Ds100p -「数据结构百题」31~40
31.P2163 [SHOI2007]园丁的烦恼]
很久很久以前,在遥远的大陆上有一个美丽的国家。统治着这个美丽国家的国王是一个园艺爱好者,在他的皇家花园里种植着各种奇花异草。
有一天国王漫步在花园里,若有所思,他问一个园丁道: “最近我在思索一个问题,如果我们把花坛摆成六个六角形,那么……”
“那么本质上它是一个深度优先搜索,陛下”,园丁深深地向国王鞠了一躬。
“嗯……我听说有一种怪物叫九头蛇,它非常贪吃苹果树……”
“是的,显然这是一道经典的动态规划题,早在N元4002年我们就已经发现了其中的奥秘了,陛下”。
“该死的,你究竟是什么来头?”
“陛下息怒,干我们的这行经常莫名其妙地被问到和OI有关的题目,我也是为了预防万一啊!” 王者的尊严受到了伤害,这是不可容忍的。
看来一般的难题是难不倒这位园丁的,国王最后打算用车轮战来消耗他的实力: “年轻人,在我的花园里的每一棵树可以用一个整数坐标来表示,一会儿,我的骑士们会来轮番询问你某一个矩阵内有多少树,如果你不能立即答对,你就准备走人吧!”说完,国王气呼呼地先走了。
这下轮到园丁傻眼了,他没有准备过这样的问题。所幸的是,作为“全国园丁保护联盟”的会长——你,可以成为他的最后一根救命稻草。
这道题拿到一看,第一个想法是二维树状数组。
单点修改,区间查询。
很标准的模板题嘛
这个数据范围可不模板……
就算离散化之后还剩\(500000*500000\)
连数组都开不下。
所以我们要寻找新的做法。
我们可以看到,所有的询问都会在修改的后面。
所以整个问题是静态的。
那么我们可以使用主席树来解决这个问题。
主席树第\(i\)个版本统计横坐标为\(1-i\)的所有树木的纵坐标在权值线段树上的体现。
这个权值线段树维护每个值域有多少个元素。
那么我们就可以在离散化后按照横坐标顺序插入。
查询时利用查分。只需要查询第\(xr\)个版本时和第\(xl-1\)个版本时\(yl\)到\(yr\)这个区间里有的元素个数,再相减就能得到答案了。
代码:
#include<cstdio>
#include<vector>
#include<algorithm>
using namespace std;
int n,m,root[1500010],s,e,tot;
struct tree
{
int x,y;
}tre[500010];
struct query
{
int X1,X2,Y1,Y2;
}q[500010];
struct node
{
int l,r,num;
}nodes[50000010];
vector<int> pril,prih,inslist[1500010];
void ins(int l,int r,int pre,int &now,int pos)
{
now=++tot;
nodes[now]=nodes[pre];
++nodes[now].num;
if(l^r)
{
int mid=(l+r)>>1;
if(pos<=mid) ins(l,mid,nodes[pre].l,nodes[now].l,pos);
else ins(mid+1,r,nodes[pre].r,nodes[now].r,pos);
}
}
int find(int l,int r,int v1,int v2,int fr,int ba)
{
if(l>ba||r<fr) return 0;
if(l>=fr&&r<=ba) return nodes[v2].num-nodes[v1].num;
int mid=(l+r)>>1;
return find(l,mid,nodes[v1].l,nodes[v2].l,fr,ba)+find(mid+1,r,nodes[v1].r,nodes[v2].r,fr,ba);
}
void read(int &hhh)
{
int x=0;
char c=getchar();
while((c<'0')|(c>'9')&&c^'-') c=getchar();
if(c^'-') x=c^'0';
char d=getchar();
while((d<='9')&(d>='0'))
{
x=(x<<1)+(x<<3)+(d^'0');
d=getchar();
}
if(c^'-') hhh=x;
else hhh=-x;
}
void writing(int x)
{
if(!x) return;
writing(x/10);
putchar((x%10)+'0');
}
void write(int x)
{
if(x<0)
{
putchar('-');
x=-x;
}
else if(!x)
{
putchar('0');
putchar('\n');
return;
}
writing(x);
putchar('\n');
}
int main()
{
read(n);
read(m);
for(int i=1;i<=n;++i)
{
read(tre[i].x);
read(tre[i].y);
pril.push_back(tre[i].x);
prih.push_back(tre[i].y);
}
for(int i=1;i<=m;++i)
{
read(q[i].X1);
read(q[i].Y1);
read(q[i].X2);
read(q[i].Y2);
--q[i].X1;
pril.push_back(q[i].X1);
prih.push_back(q[i].Y1);
pril.push_back(q[i].X2);
prih.push_back(q[i].Y2);
}
sort(pril.begin(),pril.end());
sort(prih.begin(),prih.end());
pril.erase(unique(pril.begin(),pril.end()),pril.end());
prih.erase(unique(prih.begin(),prih.end()),prih.end());
s=prih.size();
e=pril.size();
for(int i=1;i<=n;++i)
{
tre[i].x=lower_bound(pril.begin(),pril.end(),tre[i].x)-pril.begin()+1;
tre[i].y=lower_bound(prih.begin(),prih.end(),tre[i].y)-prih.begin()+1;
inslist[tre[i].x].push_back(tre[i].y);
}
for(int i=1;i<=m;++i)
{
q[i].X1=lower_bound(pril.begin(),pril.end(),q[i].X1)-pril.begin()+1;
q[i].Y1=lower_bound(prih.begin(),prih.end(),q[i].Y1)-prih.begin()+1;
q[i].X2=lower_bound(pril.begin(),pril.end(),q[i].X2)-pril.begin()+1;
q[i].Y2=lower_bound(prih.begin(),prih.end(),q[i].Y2)-prih.begin()+1;
}
for(int i=1;i<=e;++i)
{
root[i]=root[i-1];
int WHILEMAX=inslist[i].size();
for(int j=0;j^WHILEMAX;++j) ins(1,s,root[i],root[i],inslist[i][j]);
}
for(int i=1;i<=m;++i) write(find(1,s,root[q[i].X1],root[q[i].X2],q[i].Y1,q[i].Y2));
return 0;
}
32.P2471 [SCOI2007]降雨量
我们常常会说这样的话:“X年是自Y年以来降雨量最多的”。它的含义是X年的降雨量不超过Y年,且对于任意Y<Z<X,Z年的降雨量严格小于X年。例如2002,2003,2004和2005年的降雨量分别为4920,5901,2832和3890,则可以说“2005年是自2003年以来最多的”,但不能说“2005年是自2002年以来最多的”由于有些年份的降雨量未知,有的说法是可能正确也可以不正确的。
这道题要求查询一个数是否是继另一个数后的最大值。
然而中间有很多数是未知的。
要判断这个结论一定成立,我们要知道中间的数是不是都知道。
那我们是不是要把所有的数都放进线段树里呢?
肯定不行,因为年份的范围是\(1e9\)。
那我们怎么离散化呢?
这里我们只用把与每个年份相邻的两个年份也加进来就好了,再顺便把查询的端点和往内一个数也加进来,不然找端点的时候容易锅……
因为如果查询时这里没有数,那么肯定就被查到了。
如果这里有,那么这里的这个数就会又把它两边的数加进来。一直到要查询到的那个数为止。
那么我们应该怎么判断呢?
这里就要分类讨论了:查询为\((p,q)\)
\(1.p > q\):肯定不成立,他们的位置都不对,\(p\)根本不在\(q\)前面。
\(2.p=q\):显然成立。
\(3.\)继续分类。
$\ \ \ \ \ $$1).$两个端点都已知。
$\ \ \ \ \ \ \ \ \ \ $$1>.$$p\(的降雨量小于\)q$:肯定不对,不符合定义。
$\ \ \ \ \ \ \ \ \ \ $$2>.\(如果\)p,q\(中间有数比\)q$的降雨量大或等于:也不符合定义,不对。
$\ \ \ \ \ \ \ \ \ \ $$3>.\(如果\)p,q\(中间有数未知:那么我们无法确定这些未知的数是否小于\)q$的降雨量,输出也许。
$\ \ \ \ \ \ \ \ \ \ $$4>.$以上条件均不满足:说明满足了所有条件,是对的。
$\ \ \ \ \ $$2).\(知道\)p$的降雨量。
$\ \ \ \ \ \ \ \ \ \ $$1>.\(如果\)p,q\(中间有数大于\)p$的降雨量或等于:不符合定义,不对。
$\ \ \ \ \ \ \ \ \ \ $$2>.\(否则无论中间是否全部已知,由于\)q$未知,都不能确定。
$\ \ \ \ \ $$3).\(知道\)q$的降雨量。
$\ \ \ \ \ \ \ \ \ \ $$1>.\(如果\)p,q\(中间有数大于\)q$的降雨量或等于:不符合定义,不对。
$\ \ \ \ \ \ \ \ \ \ $$2>.\(否则无论中间是否全部已知,由于\)p$未知,都不能确定。
$\ \ \ \ \ $$4).$两个都未知:无论中间是否全部已知,由于不能确定中间的数是否小于他们,所以输出也许。
关于判断中间是否有数大于某数,我们需要查询中间的最大值。
关于判断中间是否有数未知,我们需要查询区间里有多少数。
所以我们要开两棵线段树,一棵记录区间最大值,一棵记录区间里的元素个数。
代码:
#include<map>
#include<cstdio>
#include<vector>
#include<algorithm>
using namespace std;
vector<int> pri;
map<int,int> mp;
int n,m,s,y[50010],r[50010],p[10010],q[10010],siz[1000010],nodes[1000010];
int getID(int val)
{
return lower_bound(pri.begin(),pri.end(),val)-pri.begin()+1;
}
void ins(int l,int r,int x,int pos,int val)
{
++siz[x];
if(l==r) nodes[x]=val;
else
{
int mid=(l+r)>>1;
if(pos<=mid) ins(l,mid,x<<1,pos,val);
else ins(mid+1,r,x<<1|1,pos,val);
nodes[x]=max(nodes[x<<1],nodes[x<<1|1]);
}
}
int findsiz(int l,int r,int x,int fr,int ba)
{
if(l>ba||r<fr) return 0;
if(l>=fr&&r<=ba) return siz[x];
else
{
int mid=(l+r)>>1;
return findsiz(l,mid,x<<1,fr,ba)+findsiz(mid+1,r,x<<1|1,fr,ba);
}
}
int findmax(int l,int r,int x,int fr,int ba)
{
if(l>ba||r<fr) return 0;
if(l>=fr&&r<=ba) return nodes[x];
else
{
int mid=(l+r)>>1;
return max(findmax(l,mid,x<<1,fr,ba),findmax(mid+1,r,x<<1|1,fr,ba));
}
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;++i)
{
scanf("%d %d",&y[i],&r[i]);
pri.push_back(y[i]-1);
pri.push_back(y[i]);
pri.push_back(y[i]+1);
mp[y[i]]=r[i];
}
scanf("%d",&m);
for(int i=1;i<=m;++i)
{
scanf("%d %d",&p[i],&q[i]);
pri.push_back(p[i]);
pri.push_back(p[i]+1);
pri.push_back(q[i]);
pri.push_back(q[i]-1);
}
sort(pri.begin(),pri.end());
pri.erase(unique(pri.begin(),pri.end()),pri.end());
s=pri.size();
for(int i=1;i<=n;++i) ins(1,s,1,getID(y[i]),r[i]);
for(int i=1;i<=m;++i)
{
int L=getID(p[i]);
int R=getID(q[i]);
if(p[i]>q[i]) printf("false\n");
else if(p[i]==q[i]) printf("true\n");
else if(mp[p[i]]&&mp[q[i]])
{
if(mp[p[i]]<mp[q[i]]) printf("false\n");
else
{
if(findmax(1,s,1,L+1,R-1)<mp[q[i]])
{
if(findsiz(1,s,1,L,R)==R-L+1) printf("true\n");
else printf("maybe\n");
}
else printf("false\n");
}
}
else if(mp[p[i]])
{
if(findmax(1,s,1,L+1,R)>=mp[p[i]]) printf("false\n");
else printf("maybe\n");
}
else if(mp[q[i]])
{
if(findmax(1,s,1,L,R-1)>=mp[q[i]]) printf("false\n");
else printf("maybe\n");
}
else printf("maybe\n");
}
return 0;
}
33.P2824 [HEOI2016/TJOI2016]排序
在 \(2016\) 年,佳媛姐姐喜欢上了数字序列。因而她经常研究关于序列的一些奇奇怪怪的问题,现在她在研究一个难题,需要你来帮助她。
这个难题是这样子的:给出一个 \(1\) 到 \(n\) 的排列,现在对这个排列序列进行 \(m\) 次局部排序,排序分为两种:
0 l r表示将区间 \([l,r]\) 的数字升序排序1 l r表示将区间 \([l,r]\) 的数字降序排序
注意,这里是对下标在区间 \([l,r]\) 内的数排序。
最后询问第 \(q\) 位置上的数字。
这道题很有意思,需要一定的技巧。
首先我们知道,对于一个长度为 \(n\) 整数序列排序需要 \(\Theta(n\log n)\) 的时间。
但是,如果我们把序列中的数字从所有的数转移到0和1两个数上,是不是就容易很多呢?
对于一个01串升序排序显然只需要 \(\Theta(n)\) 的时间。我们只需要统计出序列中所以1的个数 \(cnt\)。
然后把 \(A_{i},i\in [1,n-cnt]\) 改为零,把 \(A_{i},i\in [n-cnt+1,n]\) 改为1即可。
降序排序则完全同理。
不仅如此,我们还可以把时间从 \(\Theta(n)\) 降到 \(\Theta(\log n)\)。
我们可以把统计区间中1的个数看作区间求和,那么我们就可以用线段树来维护区间赋值和区间求和的操作,复杂度 \(\Theta(\log n)\)。
好,接下来我们思考一个问题——如何把一个普通的序列转化为01序列呢?我们可以按大小来划分。
假设我们现在正在二分,那么我们不妨把所有大于等于 \(mid\) 的数置为1,否则置为0。这样整个序列就变成了一个01序列。
排序后判断第 \(q\) 个位置是不是1就行了。
这里还有一个问题——为什么这个二分是满足单调性的呢?
