论文阅读笔记(五十一)高低分辨率行人重识别 (Part 1)
Super-resolution Person Re-identification with Semi-coupled Low-rank Discriminant Dictionary Learning 【CVPR2015】
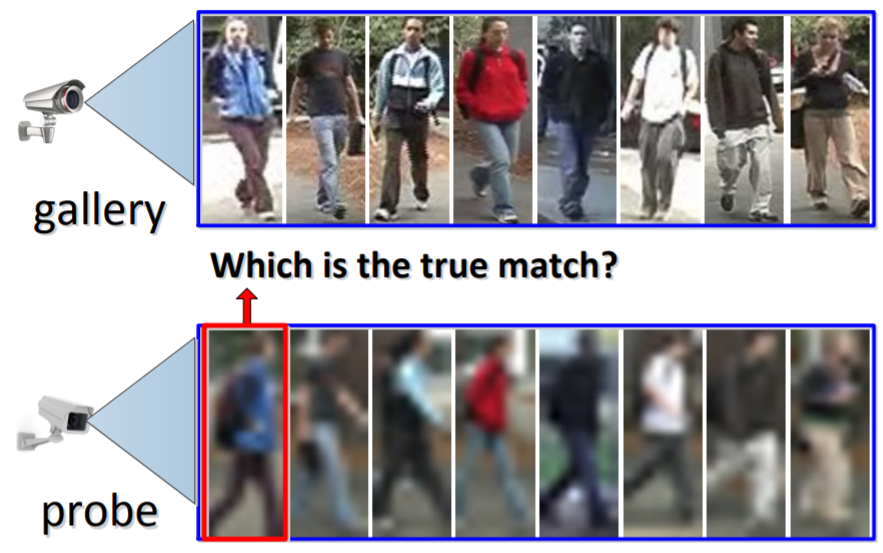
问题背景:gallery为高分辨率,probe为低分辨率。
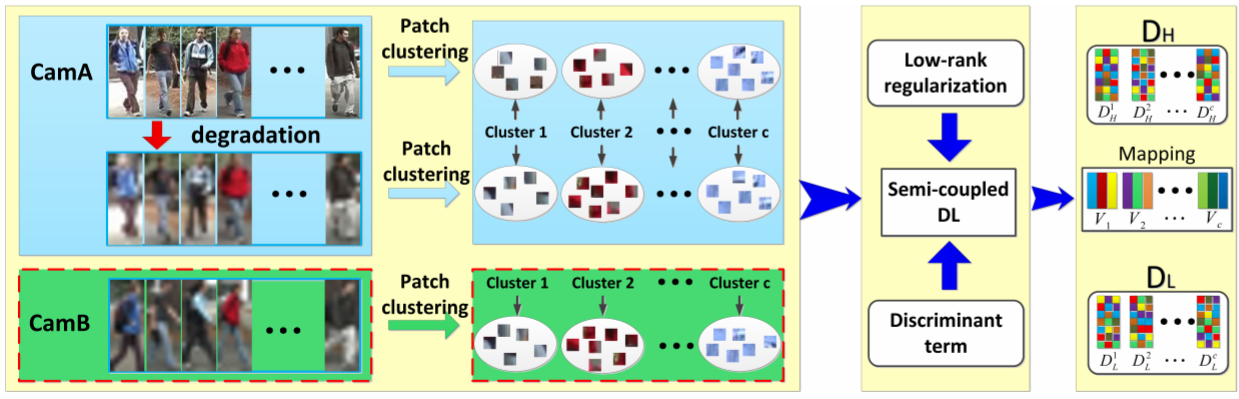
本文提出了Semi-Coupled Dictionary Learning(SCDL)方法,具体如下:
假定HR图像来自于![]() ,LR图像来自于
,LR图像来自于![]() ,通过对
,通过对![]() 进行下采样为LR图像记为
进行下采样为LR图像记为![]() 。将来自于
。将来自于![]() 和
和![]() 的LR图像分割为多个patch,根据patch特征之间的相似性采用K-means聚类,将
的LR图像分割为多个patch,根据patch特征之间的相似性采用K-means聚类,将![]() 的聚类结果复刻到
的聚类结果复刻到![]() 的HR图像中。定义HR、LR的第 i 个子字典分别为
的HR图像中。定义HR、LR的第 i 个子字典分别为![]() 和
和![]() ,每个聚类的子字典拥有表征聚类内的patch,但对其它聚类的patch表征能力较差。第 i 个聚类的映射矩阵为
,每个聚类的子字典拥有表征聚类内的patch,但对其它聚类的patch表征能力较差。第 i 个聚类的映射矩阵为![]() 。HR、LR整体的字典分别为
。HR、LR整体的字典分别为![]() 和
和![]() 。
。
注:为什么要分成小块呢?因为作者认为不同颜色的块受到分辨率的影响不一样。如果色块单一,那么分辨率不一致是没太大影响的;但如果色块细节丰富颜色众多,那么分辨率影响较大。因此对不同颜色的块需要学习不同的字典和映射。
定义patch的集合:![]() 、
、![]() 、
、![]() 分别表示
分别表示![]() 、
、![]() 、
、![]() 的patch集合,下标 i 表示其来自第 i 个聚类,
的patch集合,下标 i 表示其来自第 i 个聚类,![]() 、
、![]() 、
、![]() 表示其为
表示其为![]() 、
、![]() 、
、![]() 中第 i 个patch。
中第 i 个patch。![]() 、
、![]() 、
、![]() 分别表示
分别表示![]() 、
、![]() 、
、![]() 关于
关于![]() 的编码系数(同理,用B表示Y的编码)。
的编码系数(同理,用B表示Y的编码)。![]() 表示
表示![]() 关于
关于![]() 的编码系数。各个聚类的映射矩阵定义为
的编码系数。各个聚类的映射矩阵定义为![]()
目标函数定义:

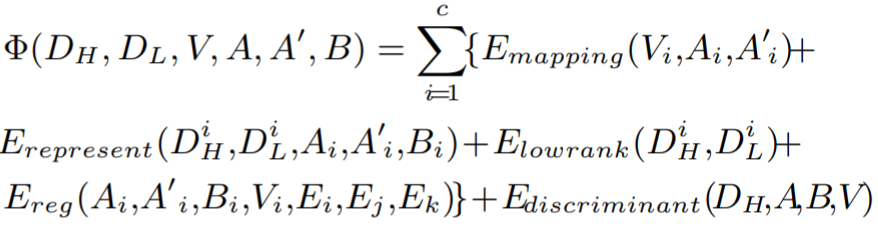
具体为:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
其中 S 和 D 分别为正负样本对,![]() ,
,![]() 。
。
优化算法分为三步:
① 固定字典对![]() 、
、![]() 和投影矩阵
和投影矩阵![]() ,更新编码系数
,更新编码系数![]() 、
、![]() 、
、![]() ;
;
② 固定编码系数![]() 、
、![]() 、
、![]() 和投影矩阵
和投影矩阵![]() ,更新字典对
,更新字典对![]() 、
、![]() ;
;
③ 固定编码系数![]() 、
、![]() 、
、![]() 和 字典对
和 字典对![]() 、
、![]() ,更新投影矩阵
,更新投影矩阵![]() 。
。

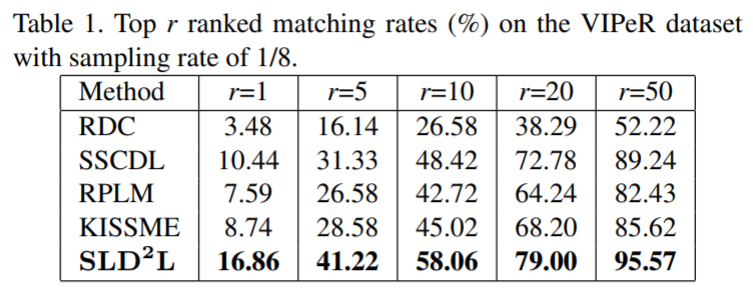
实验结果:
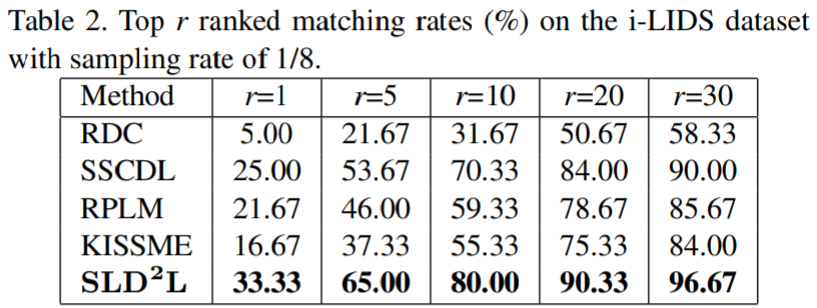
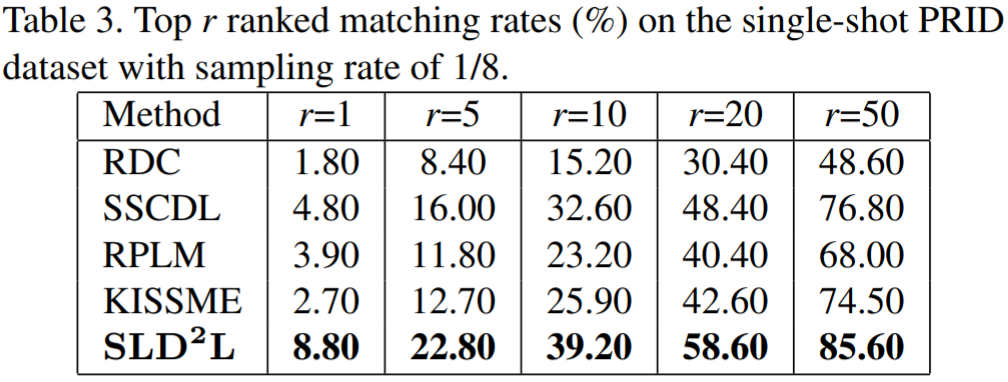
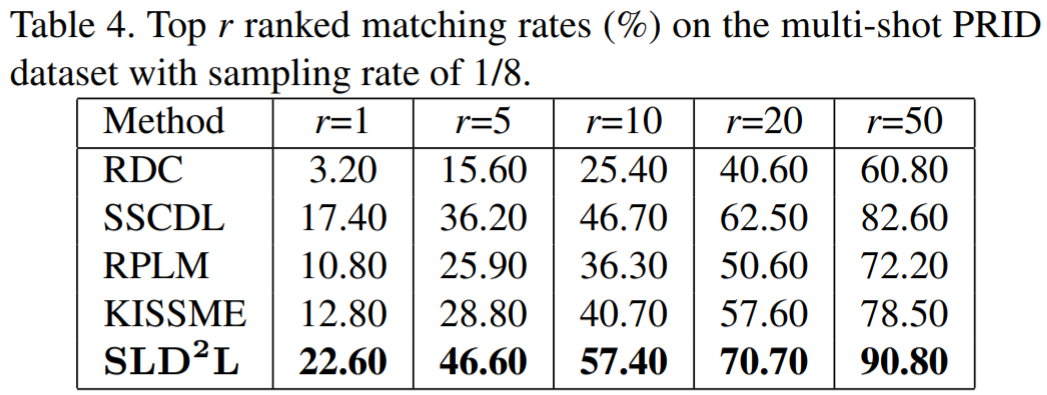
Deep Low-Resolution Person Re-Identification【AAAI2018】
本文针对高低分辨率匹配问题提出了 Super-resolution and Identity joiNt learninG (SING) 方法,同时关注行人的超分图像优化和匹配问题。本文指出了当前跨分辨率reid方法的一个问题:只是在一个预定义的特征空间进行特征转换,而不是去恢复确实的样貌信息。由此可以尝试将图像超分技术(SR)应用到reid中。然而直接将SR应用到reid中存在主次相容性的问题,也就是两个任务的目标不同,SR的目标只是改善图像的分辨率,但SR优化后的图像不一定能对reid的匹配提供帮助。SING结构如下:
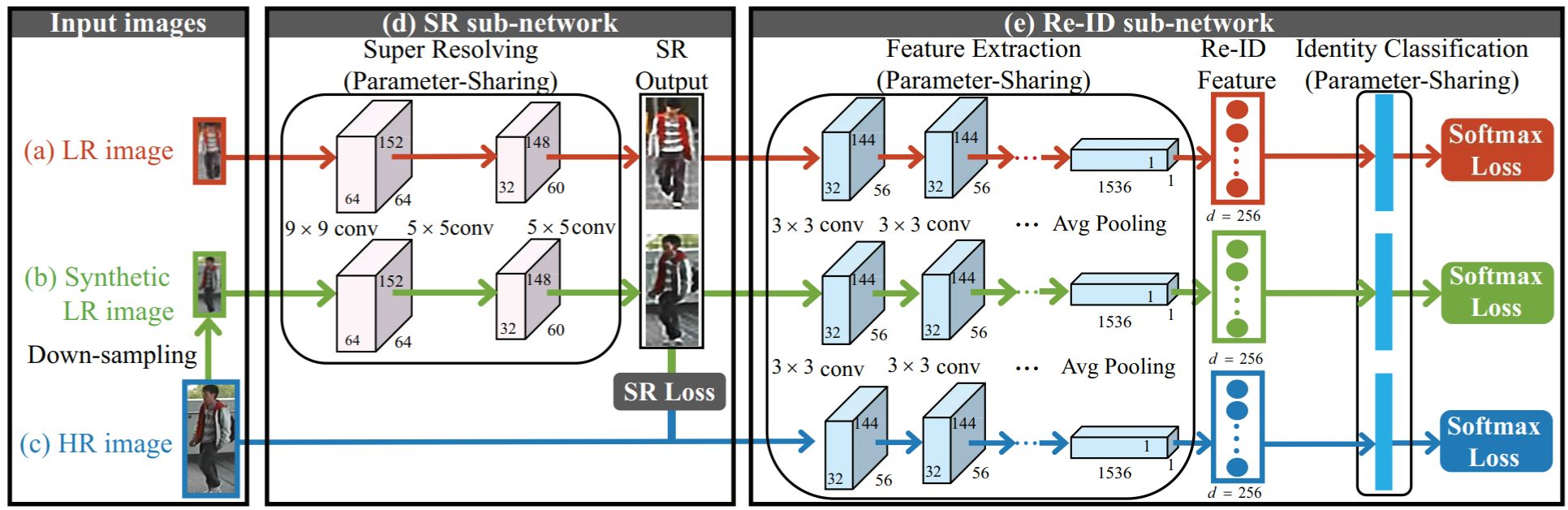
结构比较易懂,不做描述。其中SR Loss为:
![]()
SING中绿色的(b)分支承担了联接SR任务和reid任务的作用,使得网络同时学习两个任务。SR网络采用了2016年提出的SRCNN网络,即两个卷积层+ReLU+重构卷积层;Reid网络采用了2016年提出的DGD网络。
由于下采样率一致,SING CNN预设的LR图像分辨率比较相似。然而现实场景中不同图像的分辨率差异较大,为此作者采用了不同的采样率![]() 训练得到多个SING模型
训练得到多个SING模型![]() ,在度量距离时采用多分辨率融合距离,即:
,在度量距离时采用多分辨率融合距离,即:
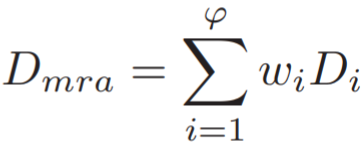
其中 w 表示权重,D 表示对应模型query与gallery的距离。为了让距离度量能够适应多种分辨率,作者评估了LR probe和HR gallery之间分辨率相似度,即:
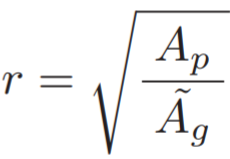
其中 ![]() 表示LR probe的空间像素,
表示LR probe的空间像素,![]() 表示所有HR gallery的平均空间像素。最终权重 w 的计算为:
表示所有HR gallery的平均空间像素。最终权重 w 的计算为:
![]()
其中![]() 为一个缩放参数。
为一个缩放参数。
可以理解为:采样率越接近LR和HR的分辨率差异,说明采样率设置的越合理,则该距离度量的权重更大。
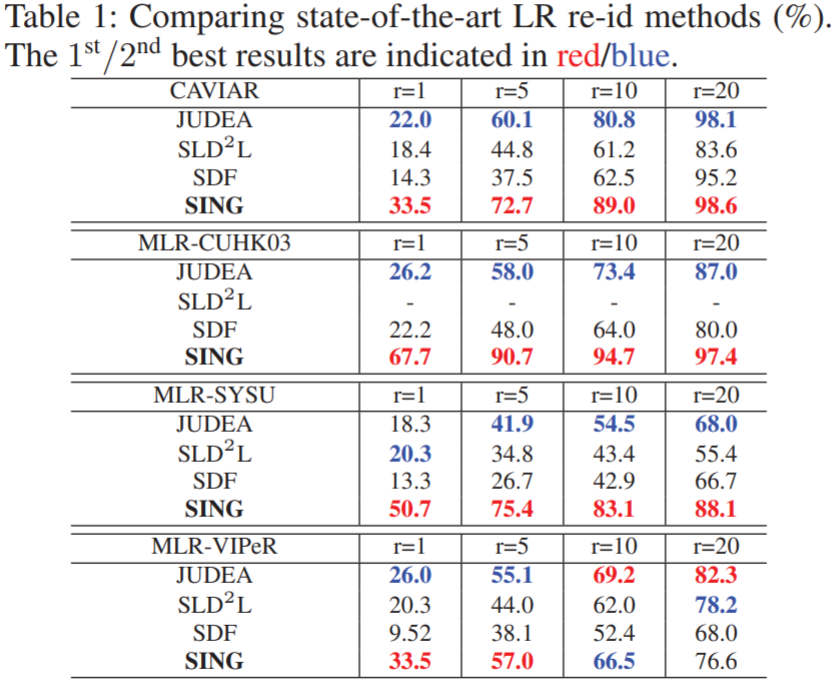
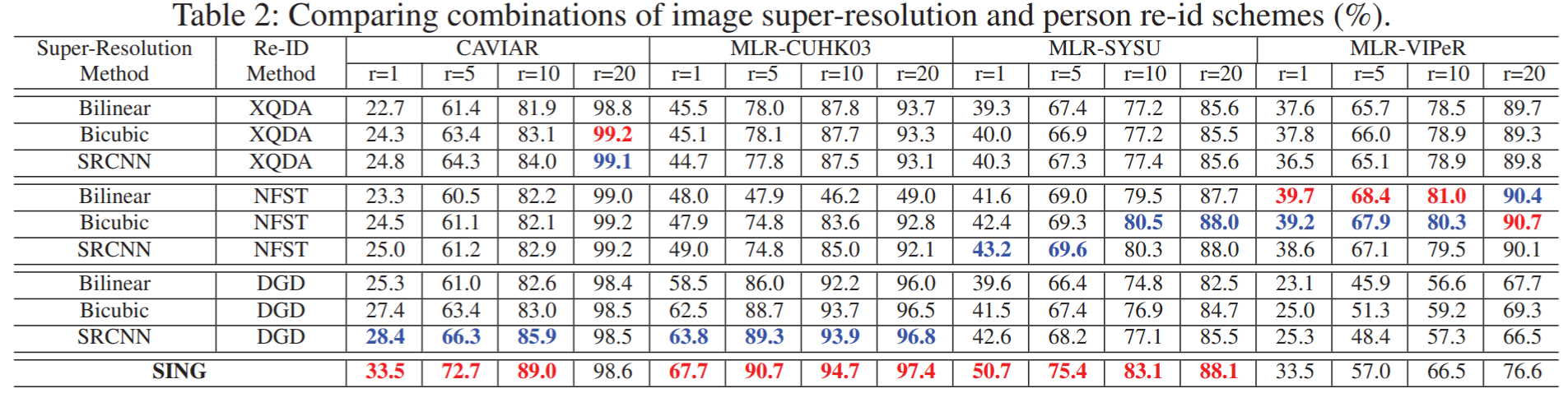
实验所用的数据集为3个模拟和1个真实的LR reid数据集。具体为:① MLR-VIPeR:由VIPeR生成,每张HR图像分辨率设置为128*48,其中一个摄像头改为LR图像,采样率设置为 {1/2, 1/3, 1/4 };② MLR-SYSU:由SYSU生成,包含2个摄像头,其中一个改为LR;③ MLR-CUHK03:由CUHK03生成,包含5个不同的摄像头对,对于每对摄像头,选取一个作为LR图像;④ CAVIAR:真实场景的高低分辨率reid数据集,包含了两个有距离差异的摄像头,其中一个为LR,另一个为HR,不需要额外设置采样率。实验结果如下:
Resolution-invariant Person Re-Identification【IJCAI2019】
本文提出了一个 Foreground-Focus Super-Resolution (FFSR) module 和 Resolution-Invariant Feature Extractor (RIFE)。前者通过采用了一个卷积自编码器来upscale行人的前景信息,后者针对高低分辨率采用了双分支特征提取结构,应用了双重注意力模块来提取特征。作者认为先前采用SR解决高低分辨率reid存在一个问题:对于行人的图像,不管是行人还是背景都被无差别地提高了分辨率。作者的FFSR与之前的SR方法不同,FFSR在训练时联合了ReID损失和前景注意力损失,在恢复行人分辨率的同时,抑制无关背景。
问题定义:行人图片为![]() ,其中
,其中 ![]() 为分辨率参数,计算为:
为分辨率参数,计算为:![]() ,即该图片的宽度与数据集中所有图片的最大宽度的比值。解决的目标问题是拉近相同ID的特征距离,拉大不同ID的特征距离,即:
,即该图片的宽度与数据集中所有图片的最大宽度的比值。解决的目标问题是拉近相同ID的特征距离,拉大不同ID的特征距离,即:
![]()
作者验证了分辨率对Reid效果的影响,如下图:
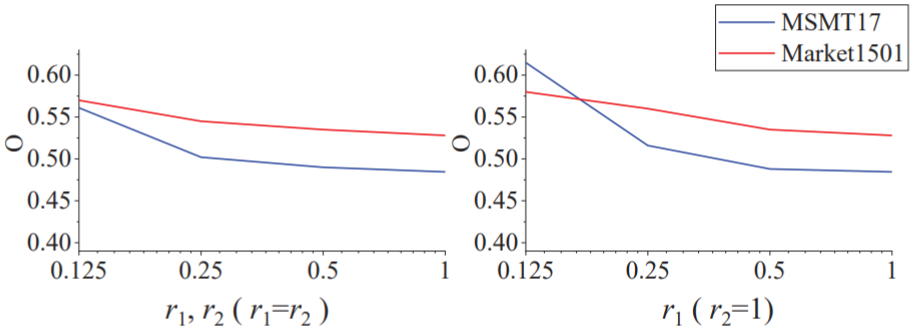
对于高低分辨率,作者提出的FFSR改善了LR的分辨率,RIFT提取出了适应分辨率的特征,即:
![]()
网络结构如下图:
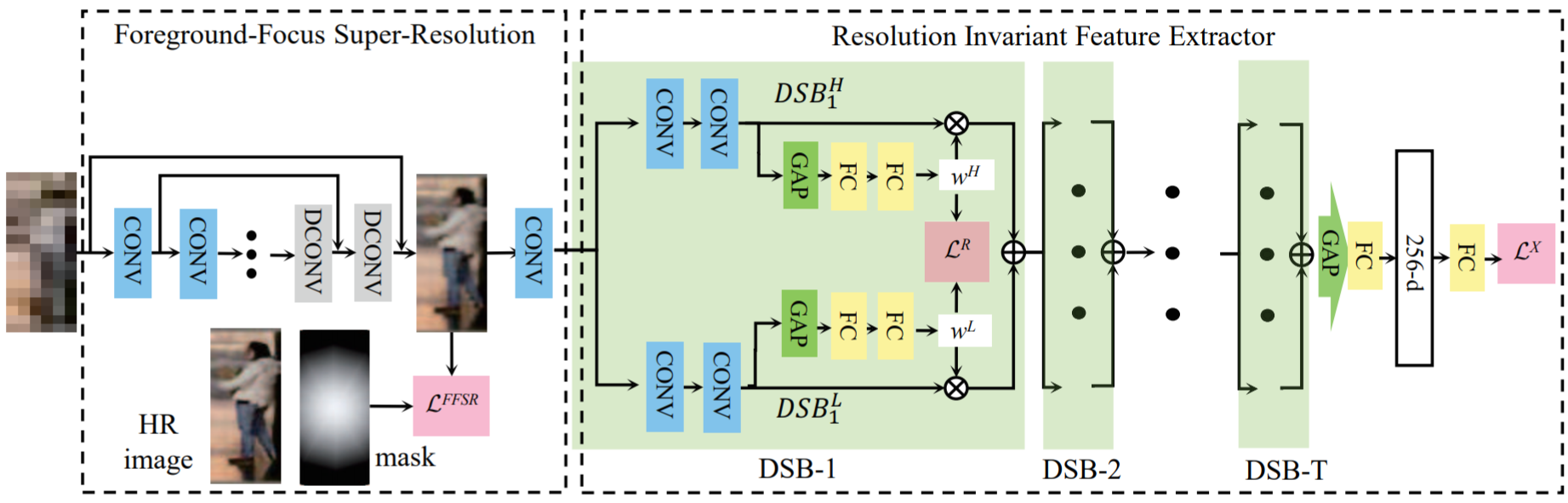
FFSR模块:FFSR的结构基于一个自编码器,先对图像进行stride=2的卷积来下采样,再进行stride=1的卷积来提取特征。在反卷积阶段采用RED-net (2016提出) 中的symmetric skip connection (跳层结构),保留了原始图像中的细节,增强了重构图像。LR重构的图像与HR图像的像素损失为:
![]()
其中![]() 为每个元素的相乘,M 为前景mask。M 的生成可以用语义分割算法,但对于标准的行人检测框,行人一般处在图像的中央,为了简化采用了Gaussian kernel作为前景mask。
为每个元素的相乘,M 为前景mask。M 的生成可以用语义分割算法,但对于标准的行人检测框,行人一般处在图像的中央,为了简化采用了Gaussian kernel作为前景mask。
RIFE模块:FFSR模块还不足以做到分辨率的适应,因此还需要采用RIFE模块进一步对特征提取做优化。由于高低分辨率图像的细节存在差异,对于两类图像需要采用不同的特征提取器。RIFE模块由多个Dual-Stream Block (DSB)组成。对于每个DSB,双分支分别提取得到特征映射![]() 和
和![]() ,如果输入的图像像素高,那么HR分支的权重更大,反之LR分支的权重更大,最终输出的特征为:
,如果输入的图像像素高,那么HR分支的权重更大,反之LR分支的权重更大,最终输出的特征为:
![]()
其损失函数定义为(损失的含义也就是分辨率 r 越大,![]() 越大,两者数值应该接近):
越大,两者数值应该接近):
![]()
最终通过 GAP 和 FC,得到的特征向量采用交叉熵损失。
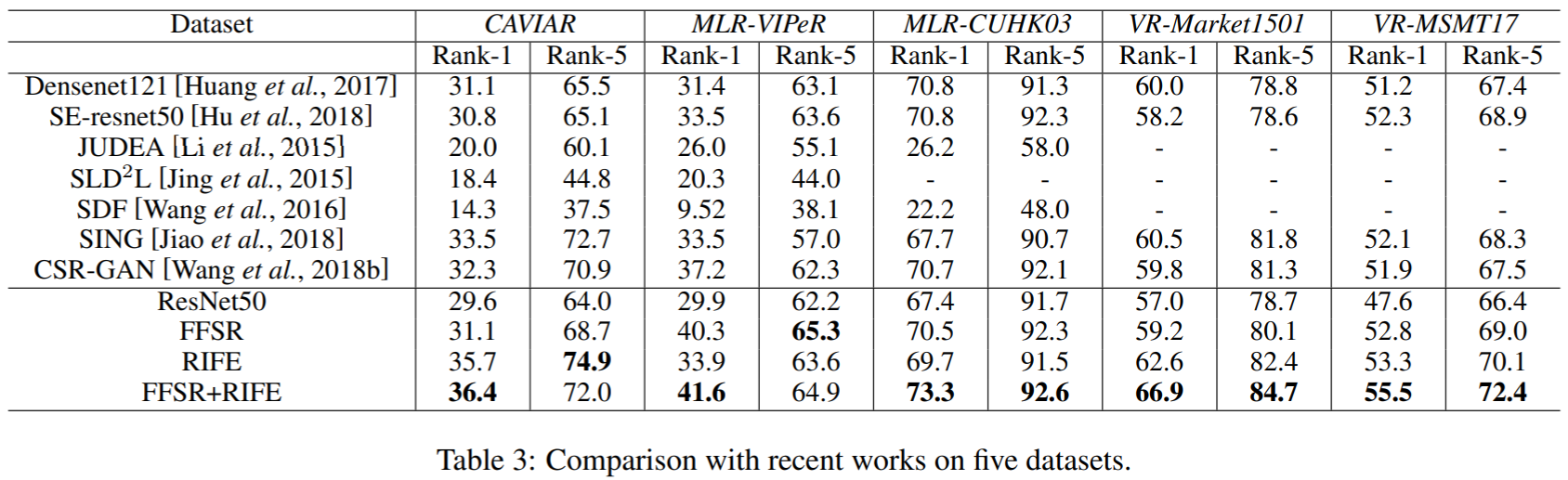
实验对CAVIAR、MLR-VIPeR、MLR-CUHK03、VR-Market1501、VR-MSMT17进行测试,前三个数据集上面已经介绍,VR-Market1501将图像下采样到宽度为[8,32),VR-MSMT17将图像下采样到宽度为[32,128)。实验结果如下:
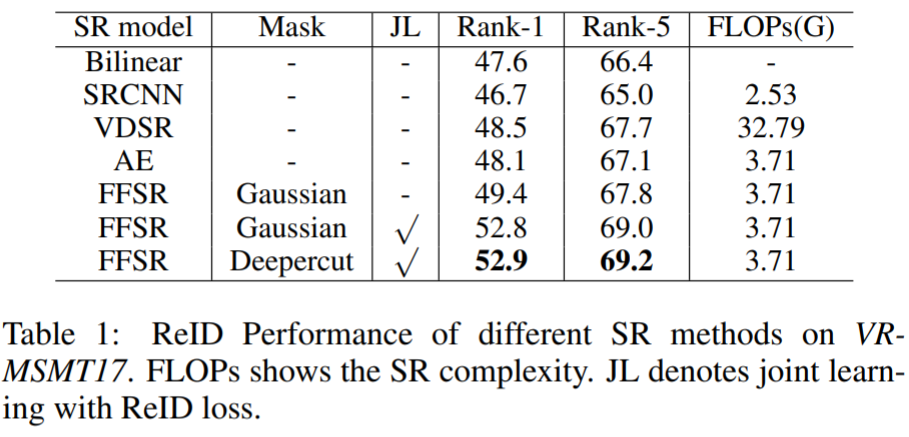
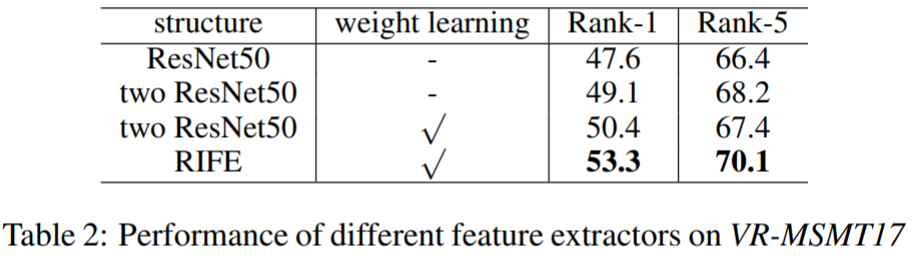
Recover and Identify: A Generative Dual Model for Cross-Resolution Person Re-Identification【ICCV2019】
作者指出之前的LR-HR匹配方法的不足之处:① 采用超分辨率的方法来提升分辨率,但需要SR模型预先定义LR的分辨率;② 真实环境下,query的LR图像分辨率是不确定的。
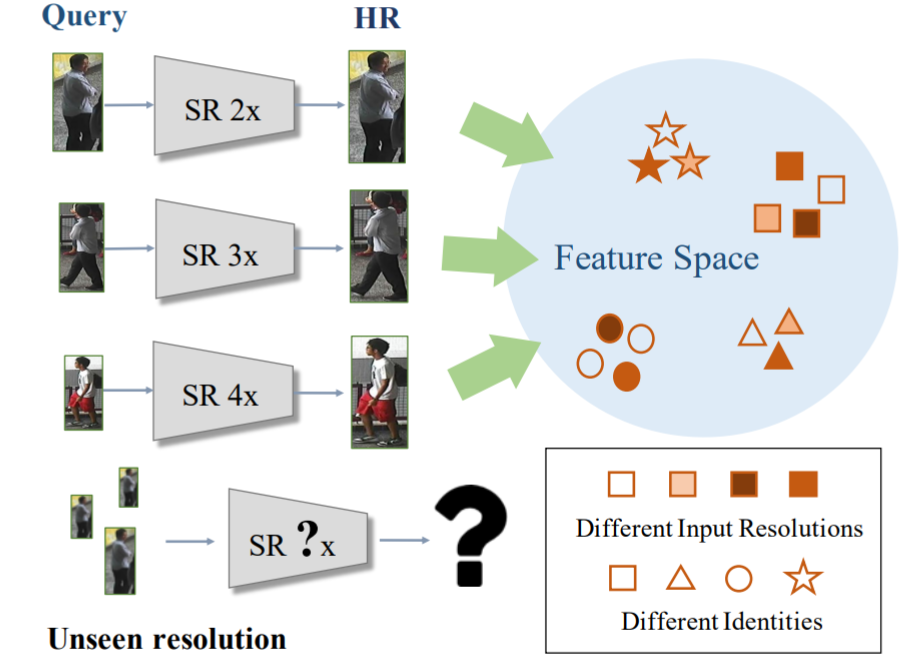
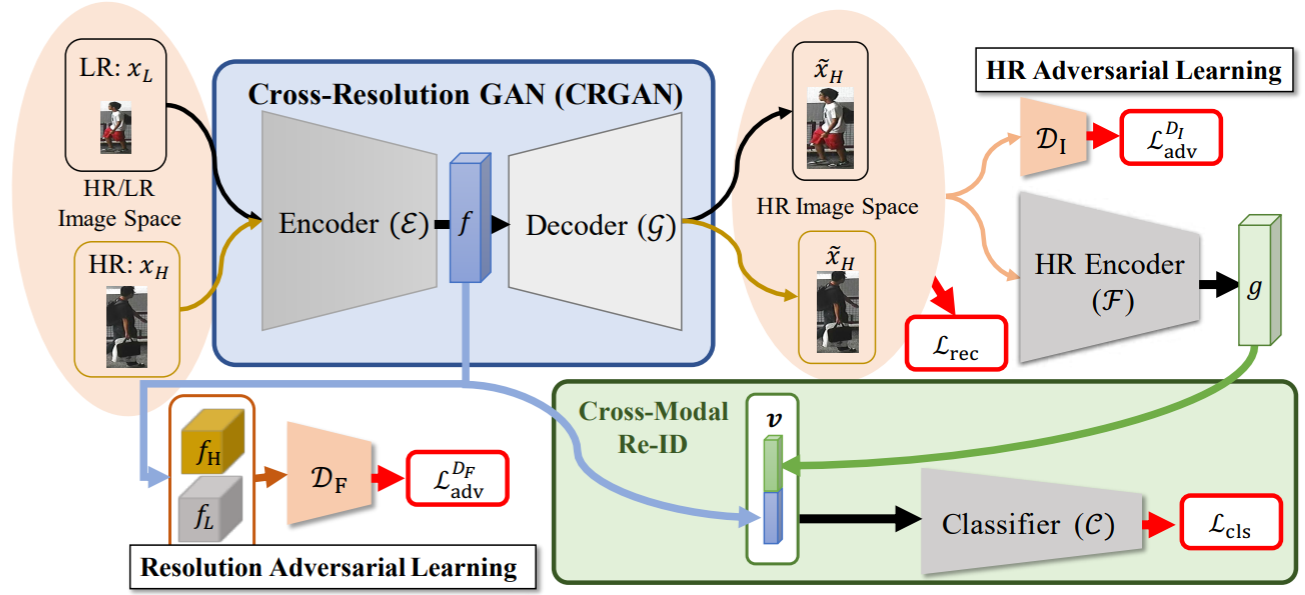
为此作者提出了Cross-resolution Adversarial Dual Network (CAD-Net)。首先采用对抗学习的思想实现分辨率适应表征,再学习恢复LR的丢失细节。其网络结构图如下:
定义:HR图像集合![]() ,对应标签集合
,对应标签集合![]()
![]() ,通过降采样获得的LR图像集合
,通过降采样获得的LR图像集合![]() 。网络的结构包含两个主要模块:Cross-Resolution Generative Adversarial Network (CRGAN) 和 Cross-Model ReID network。CRGAN模块可以学习得到一个分辨率适应的特征
。网络的结构包含两个主要模块:Cross-Resolution Generative Adversarial Network (CRGAN) 和 Cross-Model ReID network。CRGAN模块可以学习得到一个分辨率适应的特征![]() ,decoder后得到的HR图像作为新的encoder的输入,得到HR特征
,decoder后得到的HR图像作为新的encoder的输入,得到HR特征![]() 。最终输出的特征为两个特征级联
。最终输出的特征为两个特征级联![]() 再通过GAP压缩到通道维度。
再通过GAP压缩到通道维度。
CRGAN包含了一个encoder ![]() 和一个decoder
和一个decoder ![]() 。为了让encoder能够适应不同分辨率,作者提出了对抗学习策略和一个分辨率判别器
。为了让encoder能够适应不同分辨率,作者提出了对抗学习策略和一个分辨率判别器![]() ,对抗损失为:
,对抗损失为:
![]()
其中![]() ,
,![]() 。为了弥补LR图像损失的细节,采用了一个high-resolution decoder重构了HR图像,重构损失为:
。为了弥补LR图像损失的细节,采用了一个high-resolution decoder重构了HR图像,重构损失为:
![]()
为了激励HR decoder能够获取更加真实的HR图像,再次采用了对抗学习的方法,引入了HR图像判别器![]() ,用来判别decoder得到的图像是real的HR图像还是fake的HR图像,对抗损失为:
,用来判别decoder得到的图像是real的HR图像还是fake的HR图像,对抗损失为:
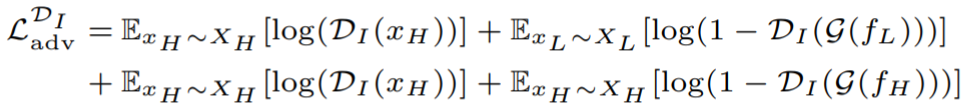
将重构的HR图像输入到一个encoder中提取得到HR特征![]() 。
。
最终用于判别的损失函数包含了三元组损失和ID损失。
实验结果(数据集设置参照SING):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号