TCP、UDP、HTTP
TCP可靠机制
序列号
TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
校验和
TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。 TCP 的接收端会丢弃重复的数据。
流量控制
TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
拥塞控制
当网络拥塞时,减少数据的发送。
慢开始: 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。 拥塞避免: 拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送放的 cwnd 加 1.
快重传与快恢复:
在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
ARQ 协议
也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
超时重传
当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段
参考资料:https://javaguide.cn/cs-basics/network/
TCP与UDP区别
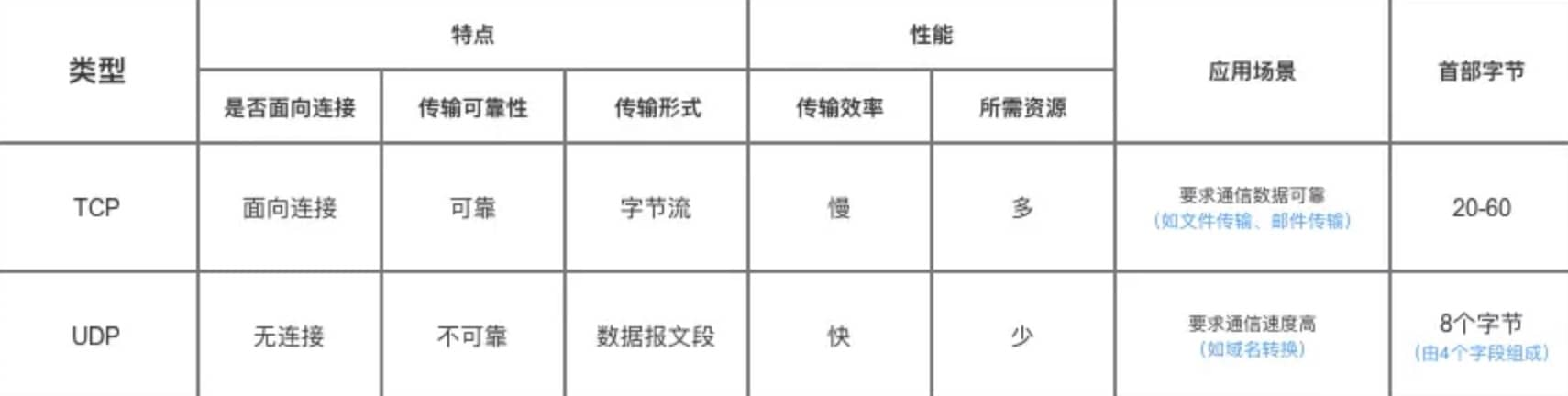
UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 却是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等。
TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务,增加了许多开销。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
TCP三次握手与四次挥手
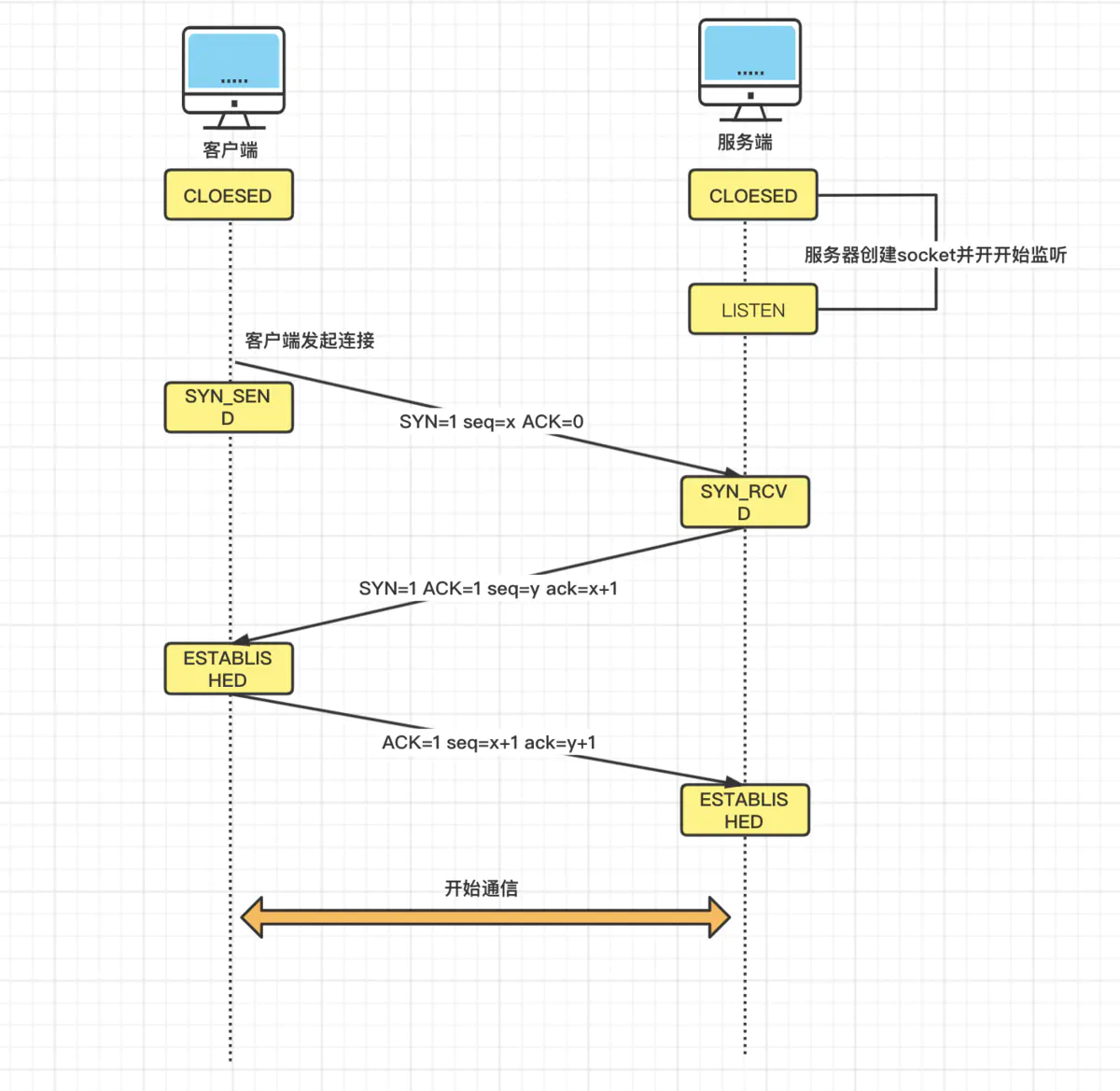
三次握手:
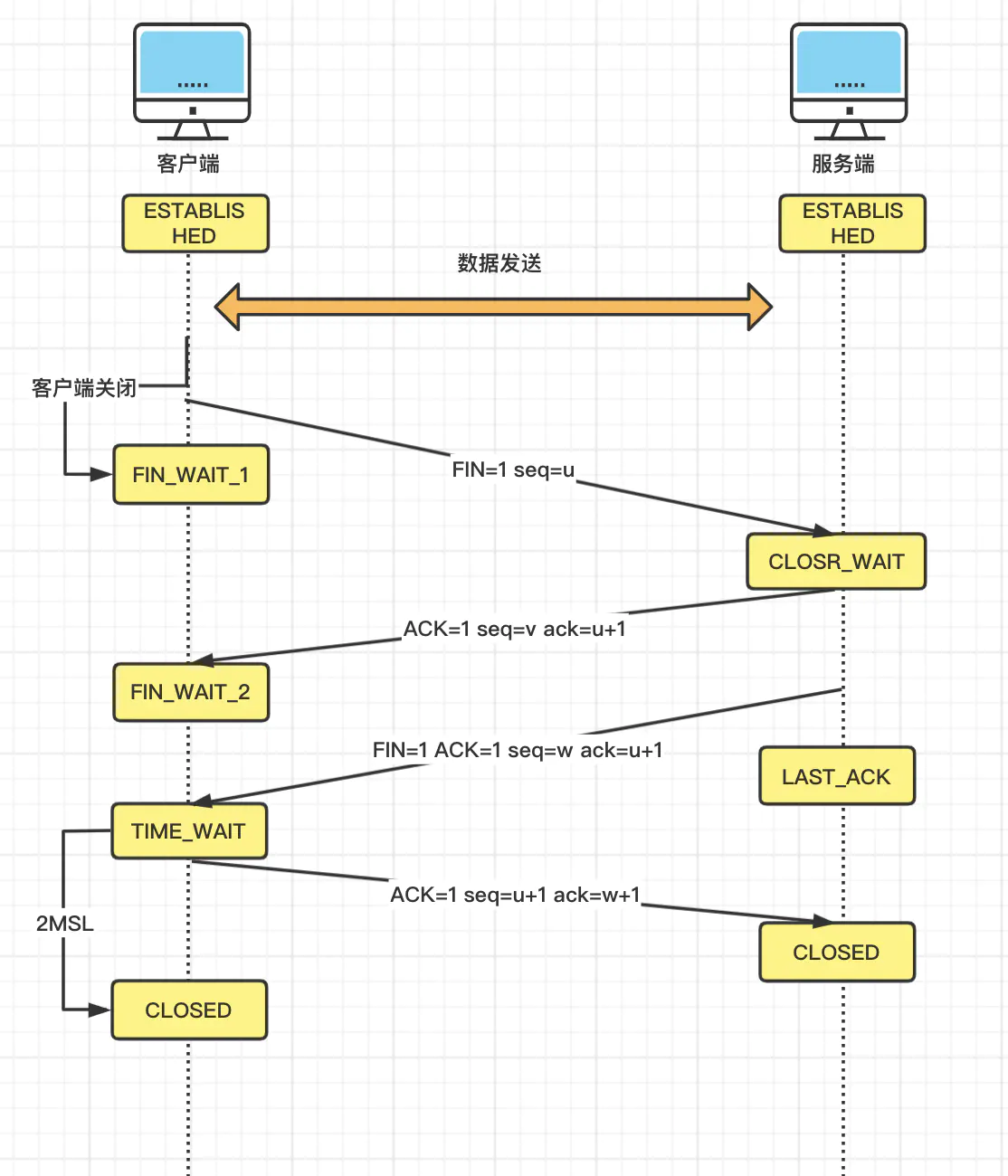
四次挥手:
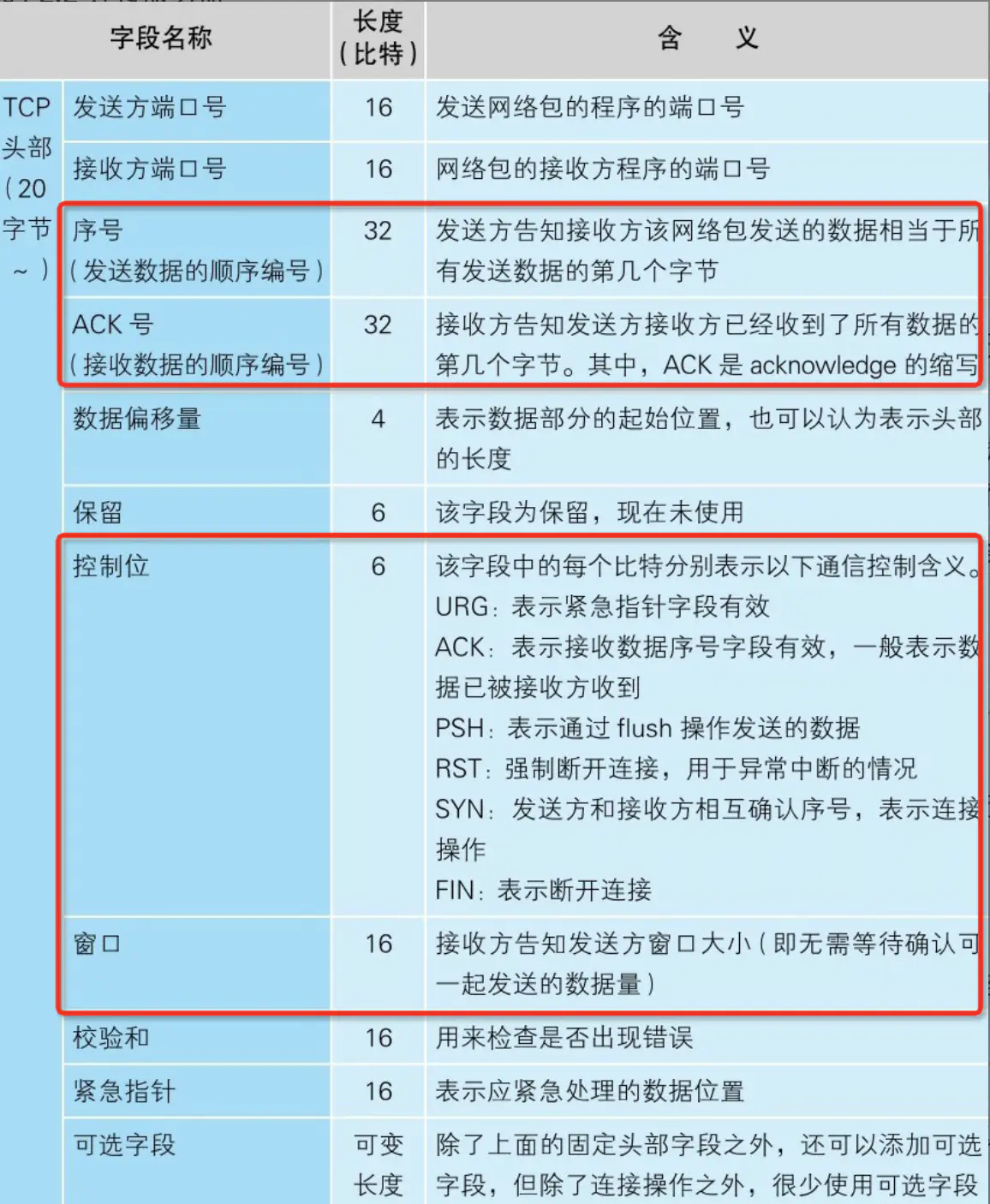
TCP包头部结构
TCP不同阶段状态
LISTEN:表示服务器端的某个SOCKET处于监听状态,等待客户端的连接
SYN-SENT:客户端发送syn请求连接服务器端时的状态
SYN-RECEIVED:服务器端收到客户端的请求连接syn报文时处于的状态
