论文阅读笔记(五十五)【WACV2018】:Improving Text-based Person Search by Spatial Matching and Adaptive Threshold
Introduction
本文研究是基于文本的行人检索,如下图:

作者先介绍了一下GNA-RNN方法:将每个单词和图像计算相关度,再通过注意力机制进行加权求和获得整个文本与图像的相关度。 本文认为GNA-RNN方法存在一些不足:1)对图像空间中的关键属性感知能力不强(如文本是“黄色衬衫”,会将“黄色短裤”的行人误判);2)对image-word pair关联度过于敏感(对于一个关键词分配的权重可能会非常大。当一张图像完美匹配了绝大部分关键词时,可能会比匹配所有关键词但不完美时关联度更高)。
本文提出了一个patch-word匹配模型,且设计了一个动态阈值机制。不同于其它方法将整张图像进行匹配,此方法计算单词与局部图像块的关联度。对于每个单词都设置一个阈值来判定是否和图像匹配,并对关联度进行一个动态压缩以缓解匹配时的敏感问题。
The Model
Patch-word Matching Model
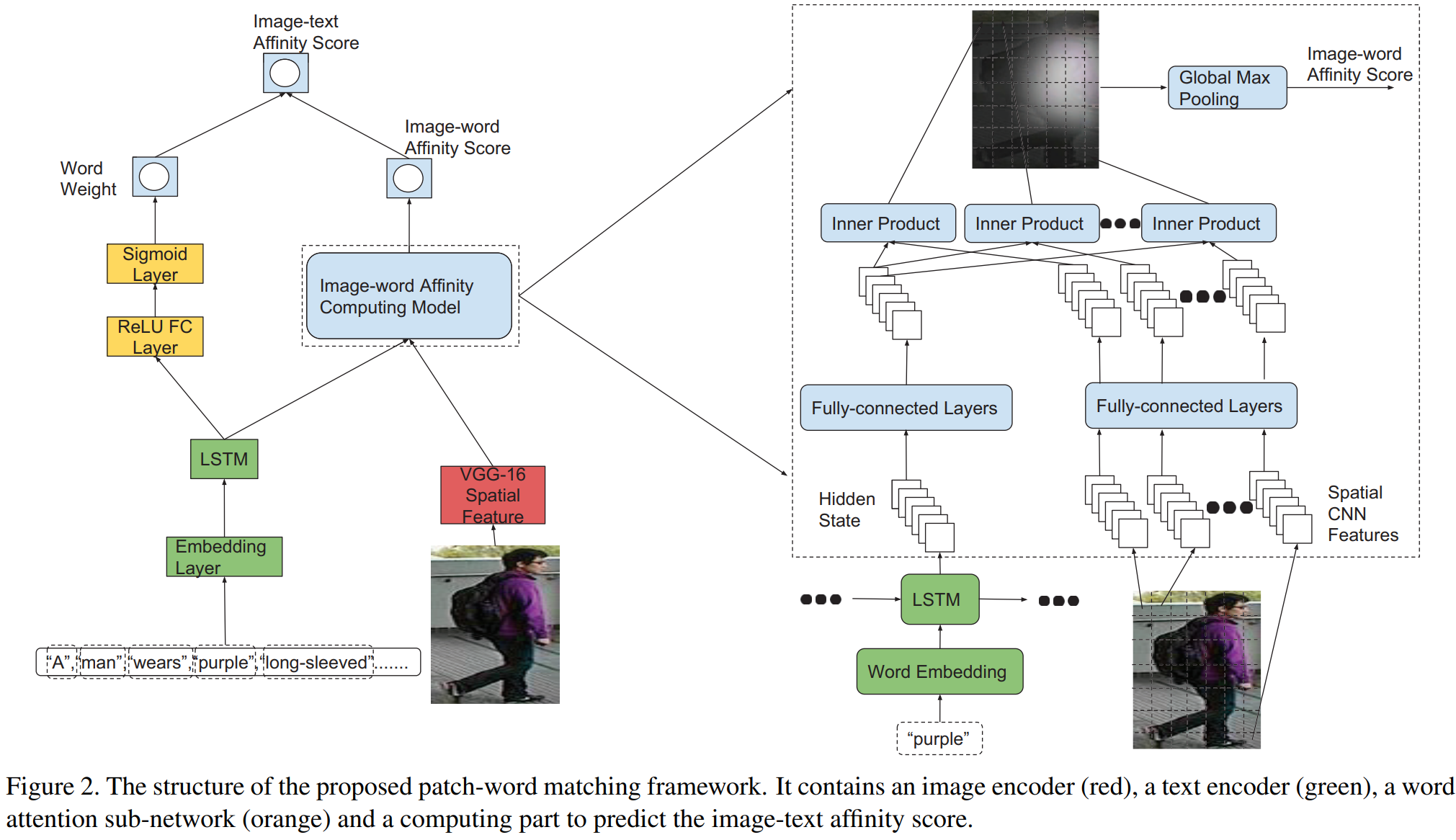
行人图像的特征提取网络采用在ReID数据集上预训练的VGG-16,输出的特征图为7x7x512,在空间上划分成49个patch,每个patch的特征向量为512维。文本的编码器包含一个单词的投影层(word-embedding layer)和LSTM层,单词投影层将每个单词投影为512维的词向量。LSTM把每个词向量的hidden state输出为前文的文本特征。文本特征和图像特征的关联度采用内积的计算方法。最后采用最大池化对49个patch的关联度进行结合。
当输入的短语是“a man wears a yellow shirt”,当输入LSTM是“shirt”时,由于LSTM的记忆性,输出的文本特征能够同时包含“yellow”和“shirt”两者的信息。当图像中的patch同时满足“yellow”和“shirt”时,能够捕获较高的响应;当图像中的patch仅仅满足“yellow”或者“shirt”时,则关联度将比较低。因此本方法能够克服GNA-RNN的第一个不足。
为了计算最终的image-text关联度,作者采用了一个单词注意力子网络,将LSTM输出的hidden state输入FC+Sigmoid得到权重。
训练时选择正样本对与负样本对的比例是1:3,交叉熵损失为:
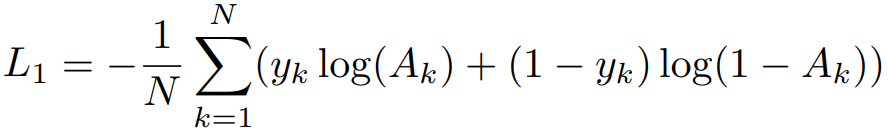
其中![]() 为第k对样本的关联度。学习率设置为0.0004,batch size设置为128,采用Adam优化器。
为第k对样本的关联度。学习率设置为0.0004,batch size设置为128,采用Adam优化器。
Adaptive Threshold mechanism
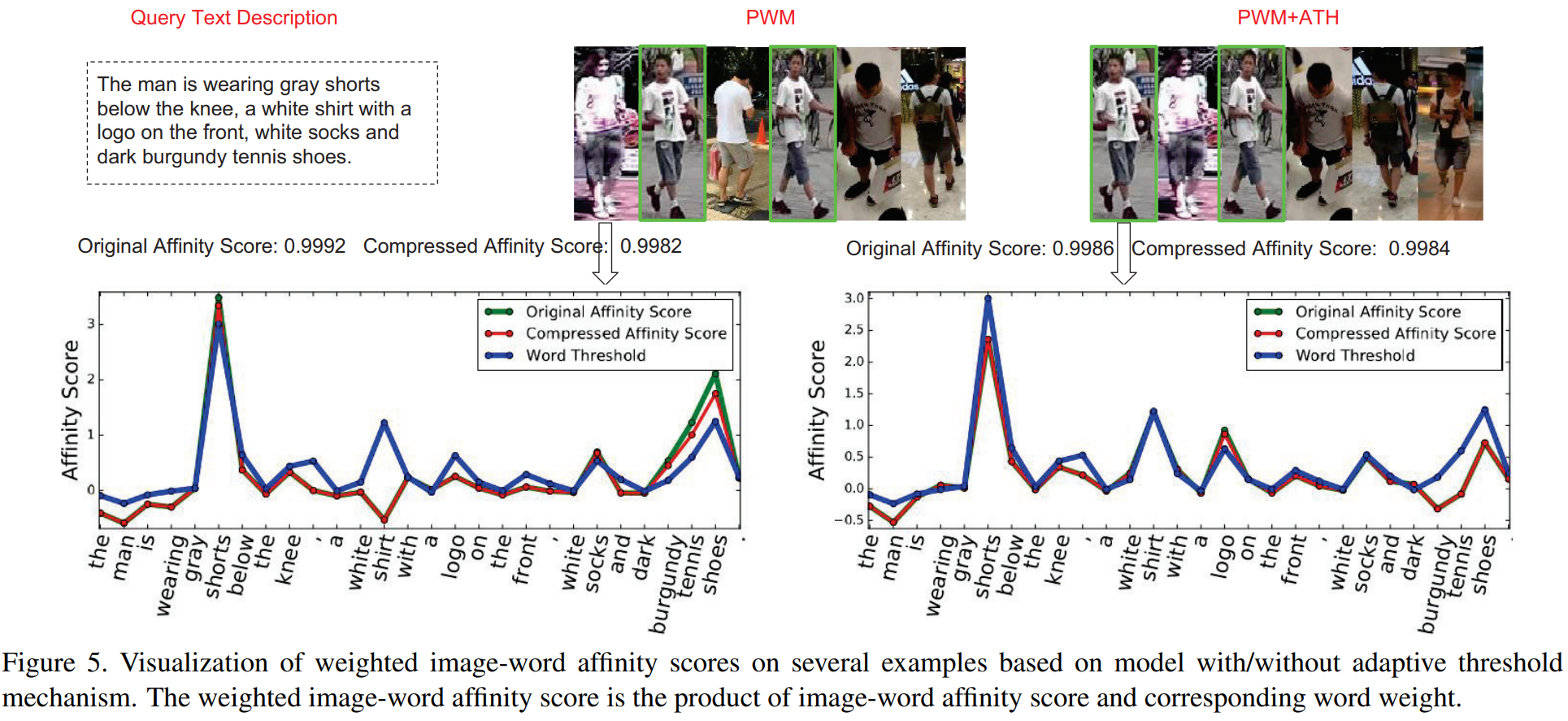
当一个单词的权重比较大时,会对最终的关联度产生很大的影响。当一个无关的图像完美匹配了部分的文本单词,很可能受到权重的影响,而被错误认为是正确选项。因此作者设计了一个动态阈值。只有超过了阈值,才能视为有关联;如果低于这个阈值,则不会被计入最终关联度的计算。
动态阈值机制包含两步骤:1) 学习每个单词的阈值;2) 基于阈值处理关联度。在第一步中,对第 t 个文本第 i 个单词设置阈值标签:![]() ,其中 C 为匹配的图像集合。函数f( )尝试了max、mean、min等方法。 由此训练动态阈值机制:
,其中 C 为匹配的图像集合。函数f( )尝试了max、mean、min等方法。 由此训练动态阈值机制:
![]()
其中![]() 为预测的注意力权重,
为预测的注意力权重,![]() 为第t个文本的单词总数,
为第t个文本的单词总数,![]() 为文本的数量,
为文本的数量,![]() 为用于预测阈值的多层感知机。在第二步中,利用阈值进行权重更新:
为用于预测阈值的多层感知机。在第二步中,利用阈值进行权重更新:
![]()
当权重超出阈值时,作者提出了两种压缩方法:
1) hard compression:![]()
2) soft compression:![]()
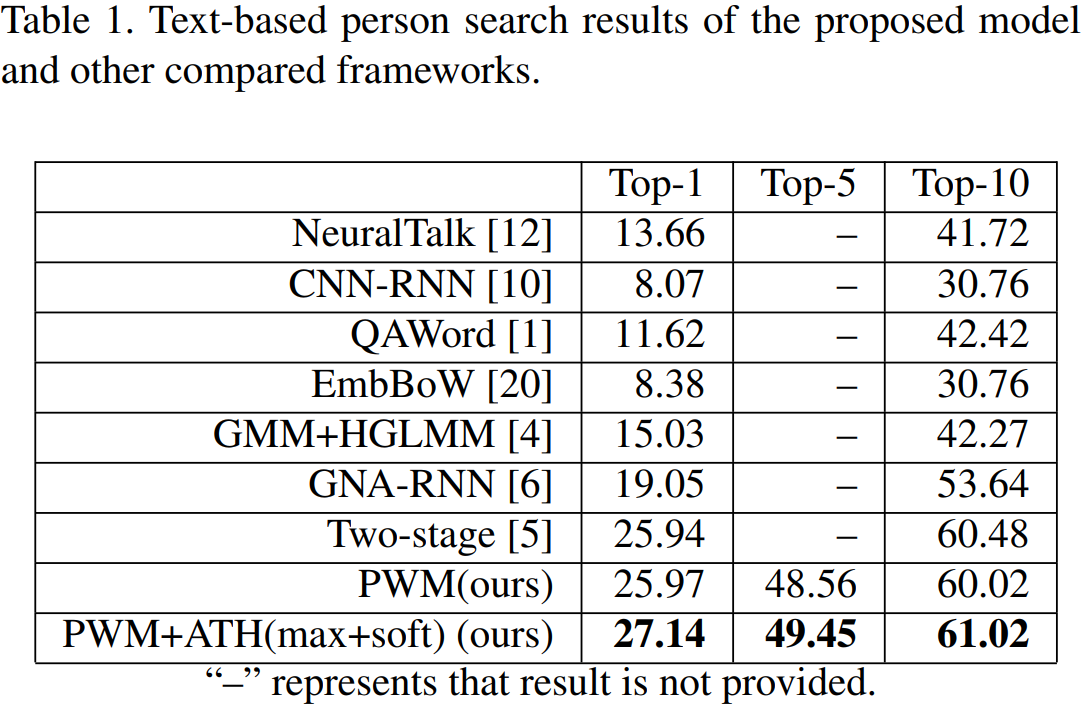
Experiments
数据集:CUHK-PEDES 包含了13003个行人的40206张图像,每张图像对应了2段文本描述。将数据集划分成训练集(11003个行人)、验证集(1000个行人)和测试集(1000个行人)。
实验结果: