论文阅读笔记(五十二)高低分辨率行人重识别 (Part 2)
Cross-Resolution Person Re-identification with Deep Antithetical Learning【ACCV2018】
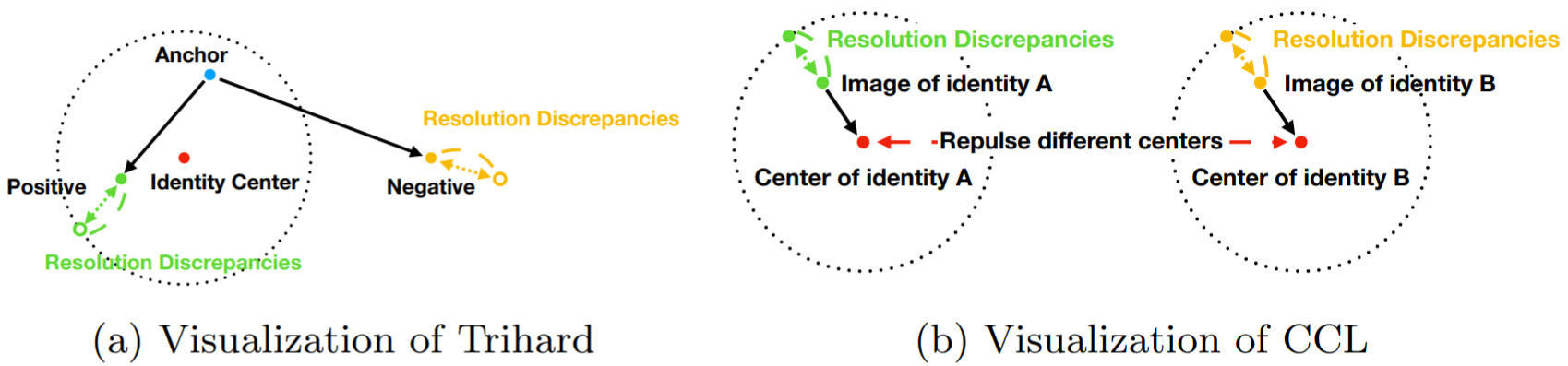
一些LR-HR匹配的方法是把图像映射到一个特征空间中,但这种方法会扰乱原有的图像分布,需要做大量的图像预处理。为此,作者提出了一种deep antithetical learning(深度对偶学习)方法,可以直接从自然的图像空间中学习,而不需要专门创建一个特征空间(作者在测试时候只针对现实场景中的分辨率差异,不对数据集做下采样操作,直接用原始数据)。方法的思路简述:① 依据分辨率对图像进行分类 → ② 创建对偶训练数据集 → ③ 采用Contrastive Center Loss(CCL)对不同分辨率的图像进行学习。
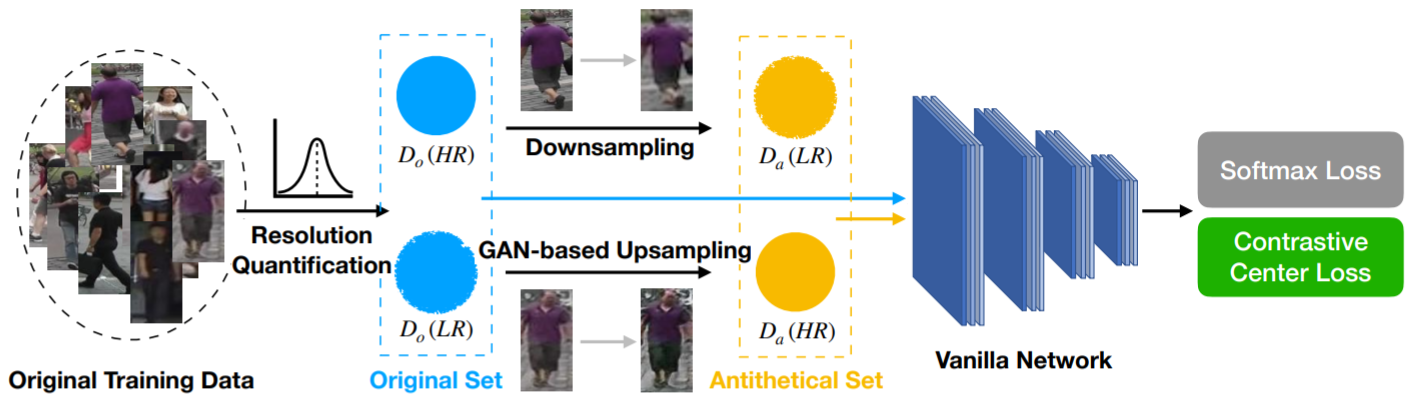
第①步:作者认为,更加锐利的边缘能够提高分辨率在频域中的高频分量。后面采用了傅里叶变换之类的数学处理(没看懂,略),划分成了两个数据子集![]() 和
和![]() 。
。
第②步:对于![]() 中的图像采用下采样获取LR集合
中的图像采用下采样获取LR集合![]() ,对于
,对于![]() 中的图像采用SR-GAN网络获取HR集合
中的图像采用SR-GAN网络获取HR集合![]() 。
。
第③步:作者认为三元组损失容易受到分辨率差异的影响,而提出的CCL旨在评估图像之间的距离同时不被分辨率差异影响。LCC损失具体为:
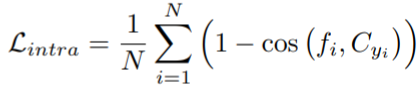
![]()
![]()
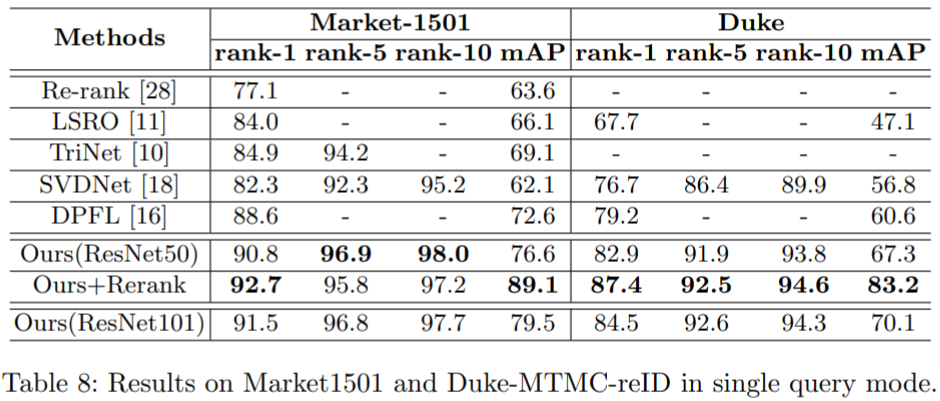
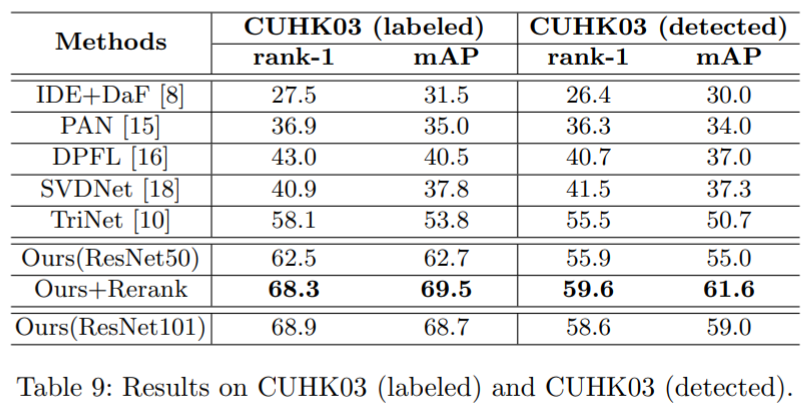
实验结果:
Cascaded SR-GAN for Scale-Adaptive Low Resolution Person Re-identification【IJCAI2018】
作者针对低分辨率reid问题提出了Cascaded Super-Resolution GAN(CSR-GAN)方法。具体贡献如下:① 级联了多个SR-GAN,上采样率可以实现尺度的适应;② 提出的CSR-GAN提高了尺度适应SR和reid的集成能力,同时增强了SR处理后LR-HR之间的相似度;③ 设计了一个common-human损失,让生成的图像更接近行人;设计了一个unique-human损失,让行人图像的特征更加有判别力。网络结构图如下:
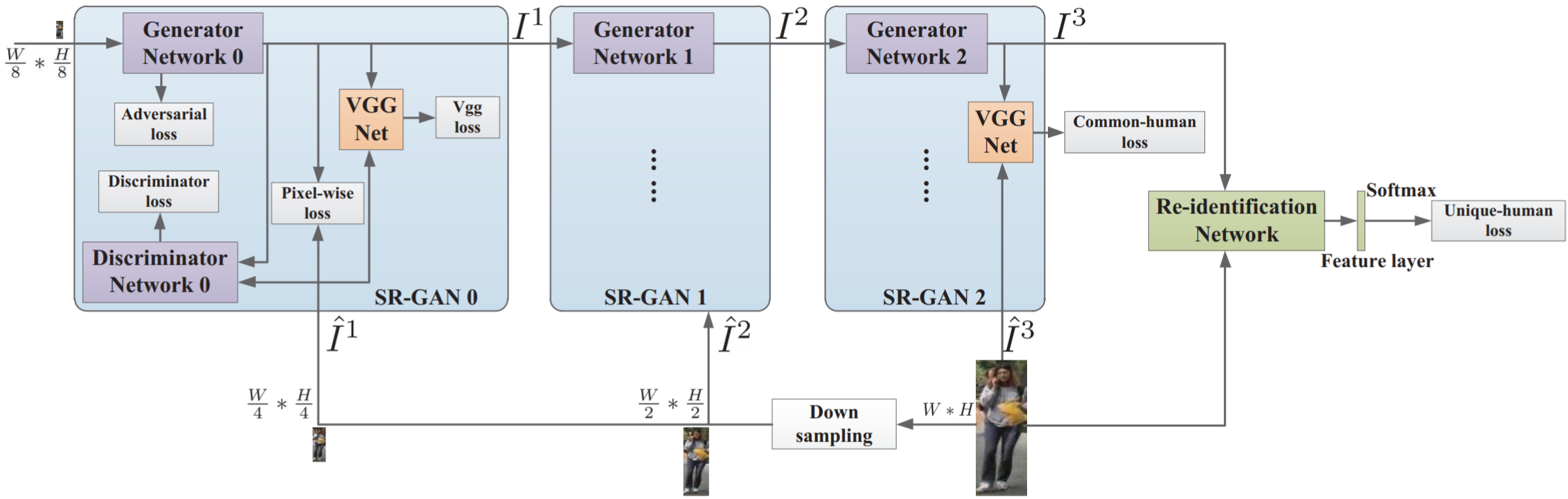
图上可知,CSR-GAN网络框架包含了3个SR-GAN模块。定义![]() 为第k个生成器
为第k个生成器![]() 输出的图像,即
输出的图像,即![]() ,
,![]() 。定义
。定义![]() 为真实图像,尺度与
为真实图像,尺度与![]() 相同。
相同。![]() 为下采样率,依次取值1/8,1/4,1/2,1。
为下采样率,依次取值1/8,1/4,1/2,1。
generator的损失函数如下:
① 像素级MSE损失:
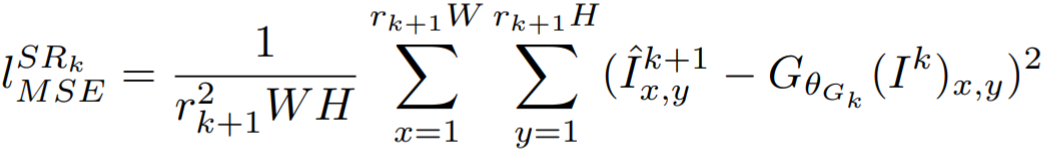
② VGG损失(采用了19层的VGG网络,其中![]() 表示第 i 层最大池化前的第 j 层卷积的特征映射):
表示第 i 层最大池化前的第 j 层卷积的特征映射):
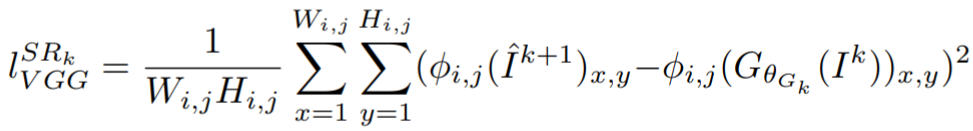
③ 对抗损失(其中![]() 为生成的超分图像为real的概率,希望生成real的概率越大,这里损失的值就越小,原对抗损失应该为
为生成的超分图像为real的概率,希望生成real的概率越大,这里损失的值就越小,原对抗损失应该为![]() ,为了方便计算梯度才改为如下形式):
,为了方便计算梯度才改为如下形式):
![]()
discriminator的损失函数如下:
![]()
common-human损失函数如下(为了让第三个模块输出的行人分类结果与原始的行人分类结果尽量一致):
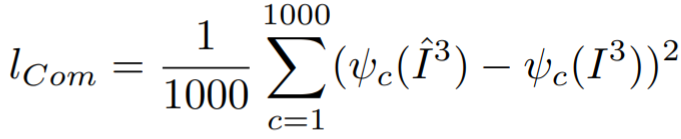
其中![]() 为行人图像判断为c类的概率。
为行人图像判断为c类的概率。
unique-human损失函数如下(交叉熵):
![]()
其中m为行人ID数量,p为分为每个ID的概率,q为行人ID和判断ID的一致性,即0或1。
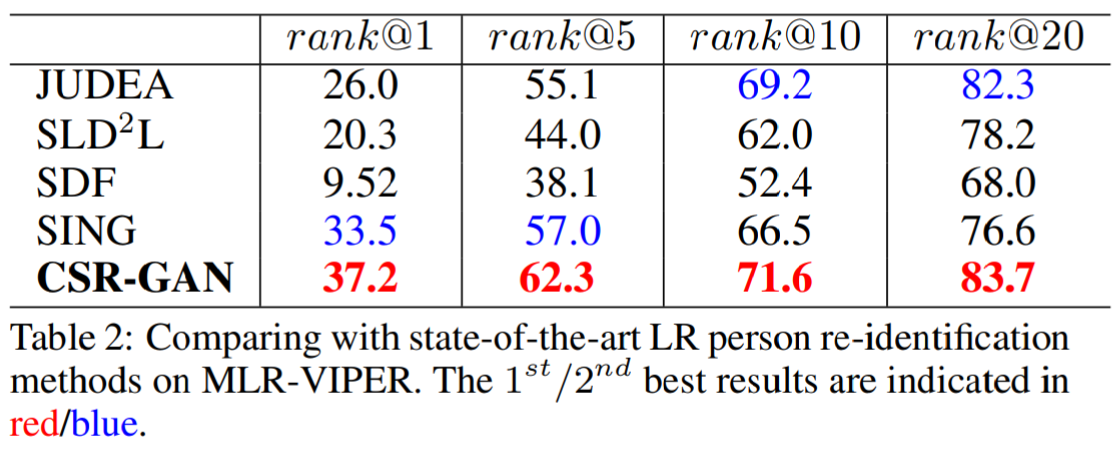
实验采用了3个数据集进行评估:SALR-VIPeR、SALR-PRID、CAVIAR,其中前两个为基于VIPeR和PRID生成的数据集。实验结果如下:
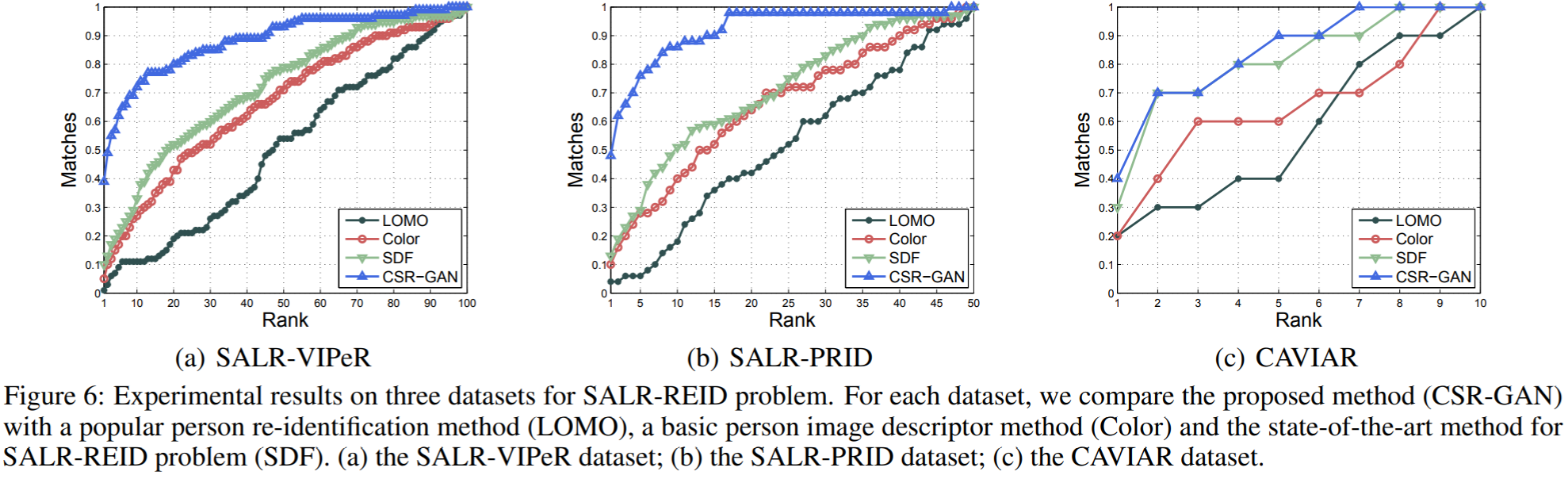
Learning Resolution-Invariant Deep Representations for Person Re-Identification【AAAI2019】
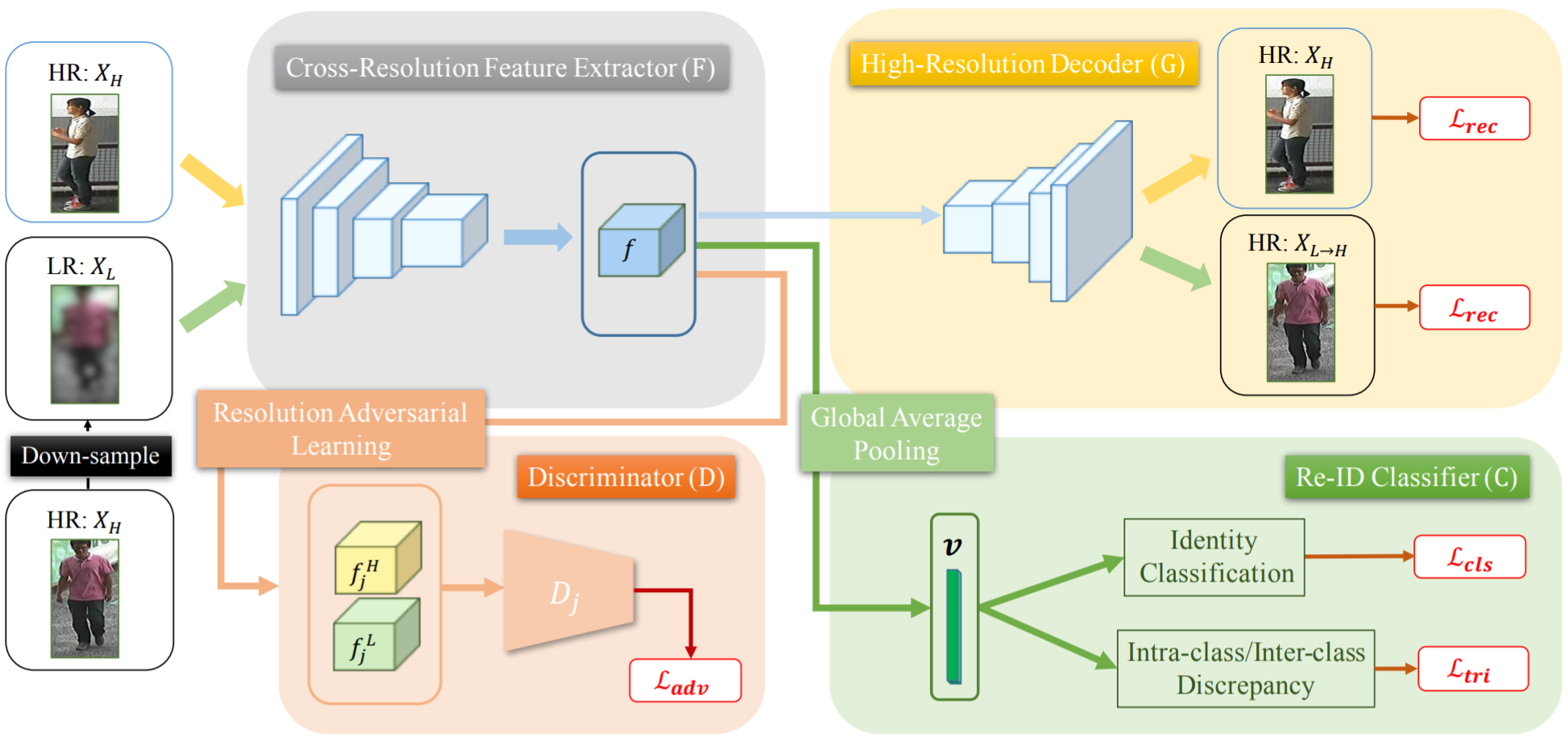
为了提取适应分辨率的特征,作者提出了一个Resolution Adaptation and re-Identification Network(RAIN),如下图所示:
定义:HR图像集合![]() ,对应标签集合
,对应标签集合![]() ,下采样得到的LR图像集合
,下采样得到的LR图像集合![]() 。
。
Cross-resolution feature extractor:输入HR、LR图像,通过Resnet50提取得到特征映射,Resnet50的5层的残差块输出分别为![]() ,引入了对抗损失:
,引入了对抗损失:
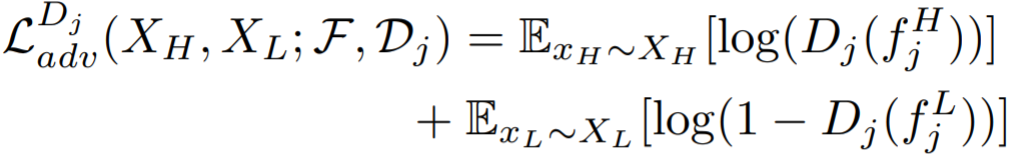
High-resolution decoder:编码器可以将提取到的特征恢复到HR图像,定义重构损失为:
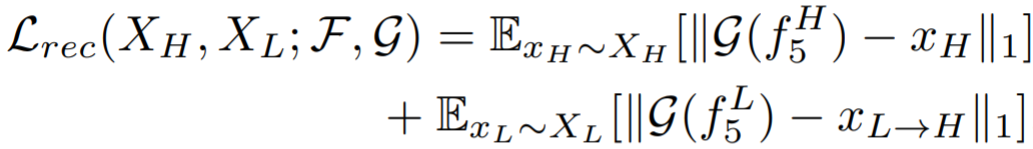
ReID classifier:先对输出的特征采用全局平均池化,得到特征映射![]() ,在采用交叉熵损失和三元组损失:
,在采用交叉熵损失和三元组损失:
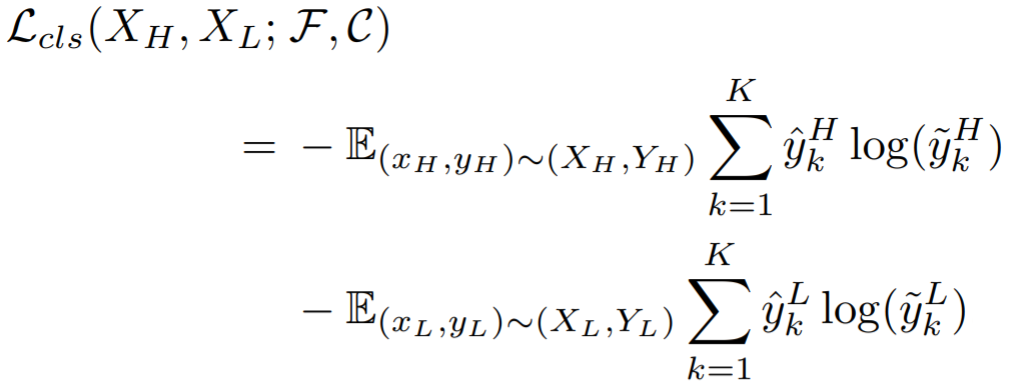
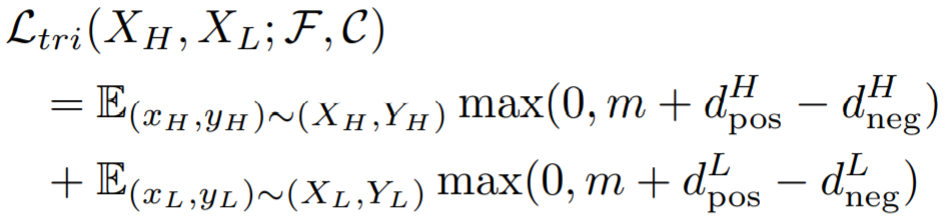
最终累加为目标函数:
![]()
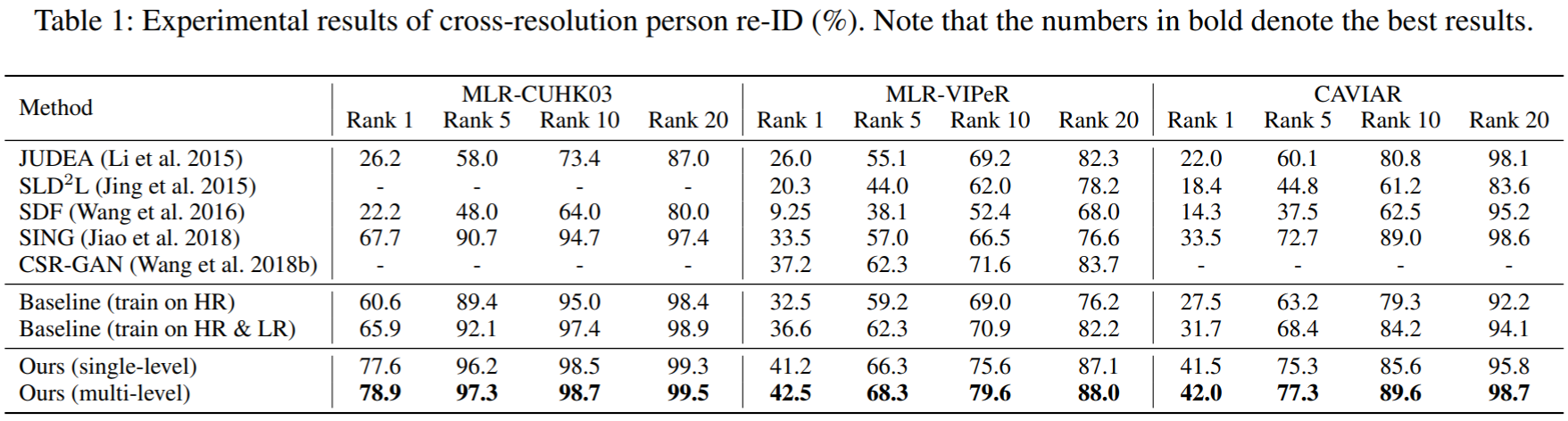
实验结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号