ESTABLISHED:TCP连接建立成功时的状态
FIN-WAIT-1:当客户端向服务端发起断开连接FIN报文后,进入此状态,等待服务端ACK确认
FIN-WAIT-2:当客户端收到服务端对FIN报文的ACK后,进入此状态。此时该连接为半连接,如果被动关闭方一直不进行关闭,那么该客户端socket将一直保持该状态
CLOSE-WAIT:当服务端确认了客户端的FIN关闭报文之后进入此状态;此时服务端 可能有一些数据需要处理
LAST-ACK:当被动关闭方发送FIN关闭报文之后,就进入该状态等待最终客户端的ACK确认
TIME-WAIT:当主动关闭方收到被动关闭方的FIN关闭报文并进行ACK确认之后,主动方会进入此状态,并且等待2MSL
CLOSED:关闭状态
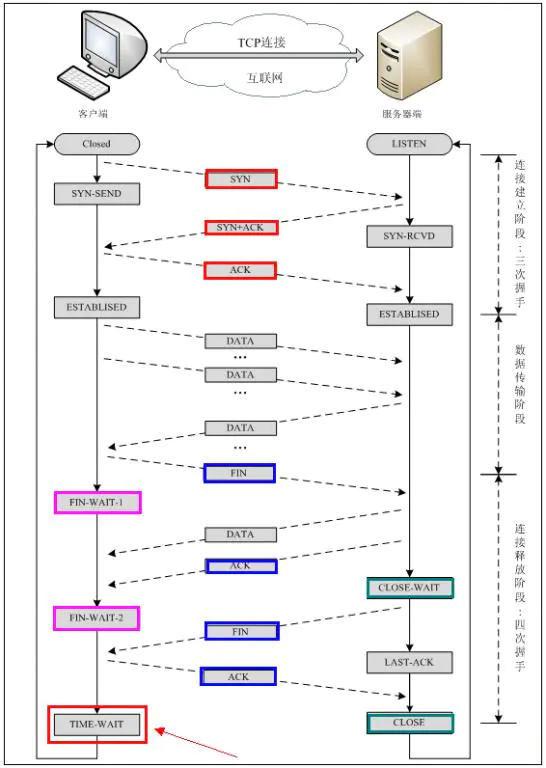
为什么客户端还需等待2MSL?
客户端在收到服务端的FIN包后进入TIME_WAIT状态,向服务的返回ACK包,并等待2MSL。(MSL指的是TCP包在Internet中可生存的最长时间)
如果该ACK包在网络上丢失,会导致服务端重发FIN包。而客户端如果复用了该socket连接(原socket进程关闭,启动的新进程恰好也使用该端口),就会让新socket进程收到FIN包。导致进程间通信混乱。
前往服务端ACK包失效,前往客户端FIN包重发,这两个包最多需要2MSL。如果等待1MSL,仍会导致上述问题。
总结来说:
1.防止旧的数据包被复用的连接接收,经过2MSL可以确保原来连接发送的数据包在网络中消失
2.保证连接正确关闭,当服务端收不到ACK时会重发FIN等待新的ACK,TIME_WAIT等待时间也会被重置
参考资料:https://www.jianshu.com/p/bdd45925bc3e
为什么是三次握手不是两次、四次?
两次握手不够,四次握手冗余。三次握手刚好可以互相确认对方接受和发送消息的功能是ok的。
三次握手的目的还有同步序列号,即seq。TCP的超时重传和流量控制等机制都依赖同步序列号。
除此之外,三次握手还可以防止使用旧的连接。
为什么是四次挥手?
服务端收到FIN包后,需要返回ACK包告知客户端已经知道需要关闭。但此时服务端可能还在处理某些数据,因此不会立即关闭,在CLOSE_WAIT状态停滞一会后,发送FIN包给客户端,告知客户端服务端已经处理完全部数据,可以关闭连接了。客户端成功关闭,返回一个ACK包给服务端,服务端结束LAST_ACK状态,进入CLOSED状态。
SYN包什么时候会被丢弃?
情况1: accept队列满了。
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:半连接队列,也称 SYN 队列;全连接队列,也称 accepet 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
在服务端并发处理大量请求时,如果 TCP accpet 队列过小,或者应用程序调用 accept() 不及时,就会造成 accpet 队列满了 ,这时后续的连接就会被丢弃,这样就会出现服务端请求数量上不去的现象。
参考资料:https://www.jianshu.com/p/34b38fe067f4
TCP不同情况下断开会发生什么?
不同情况导致TCP连接断开:
- 在进程崩溃时,会由操作系统内核代劳TCP四次挥手
- 当 TCP 连接建立后,如果某一方断电或断网,如果此时刚好正在发送数据,TCP 数据包发送失败后会重试,重试达到上限时也会断开连接
- 当 TCP 连接建立后,如果某一方断电或断网,且这条连接没有数据传输时
- 如果开启了 KeepAlive 则会在一定心跳检测后断开连接,这个默认检测时间大概2个多小时,比较久
- 如果未开启 KeepAlive 则连接永远存在
- 断电断网重启后
- 如果client给server发送消息,server会返回RST包强制断开连接。
- 如果不发送消息,仍然保持连接。
参考资料:https://www.jianshu.com/p/7cf6d18a5f7a
TCP三次握手如何优化?
1、减少超时重传次数,尽快将超时错误反映到程序中
2、增大半连接和全连接队列长度,可容纳更多连接
3、开启syncookie应对SYN泛洪攻击
4、客户端首个SYN包就携带数据,建立在双方信任的基础上
参考资料:https://www.jianshu.com/p/be30d4eeb191
HTTP与TCP
一次http请求后,tcp会立即断开连接吗?
在 HTTP/1.0 中,一个服务器在发送完一个HTTP 响应后,会断开 TCP 链接。但是这样每次请求都会重新建立和断开 TCP 连接,代价过大。所以虽然标准中没有设定,某些服务器对 Connection: keep-alive 的 Header 进行了支持。这样的好处是连接可以被重新使用,之后发送 HTTP 请求的时候不需要重新建立 TCP 连接,以及如果维持连接,那么 SSL 的开销也可以避免,
既然维持TCP 连接好处这么多,HTTP/1.1 就把 Connection 头写进标准,并且默认开启持久连接,除非请求中写明 Connection: close,那么浏览器和服务器之间是会维持一段时间的 TCP 连接,不会一个请求结束就断掉。
一个 TCP 连接可以对应几个 HTTP 请求?
因为一个HTTP请求结束并不会关闭TCP连接,所以一个 TCP 连接是可以发送多个 HTTP 请求的。
一个 TCP 连接中 HTTP 请求发送可以一起发送么(比如一起发三个请求,再三个响应一起接收)?
在 HTTP/1.1 存在 Pipelining 技术可以完成这个多个请求同时发送,但是由于浏览器默认关闭,所以可以认为这是不可行的。在 HTTP2 中由于 Multiplexing 特点的存在,多个 HTTP 请求可以在同一个 TCP 连接中并行进行。
那么在 HTTP/1.1 时代,浏览器是如何提高页面加载效率的呢?主要有下面两点:
维持和服务器已经建立的 TCP 连接,在同一连接上顺序处理多个请求;和服务器建立多个 TCP 连接。
HTTP/1.1 Pipeling解决方式为,若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞;
HTTP/2多个请求可同时在一个连接上并行执行。某个请求任务耗时严重,不会影响到其它连接的正常执行;
为什么有的时候刷新页面不需要重新建立 SSL 连接?
TCP 连接有的时候会被浏览器和服务端维持一段时间,TCP 不需要重新建立,SSL 自然也会用之前的。
浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
有。根据浏览器的设置而定,Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
参考资料:https://www.jianshu.com/p/67d5d46b4e84
HTTP1.0、1.1与2.0
HTTP1.0与1.1的区别
1、缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
2、带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
3、错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
4、Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
5、长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
HTTP2.0新特性
1、新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
2、多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
3、header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
4、服务端推送(server push),当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。
参考资料:https://www.cnblogs.com/heluan/p/8620312.html
HTTPS请求过程
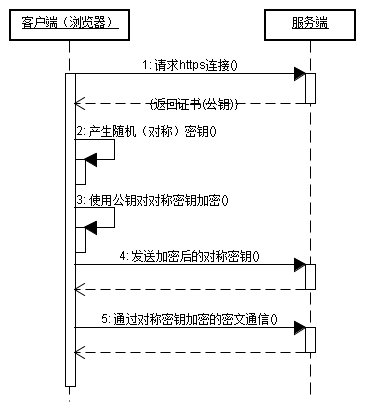
原始的https中,服务端返回公钥是明文传输,存在被劫持的风险。后引进CA证书,即服务端需要使用公钥请求CA机构返回加有数字签名的证书,然后再想客户端返回该证书。
客户端需向CA机构请求验证证书合法性,才会信任证书中的公钥。
HTTP与HTTPS区别
1、http是明文传输的,不安全。https是加密传输的
2、https在tcp3次握手后还需要进行tls四次握手
3、http端口是80,https端口是443
4、https需要向CA申请数字证书来保证服务端身份可信
TLS四次握手:
1、客户端发送 TLS版本号/客户端随机数/密码套件
2、服务端发送 TLS版本号/服务端随机数/选择的密码套件
3、客户端验证完证书,随机生成一个随机数,用RSA公钥加密该随机数,发送给服务端,服务端收到后用RSA私钥解密,得到随机数,结合三个数生成会话密钥
4、服务器发Change Cipher等消息通知使用加密方式发送信息
参考资料:https://blog.csdn.net/qq_35642036/article/details/82788421

 浙公网安备 33010602011771号
浙公网安备 33010602011771号