论文阅读笔记(四十二)【AAAI2019】:STA:Spatial-Temporal Attention for Large-Scale Video-based Person Re-Identification
Introduction
本文主要提出了高效且容易实现的STA框架(Spatial-Temporal Attention)来解决大规模video Reid问题。框架中融合了一些创新元素:帧选取、判别力局部挖掘、不带参特征融合、视频内正则化项。
Proposed Method
(1)总体思路:
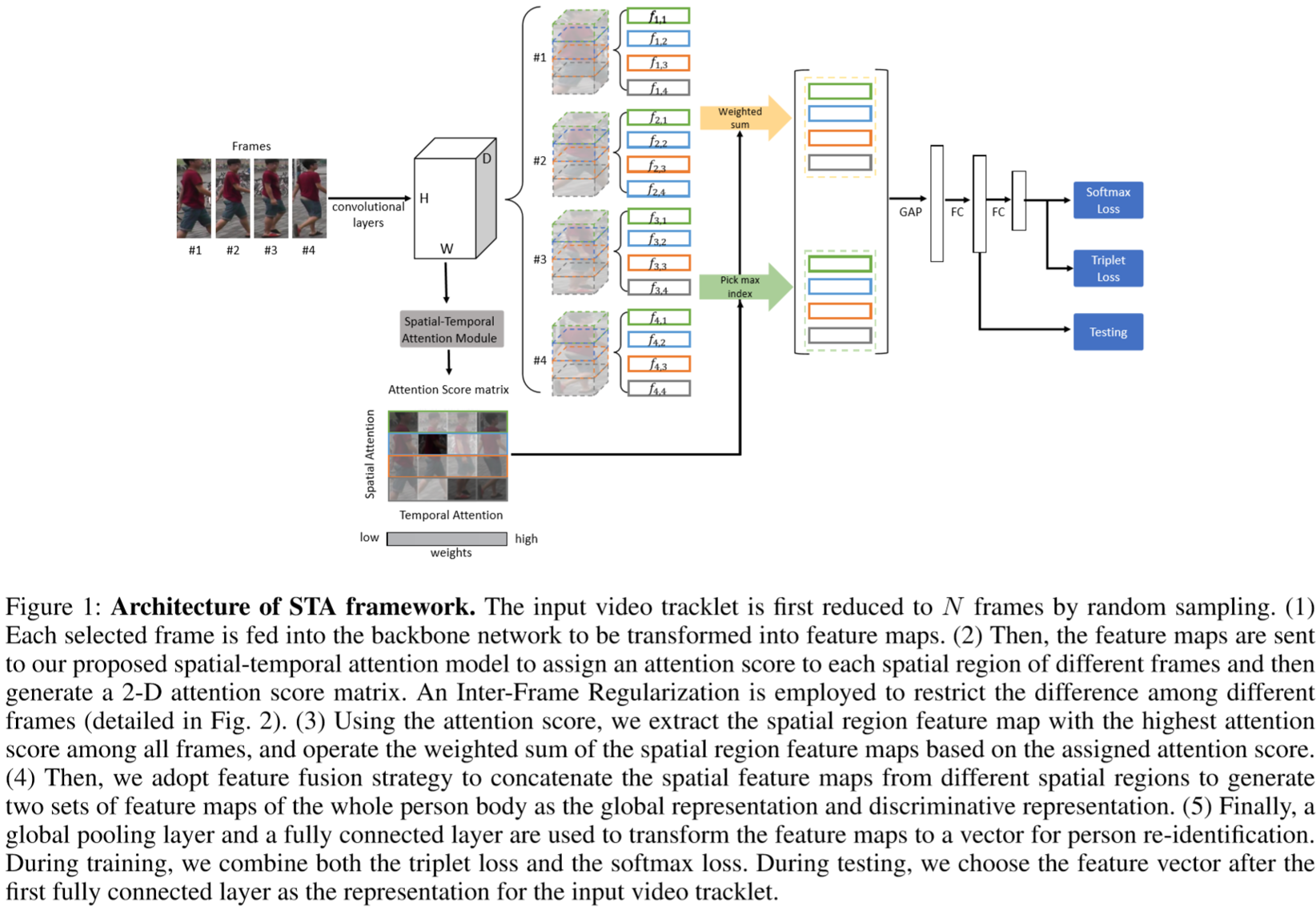
先通过骨干网络提取特征映射,再将特征映射通过STA框架生成2D的注意力得分矩阵。为了降低视频内各帧的差异,采用了视频内正则化项来评估视频内相似度。采用空间权重最大化、时间权重平均化的策略获得两个视频级特征映射。最后通过级联得到全局特征映射,进行平均池化和全连接层得到视频级特征向量。采用的损失函数为softmax损失和三元组损失。
(2)STA框架:
① 骨干网络:
采用了Resnet50,进行了如下改进:将conv5的步长改为1,得到的特征映射尺寸为2048*16*8。输入的视频采用随机采样,取N帧:![]() ,得到特征映射为:
,得到特征映射为:![]() 。
。
② STA模块:
之前提出的时空注意力方法存在以下缺点:CNN层多计算量大;输入的视频序列的帧数需要固定;没有关注到区域之间的空间关系(没有理解?);时空两种注意力由两个不同的模型提取。

