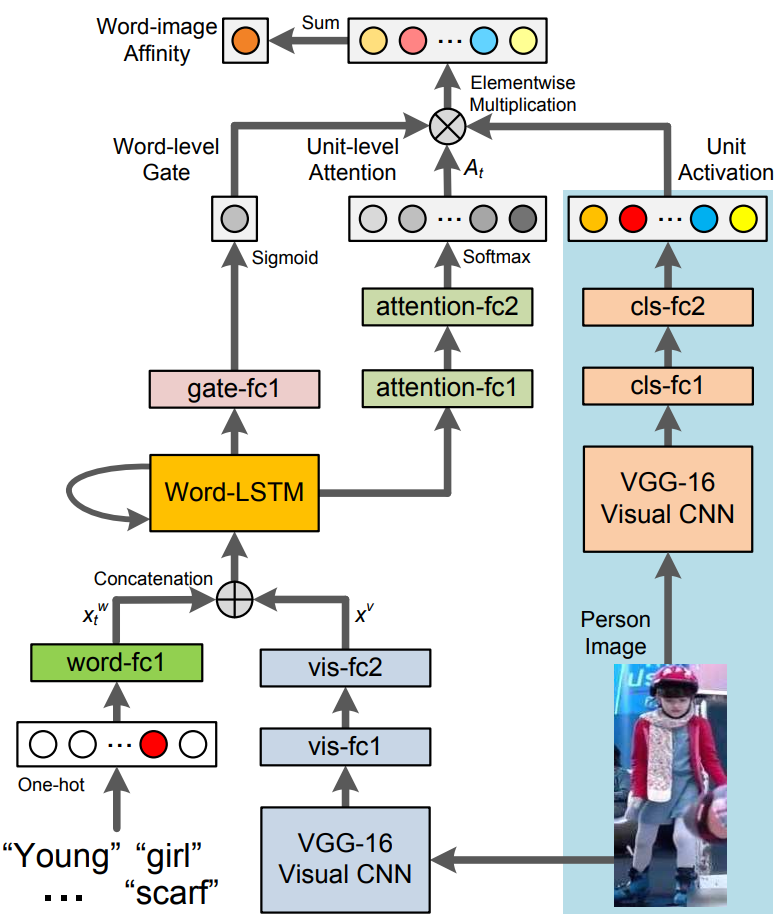
论文阅读笔记(六十八):图文跨模态行人检索(3篇)
1. Pose-Guided Multi-Granularity Attention Network for Text-Based Person Search【AAAI2020】

(1) 视觉特征提取:
作者认为人体姿态信息可以引导局部特征的匹配,因此引入了2017年提出的PAF模型进行姿态估计,提取14个关键点。由于行人会受到遮挡等情况,关键点也并非精确,其置信图如下图所示。关键点置信图存在两个作用:
① 与原图的3个通道级联,得到17通道的初始数据,输入VGG-16 (ResNet-50也同理)中,提取[12, 4, 512]尺寸的特征图,再将特征图按PCB的策略划分为6个条纹,每个条纹在第一个维度上取平均,得到尺寸为[6, 4, 512]的特征图,将其视为24个局部,每个局部对应512维特征向量。
② 14个置信图被用于与名词短语之间的语义对齐。

(2) 文本特征提取:
文本特征采用Bi-LSTM提取,其中名词短语采用2002年提出的NLTK进行查找,并同样用Bi-LSTM提取名词短语的特征。
(3) Coarse Alignment Network:
用余弦相似度计算每个图像局部区域和整体文本的特征相似度![]() ,最终整体图像与整体文本的相似度得分为:阈值
,最终整体图像与整体文本的相似度得分为:阈值![]() =1/24
=1/24
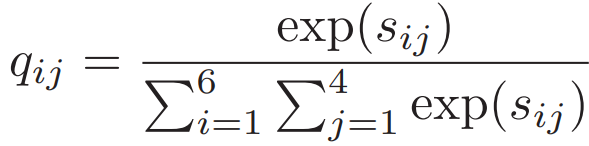
![]()
(4) Fine-Grained Alignment Network:
14个关键点被划分为6个身体区域,每个区域的特征图相加,并通过Pose CNN投影为b维的特征向量,即:![]() ,每个名词短语特征都投影到相同的特征维度,即:
,每个名词短语特征都投影到相同的特征维度,即:![]() 。计算第1个区域的文本特征,即:
。计算第1个区域的文本特征,即:

