【汇编语言】笔记 1~8章
9~17章:https://www.cnblogs.com/orangelsk/articles/16282298.html
寄存器
数据在寄存器中的存储
8086的CPU是16位结构,其CPU内部总线的宽度是16,这意味着CPU内部的寄存器、运算器、控制器一次能传输、存储的最大数据为16位。
对于通用寄存器来说,例如ax,可以分为高位ah和低位al,各自占用8位bit,是ax的一半。在使用命令操作ah、al时,单独的将其看作是8bit的寄存器,al的溢出不会影响ah。
8086CPU如何给出物理地址
8086CPU的外部地址总线宽度为20,而CPU内部一次只能处理16位bit,内存寻址需要20位bit,这中间差了4位bit。
8086CPU内部通过加法器运算两次16位bit数据,即段地址 * 16 + 偏移地址得出物理地址。二进制数据乘16意味着左移4位bit,这样就可以凑出20位bit数据。
偏移地址受限于16位bit,最大为2^16=64KB。
CS和IP
CS是段寄存器,IP是指令指针寄存器。CPU从内存中获取要执行的指令,指令地址=CS * 16 + IP。
8086CPU的执行指令的过程:
1、从CS:IP指向的内存地址读取指令进入指令缓冲器
2、IP寄存器的值自动增加,指向下一条指令
3、执行指令(转至第1步,循环执行)
jmp
同时修改CS和IP寄存器的内容:jmp 段地址:偏移地址,jmp 2AE3:3
只修改IP寄存器内容:jmp 某一寄存器,jmp ax
寄存器(内存访问)
mov、add、sub
语法格式:(add、sub与mov相同)
mov ax,1
mov ax,bx
mov [0],ax
mov ax,[0]
mov ds,ax
mov byte ptr [0],1 ; 在之后会学到
数据在内存单元的存储
8086PC机中一个字(16bit)代表两个字节,CPU是16位的,一次处理的数据宽度是16位,因此在寄存器与内存交互过程中,每次处理字大小(16bit)的数据。
8086的一个内存单元有8bit,两个连续内存单元称为字单元。字单元包括高地址和低地址的内存单元,当字单元数据进入寄存器,高地址内存单元存于寄存器高地址,低地址内存单元存于寄存器低地址。
DS和[address]
寄存器访问内存单元中的数据,需要有准确的地址指向。DS段寄存器中存放要访问内存单元的段地址,偏移地址通过[address]来控制,[0]表示偏移指针指向段的0号单元,[1]表示指向段的1号内存单元。
DS是段寄存器,只能通过寄存器赋值,不能直接赋值。
mov ax,1000H
mov ds,ax ; 给ds寄存器赋值
mov bh,[0] ; 将10000H的内存单元数据读入bh
mov [2],bx ; 将bx寄存器16位bit写入10002H地址的字单元
CPU的栈机制
CPU提供push和pop指令,来将一段连续内存模拟成栈,SS段寄存器记录栈的段地址,SP寄存器用作偏移指针,指向栈顶。
8086CPU的栈段是一段连续内存,地址由低到高。入栈时,数据优先存入高地址,SP从高地址往低地址偏移,出栈时,SP从低地址往高地址偏移。栈的溢出需要自行控制,8086CPU不提供这样的保护机制。
push过程:
1、SP=SP-2
2、将数据写入SS:SP地址的字单元
pop过程:
1、将SS:SP地址的内存数据读出
2、SP=SP+2
SS作为段寄存器,只能通过寄存器赋值。
mov ax,1000H
mov ss,ax
mov sp,0000H ; 定义从10000H~1FFFFH的栈段
mov ax,2000H
mov ds,ax ; 定义要访问的数据段起始位置20000H
push bx ; 将bx中的数据入栈
pop ax ; 出栈数据存入ax
push [0] ; 将20000H处字单元数据入栈
pop [2] ; 出栈的字单元数据存入20002H地址字单元
内存段
一组连续内存单元,可以抽象定义成“段”,这组内存单元的起始地址称为段地址,想要访问其中某个内存单元需要一个偏移指针。段地址存于段寄存器,偏移指针可存于普通的寄存器中。
(作为段寄存器,赋值只能通过通用寄存器中转,不能像其他寄存器直接赋值。)
当这组内存单元被不同的寄存器指向,便有了不同的虚拟意义。比如当它被CS:IP指向时,这意味着这段内存存放代码指令,就可以称之为“代码段”。
当被DS指向时,可以称之为“数据段”,当被SS:SP指向时,可以称之为“栈段”。连续的内存本身只用作存储,CPU为其赋予了不同的存储意义,它用作什么,主要看寄存器中的设置。
程序的生命周期
编写
用汇编语言编写的程序文件称为“源程序”,在“源程序”中分为“伪指令”和“程序”两个部分,例如:
assume cs:codesg ; 声明代码段
codesg segment ; 代码段开始
mov ax,0123h
mov bx,0456h
add ax,bx
add ax,ax
mov ax,4c00h ; 这两行,标识程序结束执行,交出CPU控制权
int 21h
codesg ends ; 代码段结束
end ; 标识编译结束位置
真正被编译为01机器码的只有中间汇编语言的部分,其余部分用来指示编译器工作,算是一种“伪指令”。
编译
编译器(masm)将“源程序”文件编译为“xxx.obj”文件。
连接
连接器(overlay linker)将“xxx.obj”文件连接为“xxx.exe”可执行文件。连接器起到的效果是,组合多个目标文件,或是组合程序调用的其他库文件中的子程序,并将目标文件最终处理为可执行文件。
加载
exe可执行文件需要被调入内存才能被CPU执行,“调入操作”需要当前正在运行的程序执行。并在成功调度后,让出CPU控制权给编写的程序,程序执行后再将CPU控制权让回。
当程序被调入内存,CPU会将CS:IP指向程序所在位置,进而执行汇编代码。
程序在内存中的位置由操作系统决定,其分配两块空间(1)256字节的数据区,称为程序段前缀PSP,用于DOS和被加载程序通信(2)被加载的程序
假设PSP区域起始地址为SA:0,那么被加载程序的起始地址为SA+10H:0。
SA:256 = SA * 16 + 16 * 16 = (SA + 16) * 16 = SA+10H:0
[BX]和loop
[BX]
通过赋值ds,可以使用 mov ax,[0] 这样的语法获取内存单元的值。bx寄存器可以起到等效作用:
mov bx,0
mov ax,[bx]
loop
loop命令用来实现循环,当执行到loop命令时:
1、cx = cx - 1
2、若cx==0,执行下一条指令
3、若cx>0,执行标志位处的指令
求2的10次方:
mov ax,1
mov cx,10
s: add ax,ax
loop s
使用bx的好处就是,可以配合loop,以变量的方式读取内存。
mov ax,2000h
mov bx,0
mov cx,10
mov ds,ax
s: mov al,[bx] ; 求20000~20010内存单元值的和
mov ah,0
add dx,ax
inc bx
loop s
debug和masm对指令的不同处理
注:汇编程序中,数据不能以字母开头,例如地址A000H,要写为0A00H。
在debug中,直接编写的汇编命令 [0] 可以被解析为ds:0;
在masm中,mov ax,[0] 将被作为 mov ax,0 进行编译。
两种解决方法:
1、使用 [bx] 代替 [0]
2、增加段寄存器标志,写成 mov ax,ds:[0]
段前缀
汇编语言中默认[bx]指向ds:bx,这里的ds:就是段前缀,显示的表明段地址。类似的写法还有ss:[bx],cs:[bx],es:[bx]。
显示的标明段前缀,就不必通过反复改变ds的值来变更地址:
; 1、若需要不同内存段的数据,可以
mov ax,2000h
mov ds,ax
; 使用ds:[bx]操作内存空间
mov ax,3000h
mov ds,ax
; 使用ds:[bx]操作内存空间
; 2、也可以
mov ax,2000h
mov ds,ax
mov ax,3000h
mov es,ax
; 使用ds:[bx]和es:[bx]操作内存空间,不必来回赋值ds
一段比较安全的空间
一般的8086PC机的 0:200~0:2ff(256个字节) 是安全空间,可以用来修改和存放代码。随便修改其他位置的数据,可能引起崩溃。
平时使用debug加载的程序,经过了操作系统的内存分配,可以保证程序所在空间时安全的。
包含多个段的程序
如何写出包含多个段的程序
当程序中包含多个段,载入内存后,不同段分配在不同的地址上。
assume将多个段寄存器与自定义的段名联系起来,可以认为code、data、stack就是对应寄存器存储的地址,code、data、stack不是寄存器,本质是地址。
在程序中通过 < name > segment 定义多个段,段名提前在assume中声明。段名是自定义的,想定义成a、b、c也没问题。通过segment可以清晰的将程序分为数据段、栈段、程序段。
程序加载入内存,cs:ip会指向第一个段的起始地址,这样程序会错误执行数据段。需要标志程序入口,需要在end后加上标志,并在代码段第一行程序前使用标志。
在数据段和栈段中,使用dw指令分配内存并赋值(以字为单位)。代码中通过dw 0,创建了8个字大小的栈段,sp指针的值需在下文程序中赋值。
代码段中,首先做的就是修正段寄存器的值。当程序载入内存时,不同的段分配在不同的地址空间上,此时ds、ss并不会自动变为对应段的段地址,需要在程序中手动修改,而之前assume的段名就是正确分配好内存后的段地址。
assume cs:code,ds:data,ss:stack
data segment ; 数据段
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends
stack segment ; 栈段
dw 0,0,0,0,0,0,0,0
stack ends
code segment ; 代码段
start: mov ax,stack ; 修正ss
mov ss,ax
mov sp,16 ; 确定栈底
mov ax,data ; 修正ds
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[0]
pop ds:[2]
mov ax,4c00h
int 21h
code ends
end start ; 指明程序入口
段的内存分配
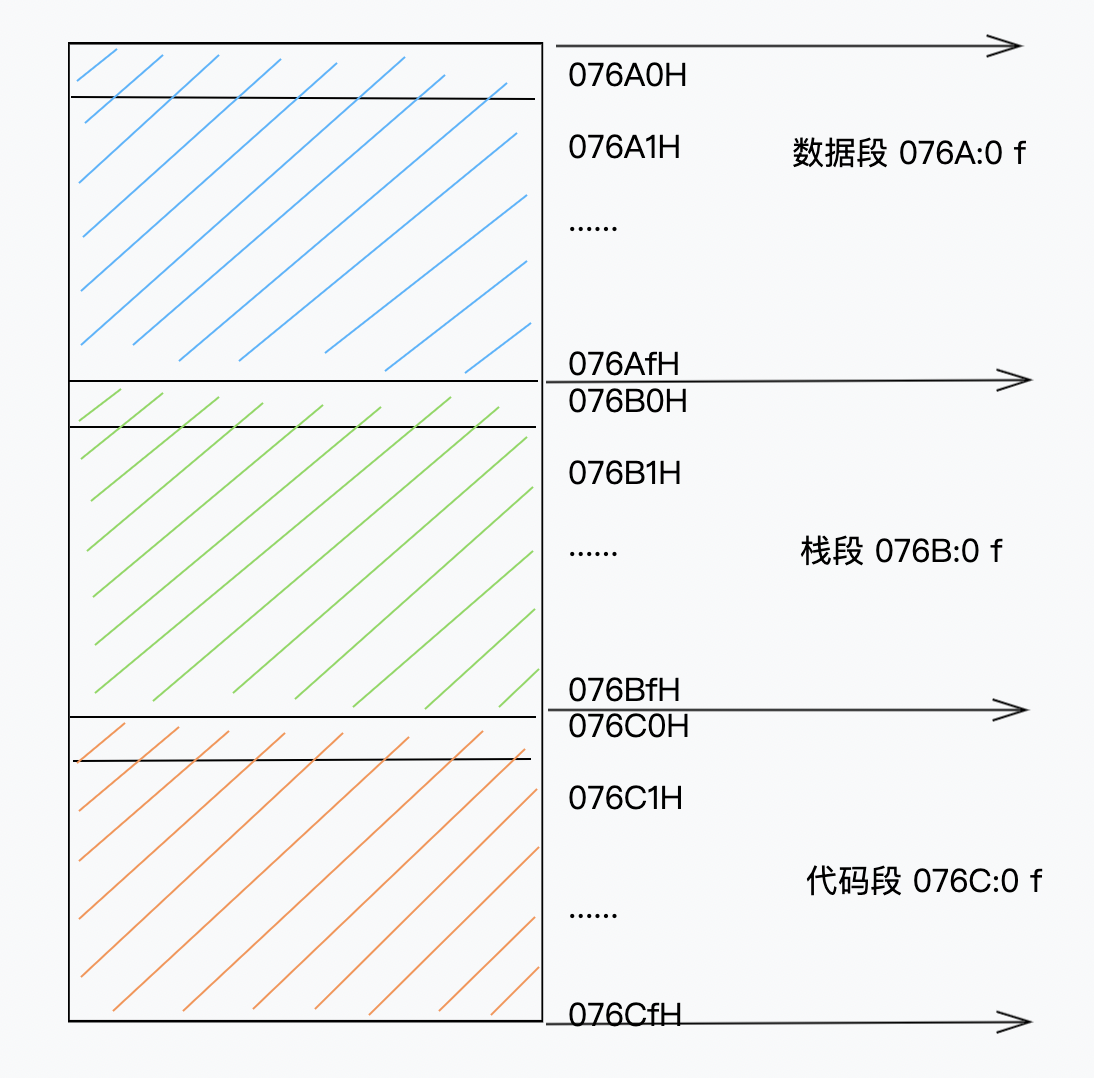
使用debug调试上文程序,得知各个段在内存中的地址:ds=076A ss=076B cs=076C
通过段地址,可得出段的内存分配,如图:
分配策略
段在分配内存时,以16byte为单位,假设一个段大小有N byte,那么分配大小为Ceiling(N / 16) * 16。
例如:数据段大小只有2byte,那么会分配16byte;代码段大小有30byte,那么分配32byte。
更灵活的定位内存地址
以字符的方式分配数据
db 'ABC' 字符以ASCII码存储内存,每个字符占一个字节。当使用dw 'ABC'为字符分配字单元,会编译出错。
and 和 or
and <寄存器> <数值> 寄存器 = 寄存器 “与” 数值
or <寄存器> <数值> 寄存器 = 寄存器 “或” 数值
[]、bx、si、di
si、di寄存器的功能和bx相似,都是用作变量来定位内存地址。si、di的特殊之处在于不能拆分成两个8位寄存器使用。
定位内存地址的方式:
-
[idata]
如[0],通过确定的常数,定位至 ds:idata -
[bx]、[si]、[di]
bx、si、di作为变量,常和loop搭配使用 -
[bx+idata]
如[bx+1],也可写作1[bx],这种写法和c语言中的a[i]类似,idata可看作数组起始偏移地址 -
[bx+si]、[bx+di]
通过两个变量定位内存地址,也可写作 [bx][si] 和 [bx][di] -
[bx+si+idata]、[bx+di+idata]
通过两个变量、一个常量确定地址,也可写作(常用的):
mov ax,[bx+200+si]
mov ax,[200+bx+di]
mov ax,200[bx][di] ; 这可以类比成c语言中的a[i][j]
mov ax,[bx].200[si]
mov ax,[bx][di].200
编程技巧
二重或更多重的循环,寄存器可能不够用,可以将数据暂存于栈段。
如下,外层3次循环,内层5层循环。
mov cx,3
push cx
s:
mov cx,5
s1:
loop s1
pop cx
loop s
数据处理的两个基本问题
两个基本问题:要处理的数据在哪?数据长度?
bp寄存器
bp寄存器像bx一样,可以和si、di搭配使用,但是使用bp时,若不显示声明段寄存器,则默认bp的段寄存器为ss。
mov ax,[bp+si] ; ss * 16 + bp + si
mov ax,es:[bp+si] ; es * 16 + bp + si
数据存储位置
不同的指令,表示数据存储位置不同:
mov bx,[0] ; 数据在内存中
mov bx,ax ; 数据在寄存器中
mov bx,1 ; 数据在指令缓冲器中,数据总线从内存读取指令,立即数(idata)随之进入指令缓冲器
内存寻址方式小结
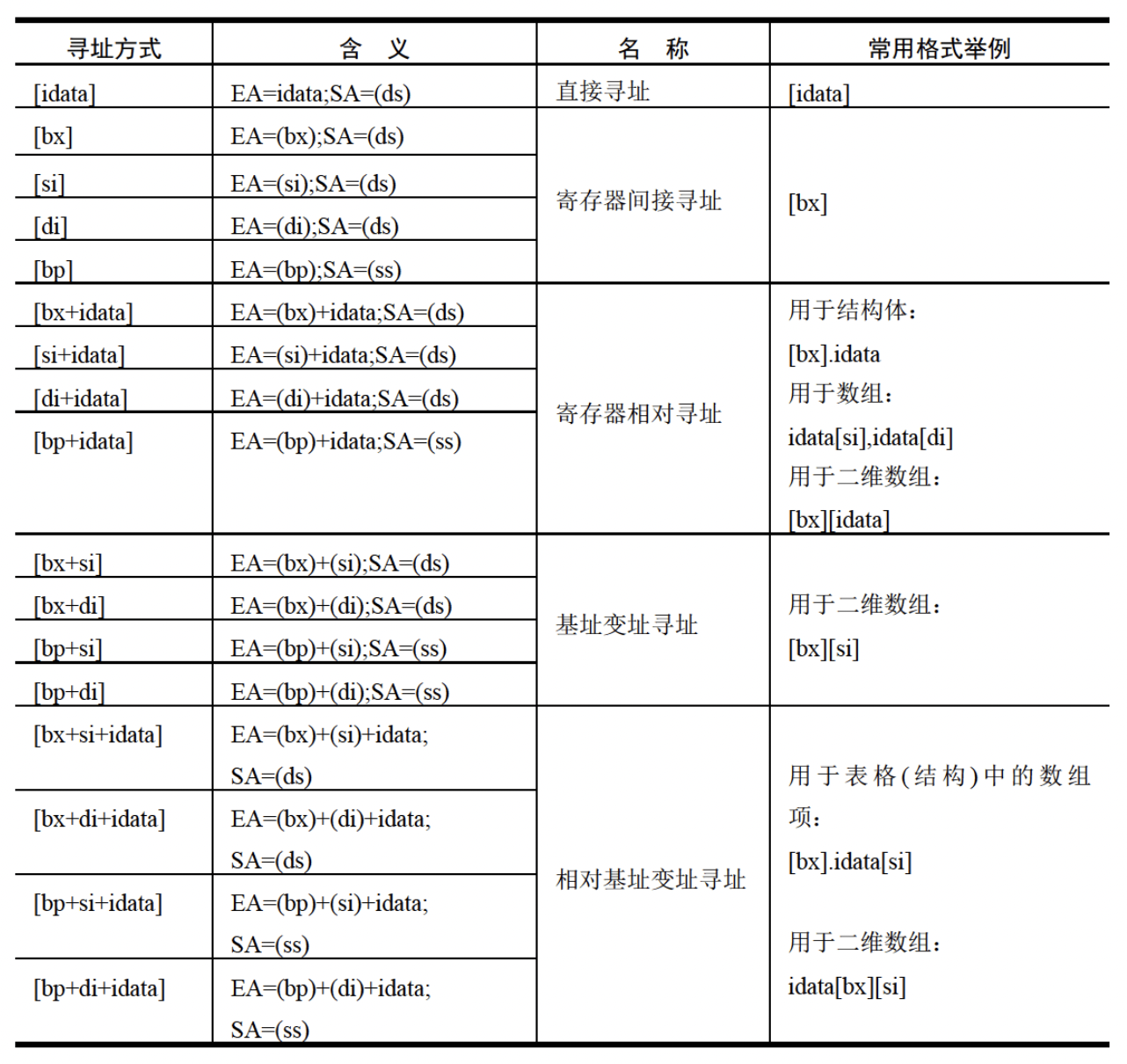
指令要处理的数据长度
- 在有寄存器时,寄存器长度可以确定操作的数据长度
mov ax,[0] ; 字单元
mov al,[2] ; 字节单元
mov bl,1 ; 字节单元
- 当没有寄存器时,通过 X ptr 指明内存单元长度
mov word ptr [bx],1 ; 字单元
mov byte ptr ds:[0],1 ; 字节单元
inc byte ptr ds:[0] ; 字节单元
- 其他情况,如push指令,只针对字单元操作
不同寻址方式的应用
在面对一串连续内存空间,好的解读方式可以更易于理解和处理数据。例如下图数据:

可以将其类比为C语言的结构体变量在内存上的分配:
struct company {
char cn[3]; // 公司名称
char hn[9]; // 总裁名称
int pm; // 排名
int sr; // 收入
char cp[3]; // 著名产品
}
若现在需要将排名修改成38,收入增加70,著名产品变为VAX,那么可以通过如下代码实现:
mov ax,seg
mov ds,ax
mov bx,60
mov word ptr [bx+0ch],38
add word ptr [bx+0eh],70
mov byte ptr [bx+10h+0],'V'
mov byte ptr [bx+10h+1],'A'
mov byte ptr [bx+10h+2],'X'
若将这段数据看作结构体处理,可以更换语法,让程序更容易理解。汇编提供了[bx].idata和[bx].idata[si]的语法,用bx定位结构体,用idata表示某个成员,用si表示某个成员数组的某一项。
mov ax,seg
mov ds,ax
mov bx,60
mov word ptr [bx].0c,38
add word ptr [bx].0e,70
mov si,0
mov byte ptr [bx].10[si],'V'
inc si
mov byte ptr [bx].10[si],'A'
inc si
mov byte ptr [bx].10[si],'X'
这和C语言语法是相似的。
dec.pm = 38;
dec.sr += 70;
int i = 0;
dec.cp[i] = 'V';
i ++;
dec.cp[i] = 'A';
i ++;
dec.cp[i] = 'X';
dd、dup
db、dw、dd、dup命令都是开辟内存单元,也都由编译器处理的伪指令。
-
db
申请一个字节 -
dw
申请一个字 -
dd
申请两个字 -
dup
与前三个命令搭配使用,达到重复申请的效果。如db 3 dup (0,1,2)等价于db 0,1,2,0,1,2,0,1,2。想要申请200个字节单元,不需要写出200个0,用db 200 dup(0)即可。
div
div命令用作除法运算。语法为div <寄存器> 或 div <内存单元>。div后面跟的是除数。
div命令面对8位除数和16位除数,有不同的处理方式:
- 当除数为8位时:
如div al 或 div byte ptr [bx],此时被除数需要以16位方式存储,且被除数存于ax寄存器中。运算结束后,al(8位)存储商,ah(8位)存储余数。
- 当除数为16位时:
如div ax 或 div word ptr [bx],此时被除数需要以32位方式存储,除数需要存储在ax和ds两个寄存器中,且dx存储高位,ax存储低位。运算结束后,ax(16位)存储商,dx(16位)存储余数。
总结来说,“被除数” 是 “除数” 和 “结果” 位数的2倍。(16-8-8、32-16-16)
目前来看,div指令运算是有溢出风险的,需要遵循:被除数高位要小于除数这一原则。
总结易错点
- 计算ds地址
当没有指定ds:data时,需要自行计算段大小,借助cs减去段长度,获取正确数据段地址。
比如段长为0230h,计算ds时,减去的是023h,不是0230h。
mov ax,cs
sub ax,023h
mov ds,ax
- 混淆高位低位
内存地址由低到高存放,比如 a4 37,写成16进制数为 37a4h。
mov ax,[bx]
mov dx,[bx+2]
div [si]
- 使用bp忘指定段寄存器
没有指定段寄存器,bp默认段寄存为ss,0[bp] = ss * 16 + bp + 0。
ds:0[bp]
- 步长加错
在循环中,需要分清处理数据的长度,是几个字节,然后决定步长是 +1 还是 +2 。
inc si
add si,2
- 16进制和10进制运算出错
分清做运算的两个数是几进制,保证相同进制运算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号