08:多级反馈队列
Multi-level Feedback
content
继07章的内容,调度算法工作时不清楚当下任务,或是未来的任务具体要执行多久,因此以运行时长为前提的调度算法都无法实践应用。
mlfq(multi leve feedback queue)算法将到来的任务一律视为短任务,并通过一些限制使“短任务”降级,当任务得不到调度,又可使任务升级来保证优先调度。这种降级、升级的策略可以通过参数调控,也可以通过计算cpu占用情况,由操作系统学习过去任务的规律,预测并调整参数,自动化的调整调度策略。
本文只讲述最基础的mlfq的工作过程,具体参数调控不多描述。
基本规则
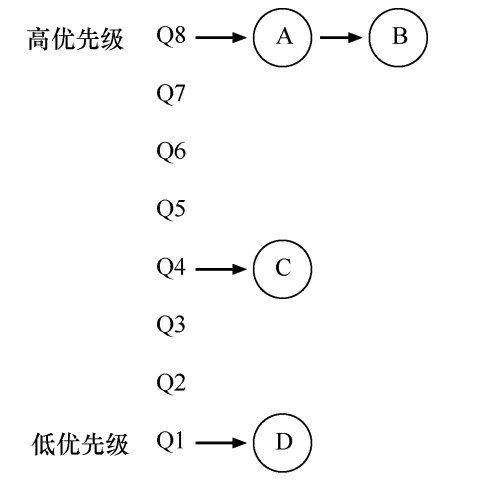
mlfq具有n个不同优先级的队列,队列中包含m个不同优先级的任务,cpu总是优先执行高优先级队列中的高优先级任务。
同一队列中的任务优先级可能相同,也可能不同。这将由os观察任务的运行规律,根据历史经验给出一个优先级。例如任务a总是执行等待键盘输入,而任务b总是执行长时间的cpu计算。那么os可认为a偏向于“交互性”的任务,优先级要比b高。
如图是mlfq的一个静态快照,当下一个时间片到来,调度规则需要满足:
- 优先执行高优先级队列中的任务,如果A优先级高于B,则先执行A。
- 如果AB优先级相同,则轮转执行AB。
优先级的调整
任务刚刚到来时,规则如下:
- 任务放入最高优先级的队列
任务在时间片内执行完后,会对其优先级进行调整。规则如下:
4-1. 任务用完整个时间片,将任务降级到下个队列里
4-2. 任务未用完时间片,如果提前释放cpu,则任务不需降级到下个队列
长任务工作过程
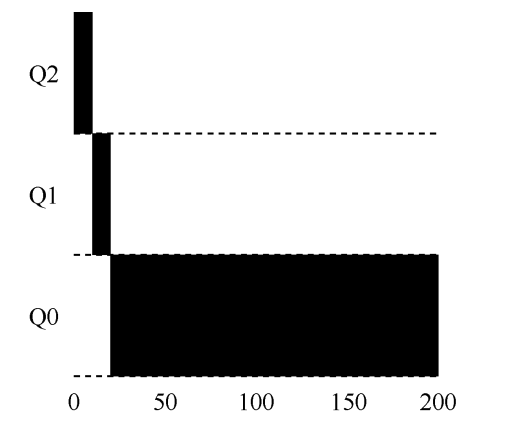
时间片10ms。
0-10ms:任务刚到来时,进入q2队列,执行10ms。
10-20ms:因使用完整个时间片,任务降级到q1队列,执行10ms。
20-200ms:任务在q3队列执行到结束。
来了一个短任务
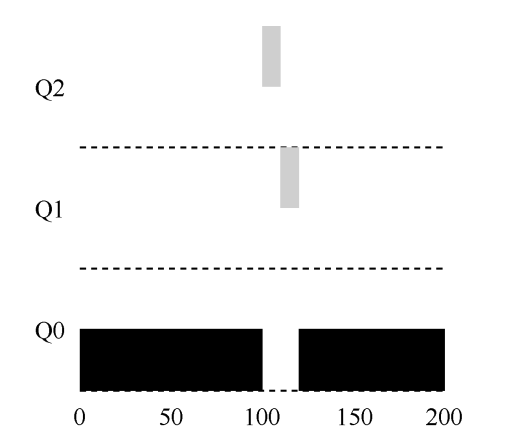
时间片10ms。如果上文中的长任务执行到100ms来了一个短任务:
100-110ms:短任务放入q2队列,优先执行q2队列的任务,短任务使用完时间片。
110-120ms:短任务降级到q1队列,q2队列无任务,执行q1队列的任务,短任务使用完时间片,整个任务执行结束。
120-200ms:长任务在q0继续执行至结束。
如果产生IO
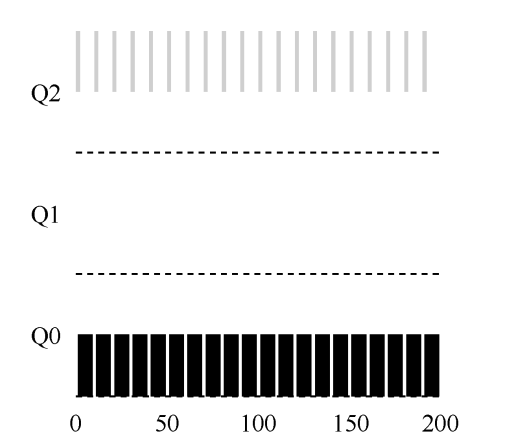
时间片10ms。如果短任务执行1ms的cpu计算,剩余9ms用于等待io。那么这9ms将分配给长任务执行。由于短任务每次都提前释放了cpu,因此短任务一直存于q2队列。
进程饿死
在当前规则下,mlfq算法会产生一些问题:
- 如果当前存在过多的“交互性”任务,任务a和b都不会占满时间片,则它们会一直在最高队列轮转执行,低队列任务将被饿死。
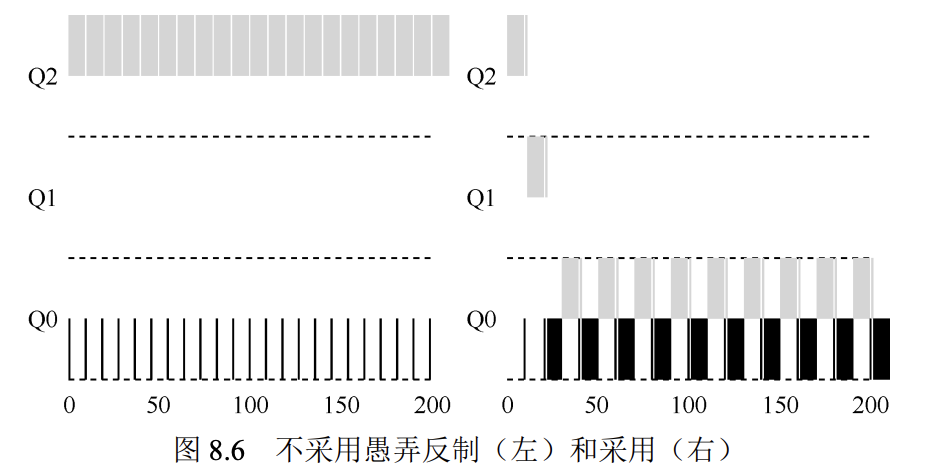
- 可以破坏调度的公平性,通过调控进程的io,让进程执行完时间片的99%后释放cpu,达到一直占用cpu的目的。
为了解决问题1,mlfq定时将所有任务重新放入最高队列中(boost)。
如右图,当出现两个交互任务后,每50ms,所有任务重新进入最高优先级队列。长任务得以获取时间片。
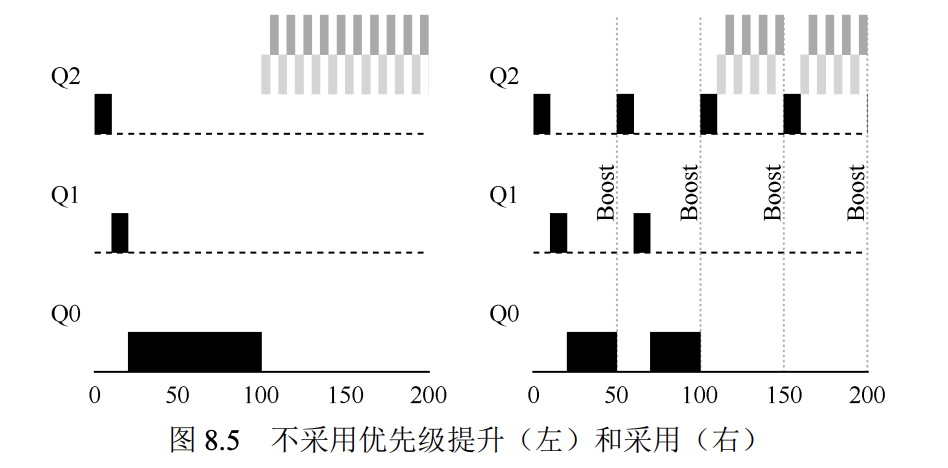
为了解决问题2,mlfq重写了策略4。任务在队列中分配的总时间片是有限的,虽然前几次可以因为提前释放cpu而不被降级,但最后一次不论怎样都要降级到下个队列。
使用新策略后,短任务虽然提前释放了cpu,但仍降级到下个队列,并最终在q0队列和长任务轮转执行。
总结下mlfq的规则
mlfq把所有刚到来的任务都视为短任务,给予最高优先级,保证了响应周期较低。
如果任务本身是短任务,可在时间片内执行完,这趋近于STJF的效率。
如果任务本身是长任务,那么可逐步降低优先级,保证后续短任务优先执行。
其中为了解决进程饿死,和防止愚弄调度进程(破坏调度公平),定期将所有任务升级到最高优先级队列,确保每个任务必定能执行到。对于交互性的任务,也强制限制在队列中的生存周期。
- 队列中A的优先级大于B,先执行A
- 队列中A优先级等于B,AB轮转执行
- 刚到来的任务放入最高优先级队列中
- 当任务使用完某一层队列分配给的时间片,降级到下一层队列。(消耗完时间片配额前,如果任务提前释放cpu还是不会降级)
- 经过一段时间,将所有任务重新放入最高优先级队列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号