【CSAPP】程序结构和执行
目录
第二章 信息的表示和处理
2.1 信息存储
2.1.1 十六进制表示法
16进制和2进制相互转换
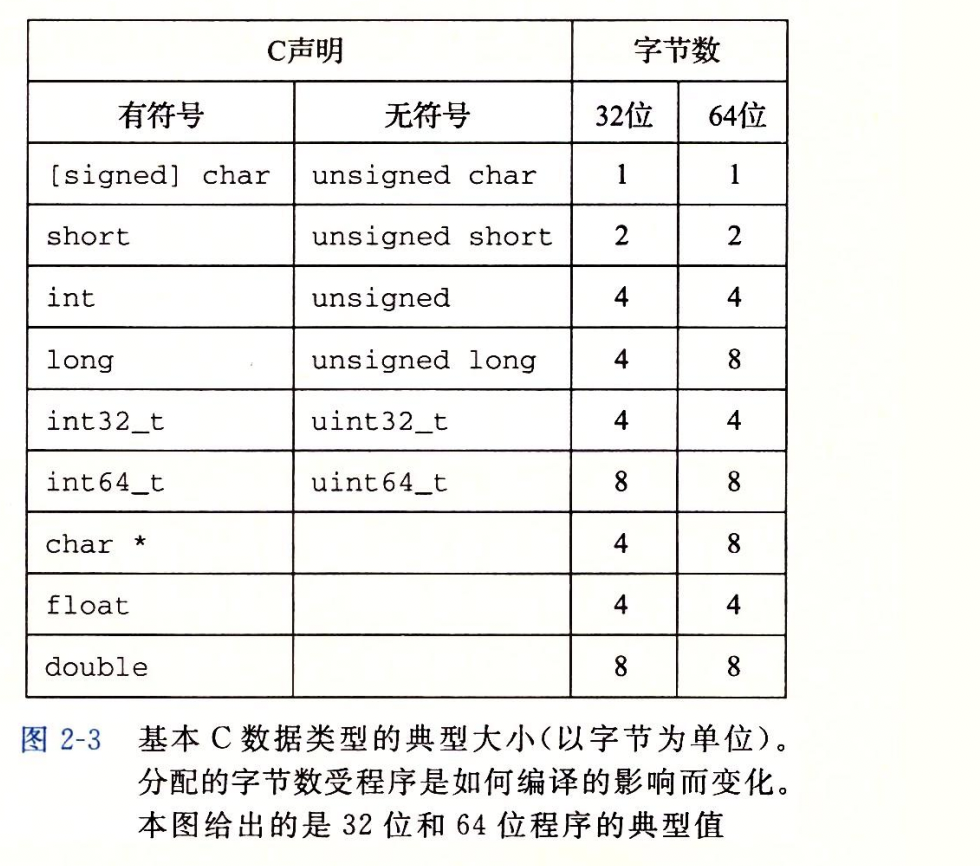
2.1.2 字数据大小
不同类型的变量在32位机器和64位机器上的变化、程序从32位机器迁移到64位机器可能引发错误。
2.1.3 寻址和字节顺序
大端(bit endian)、小端(little endian)

不同字节顺序的重要性体现在:
- 网络传输中,发送和接受需要统一标准
- 汇编代码表示的字节数据和日常阅读习惯不同
- 指针类型强转后,编译器将指针指向的单元看作字节序列,字节序列在不同平台上使用不同的字节顺序存储
2.1.4 表示字符串
"123" 在机器中的存储用16进制表示为 31 32 33 00,字符串以0x00终止。
2.1.5 表示代码
不同操作系统编译出的二进制代码不同。二进制代码在不同环境下不兼容。
2.1.6 布尔代数简介
| & ~ ^ 运算

2.1.7 C语言中的位级运算
交换变量值的小技巧:
void inplace_swap(int *x, int *y) {
*y = *x ^ *y;
*x = *x ^ *y;
*y = *x ^ *y;
}
2.1.8 C语言中的逻辑运算
|| && ! 不适用于位级运算
2.1.9 C语言中的位移运算
逻辑右移:补0
算数右移:补最高位的值,最高位是0补0,是1补1
C语言中,w位的值右移k位,k>=w:实际位移(k mod w)位
C语言中,>> << 的优先级小于 + -
2.2 整数表示
2.2.1 整形数据类型
2.2.2 无符号数的编码
2.2.3 补码编码
2.2.4 有符号数和无符号数之间的转换
无符号数和补码向量公式:
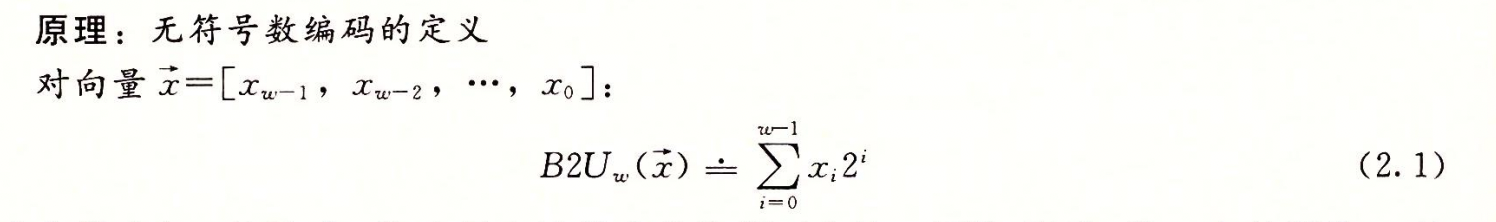
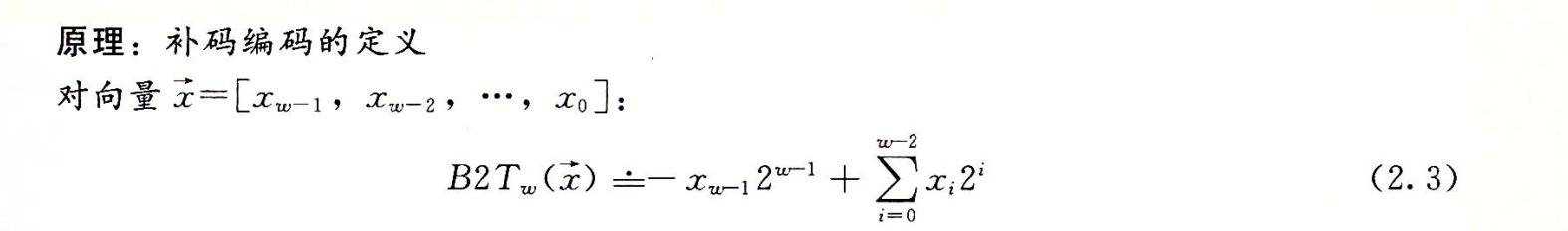
补码和无符号数的转换公式:x表示十进制数字
\[T2U_{w}(x) \doteq B2U_{w}\left (T2B_{w}(x) \right), TMin_{w} \leqslant x \leqslant TMax_{w}
\]
\[U2T_{w}(x) \doteq B2T_{w}\left (U2B_{w}(x) \right), 0 \leqslant x \leqslant UMax_{w}
\]
由以上公式可以推导出:
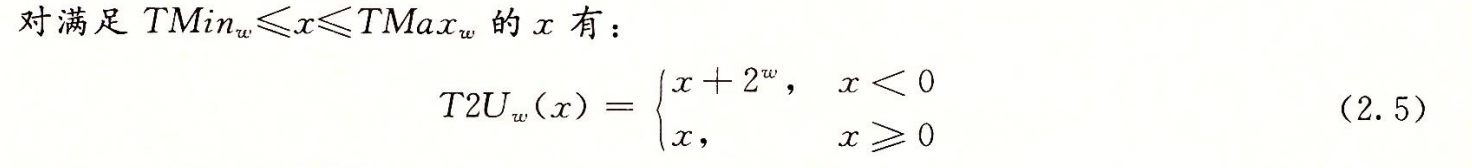
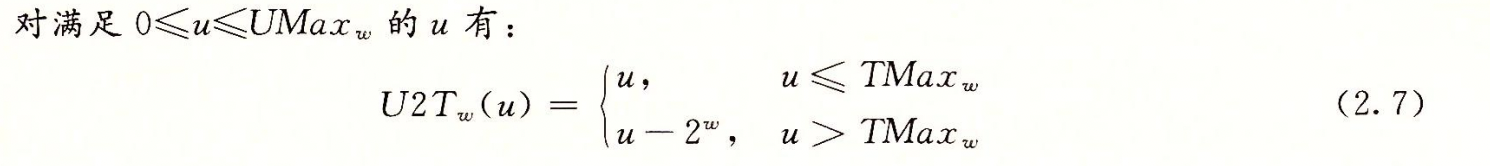
推导过程
首先定义:$$ \vec x = T2B_{w}(x) = U2B_{w}(x) $$
由公式2.1和2.3推到得出:
\[B2U_{w}( \vec x) - B2T_{w}( \vec x) \doteq x_{w-1}2^{w}
\]
则可连续推导出:
\[T2U_{w}(x) \doteq B2U_{w}(T2B_{w}(x)) \doteq B2U_{w}(\vec x) \doteq x_{w-1}2^{w} + B2T_{w}(\vec x) = x_{w-1}2^{w} + B2T_{w}(T2B_{w}(x)) \doteq x_{w-1}2^{w} + x
\]
通过第w-1位是0还是1的讨论即可得出公式2.5
类似的:
\[U2T_{w}(x) \doteq B2T_{w}(U2B_{w}(x)) \doteq B2T_{w}(\vec x) \doteq B2U_{w}(\vec x) - x_{w-1}2^{w} \doteq B2U_{w}(U2B_{w}(x)) - x_{w-1}2^{w} \doteq x - x_{w-1}2^{w}
\]
通过第w-1位是0还是1的讨论即可得出公式2.7
总结来说
一串bit位,可以看做无符号数,也可看作有符号数。对于它本身,将其看作 无符号数 减 将其看作有符号数,结果有两种情况:
-
等于0,即最高位是0,两个数大小一致
比如0001 - 0001 = 0000 -
等于2^w,即有符号数最高位是1
比如1001 - 1001 = 9 - (-7) = 16 = 2^4
2.2.5 C语言中的有符号数和无符号数
%d %u %x 分别用于表示十进制、无符号十进制、十六进制
在补码和无符号数转换时(类型强转、隐式转换),底层执行T2U或U2T算数运算
当无符号数和有符号数 运算 或 比较 时,会默认将有符号数当作无符号数对待,并进行计算;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号