05: 进程api
process API
content
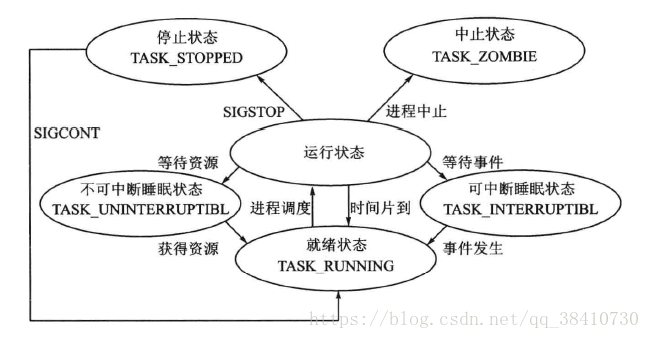
linux进程状态:
参考:
https://blog.csdn.net/shenwansangz/article/details/51981459
fork:创建子进程,子进程从fork处开始执行,子进程获取的fork返回值为0。
wait:父进程阻塞等待任意一个子进程执行结束,父进程再开始执行。特殊情况下不会等待。
exec:可执行程序载入内存,替换当前进程的内存数据,相当于原进程从未发生,exec也不会有调用返回。
fork+exec可以发挥强大的功能,比如unix shell,父进程fork出子进程获取用户输入,指令及参数由exec执行,父进程wait等待执行结束,之后再次fork等待用户输入。
父进程结束后,子进程还未运行结束,则成子进程未孤儿进程。子进程将由Init进程托管,init来负责子进程的善后工作(清理内核中的PCB)。
子进程在内核中的PCB需要父进程调用wait来清理,若父进程一直未处理子进程PCB(例如父进程处于死while),子进程虽然结束,但是PCB未被清除,则子进程称为僵尸进程。
参考:
https://blog.csdn.net/fjtooo/article/details/120869794
https://github.com/huangz1990/note/blob/master/os/apue/chp8.rst
homework
p1:父子进程访问公共变量
int main(int argc, char const *argv[])
{
int x = 50;
int rc = fork();
if (rc < 0) {
printf("fork fail");
exit(1);
} else if (rc == 0) {
printf("child x = %d\n", x);
x = 200;
printf("child x = %d\n", x);
} else {
printf("parent x = %d\n", x);
x = 100;
printf("parent x = %d\n", x);
wait(NULL);
}
return 0;
}
参考:
https://yuhao0102.github.io/2019/05/05/fork----父子进程共享/
https://blog.csdn.net/qq_35191331/article/details/79803548
父子进程遵循“读时共享,写时复制”。子进程创建后,共享父进程的数据段、代码段、堆栈。当子进程或父进程修改了某个共享数据,此时发生中断,分配物理内存并拷贝数据给子进程。若中断原因不是exec引起,则父子进程仍然共享代码段,数据段和堆栈处于各自的虚拟内存中。在外界看来,两进程操作公共变量互不影响。
p2:父子进程对同一文件写入
int main(int argc, char const *argv[])
{
int fd = open("./p2.output", O_CREAT|O_WRONLY|O_TRUNC, S_IRWXU);
if (fd < 0) exit(1);
int rc = fork();
if (rc < 0) exit(1);
else if (rc == 0) {
printf("child fd:%d\n", fd);
write(fd, "child", 5);
} else {
printf("parent fd:%d\n", fd);
write(fd, "parent", 6);
wait(NULL);
}
return 0;
}
参考:
http://fuerain.ink/archives/linux-multi-process-w-file.html
https://blog.csdn.net/u011508527/article/details/46878205
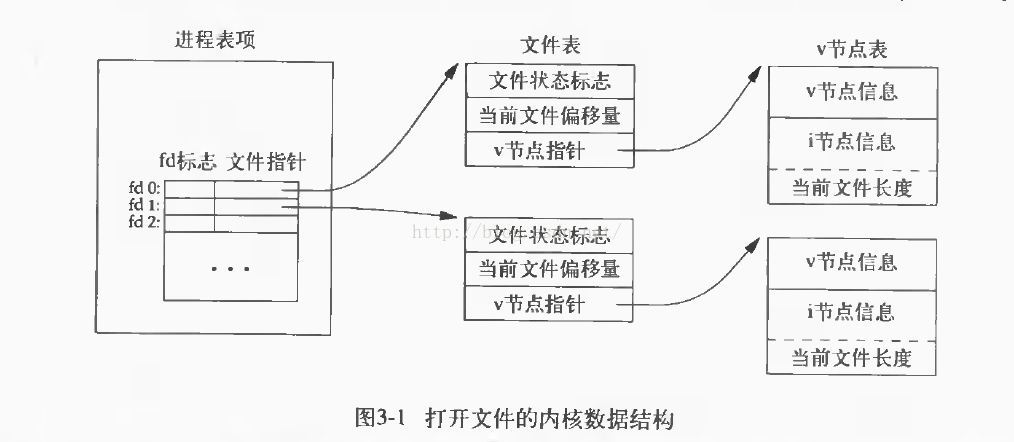
父子进程同时操控文件,有两种情况:
- 先open,再fork
- 先fork,再open
无论哪种情况,本质都是子进程对父进程内存数据的复制,以及文件在内存的存储形式。
在进程中打开的文件,以fd和文件指针的形式存储在该进程内存的某个区域,当fork出子进程,fd和文件指针将被共享(或中断后被复制),此时父子进程的文件指针的值一致,则两进程都在操控同一份文件表。而write函数是系统调用函数,保证了原子性,那么文件的偏移量就不会出错。写入的数据就不会出现“穿插”或“覆盖”的情况,写入的先后由调度算法决定。
先fork了子进程再打开文件,本质是父子进程在进程表中添加fd和文件指针,触发“写时复制”,子进程被分配空间并将数据copy,那么父子进程的文件指针就会引用不同的文件表,文件的偏移量就不会在两个进程间正确同步,进而导致写入冲突。
p3:不使用wait,保证子进程先执行
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char const *argv[])
{
int rc = vfork();
if (rc < 0) {
printf("fork fail");
exit(1);
} else if (rc == 0) {
printf("hello\n");
} else {
printf("goodbye\n");
}
return 0;
}
fork会将父进程的数据都复制一遍,但是exec会又覆盖一遍内存数据,那么一开始的复制是没必要的,因此fork引入copy on write, 子进程和父进程共享数据读取,当其中一方要修改共享的内存时再执行复制。
vfork也和父进程共享数据,但是没有copy-on-write,子进程的修改会污染父进程。(子进程退出应该使用_exit(),使用return会将父进程栈弹出)
在执行顺序上也有不同,父进程会等待子进程执行exit或exec之后再执行。
参考:
Linux中fork,vfork和clone详解(区别与联系)
https://www.zhihu.com/question/26591968?utm_id=0
p4:使用多种exec变体函数
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
#include <sys/wait.h>
int main(int argc, char const *argv[]) {
int rc = fork();
if (rc < 0) {
fprintf(stderr, "fork failed");
exit(1);
} else if (rc == 0) {
// execl("/bin/ls", "ls", "-l", NULL);
// char *arg[] = {"ls", "-l", NULL};
// execv("/bin/ls", arg);
// execlp("ls", "ls", "-l", NULL);
// char *arg[] = {"ls", "-l", NULL};
// execvp("ls", arg);
// char *env[] = {"name=orange", NULL};
// execle("./output/env", "env", NULL, env);
char *arg[] = {"1", "2", "3", NULL};
char *env[] = {"name=orange", NULL};
execve("./output/env", arg, env);
perror("exec error");
} else {
wait(NULL);
}
}
env.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
for (int i = 0; i < argc; i ++ ) {
printf("argv[%d]:%s\n", i, argv[i]);
}
printf("name:%s\n", getenv("name"));
}
exec变体函数都由execve而来,这些函数的参数主要是3个部分:文件名或路径,文件参数,执行文件时的环境变量。
函数名的规律,方便记忆参数:
- 带有l,表示文件参数可以一个个罗列
- 带有v,表示文件参数应该整理到数组里,通过数组传递
- 带有e,表示可以将新环境变量组成数组,然后传递
- 带有p,表示可以传文件名称,操作系统自动帮你去PATH寻找对应的文件
参考:
https://zhuanlan.zhihu.com/p/203015620
p5:wait的返回是什么,子进程使用wait发生什么
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
int rc = fork();
if (rc < 0) {
perror("fork failed");
exit(1);
} else if (rc == 0) {
printf("this is child, pid:%d\n", getpid());
int w = wait(NULL);
if (w < 0) {
perror("child wait failed");
} else {
printf("child wait success, w:%d\n", w);
}
} else {
printf("this is parent, pid:%d\n", getpid());
int w = wait(NULL);
if (w < 0) {
perror("parent wait failed");
} else {
printf("parent wait success, w:%d\n", w);
}
}
return 0;
}
在子进程里调用wait会返回错误;wait返回的是子进程的pid。
关于wait参数的拓展
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
int rc = fork();
int status;
if (rc < 0) {
perror("fork failed");
exit(1);
} else if (rc == 0) {
printf("this is child, pid:%d\n", getpid());
// sleep 10*2s
for (int i = 0; i < 10; i ++ ) {
printf("sleeping, pid:%d\n", getpid());
sleep(2);
}
exit(2);
} else {
printf("this is parent, pid:%d\n", getpid());
int w = wait(&status);
if (w == -1) {
perror("wait failed");
} else {
if (WIFEXITED(status)) {
// WEXITSTATUS 可获取子进程exit的状态
printf("child process exit status:%d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
// WTERMSIG 可获取使子进程终止的信号
printf("child process killed by:%d\n", WTERMSIG(status));
} else if (WIFSTOPPED(status)) {
// WSTOPSIG 可获取使子进程暂停的信号
printf("child process stop by:%d\n", WSTOPSIG(status));
}
}
}
return 0;
}
如果wait的参数status不为NULL,还可以更详细的通过status获取子进程退出的原因。
参考:
https://zhuanlan.zhihu.com/p/341840514
p6:使用waitpid代替wait
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