![]()
其余5个区域的文本特征同理。相同的机制也应用到了视觉特征,即:![]() 。
。
图文细粒度的相似度为:
![]()
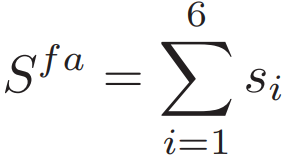
(5) 损失函数:
采用了Identify-aware的思想,对不同模态采用了ID损失。并对不同模态之间采用了三元组损失。对姿态的特征p进行分类损失,使得这6个特征能表示不同类别。
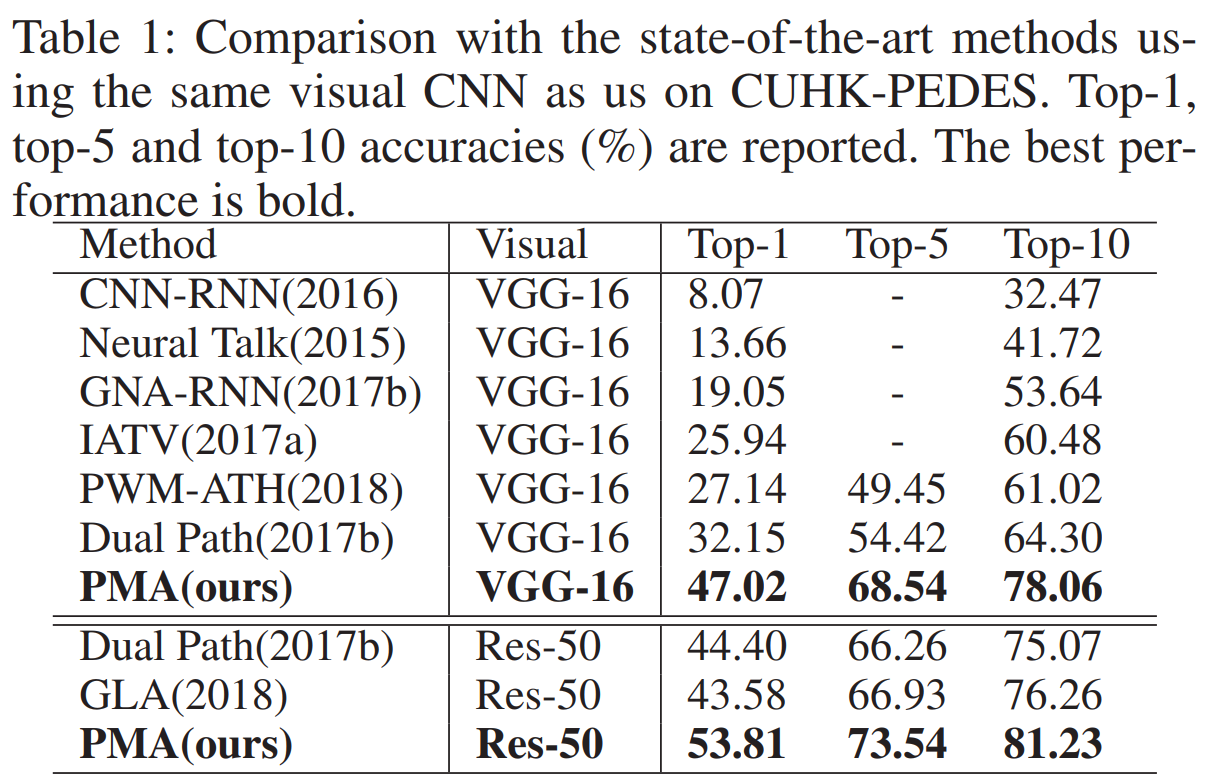
(6) 实验结果:
2. ViTAA: Visual-Textual Attributes Alignment in Person Search by Natural Language【arXiv2020】
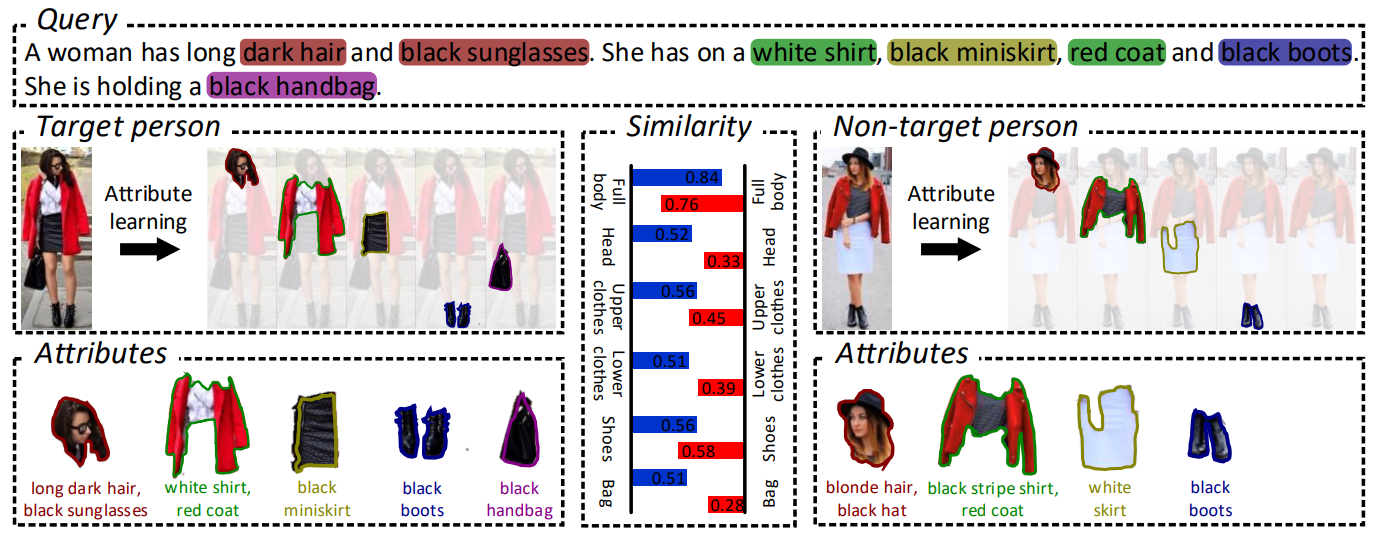

(1) Align Loss:
采用余弦相似度评估图文特征距离,即:![]()
约束表示为:![]()
具体化为Alignment Loss为:
(2) K-reciprocal Sampling:
通俗理解为:找到包含同一个属性且互相最相似的样本对。

(3) 实验结果:

3. Person Search with Natural Language Description【CVPR2017】