论文阅读笔记(五十八)【arXiv2019】:Visual-Textual Association with Hardest and Semi-Hard Negative Pairs Mining for Person Search
Introduction
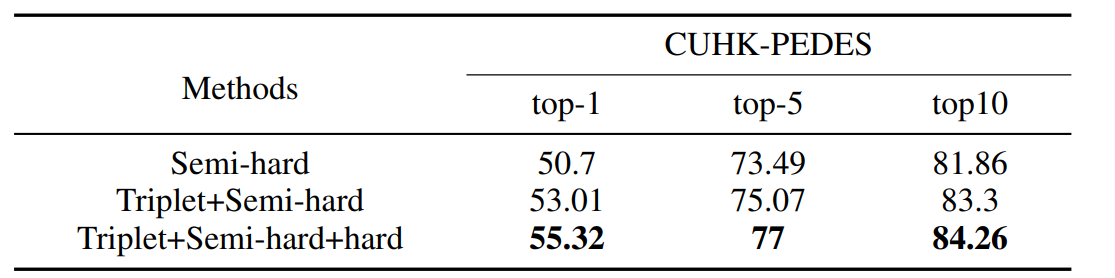
提出了一个Smoothed Global Maximum Pooling (S-GMP),使得提取的视觉特征与文本特征更加一致; 提出一个基于bi-LSTM的memory attention模块,使得提取的语义特征更具有针对性;在损失函数上,结合了单模态三元组损失和跨模态难样本挖掘交叉熵损失。
Proposed Method
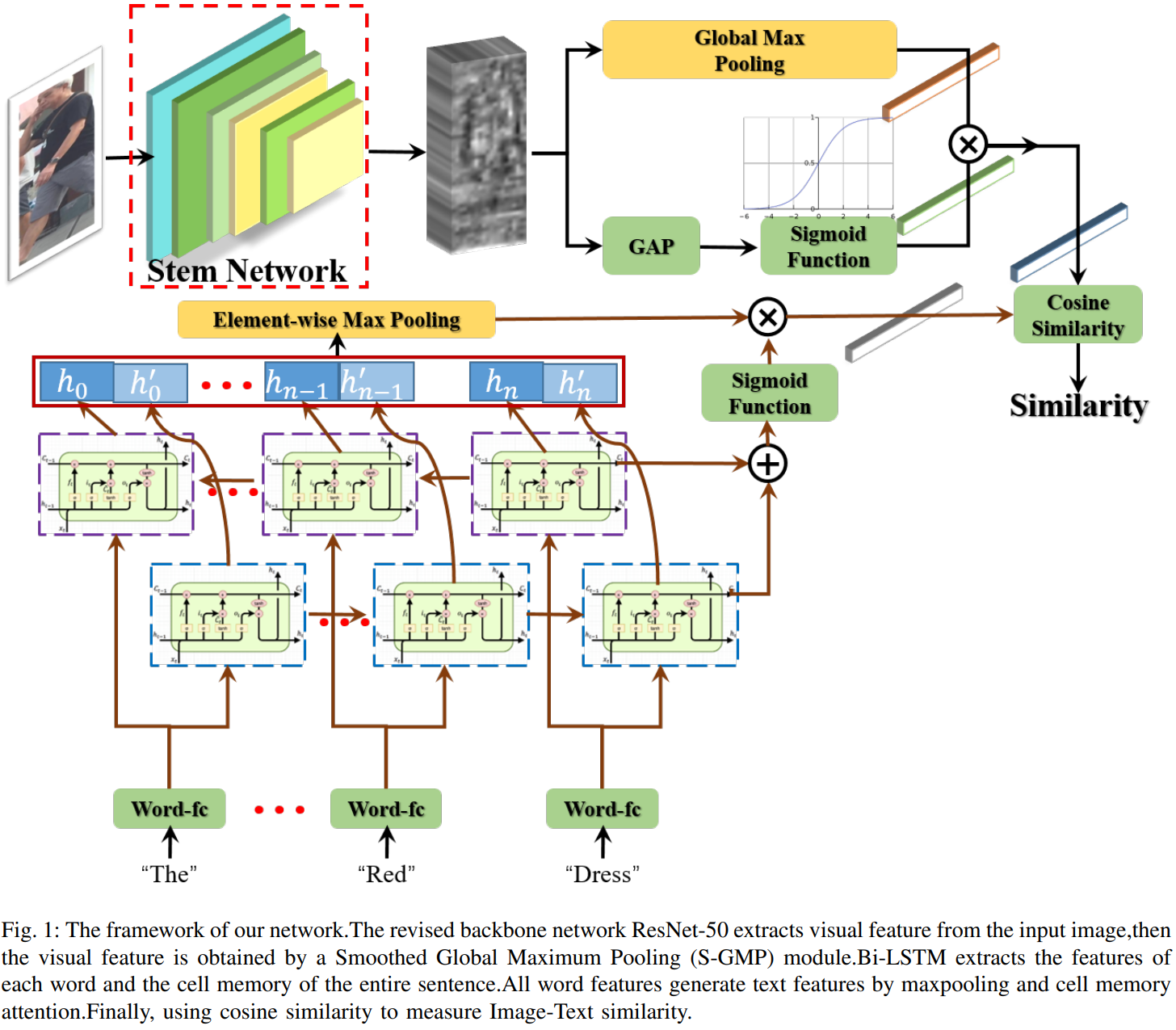
从图中直观感受是在两个特征提取分支上加入了注意力机制。
1) 视觉特征提取网络 (S-GMP):采用了ResNet50作为骨干网络,将全局平均池化的输出作为注意力的权重,对全局最大池化的输出进行加权。
2) 文本特征提取网络 (Memory Attention):将最后一个词向量通过LSTM的输出作为注意力模块的输入,因为最后一个LSTM的输出包含了整个文本的信息。bi-LSTM的所有单词的输出通过了最大池化,即在每个特征维度取最大值,得到整个文本的特征,最后通过注意力加权得到新的特征向量。
3) 在距离度量采用了consin相似度,并采用sigmoid进行归一化。交叉熵损失为:
![]()
4) 模态内的三元组损失:
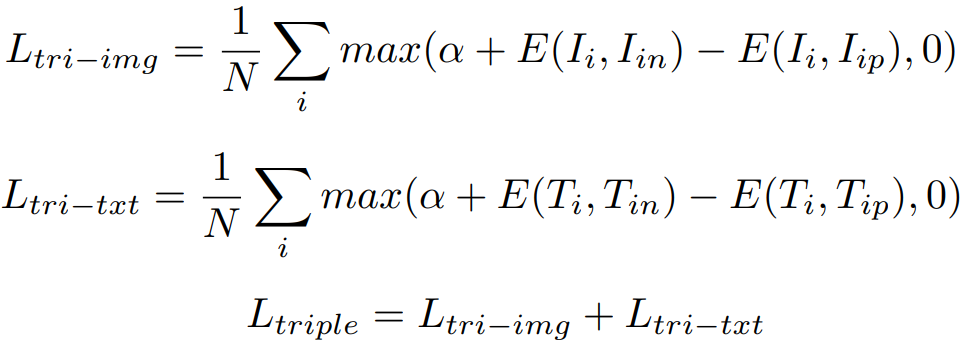
5) 模态间难样本损失:
寻找cosine相似度最高的负样本作为一组难样本对:
![]()
寻找特征向量距离最近的负样本作为一组难样本对:
![]()
6) 正样本损失:
![]()
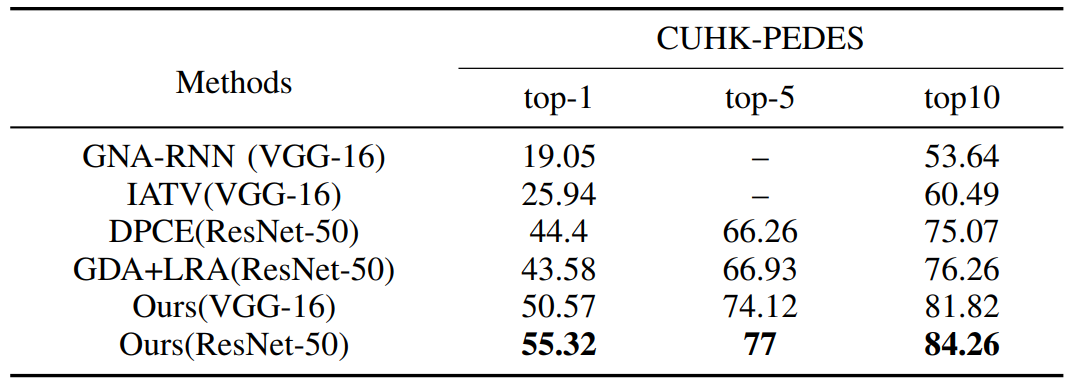
Experiments
实验设置:学习率2x10-3,想70次和90次迭代时下降0.1,batch size = 64 (64个ID,128图像,256段文本),采用Adam优化器