论文阅读笔记(四十三)【AAAI2020】:Rethinking Temporal Fusion for Video-based Person Re-identificationon Semantic and Time Aspect
Introduction
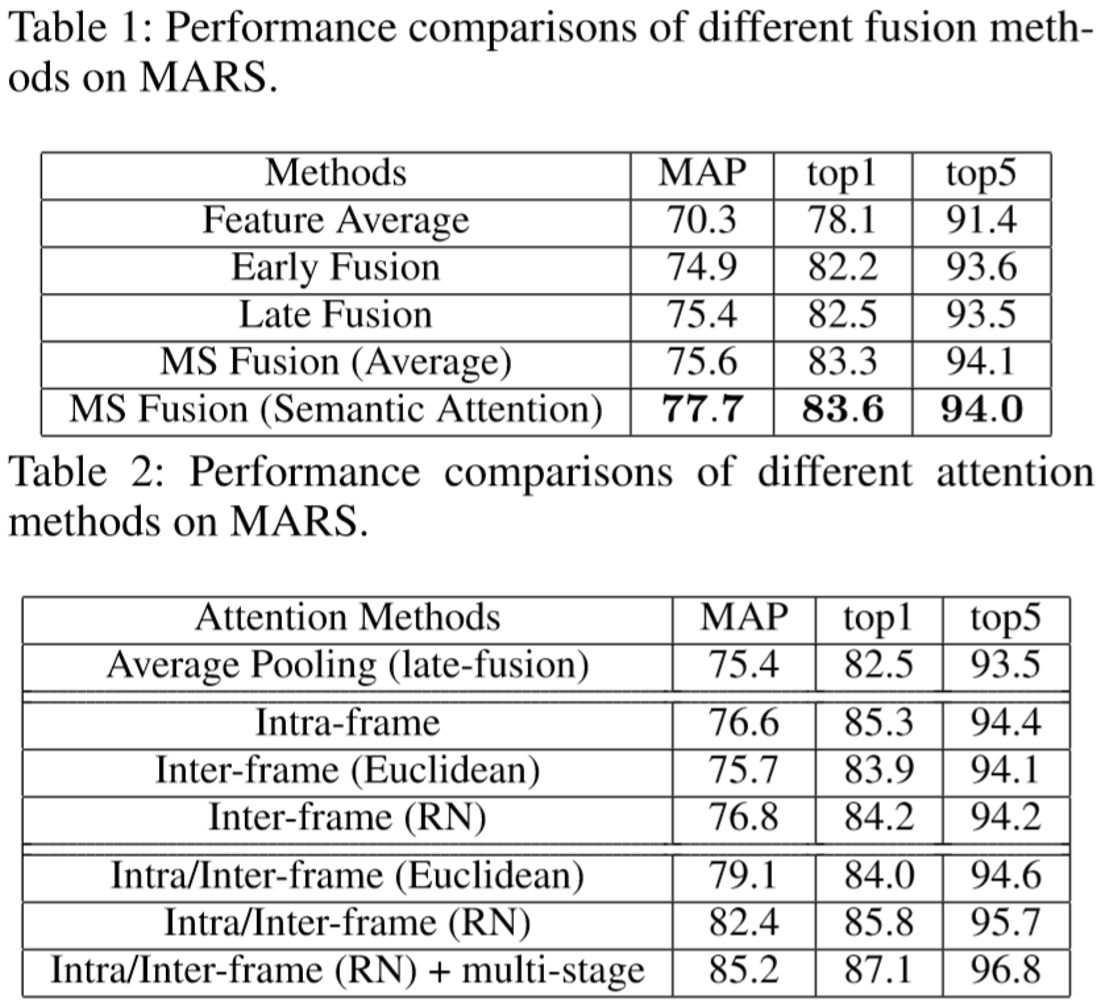
作者认为之前提出的网络忽视了不同阶段的特征差异,新提出了一个同时考虑时间、语义信息的网络框架。在时间维度采用了注意力机制,之前的方法都是将每一帧看成独立的个体提取注意力得分,但作者考虑了帧与帧之间的关系信息;在语义维度采用了CNN多层特征融合的策略

Methods
(1)概述:
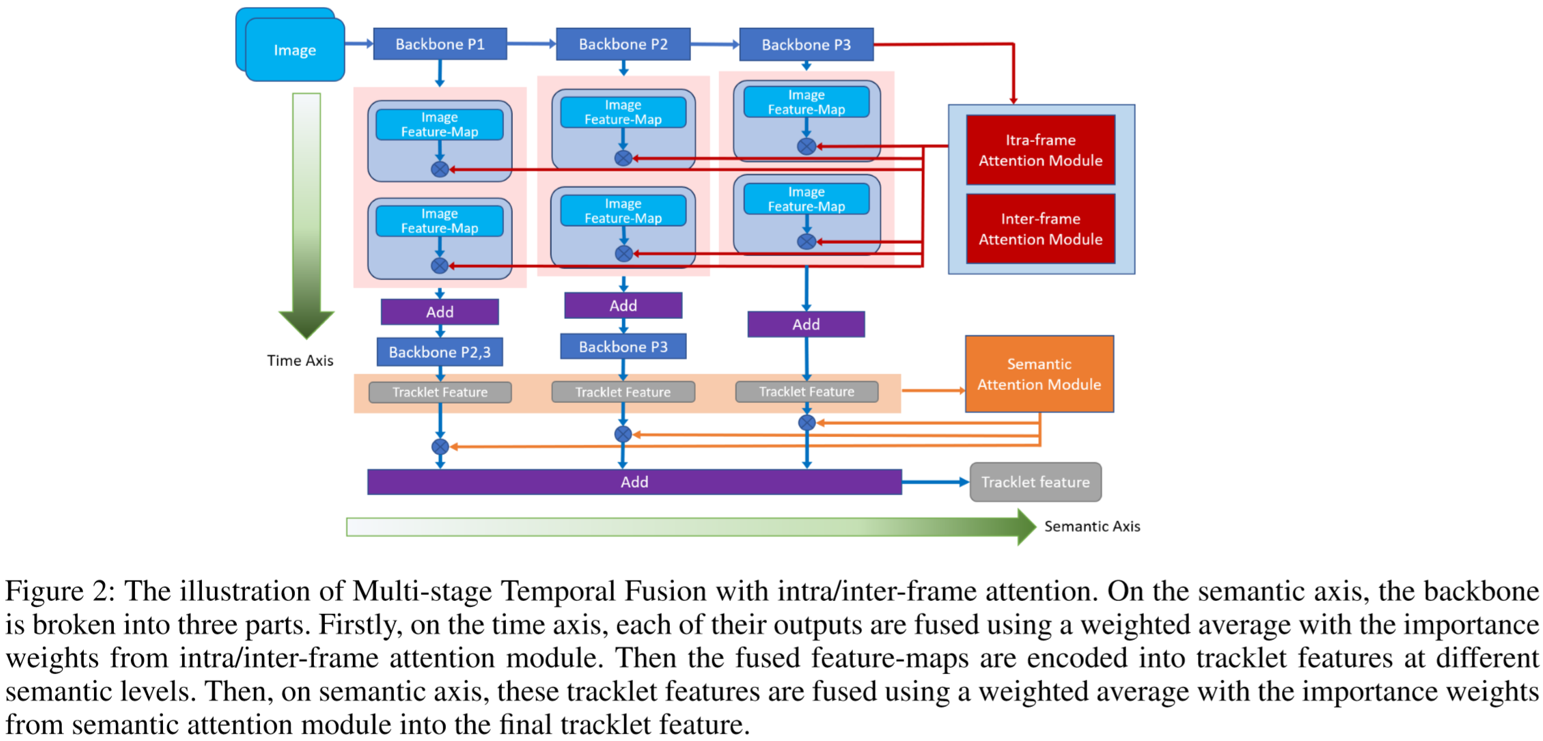
(2)时间维度:Intra/Inter-Frame Attention:
为了降低帧之间的冗余信息,并把注意力集中到重要的帧上,提出了帧内/帧间注意力机制。给定L帧图像,提取得到的视频特征向量为![]() ,计算方法为:
,计算方法为:
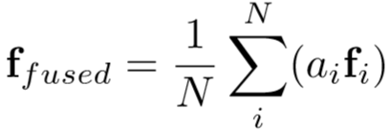
权重的计算为:
![]()
其中w表示帧内注意力权重,v表示帧间注意力权重。
① 帧内注意力权重:
大部分现有的注意力计算方法是基于该帧自身的质量和内容,这种注意力机制称为帧内注意力权重。假定视频包含L帧,通过骨干网络提取得到第i帧的特征为![]() ,通过二元回归器得到权重为:
,通过二元回归器得到权重为:
![]()
② 帧间注意力权重:
为了关注更有判别力的特征,降低冗余,包含相似视觉信息的帧应该被分配到更低的注意力权重。因此,帧的权重也要考虑到与其它帧的关系度和差异性,这种注意力机制称为帧间注意力权重。
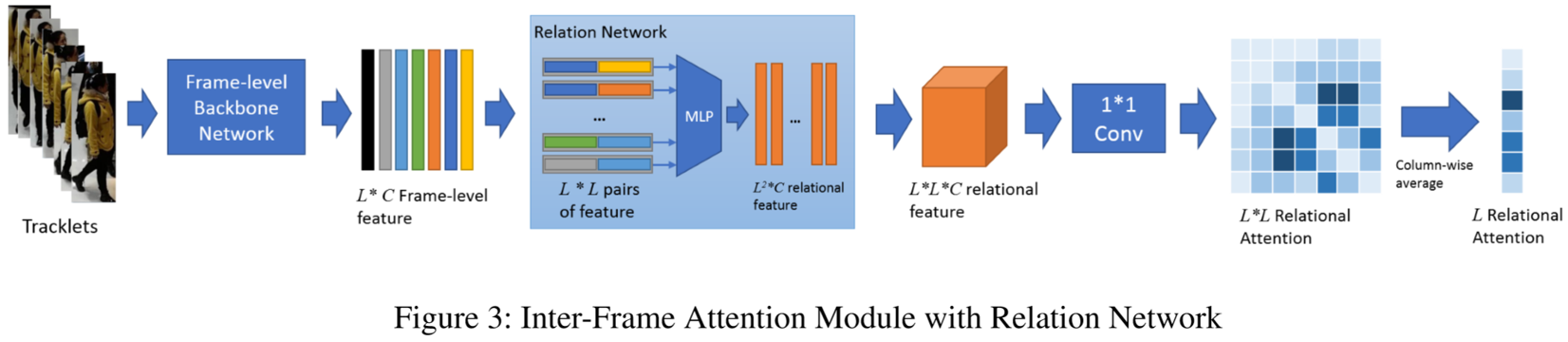
上图为作者提出的基于帧间注意力模块的关系网络。首先采用骨干网络提取出帧的特征![]() ,最直接的方法是采用距离度量方法(欧氏距离或者余弦距离)计算得到两帧的相似度,帧间的注意力得分计算为:
,最直接的方法是采用距离度量方法(欧氏距离或者余弦距离)计算得到两帧的相似度,帧间的注意力得分计算为:
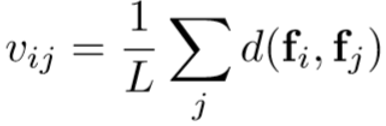
作者对此做了深层次的改进,提出了关系网络。输入每对帧的特征信息,即![]() 维的特征,通过多层感知,投影到了
维的特征,通过多层感知,投影到了![]() 维的关系空间,得到关系映射计算为:
维的关系空间,得到关系映射计算为:
![]()
由此得到一个规格为![]() 的关系映射矩阵,通过1*1卷积输出通道维度为1的关系注意力矩阵,每个元素
的关系映射矩阵,通过1*1卷积输出通道维度为1的关系注意力矩阵,每个元素![]() 表示第i帧和第j帧的关系权重,通过计算同其他L-1帧权重的平均得到该帧的关系注意力权重:
表示第i帧和第j帧的关系权重,通过计算同其他L-1帧权重的平均得到该帧的关系注意力权重:
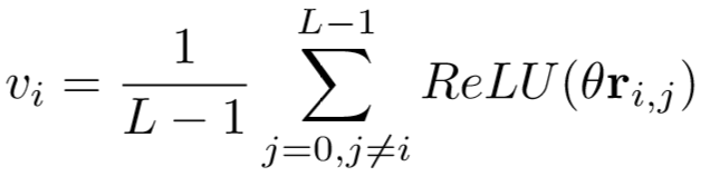
(3)语义维度:Multi-Stage:
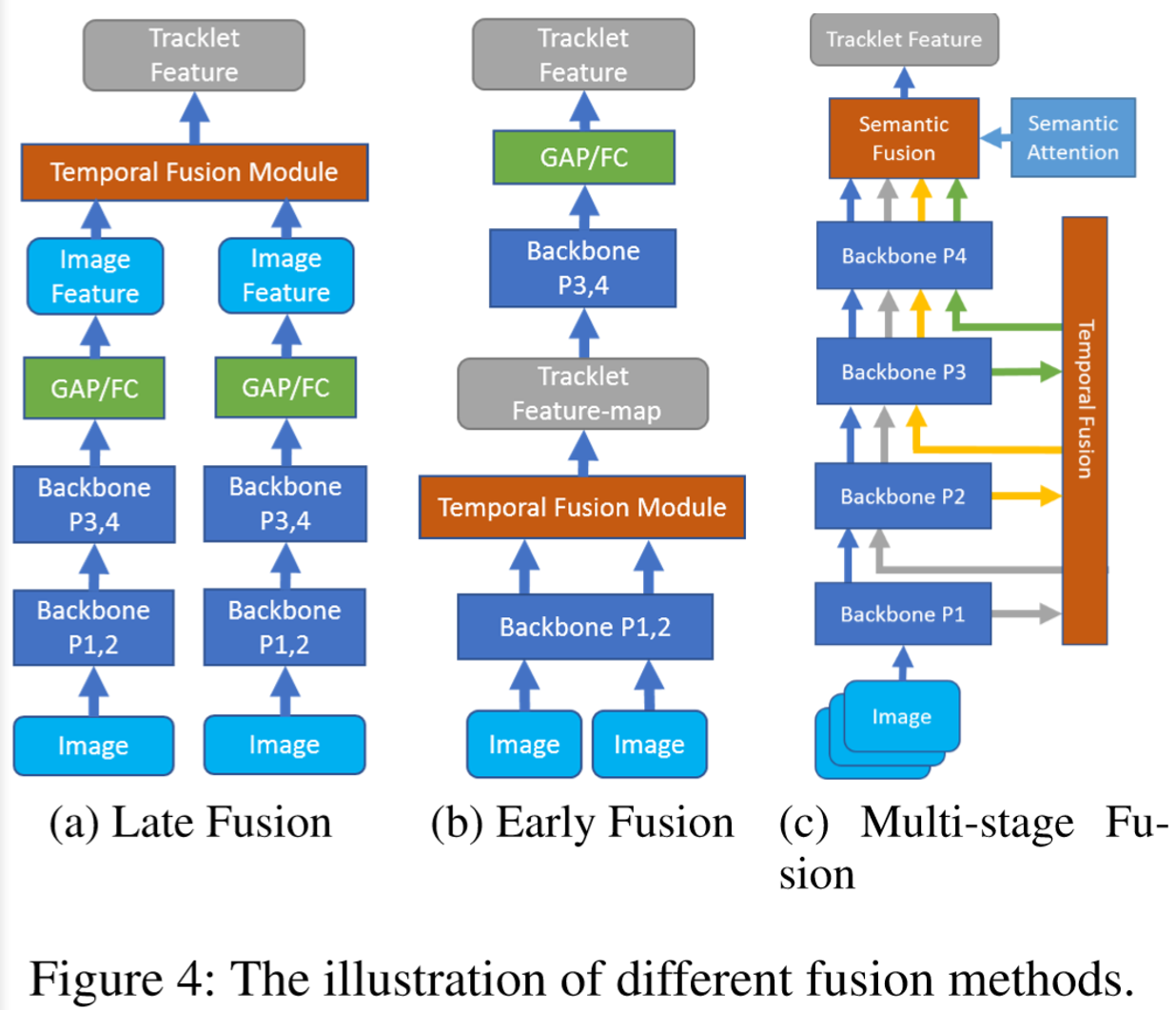
在多阶段特征融合上,作者采用了语义注意力模块。假定有K个来自不同阶段的特征,每个阶段的输出设为g,通过Softmax得到该阶段的重要性得分,即:
![]()
具体表示为:第i个分支提取的特征在第j个分支上所占的注意力权重。通过求平均得到第j个分支的注意力权重:
![]()
最终输出的特征为:
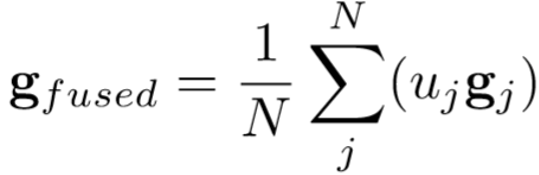
Experiments
(1)实验设置:
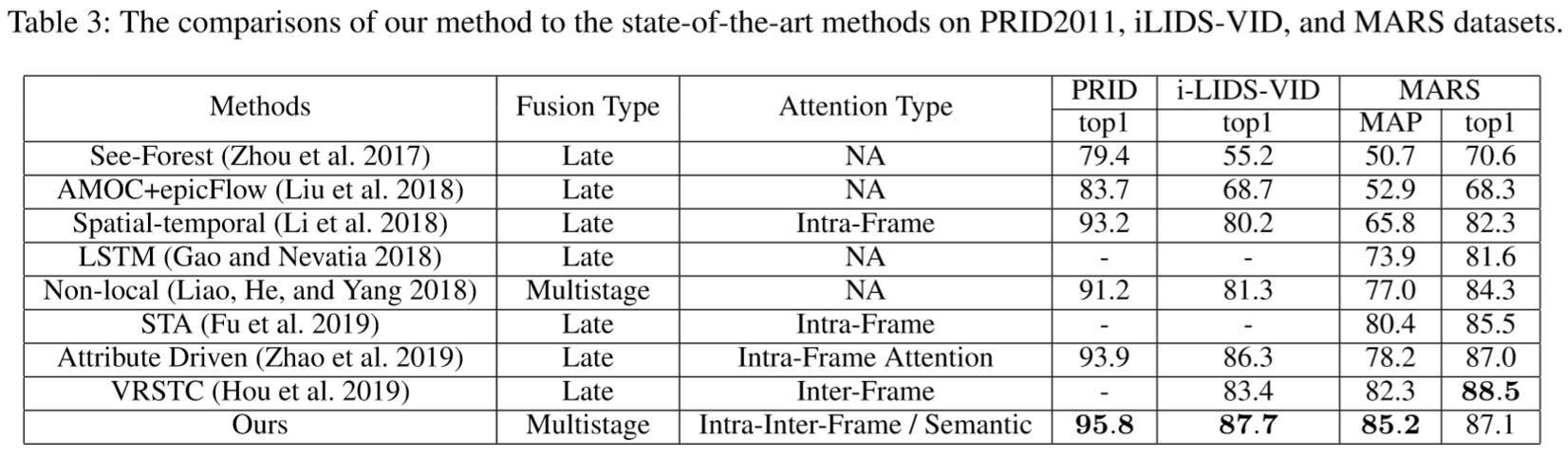
① 数据集设置:PRID2011、iLIDS-VID、MARS;
② 实验细节:采用了ResNet50作为骨干网络,用CUHK03、DukeMTMC、Market1501进行预训练,再在PRID2011、iLIDS-VID、MARS微调。
(2)实验结果: