论文阅读笔记(四十一)【CVPR2017】:Learning Deep Context-aware Features over Body and Latent Parts for Person Re-identification
Introduction
(1)Motivation:
当前的行人重识别方法存在如下两个问题:
① 随着网络的深入,行人的细节特征难以捕捉,例如鞋子、墨镜;
② 硬性分割行人区域存在语义的不对齐。
(2)Contribution:
针对问题①,作者提出了Multi-Scale Context-Aware Network(MSCAN),如下图,MSCAN每个卷积层都采用了不同感受野的空洞卷积核,再级联为该层的输出,感知不同大小的区域特征。针对问题②,作者提出了Spatial Transform Networks(STN),用于定位行人的不同区域。
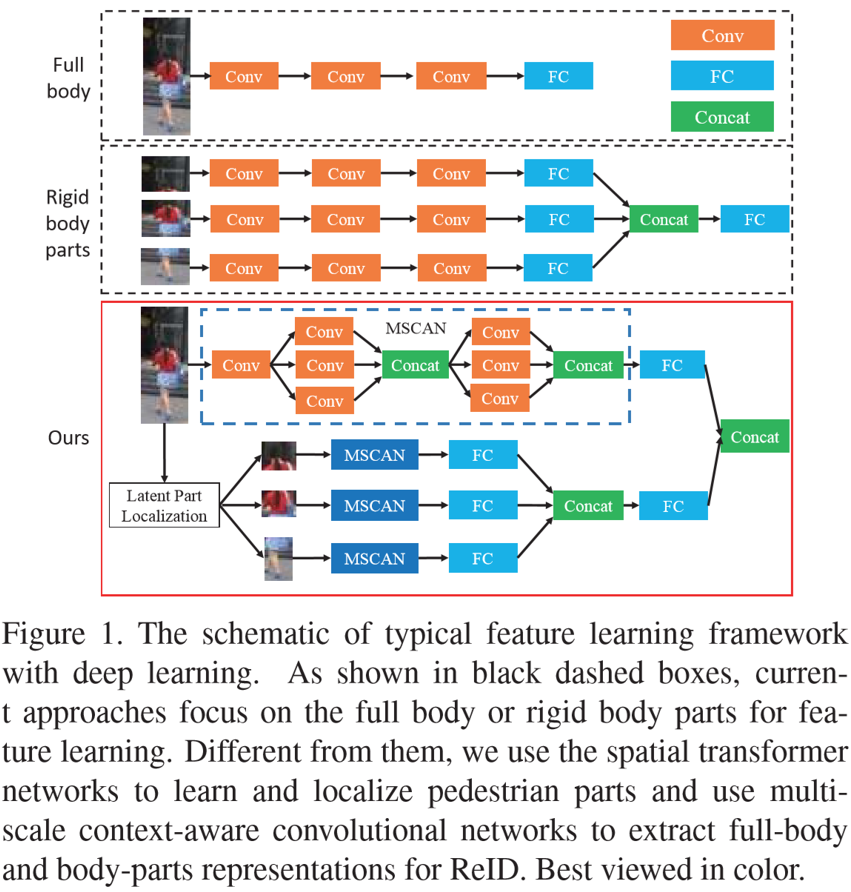
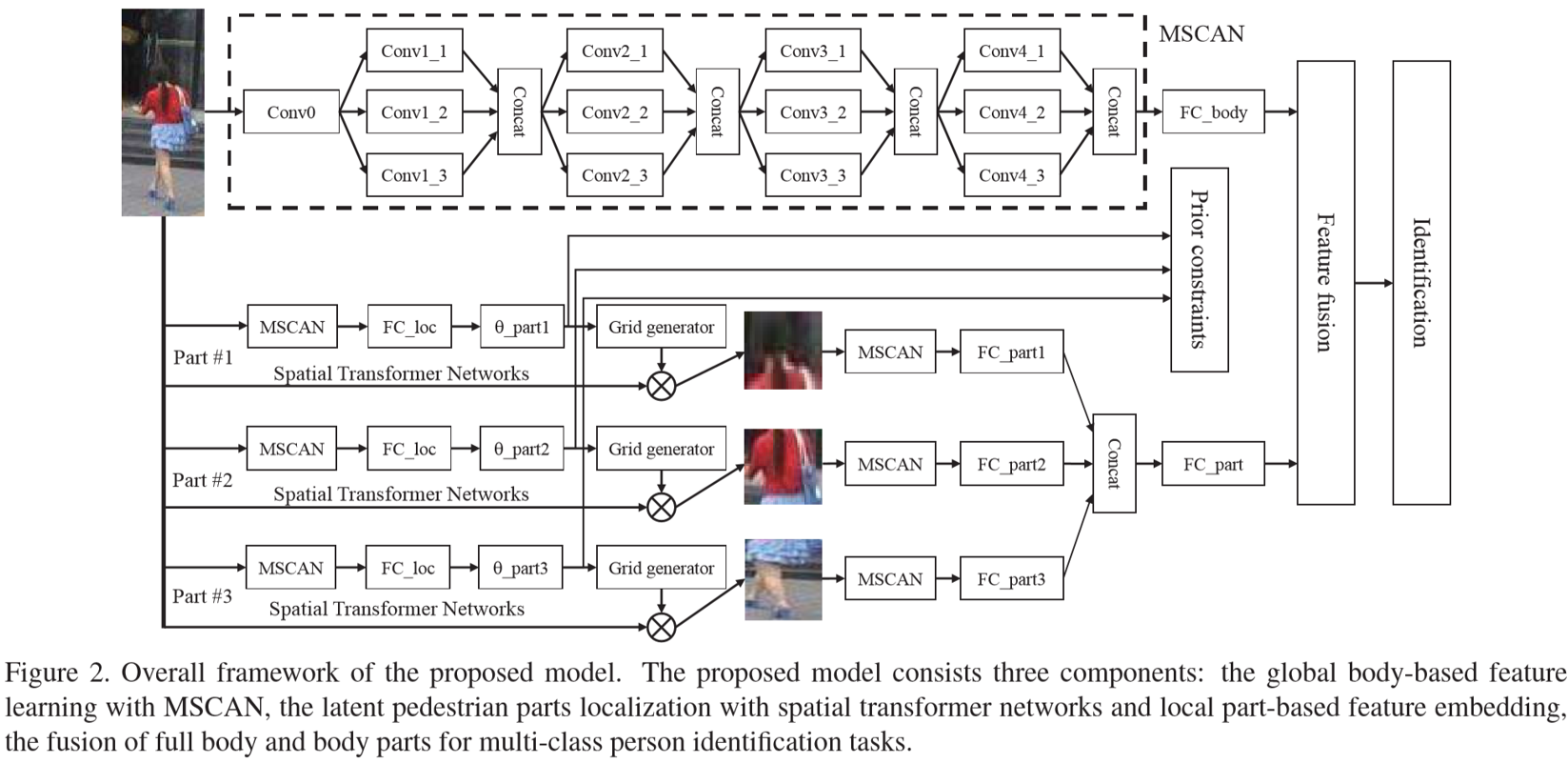
Proposed Method
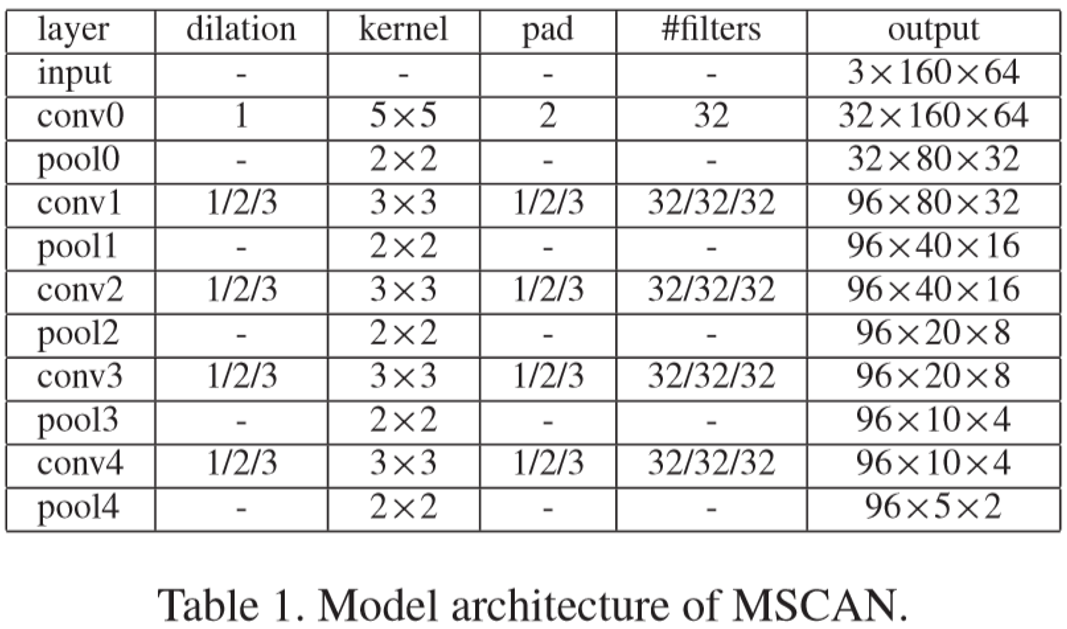
(1)Multi-scale Context-aware Network:
MSCAN的网络结构如下图:
(2)Latent Part Localization:
作者采用STN作为区域定位网络,包含两个部分:学习图像转换的参数;采用图像插值生成区域图像。转换参数为![]() ,s为scale,t为translation,图像的宽高正规化到[-1, 1],生成的区域图像为:
,s为scale,t为translation,图像的宽高正规化到[-1, 1],生成的区域图像为:
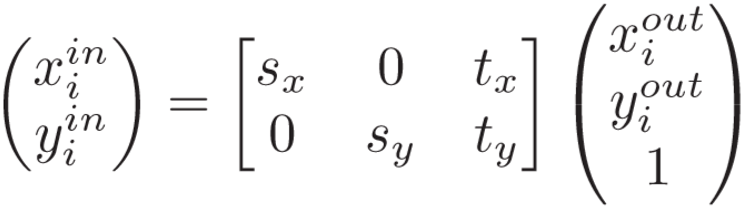
其中 i 表示为像素点编号。
三个区域分支的MSCAN模块均为提取全局的特征,再通过FC_loc层提取得到128维的特征,这部分共享参数,之后再通过各自的FC层提取到四个转换参数。提取得到的局部图像规格为96*64。
区域定位网络存在三个难点:
① 三个子网络很容易关注到相同的区域,比如中间位置;
② Scale参数容易成为负数,导致图像翻转;
③ 区域可能会定位到图像之外。
针对问题①,作者预估了偏移的局部中心区域,设定三个区域的(Cx,Cy)分别为(0,0.6), (0,0), (0,−0.6),以至于学习得到的区域能够互补,其中α = 0.5,即:
![]()
针对问题②,作者希望scale的值为正,以至于预测的区域更合理,其中β = 0.1,即:
![]()
针对问题③,作者采用图像内裁剪的约束,其中γ = 1.0,即:
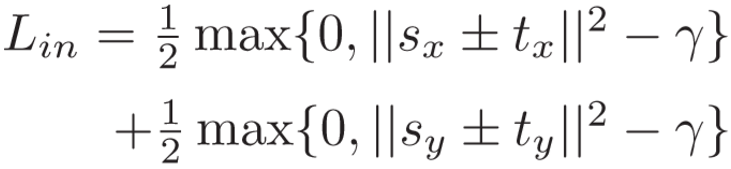
最终局部损失为:
![]()
(3)Feature Extraction and Fusion:
每个局部特征都采用MSCAN提取,得到128维的特征向量,再将三个融合为一个。最后全局和局部特征进行级联,得到256维特征向量。
(4)目标函数:
分类任务采用softmax损失,即:
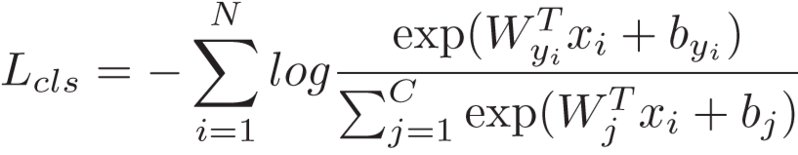
最终损失函数为:
![]()
Experiments
(1)实验设置:
① 数据集设置:Market1501、CUHK03、MARS;
② 参数设置:模型基于Caffe;图片大小resize为150*64;batch size = 64;learning rate = 0.01,并在1w次迭代后下降至0.01倍;momentum = 0.9,weight decay = 5*10-3;共迭代5w次。
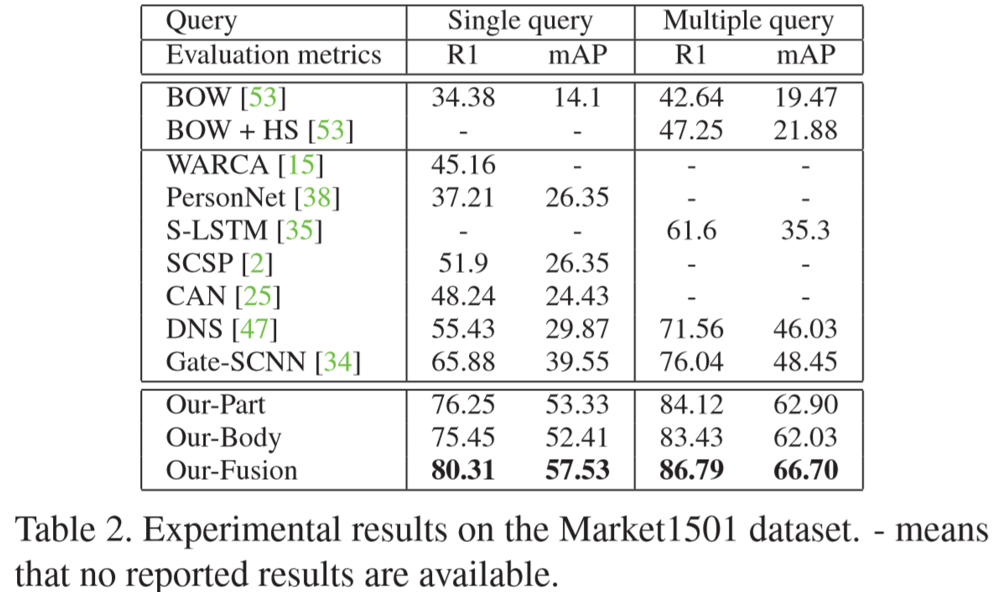
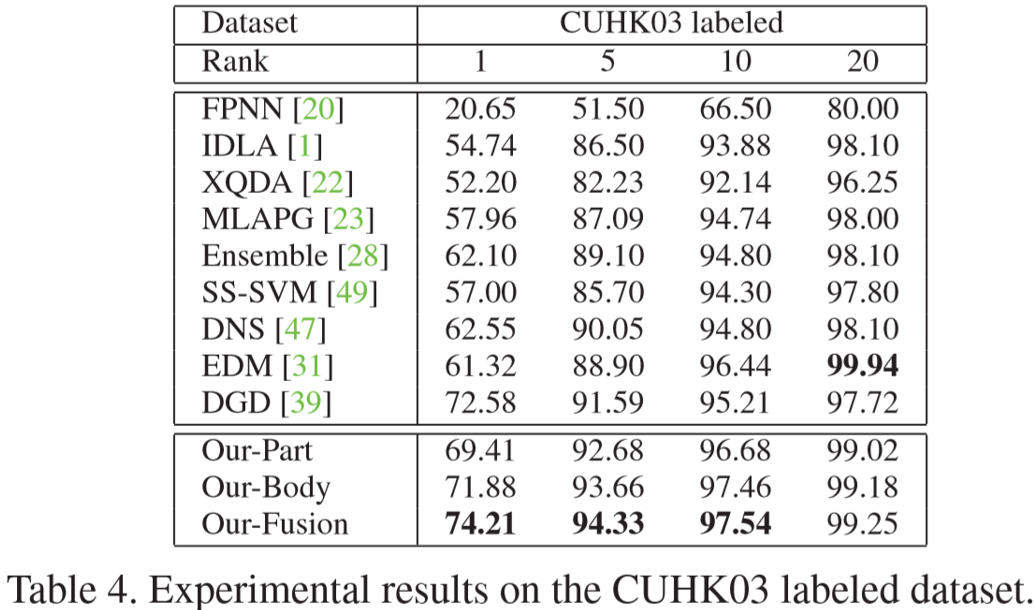
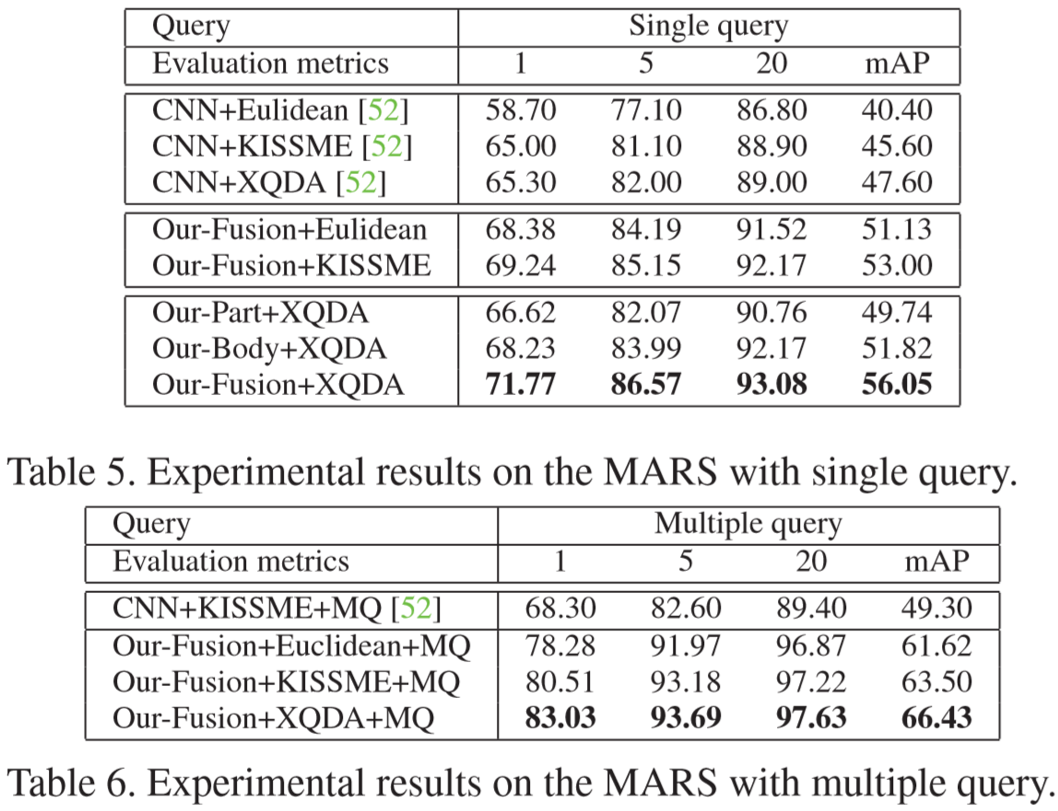
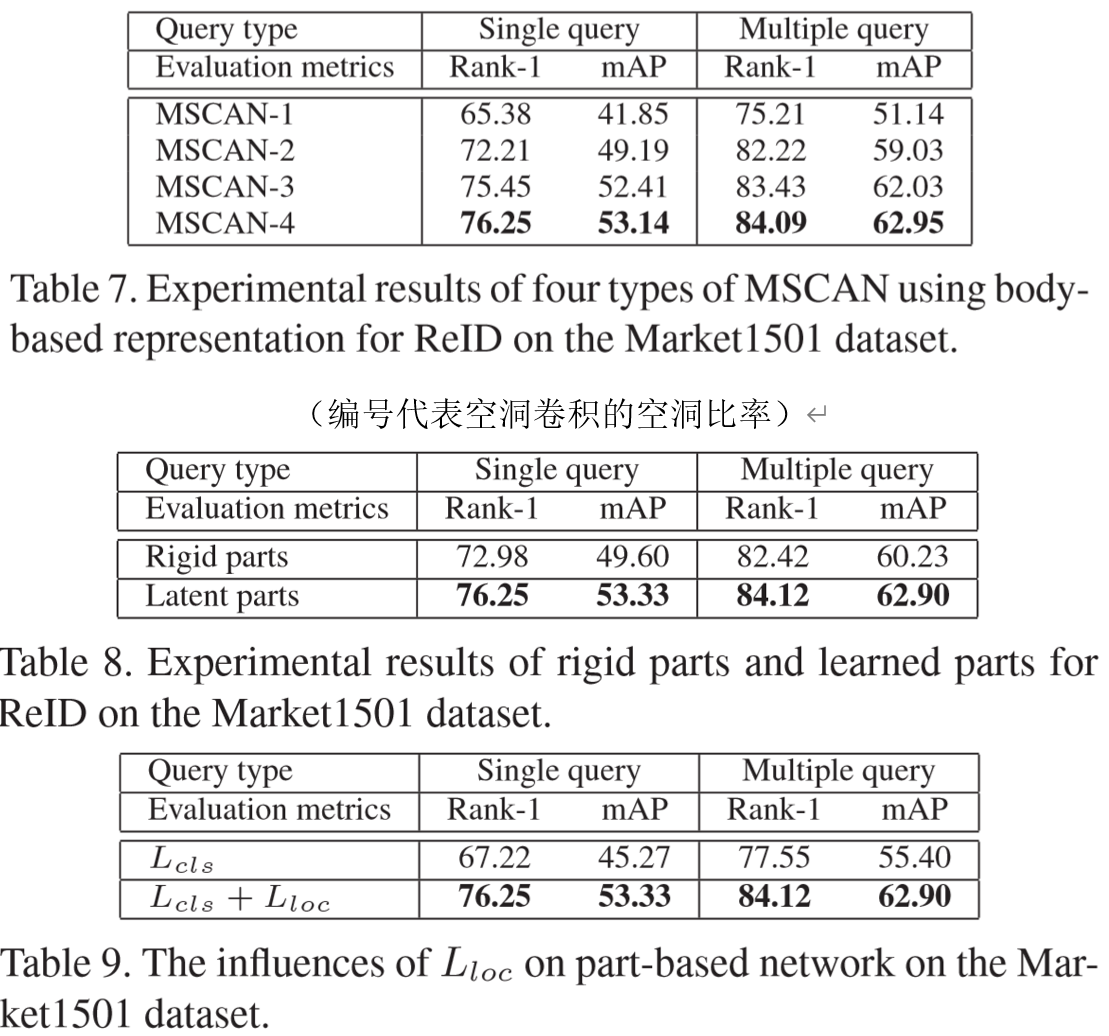
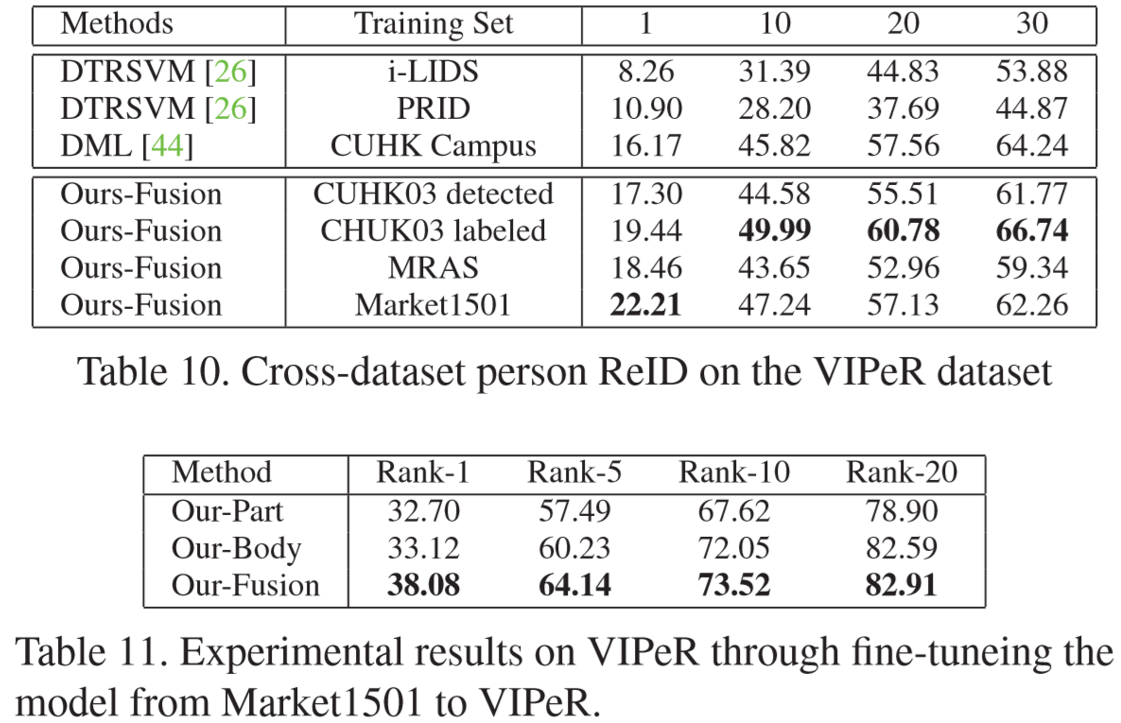
(2)实验结果: