论文阅读笔记(四十八)【CVPR2019】:Attribute-Driven Feature Disentangling and Temporal Aggregation for Video Person Re-Identification
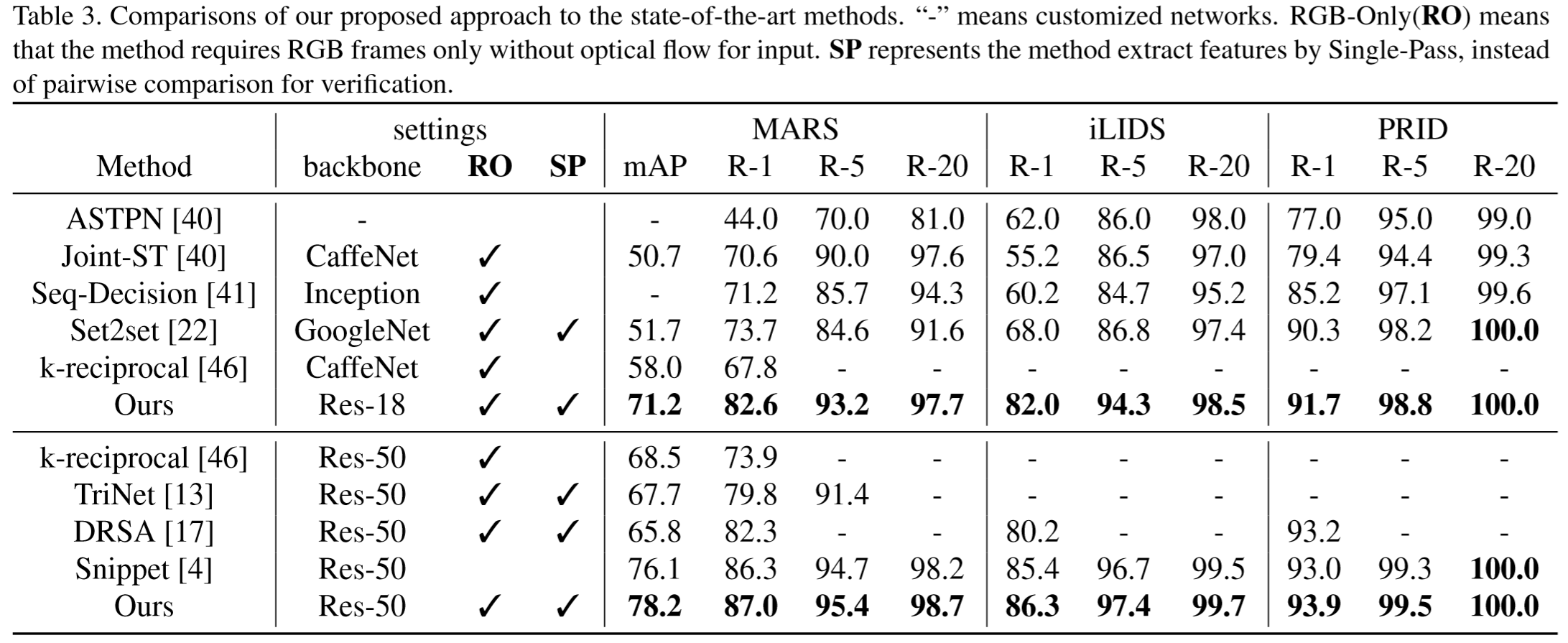
本文提出的方法思想是利用属性信息来挖掘各个局部特征的权重,如下图所示。
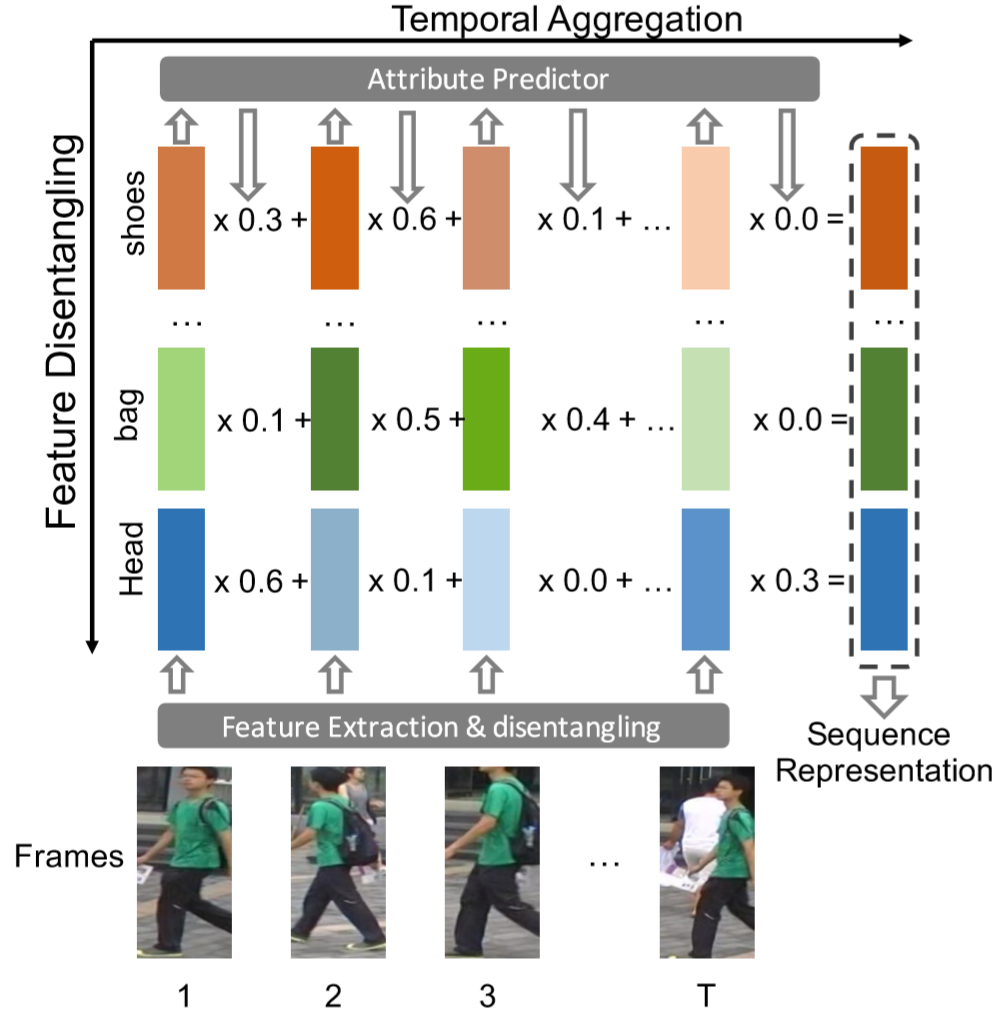
网络框架如下图。框架对人体的六组属性进行了区分:性别&年龄、头部、上半身、下半身、鞋子、背包拎包等,具体见下表。通过Resnet提取出全局的特征,通过全连接层得到6+1个特征划分,通过RAP静态行人属性数据库进行迁移学习,得到属性的判别器。特征融合的过程中采用时间注意力,对每个帧的各个属性计算置信值,再进行加权融合。最终的特征采用6+1个特征级联。
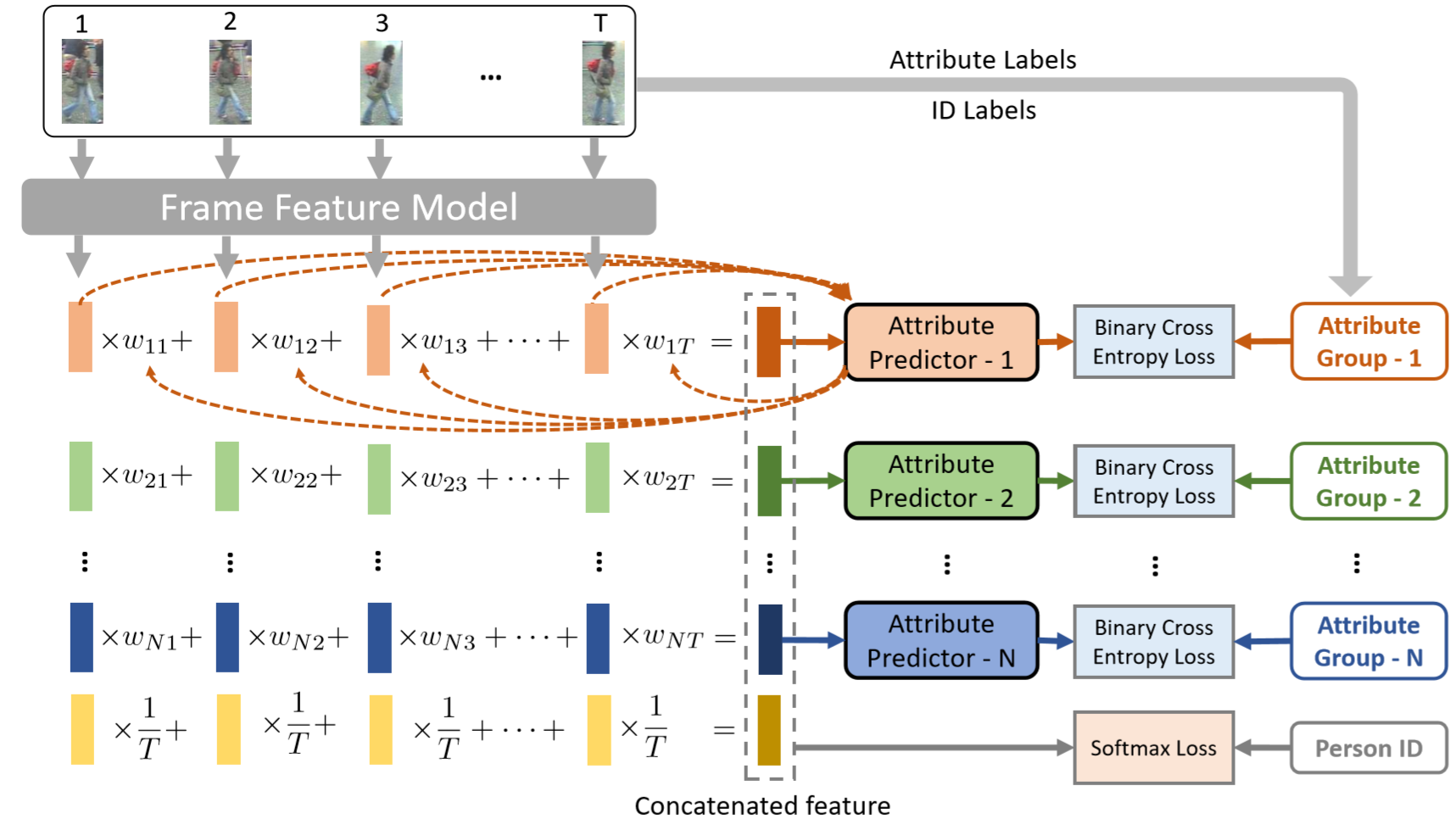

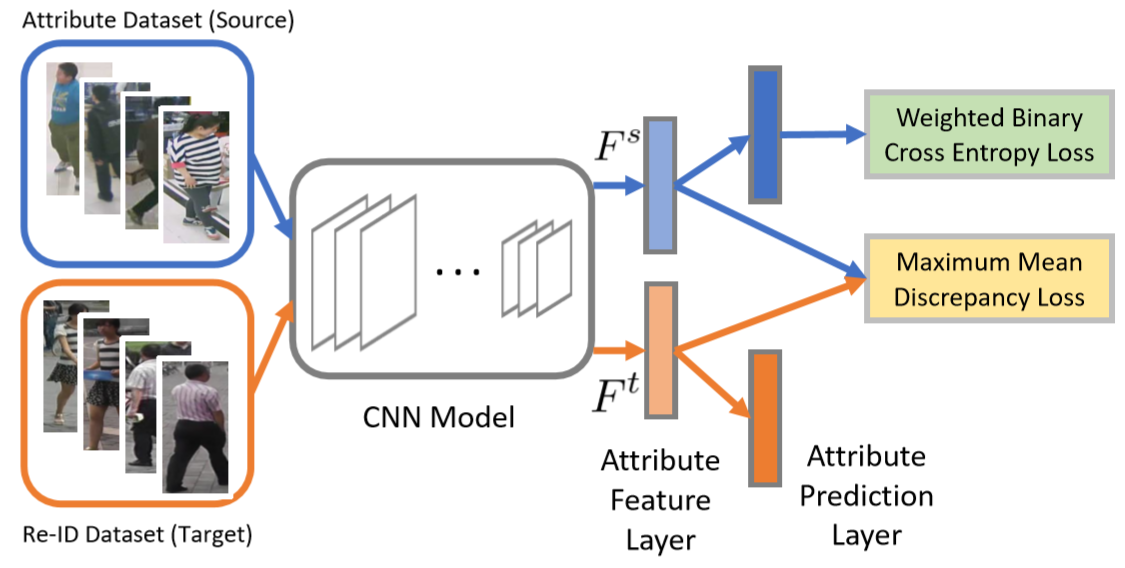
其中迁移学习获得属性label的过程如下图。利用Maximum Mean Discrepancy (MMD)来训练两个数据集之间的feature分布【传送门】。这里的MMD损失为:
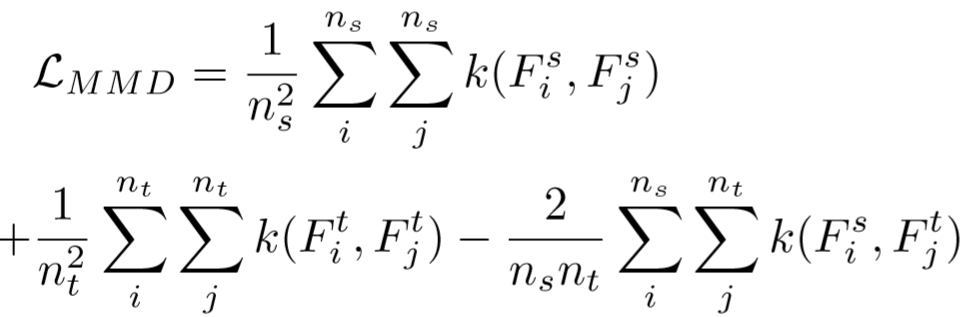
其中 k 为:![]()
实验结果如下: