writing(x);
putchar('\n');
}
int main()
{
read(n);
read(m);
search(33000);
for(int i=1;i^201;++i) ton[i]=prime[i];
for(int i=1;i<=n;++i)
{
read(a[i]);
in[i]=tot+1;//in[],out[]记录每个原序列的元素质因数在新的序列中的开头结尾
for(int j=1;j^201;++j)
{
while(a[i]%ton[j]==0)
{
a[i]/=ton[j];
++cnt[i][j];
}
}
if(a[i]>1)
{
for(int j=201;prime[j]*prime[j]<=a[i];++j)//把大的质因数拿出来作为一个新的序列
{
while(a[i]%prime[j]==0)
{
a[i]/=prime[j];
pri[++tot]=prime[j];
}
}
if(a[i]>1) pri[++tot]=a[i];
}
out[i]=tot;
}
inv[1]=1;
for(int i=2;i<=tot;++i) inv[i]=(((-(long long)(mod/i)*inv[mod%i])%mod)+mod)%mod;//线性处理逆元
for(int i=1;i<=tot;++i)
{
p.push_back(pri[i]);
belong[i]=(i-1)/each+1;
}
sort(p.begin(),p.end());
p.erase(unique(p.begin(),p.end()),p.end());
for(int i=1;i<=tot;++i) pri[i]=lower_bound(p.begin(),p.end(),pri[i])-p.begin()+1;
for(int i=1;i^201;++i)//对小的质因数做前缀和
{
for(int j=1;j<=n;++j) nodes[j][i]=nodes[j-1][i]+cnt[j][i];
}
for(int i=1;i<=m;++i)
{
read(opl);
read(opr);
as[i].l=in[opl];
as[i].r=out[opr];//莫队的询问左右端点,把原序列中查询区间的质因数全部覆盖掉。
as[i].ID=i;
as[i].lyc=opl;
as[i].wgy=opr;
}
sort(as+1,as+1+m,cmp);
nowl=1;
for(int i=1;i<=m;++i)
{
while(nowl>as[i].l)
{
--nowl;
cur=((long long)cur*inv[app[pri[nowl]]+1])%mod;//先乘上以前的逆元,消除之前的答案贡献
++app[pri[nowl]];
cur=((long long)cur*(app[pri[nowl]]+1))%mod;//乘上现在的答案贡献
}
while(nowr<as[i].r)
{
++nowr;
cur=((long long)cur*inv[app[pri[nowr]]+1])%mod;
++app[pri[nowr]];
cur=((long long)cur*(app[pri[nowr]]+1))%mod;
}
while(nowl<as[i].l)
{
cur=((long long)cur*inv[app[pri[nowl]]+1])%mod;
--app[pri[nowl]];
cur=((long long)cur*(app[pri[nowl]]+1))%mod;
++nowl;
}
while(nowr>as[i].r)
{
cur=((long long)cur*inv[app[pri[nowr]]+1])%mod;
--app[pri[nowr]];
cur=((long long)cur*(app[pri[nowr]]+1))%mod;
--nowr;
}
int tmp=cur;
for(int j=1;j^201;++j) tmp=((long long)tmp*(nodes[as[i].wgy][j]-nodes[as[i].lyc-1][j]+1))%mod;//临时乘上小的质因数对答案的贡献
ans[as[i].ID]=tmp;
}
for(int i=1;i<=m;++i) write(ans[i]);
return 0;
}

