CMU15-445:Lecture #10 笔记
Lecture #10: Sorting & Aggregation Algorithms
本文是对CMU15-445课程第10节笔记的一个粗略总结和翻译。仅供个人(M1kanN)复习使用。
1. Sorting
- DBMS需要对数据进行排序,因为在关系模型下,表中的tuple没有特定的顺序,排序在ORDER BY、GROUP BY、JOIN和DISTINCT操作符中可能使用。如果需要排序的数据在内存中可以放下,那么DBMS可以使用标准的排序算法(qsort)。如果放不下,则需要使用external sorting,能够根据需要溢出到磁盘,并且倾向于顺序而不是随机I/O。
- 如果一个查询包含一个带有LIMIT的ORDER BY,则DBMS只需要扫描一次数据就可以找到前N个元素。这就是所谓的 Top-N Heap Sort。堆排序的理想情况是前N个元素可以放在内存中,这样DBMS只需要维护一个内存中的堆排序优先队列即可。
- 对太大而无法装入内存的数据进行排序的标准算法是外部合并排序(external merge sort)。是一个分治排序算法,将数据集分成独立的运行,然后对它们进行单独排序。它们可以根据需要将runs溢出到磁盘中,然后一次读回它们。该算法分两个阶段:
- **Phase #1 - Sorting: **
首先该算法对适合主内存的小块数据进行排序,然后将排序后的页面写入磁盘。 - **Phase #2 - Merge: **
然后,将排序后的子文件合并为一个更大的单一文件。
- **Phase #1 - Sorting: **
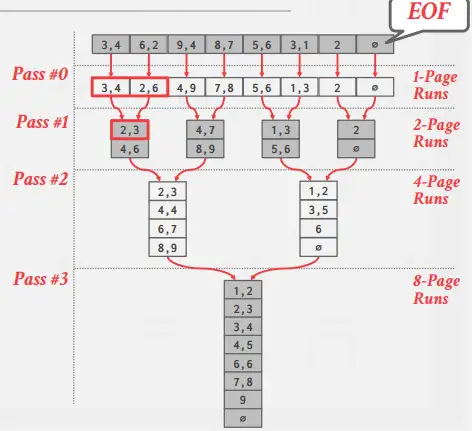
Two-way Merge Sort
- 最基本的版本是二路归并排序。该算法在排序阶段读取每个页面,对其排序,并将排序后的版本写回磁盘。然后在合并阶段,它使用3个缓冲页。它从磁盘中读取两个排序页,并将它们合并到第三个缓冲页中。 每当第三页被填满时,就会将第三页写会磁盘,并替换为一个空页。每一组排序的页面称为一个 run。该算法递归的将这些runs合并。
(每个pass可以理解为每一个遍历!) - 如果N是数据页的总数,该算法在数据中一共进行了\(1 + \lceil log_2N\rceil\)次pass(1次用于第一个排序步骤,剩下的用于归并)。总是IO成本是\(2N\times(\#\ of\ pass)\)。因为每一个pass对每一个页面都有一个IO读和写。
General(K-way) Merge Sort
- 该算法的一般版本允许DBMS使用3个以上的缓冲页。
B表示缓冲页的总数,在排序阶段,该算法可以一次读取B页,并将\(\lceil\frac NB\rceil\)个排序好了的runs写回磁盘。合并阶段,可以在每个通道中合并最多B - 1个runs,同样为合并后的数据使用一个缓冲页,并根据需要写回磁盘。 - 在一般的版本中,该算法要经历 \(1 + \lceil log_{B-1}\lceil\frac NB \rceil\rceil\) 个passes(1个是排序阶段,剩下是归并阶段)。然后,总共的IO花费是 \(2N \times (\#\ of\ passes)\)
因为这个算法每一个pass对每一个page都需要一次读和写。
Double Buffering Optimization
- 外部合并排序的一个优化是:在后台预取下一个run。并在系统处理当前运行时将其存储在第二个缓冲区。这通过不断利用磁盘来减少每一步的IO请求的等待时间。这种优化需要多线程。因为预取应该在当前运行的计算过程中进行。
Using B+Tree
- 对于DBMS,使用现有的B+Tree索引来帮助排序,而不是使用外部的合并排序算法,有时候是很有利的。特别是如果该索引是一个聚类索引,DBMS可以直接遍历B+树直接获取数据。(因为是聚类,所以数据将以正确的形式存储,IO访问是连续的)。所以会总比外部合并排序好,因为不需要计算。另一方面,如果索引是非聚类的,则遍历树几乎总是更坏的,因为数据不连续!几乎所有的记录访问都需要磁盘读取。
2. Aggregations
- 查询计划 聚合运算符将一个或多个tuple的值折叠成一个标量值。有两种实现聚合的方法:(1)排序(2)哈希
Sorting
- DBMS首先根据GROUP BY对tuples进行排序。如果所有数据都在缓冲池中,它可以使用内存中的排序算法(qsort)。如果数据大小比内存大,则可以使用外部合并排序算法。然后DBMS对排序后的数据进行顺序扫描来计算聚合。操作符的输出将在key上进行排序。
- 在执行排序聚合,重要是要对查询操作进行排序,以效率最大化。例如:如果查询需要一个过滤器,最好先执行过滤器,然后对过滤后的数据进行排序,以减少数据量
Hashing
- 在计算聚合时,散列的计算成本比排序第。DBMS在扫描表的时候会填充一个暂时的哈希表(ephemeral hash table)。对每一条记录,检查哈希表中是否已经有一个条目,并进行适当的修改。如果哈希表过大,无法容纳在内存,则DBMS可以将其溢出到磁盘上。有两个阶段来完成这个任务:
- Phase #1 – Partition:
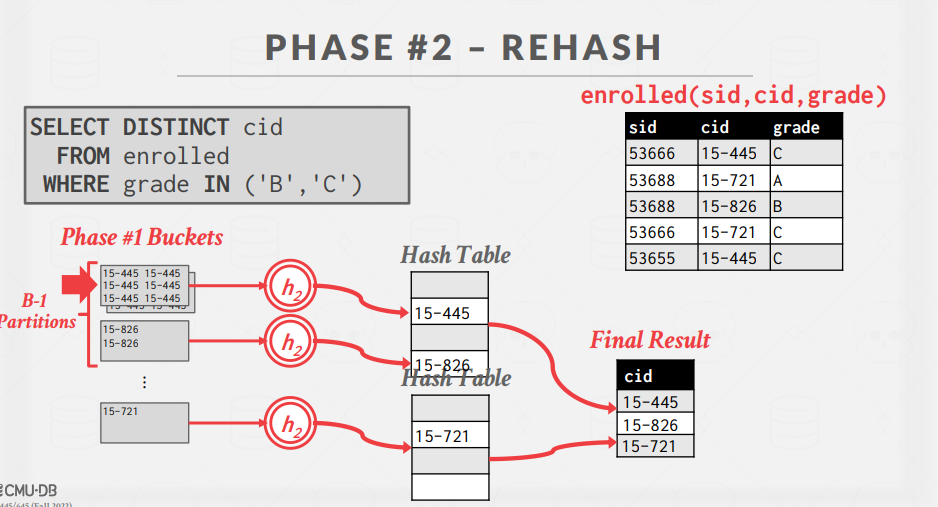
使用哈希函数h1,根据目标的hash key将tuple分割到磁盘中的不同分区。这可以将所有匹配的tuple放在同一个分区中。DBMS通过输出缓冲区将分区溢出(spill)到磁盘上。 - Phase #2 – ReHash:
对磁盘上的每一个区,将其页面读入内存,并根据第二个哈希函数h2, 建立一个内存哈希表。通过这个哈希表的每一个桶,把匹配的tuple汇聚在一起。计算聚合。这假设每个分区都可以被内存容纳。
- Phase #1 – Partition:
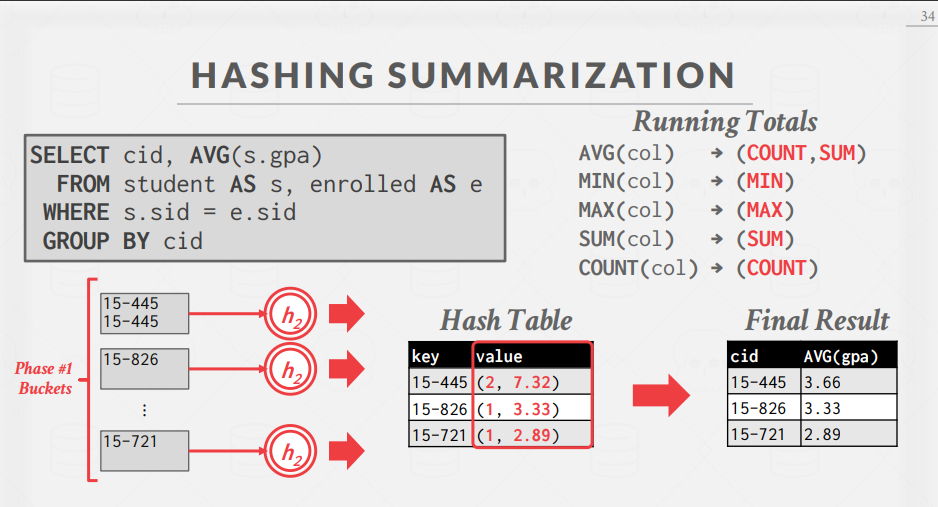
- 在ReHash阶段,DBMS可以存储形式为(GroupByKey -> RunningValue)的配对,以计算聚合。RunningValue的内容取决于聚合函数。要在哈希表中插入一个新tuple。
- 如果它找到一个匹配的GroupByKey,那么就适当地更新RunningValue。
- 否则就插入一个新的(GroupByKey→RunningValue)对。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号