论文阅读笔记(五十七)【ICCVW2019】:Fusing Two Directions in Cross-domain Adaption for Real Life Person Search by Language
Introduction
本文认为文本-图像reid的难点包含两方面:1) 文本和图像两者特征差异,2) 域适应 (比如一些文本在训练过程中没有遇到,在测试时就难以适应)。
本文的贡献:1) 提出了一个基于文本的行人检索框架;2) 提出了一个Cross-domain Bi-directional Adaption (CBA)方法来解决域适应的问题。
Proposed Approach
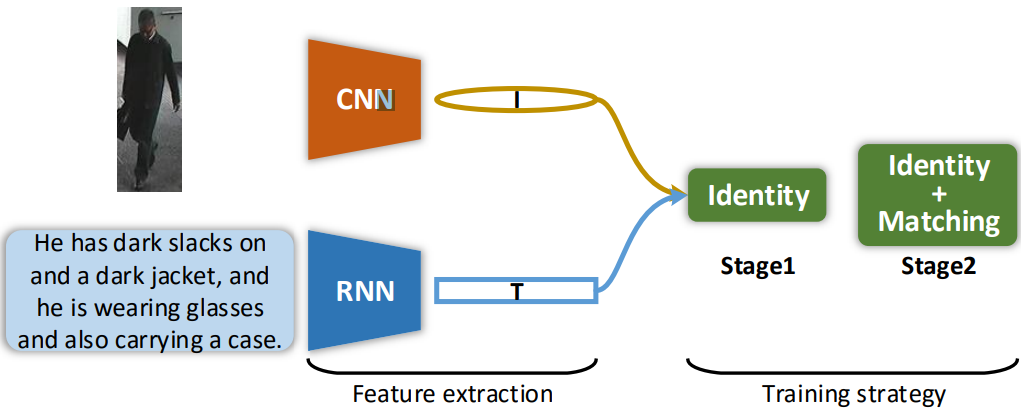
框架结构比较简单,图像采用CNN提取特征,文本采用RNN,在stage1采用交叉熵损失,在stage2再结合进去三元组损失。三元组损失中距离度量函数S采用了consin距离。
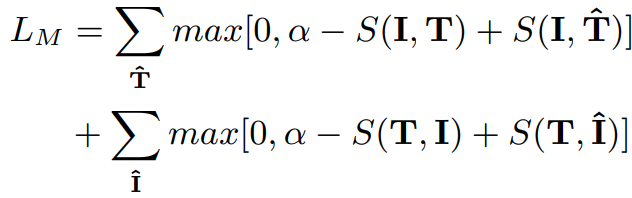
现有的域适应方法只考虑将 source domain 迁移到 target domain,作者提出的CBA方法结合了双向的domain迁移。
1)source→target:
CNN采用ResNet,RNN采用Bi-GRU。首先在CUHK-PEDES上训练两个编码器训练特征提取;再在MSMT17上训练图像编码器 (CNN) 的域适应能力 (文中没有具体介绍域适应的步骤);最后再用适应后的图像编码器,结合之前的文本编码器再次训练,这一步中图像编码器是参数固定的。
2) target→source:
CNN采用Osnet在MSMT17进行预训练 (感觉这样训练不能叫跨域吧?),提取视觉特征,再结合DeepMAR提取属性特征 (这里作者采用了两个在不同数据集上预训练的子模型,区别在于属性的多样性),级联后压缩成新的视觉特征。RNN采用了Bi-LSTM提取文本特征。两者在CUHK-PEDES上进行训练。
Experiments
表1:没有设置域适应