通过骨干网络提取得到特征映射,每帧通过L2正则化在通道维度生成注意力映射,具体计算为:
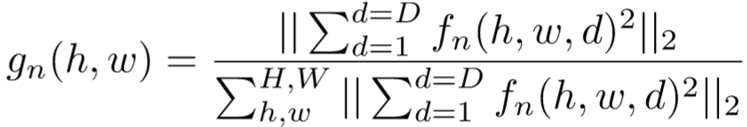
a将每帧分割为K块,由此每帧都得到若干特征映射、注意力映射:

在第k个区域的n帧上采用L1正则化,得到该区域的空间注意力得分:
![]()
由此可以得到整个视频的空间注意力得分,为N*K规格的矩阵S。
直接比较不同帧相同区域的注意力得分,通过L1计算获得时空注意力得分,为:
![]()
③ 视频内正则化:
同一个视频内部的行人帧需要表示相近的特征,常用的一个方法是增加一个分类损失来确保所有帧都属于同一个人,但一些噪声样本会增大训练过程的不稳定性。第二个方法是KL散度来衡量帧之间的相似度,但是在注意力映射中存在很多接近0的元素,在KL散度中的log计算中会趋近于无穷,带来训练的不稳定。为了限定视频内各帧的相似,且避免只关注到一帧的情况,本文采用了视频内正则化项。具体为:
定义G为不同帧的注意力映射图:
![]()
假设为不同的两帧注意力映射,计算两者的F范式为:
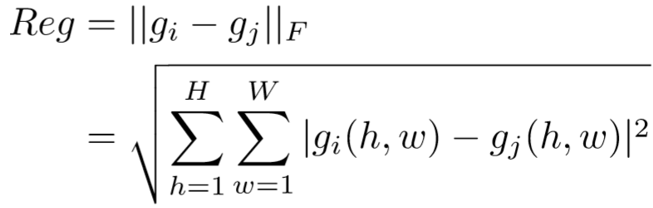
最终将其结合进损失函数,即为:
![]()
④ 特征融合策略:

最终concat得到特征通过平均池化和全连接层得到特征向量X,即:
![]()
⑤ 损失函数:
采用了三元组损失和softmax损失:

![]()
Experiment
(1)实验设置:
① 数据集设置:Mars、DukeMTMC-VideoReID
② 参数设置:每个视频随机选取N=4帧,区域划分为K=4份,每个batch选取16个ID各4个视频;三元组损失的margin=0.3;采用Adam优化器,weight decay=0.0005;lr=0.0003,并在200和400次迭代时下降到1/10,总共迭代800次。实验在两个NVIDIA TITAN X GPU上训练。
(2)实验结果:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号