int rc = fork();
int p = 0;
if (rc < 0) {
perror("fork failed");
exit(1);
} else if (rc == 0) {
p = getpid();
printf("this is child, pid:%d\n", p);
} else {
// waitpid(p, NULL, WNOHANG);
waitpid(p, NULL, 0);
printf("this is parent, pid:%d\n", getpid());
}
return 0;
}
waitpid更加灵活,可以控制具体等待哪一种子进程,并且可以不阻塞父进程。
waitpid 和 wait 的不同之处在于, waitpid 可以选择自己要等待的进程, 也可以决定子进程未终结时是否阻塞, 支持作业控制, 以及一些其他更细致的选项。
waitpid 的 pid 参数用于指定等待的特定子进程,它的值可以是:
pid == -1 :等待任意一个子进程,类似于 wait 。
pid > 0 :等待 ID 值为 pid 的子进程。
pid < -1 :等待任意组 ID 为 pid 绝对值的子进程。
pid == 0 :等待任意组 ID 和父进程相同的子进程。
options 参数用于控制 waitpid 的返回行为,它的其中两个常用值如下:
0 :执行默认行为 —— 在 pid 参数指定的进程未终结时,一直阻塞。
WNOHANG :在 pid 参数指定的进程未终结时,不阻塞,直接返回 0 ,结束 waitpid 的调用。
还有 options 参数,可以参考文档。
wait 函数等同于 waitpid(-1, &status, 0) 。
需要说明的是, wait 和 waitpid 的实际作用是等待子进程的状态改变, 子进程的退出只是“状态”的其中一种, 这两个函数的更多用法可以参考文档。需要说明的是, wait 和 waitpid 的实际作用是等待子进程的状态改变, 子进程的退出只是“状态”的其中一种, 这两个函数的更多用法可以参考文档。
参考:
https://github.com/huangz1990/note/blob/master/os/apue/chp8.rst
p7:子进程关闭标准输出后执行printf
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char const *argv[])
{
int rc = fork();
if (rc < 0) {
perror("fork failed");
exit(1);
} else if (rc == 0) {
fclose(stdout);
printf("this is child\n");
} else {
wait(NULL);
printf("this is parent\n");
}
return 0;
}
子进程不影响父进程,copy-on-write;
p8:创建两个子进程,将子进程a的标准输出连接到子进程b的标准输入
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main(int argc, char const *argv[])
{
int fd[2];
if (pipe(fd) < 0) {
perror("create pipe failed");
exit(1);
}
int i, pid = 0;
for (i = 0; i < 2; i ++ ) {
pid = fork();
if (pid < 0) {
perror("create child process failed");
exit(1);
} else if (pid == 0) {
break; // 需及时退出循环,否则会子进程会继续循环,创建出子子进程
}
}
// child
if (pid == 0) {
if (i == 0) {
printf("this is child[%d]\n", getpid());
// 关闭写端,重定向标准输入到fd[0]
close(fd[1]);
dup2(fd[0], STDIN_FILENO);
char buf[64];
memset(buf, 0, sizeof(buf));
read(STDIN_FILENO, buf, sizeof(buf));
printf("read from brother: %s\n", buf);
}
if (i == 1) {
printf("this is child[%d]\n", getpid());
// 关闭读端,重定向标准输出到fd[1]
close(fd[0]);
dup2(fd[1], STDOUT_FILENO);
printf("hello");
}
}
// parent
if (pid > 0) {
int w = 0;
while (1) {
w = waitpid(-1, NULL, 0);
if (w > 0) {
printf("child[%d] finish\n", w);
} else if (w == -1) {
break;
}
}
}
return 0;
}
首先要了解:
- pipe怎么使用
- 怎么正确的创建多个子进程
- 如何将标准输入输出连接到pipe
pipe称为匿名管道,本质是内核的环形队列(一种buffer),它只能在有血缘关系的进程之间通信时使用,并且数据是单向流动的。
dup2(oldfd, newfd) 就是将newfd指向到oldfd指向的文件,这样newfd和oldfd都可以操作这份文件。
参考:
https://blog.csdn.net/mrtwenty/article/details/98848934
https://www.cnblogs.com/love-jelly-pig/p/10048483.html
https://zhuanlan.zhihu.com/p/558285964

 浙公网安备 33010602011771号
浙公网安备 33010602011771号