其实这个问题很简单,就留给大家吧)))
#pragma GCC diagnostic error "-std=c++11"
#include <cstdio>
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
char buf[1 << 21], *p1 = buf, *p2 = buf;
#ifndef ONLINE_JUDGE
#define gc() getchar()
#else
#define gc() (p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 1 << 21, stdin), p1 == p2) ? EOF : *p1++)
#endif
#define is_number (ch >= '0' && ch <= '9')
template < typename Type >
void read(Type& a) {
a = 0; bool f = 0; char ch;
while (!(ch = gc(), is_number)) if (ch == '-') f = 1;
while (is_number) a = (a << 3) + (a << 1) + (ch ^ '0'), ch = gc();
a = (f ? -a : a);
}
template < typename Type, typename... Args >
void read(Type& t, Args&... args) {
read(t), read(args...);
}
#define ls (k << 1)
#define rs (k << 1 | 1)
// #define mid ((l + r) >> 1)
const int MAXN = 1e5 + 5;
int nodes[MAXN << 2];
int marks[MAXN << 2];
int ints[MAXN], bit[MAXN];
int n, m, q;
struct QueryNode {
int l, r;
int type;
QueryNode(){}
QueryNode(int L, int R, int T) : l(L), r(R), type(T) {}
} asks[MAXN];
void pushdown(int k, int l, int r) {
if (~marks[k]) {
int mid = (l + r) >> 1;
nodes[ls] = (mid - l + 1) * marks[k];
marks[ls] = marks[k];
nodes[rs] = (r - mid) * marks[k];
marks[rs] = marks[k];
marks[k] = -1;
}
}
void construct(int k, int l, int r) {
int mid = ((l + r) >> 1);
if (l ^ r) {
construct(ls, l, mid);
construct(rs, mid + 1, r);
nodes[k] = nodes[ls] + nodes[rs];
}
else
nodes[k] = bit[l];
}
void update(int k, int l, int r, int x, int y, int v) {
int mid = ((l + r) >> 1);
if (l > y || r < x) return ;
if (l >= x && r <= y) nodes[k] = (r - l + 1) * v, marks[k] = v;
else {
pushdown(k, l, r);
if (mid >= x) update(ls, l, mid, x, y, v);
if (mid < y) update(rs, mid + 1, r, x, y, v);
nodes[k] = nodes[ls] + nodes[rs];
}
}
int queryf(int k, int l, int r, int x, int y) {
int mid = ((l + r) >> 1);
pushdown(k, l, r);
if (l > y || r < x) return 0;
else if (l >= x && r <= y) return nodes[k];
else return queryf(ls, l, mid, x, y) + queryf(rs, mid + 1, r, x, y);
}
bool check(int x) {
for (int i = 1; i <= n; ++i) bit[i] = (ints[i] >= x);
memset(marks, -1, sizeof marks);
memset(nodes, 0, sizeof nodes);
construct(1, 1, n);
for (int i = 1; i <= m; ++i) {
int sum = queryf(1, 1, n, asks[i].l, asks[i].r);
if (asks[i].type == 1) update(1, 1, n, asks[i].l, asks[i].l + sum - 1, 1), update(1, 1, n, asks[i].l + sum, asks[i].r, 0);
else update(1, 1, n, asks[i].l, asks[i].r - sum, 0), update(1, 1, n, asks[i].r - sum + 1, asks[i].r, 1);
}
return queryf(1, 1, n, q, q);
}
signed main() {
read(n, m);
for (int i = 1; i <= n; ++i) read(ints[i]);
for (int i = 1; i <= m; ++i) read(asks[i].type, asks[i].l, asks[i].r);
read(q);
int l = 1, r = n, ans = 0;
while (l <= r) {
int mid = ((l + r) >> 1);
if (check(mid)) l = mid + 1, ans = mid;
else r = mid - 1;
}
printf("%d\n", ans);
return 0;
}
34.P1712 [NOI2016]区间
在数轴上有 \(N\) 个闭区间 \([l_1,r_1],[l_2,r_2],...,[l_n,r_n]\) 。现在要从中选出 \(M\) 个区间,使得这 \(M\) 个区间共同包含至少一个位置。换句话说,就是使得存在一个 \(x\) ,使得对于每一个被选中的区间\([l_i,r_i]\) ,都有 \(l_i≤x≤r_i\) 。
对于一个合法的选取方案,它的花费为被选中的最长区间长度减去被选中的最短区间长度。区间\([l_i,r_i]\) 的长度定义为\(r_i-l_i\) ,即等于它的右端点的值减去左端点的值。
求所有合法方案中最小的花费。如果不存在合法的方案,输出 \(-1\) 。
题意简述
题意已经很清楚了,就不再说了
题解
我们首先考虑怎么去选择这 \(M\) 个区间才能使得最终的花费最小。
不难想到我们需要尽量选择 长度尽量靠近 的 \(M\) 个区间,换句话说就是我们需要按照区间的长度进行排序。
原因很显然,我们如果选择的区间的长度不靠近,那么就会造成最小的区间长度变小,最大的区间长度变大。然而答案就是长度最大的区间和长度最小的区间,所以我们需要让这两个区间的长度尽量靠近。
排完序后我们就依次把每个区间加入到答案所在的集合里。
具体来说就是维护一个数组 \(A\),每当我们加入一个区间 \([l_{i},r_{i}]\),就令 \(A_{l_{i}},A_{l_{i}+1},\cdots,A_{r_{i}}\) 全部加一。如果存在某一个 \(A_{p}\) 使得 \(M\le A_{p}\),我们就更新答案,并且删除最先加入进来的区间,也就是令 \(A_{l_{i}},A_{l_{i}+1},\cdots,A_{r_{i}}\) 全部减一。
一些细节:
-
要离散化(废话
-
线段树开8倍(每个区间有两个端点
-
没了
#include <cstdio>
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
using namespace std;
const int SIZE = 500000 + 5;
int MAX[SIZE << 3];
int mark[SIZE << 3];
vector < int > disc;
int n, m, holyans = -1;
struct interval {
int l, r;
int len;
interval(){}
interval(int L, int R, int S) : l(L), r(R), len(S){}
bool operator < (const interval& rhs) const {
return len < rhs.len;
}
} seg[SIZE];
#define ls (k << 1)
#define rs (k << 1 | 1)
#define mid ((l + r) >> 1)
#define pushdown(k) \
if (mark[k]) { \
MAX[ls] += mark[k]; \
MAX[rs] += mark[k]; \
mark[ls] += mark[k]; \
mark[rs] += mark[k]; \
mark[k] = 0; \
}
#define pushup(k) MAX[k] = max(MAX[ls], MAX[rs])
#define GetID(x) (lower_bound(disc.begin(), disc.end(), x) - disc.begin() + 1)
void modify(int k, int l, int r, int x, int y, int v) {
if (l >= x && r <= y) mark[k] += v, MAX[k] += v;
else {
pushdown(k);
if (mid >= x) modify(ls, l, mid, x, y, v);
if (mid < y) modify(rs, mid + 1, r, x, y, v);
pushup(k);
}
}
void discretization() {
for (int i = 1; i <= n; ++i) disc.push_back(seg[i].l), disc.push_back(seg[i].r);
sort(disc.begin(), disc.end());
sort(seg + 1, seg + 1 + n);
disc.erase(unique(disc.begin(), disc.end()), disc.end());
for (int i = 1; i <= n; ++i) seg[i].l = GetID(seg[i].l), seg[i].r = GetID(seg[i].r);
}
signed main() {
scanf("%d %d", &n, &m);
for (int i = 1, x, y; i <= n; ++i) scanf("%d %d", &x, &y), seg[i] = interval(x, y, y - x + 1);
discretization();
int size = disc.size();
int max_id = n;
for (int i = n; i >= 1; --i) {
while (MAX[1] >= m && max_id > i) {
modify(1, 1, size, seg[max_id].l, seg[max_id].r, -1);
--max_id;
if (MAX[1] >= m) {
if (~holyans) holyans = min(holyans, seg[max_id].len - seg[i].len);
else holyans = seg[max_id].len - seg[i].len;
}
}
modify(1, 1, size, seg[i].l, seg[i].r, 1);
if (MAX[1] >= m) {
if (~holyans) holyans = min(holyans, seg[max_id].len - seg[i].len);
else holyans = seg[max_id].len - seg[i].len;
}
}
printf("%d\n", holyans);
return 0;
}
35.P5524 [Ynoi2012]NOIP2015洋溢着希望
给出一个长度为 \(n\) 的整数序列 \(a_1,a_2,\ldots,a_n\),进行 \(m\) 次操作,操作分为两类。
操作 \(1\):给出 \(l,r,v\),将 \(a_l,a_{l+1},\ldots,a_r\) 分别加上 \(v\)。
操作 \(2\):给出 \(l,r\),询问 \(\sum\limits_{i=l}^{r}\sin(a_i)\)。
唯一一道我能做的Ynoi……
修改操作很模板,略。
对于询问,直接维护是不理智的。相信大家都学过三角函数,和差角公式应该很熟悉。
对于这道题我们可以用这两个公式来维护询问:
这样,我们再维护一个加法标记,就能解决询问了。
挺水的对吧。
#include <cstdio>
#include <iostream>
#include <algorithm>
#include <cstring>
#include <queue>
#include <cmath>
using namespace std;
const int MAXN = 2e5 + 5;
int n, m, integer[MAXN];
long long nodes[MAXN << 2];
double sum_sinx[MAXN << 2];
double sum_cosx[MAXN << 2];
#define ls (k << 1)
#define rs (k << 1 | 1)
#define mid ((l + r) >> 1)
void update(int k, double sinx, double cosx) {
double tsum_sinx = sum_sinx[k];
double tsum_cosx = sum_cosx[k];
sum_sinx[k] = tsum_sinx * cosx + tsum_cosx * sinx;
sum_cosx[k] = tsum_cosx * cosx - tsum_sinx * sinx;
}
void pushup(int k) {
sum_sinx[k] = sum_sinx[ls] + sum_sinx[rs];
sum_cosx[k] = sum_cosx[ls] + sum_cosx[rs];
}
void pushdown(int k) {
if (nodes[k]) {
nodes[ls] += nodes[k];
nodes[rs] += nodes[k];
double t_sinx = sin(nodes[k]);
double t_cosx = cos(nodes[k]);
nodes[k] = 0;
update(ls, t_sinx, t_cosx);
update(rs, t_sinx, t_cosx);
}
}
void build(int k, int l, int r) {
if (l ^ r) build(ls, l, mid), build(rs, mid + 1, r), pushup(k);
else sum_sinx[k] = sin(integer[l]), sum_cosx[k] = cos(integer[l]);
}
void modify(int k, int l, int r, int x, int y, int v, double sinx, double cosx) {
if (l >= x && r <= y) update(k, sinx, cosx), nodes[k] += v;
else {
pushdown(k);
if (mid >= x) modify(ls, l, mid, x, y, v, sinx, cosx);
if (mid < y) modify(rs, mid + 1, r, x, y, v, sinx, cosx);
pushup(k);
}
}
double queryf(int k, int l, int r, int x, int y) {
if (l >= x && r <= y) return sum_sinx[k];
else {
pushdown(k);
double res = 0;
if (mid >= x) res += queryf(ls, l, mid, x, y);
if (mid < y) res += queryf(rs, mid + 1, r, x, y);
return res;
}
}
signed main() {
scanf("%d", &n);
for (int i = 1; i <= n; ++i) scanf("%d", &integer[i]);
build(1, 1, n);
scanf("%d", &m);
for (int i = 0, opt, x, y, v; i < m; ++i) {
scanf("%d %d %d", &opt, &x, &y);
if (opt == 1) scanf("%d", &v), modify(1, 1, n, x, y, v, sin(v), cos(v));
else printf("%.1lf\n", queryf(1, 1, n, x, y));
}
return 0;
}
36.P5335 [THUSC2016]补退选
X 是 T 大的一名老师,每年他都要教授许多学生基础的 C++ 知识。在 T 大,每个学生在每学期的开学前都需要选课,每次选课一共分为三个阶段:预选,正选,补退选;其中「补退选」阶段最忙碌。
在补退选阶段,学生即可以选课,也可以退课。对于X老师来说,在补退选阶段可能发生以下两种事件:
1.一个姓名为 \(S\) 的学生选了他的课(姓名将出现在 X 的已选课学生名单中)
2.一个姓名为 \(S\) 的学生退了他的课(姓名将从 X 的已选课学生名单中移除)
同时,X 老师对于有哪些学生选了他的课非常关心,所以他会不定时的查询已选课学生名单,每次查询的格式如下:
最早在哪个事件之后,姓名以 S 为前缀的学生数量超过了 v
X老师看你骨骼惊奇,所以想用这个问题考考你,你当然不会畏惧,所以勇敢的接下了这个任务。
注意1:学生的姓名可能相同,如果有\(p\)个姓名相同的学生都选了X老师的课,则他们的姓名将出现在X老师的名单上\(p\)次。
注意2:只有已经选了课的学生才会退课,如果姓名为\(S\)的学生退课,则在他退课之前X老师的名单上一定有姓名。
注意3:选课,退课和查询都被定义为「事件」,「事件」的编号从 1 开始
题意简述
给定插入、删除字符串的操作,查询在最早哪一时刻以 \(S\) 为前缀的字符串数量超过了某一个值。
题解
字符串+前缀一眼就trie树了嘛。
插入和删除都是常规的trie,可以维护一个sum来统计。
如果某一时刻的sum超过了vector统计的size,那么就push进去。
查询的话就暴力查询。如果在某一个字符的统计少于了 \(k\) 那么就不可能了。
总结来说,这是一道比较水而且典型的trie树练习题。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e6 + 5;
int n, tot, lastans = 0;
struct TrieNode {
int frie, ch[30];
vector < int > rec;
} trie[N];
void Insert(char str[], int ts) {
int root = 0;
for (int i = 0; str[i]; ++i) {
int now = str[i] - 'a';
if (!trie[root].ch[now]) trie[root].ch[now] = ++tot;
root = trie[root].ch[now];
trie[root].frie++;
if (trie[root].frie > (int)trie[root].rec.size()) trie[root].rec.push_back(ts);
}
}
void Delete(char str[], int ts) {
int root = 0;
for (int i = 0; str[i]; ++i) {
int now = str[i] - 'a';
if (!trie[root].ch[now]) trie[root].ch[now] = ++tot;
root = trie[root].ch[now];
trie[root].frie--;
if (trie[root].frie >= (int)trie[root].rec.size()) trie[root].rec.push_back(ts);
}
}
int Queryf(char str[], long long k) {
int root = 0;
for (int i = 0; str[i]; ++i) {
int now = str[i] - 'a';
root = trie[root].ch[now];
if ((long long)trie[root].rec.size() <= k) return -1;
}
return trie[root].rec[k];
}
signed main() {
scanf("%d", &n);
for (int i = 1, opr, a, b, c; i <= n; ++i) {
char str[N];
scanf("%d %s", &opr, str);
if (opr == 1) Insert(str, i);
else if (opr == 2) Delete(str, i);
else scanf("%d %d %d", &a, &b, &c), printf("%d\n", lastans = Queryf(str, (1LL * a * abs(lastans) + 1LL * b) % (1LL * c)));
}
return 0;
}
37.P4309 【[TJOI2013]最长上升子序列】
给定一个序列,初始为空。现在我们将1到N的数字插入到序列中,每次将一个数字插入到一个特定的位置。每插入一个数字,我们都想知道此时最长上升子序列长度是多少?
Description
动态维护LIS
Solution
这道题正解应该是在平衡树上维护dp。
设 \(dp_{i}\) 表示前 \(i\) 个数的LIS长度,转移方程显然为:
这东西都不知道可以考虑$\ \ \ \ \ \ \ \ \ \ \ $了
然后我们放到维护的节点上即可。
开头说过平衡树对吧,但是这道题的数据过水,vector+bit直接能过,而且跑得飞快,管理如果有心情的话就加强一下吧。
#include <bits/stdc++.h>
const int N = 100000 + 5;
int n, p[N], ans[N], bit[N];
std::vector < int > vec;
void update(int x, int y) {
for (; x <= n; x += x & -x) bit[x] = std::max(bit[x], y);
}
int queryf(int x) {
int res = 0;
for (; x; x -= x & -x) res = std::max(res, bit[x]);
return res;
}
signed main() {
scanf("%d", &n);
for (int i = 1; i <= n; ++i) scanf("%d", &p[i]), vec.insert(p[i] + vec.begin(), i);
for (int i = 1; i <= n; ++i) ans[vec[i - 1]] = queryf(vec[i - 1]) + 1, update(vec[i - 1], ans[vec[i - 1]]);
for (int i = 1; i <= n; ++i) ans[i] = std::max(ans[i], ans[i - 1]);
for (int i = 1; i <= n; ++i) printf("%d\n", ans[i]);
return 0;
}
38.CF85D Sum of Medians
一个集合,初始为空。现有三个操作:
1.add:向集合里加入数x,保证加入前集合中没有数x;
2.del:从集合中删除数x,保证删除前集合中有x;
3.sum:询问将集合里的数从小到大排序后,求下标i模5余3的数的和。
现有n次操作,对于每个查询操作,输出答案
Description
让你维护一个类似std::set的东西,实现一个支持插入、删除、查询升序排序后的 \(\sum_{i=1}^{n}[i\operatorname{mod}5=3]\times A_{i}\) 的不可重集合。
Solution
正解线段树没跑。但是我们看到3S的时限 \(10^{5}\) 的数据以及一贯的CF数据。我们有理由认为这道题vector模拟能过(滑稽
然后就真的能过,std::lower_bound查找插入以及删除的位置。查询的话就 \(i\) 从2开始(vector下标从0开始,所以要减一),每次 \(i=i+5\) 然后累加 \(A_{i}\) 即可。
#include <bits/stdc++.h>
std::vector < int > vect;
signed main() {
int n;
scanf("%d", &n);
for (int i = 0, x; i < n; ++i) {
char str[5];
scanf("%s", str);
if (*str == 'a') {
scanf("%d", &x);
vect.insert(std::lower_bound(vect.begin(), vect.end(), x), x);
} else if (*str == 'd') {
scanf("%d", &x);
vect.erase(std::lower_bound(vect.begin(), vect.end(), x));
} else {
long long res = 0;
for (unsigned i = 2; i < vect.size(); i += 5) res += vect[i];
printf("%lld\n", res);
}
}
return 0;
}
39.P3620 [APIO/CTSC 2007]数据备份
你在一家 IT 公司为大型写字楼或办公楼(offices)的计算机数据做备份。然而数据备份的工作是枯燥乏味的,因此你想设计一个系统让不同的办公楼彼此之间互相备份,而你则坐在家中尽享计算机游戏的乐趣。
已知办公楼都位于同一条街上。你决定给这些办公楼配对(两个一组)。每一对办公楼可以通过在这两个建筑物之间铺设网络电缆使得它们可以互相备份。
然而,网络电缆的费用很高。当地电信公司仅能为你提供 K 条网络电缆,这意味着你仅能为 K 对办公楼(或总计 2K 个办公楼)安排备份。任一个办公楼都属于唯一的配对组(换句话说,这 2K 个办公楼一定是相异的)。
此外,电信公司需按网络电缆的长度(公里数)收费。因而,你需要选择这 K对办公楼使得电缆的总长度尽可能短。换句话说,你需要选择这 K 对办公楼,使得每一对办公楼之间的距离之和(总距离)尽可能小。
下面给出一个示例,假定你有 5 个客户,其办公楼都在一条街上,如下图所示。这 5 个办公楼分别位于距离大街起点 1km, 3km, 4km, 6km 和 12km 处。电信公司仅为你提供 K=2 条电缆。
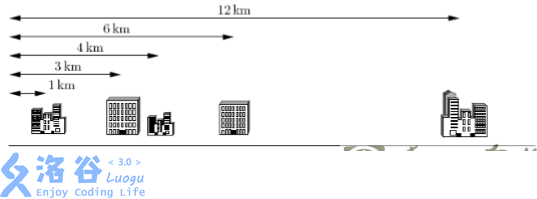
上例中最好的配对方案是将第 1 个和第 2 个办公楼相连,第 3 个和第 4 个办公楼相连。这样可按要求使用 K=2 条电缆。第 1 条电缆的长度是 3km―1km = 2km,第 2 条电缆的长度是 6km―4km = 2 km。这种配对方案需要总长 4km 的网络电缆,满足距离之和最小的要求。
题意简述
给定 \(n\) 栋建筑,选出 \(k\) 对,使其距离之和最小。
题解
可以想见,这 \(k\) 对建筑每对都是相邻的。我们设 \(L_{i}=A_{i}-A_{i-1}\),其中 \(A_{i}\) 为题目中输入的序列。即 \(L\) 为 \(A\) 的差分序列。
由于已经被选过的位置不能再次被选,所以如果我们选了 \(L_{i}\) 那么 \(L_{i+1}\) 和 \(L_{i-1}\) 都不能选了。如果我们选了 \(L_{i+1}\) 和 \(L_{i-1}\) 那么我们也不能选 \(L_{i}\) 了。
我们设 \(L\) 中的最小值为 \(L_{m}\)。考虑当前情况的每一个最优解,则只有以下两种情形:
-
选 \(L_{m}\)
-
选 \(L_{m+1}\) 和 \(L_{m-1}\)
如此我们得到了一个策略:每次选择 \(L\) 中的最小值即 \(L_{m}\),然后删除 \(L_{m},L_{m-1},L_{m+1}\)。如果我们选择了 \(L_{m+1}+L_{m-1}-L_{m}\) 的话,即删除 \(L_{m}\),选择 \(L_{m}\)。否则即认为选择 \(L_{m}\) 是当前的最优策略。
思路来自李煜东的蓝书。
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5 + 5;
int n, k, tot, rhs, ans, dis[N], lists[N];
struct ListNode {
struct LinkList {
int prev, next;
int val, id;
} p[N];
void remove(int x) {
p[p[x].prev].next = p[x].next;
p[p[x].next].prev = p[x].prev;
}
} list;
struct HeapNode {
struct Heap {
int val, id;
} h[N];
void upward(int x) {
while (x > 1) {
if (h[x].val < h[x >> 1].val) {
swap(h[x], h[x >> 1]);
swap(list.p[h[x].id].id, list.p[h[x >> 1].id].id);
x >>= 1;
}
else break;
}
}
void downward(int x) {
int s = x << 1;
while (s <= tot) {
if (s < tot && h[s].val > h[s + 1].val) ++s;
if (h[s].val < h[x].val) {
swap(h[s], h[x]);
swap(list.p[h[s].id].id, list.p[h[x].id].id);
x = s;
s = x << 1;
}
else break;
}
}
void remove(int x) {
if (x == --tot + 1) return ;
swap(h[x], h[tot + 1]);
swap(list.p[h[x].id].id, list.p[h[tot + 1].id].id);
upward(x);
downward(x);
}
void extract(int x) {
h[1] = h[n--];
downward(1);
}
int backtop() {
return h[1].val;
}
} heap;
signed main() {
scanf("%d %d %d", &n, &k, &rhs);
for (int i = 1; i < n; ++i) {
int x; scanf("%d", &x);
list.p[i].val = x - rhs;
list.p[i].prev = i - 1;
list.p[i].next = i + 1;
list.p[i].id = ++tot;
rhs = x;
heap.h[tot].val = list.p[i].val;
heap.h[tot].id = i;
heap.upward(tot);
}
for (int i = 1; i <= k; ++i) {
ans += heap.backtop();
if (!list.p[heap.h[1].id].prev || list.p[heap.h[1].id].next == n) {
if (!list.p[heap.h[1].id].prev) {
heap.remove(list.p[list.p[heap.h[1].id].next].id);
list.remove(list.p[heap.h[1].id].next);
}
else {
heap.remove(list.p[list.p[heap.h[1].id].prev].id);
list.remove(list.p[heap.h[1].id].prev);
}
list.remove(heap.h[1].id);
heap.remove(1);
}
else {
int temp = heap.h[1].id;
heap.h[1].val = list.p[list.p[heap.h[1].id].prev].val + list.p[list.p[heap.h[1].id].next].val - list.p[heap.h[1].id].val;
list.p[heap.h[1].id].val = heap.h[1].val;
heap.downward(1);
heap.remove(list.p[list.p[temp].prev].id);
heap.remove(list.p[list.p[temp].next].id);
list.remove(list.p[temp].prev);
list.remove(list.p[temp].next);
}
}
printf("%d\n", ans);
return 0;
}
40.P3793 由乃救爷爷
读入三个数n,m,s
你需要srand( s )一下
然后n个数表示a[i],这个直接调用read函数
然后m个询问,表示区间最大值,询问的区间是l = read() % n + 1 , r = read() % n + 1,注意有可能 l > r
题意简述
给定序列,求每次询问区间的RMQ。
题解
不带修的RMQ我们一般使用的是ST表求。但这道题ST表 \(\Theta(n\log n)\) 的空间当场去世。
我们考虑把序列分个块儿。由于查询的区间不一定会完全覆盖完一个块儿,所以我么需要求出每个块儿中的前/后缀最大值,然后用ST表搞出整个块儿的最大值。
但是如果 \(l,r\) 在同一个块儿内的话就会出问题,所以当查询区间的两端点在同一个块儿内的时候我们就直接暴力查询。
const int N = 2e7 + 5;
const int SQN = 4500 + 5;
const int LGSQN = 10 + 5;
int n, m, s, block = 7500;
__uint64 f[SQN][LGSQN], a[N];
__uint64 ans, cpy[N], pas[N];
__uint64 get(__uint64 x) {
return (x + block - 1) / block;
}
__uint64 ret(__uint64 l, __uint64 r) {
__uint64 res = a[l];
for (__uint64 i = l; i <= r; ++i) res = max(res, a[i]);
return res;
}
signed main() {
read(n, m, s);
_srand(s);
for (int i = 1, j = 1; i <= n; ++i, j = get(i)) {
a[i] = _read();
f[j][0] = max(a[i], f[j][0]);
}
int mot = get(n);
int fck = log2(mot);
for (int j = 1; j <= fck; ++j)
for (int i = 1; i <= mot - (1 << j) + 1; ++i)
f[i][j] = max(f[i][j - 1], f[i + (1 << (j - 1))][j - 1]);
for (int i = 1; i <= n; ++i)
if (i % block != 1) pas[i] = max(pas[i - 1], a[i]);
else pas[i] = a[i];
for (int i = n; i >= 1; --i)
if (i % block) cpy[i] = max(cpy[i + 1], a[i]);
else cpy[i] = a[i];
for (int i = 0; i < m; ++i) {
__uint64 x = _read() % n + 1;
__uint64 y = _read() % n + 1;
if (x > y) swap(x, y);
__uint64 l = get(x), r = get(y);
__uint64 MAX = max(cpy[x], pas[y]);
if (l == r) ans += ret(x, y);
else if (r - l == 1) ans += MAX;
else {
__uint64 k = log2(r - l - 1);
__uint64 t = max(f[l + 1][k], f[r - (1 << k)][k]);
ans += max(MAX, t);
}
}
write(io_l, ans);
}
