KMP 求子串算法
参考:mooc浙大数据结构
https://www.icourse163.org/learn/ZJU-93001?tid=1459700443#/learn/content?type=detail&id=1235254085&cid=1254945340
kmp算法的本质是:
1、当指针 i 指向的 字符s[i] 和指针 j 指向的 字符p[j] 不相同时,指针 i 不回退,指针 j 回退。(对比暴力算法是,指针 i 回退到之前位置的下一个位置,指针 j 直接回退到0)
2、然后根据p的相同前后缀处理出来一个数组,记录着每次不匹配时,j 指针应该回退的位置。
记录指针回退位置的数组称为match数组,match[i]表示的是:
字符串p中,下标从0到i这段区间内,找到最长的且相同的前后缀,该前缀最后一个字符的下标。如果0-i区间内没有子串,那么记录match[i]=-1

构建match数组时的思想类似动态规划,在求match[i]时,假设match[i]之前的元素都已经被求出。那么
1、如果p[j] == p[match[j - 1] + 1] 那么 match[j] = match[j - 1] + 1
2、如果p[j] != p[match[j - 1] + 1] 那么 比较 p[j] 是否和 p[match[match[j - 1]] + 1]相同,如果相同 match[j] = match[match[j - 1]] + 1
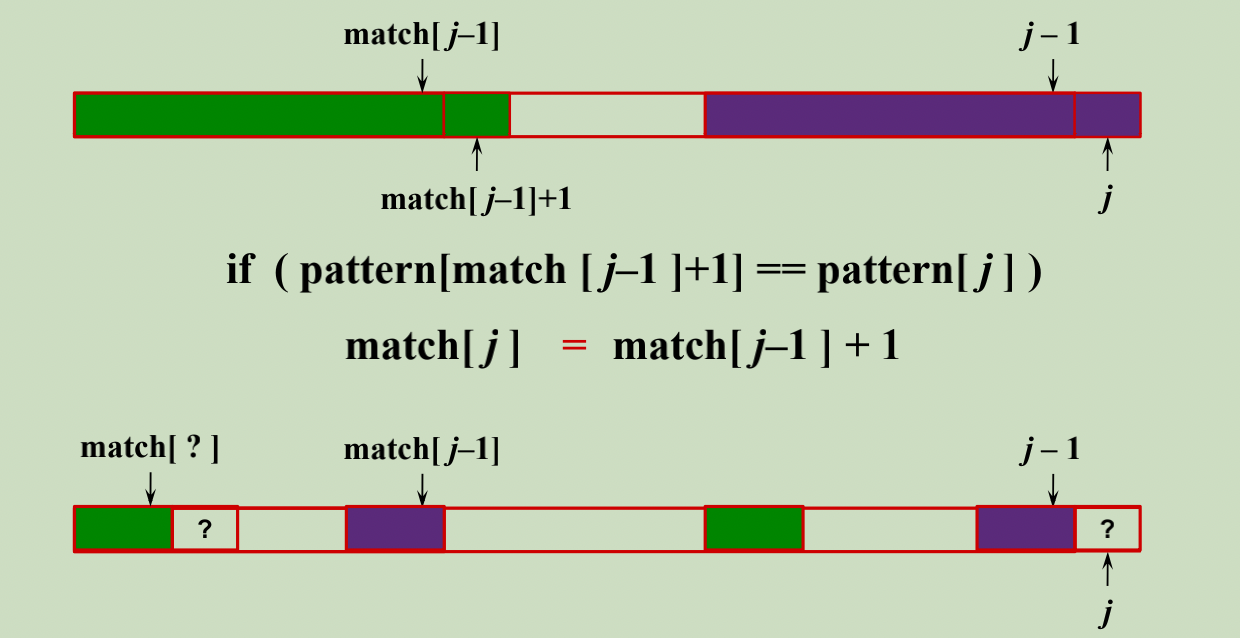
解释:这里绿色和紫色区间表示相同的前后缀,当求match[j]时,该位置的字符和前缀的后一个字符相同的话,就最好了,直接可以使得match[j]在原有前缀下标基础上加一。
但是如果不幸运,达不到这么理想的情况。还可以继续向前比较,因为绿色区间内本身也是可以分成相同的前后缀的,所以这里的四小块都是相等的,于是我们看看第j个字符是不是和更前面的前缀的下一个字符相等。
参考例题:https://www.acwing.com/problem/content/833/
#include<iostream>
#include<string>
using namespace std;
const int N = 1e5 + 10;
int n, m;
string p, s;
int match[N];
void build() {
match[0] = -1;
for (int i = 1; i < n; i ++) {
int idx = match[i - 1];
while (idx >= 0 && p[i] != p[idx + 1])
idx = match[idx];
if (p[i] == p[idx + 1])
match[i] = idx + 1;
else
match[i] = -1;
}
}
int main() {
cin >> n >> p >> m >> s;
build(); // 构建match数组
int i = 0, j = 0;
while (i < m) {
while(i < m && j < n) {
if (s[i] == p[j]) i ++, j ++;
else if (j > 0) j = match[j - 1] + 1;
else i ++;
}
// 找到一个子串,继续寻找下一个子串
if (j == n) {
cout << i - n << " ";
j = match[j - 1] + 1;
}
}
return 0;
}
