论文阅读笔记(三十六)【AAAI2020】:Relation-Guided Spatial Attention and Temporal Refinement for Video-based Person Re-Identification
Introduction
为了提取两个特征之间的相关性,设计了Relation Module(RM)来计算相关性向量;
为了减小背景干扰,关注局部的信息区域,采用了Relation-Guided Spatial Attention Module(RGSA),由特征和相关性向量来决定关注的区域;
为提取视频级特征,采用了Relation-Guided Temporal Refinement Module(RGTR),通过帧之间的关系信息融合为视频特征。
Method
(1)框架概述:

假定输入的视频片段为![]() ,采用CNN提取得到单帧的特征映射
,采用CNN提取得到单帧的特征映射![]() ,传入RGSA提取得到帧级特征向量
,传入RGSA提取得到帧级特征向量![]()
![]() ,得到向量集合
,得到向量集合![]() ,最后通过RGTR得到视频级特征向量
,最后通过RGTR得到视频级特征向量![]() 。采用的损失包含:帧级的交叉熵损失、视频级的交叉熵损失、三元组损失。
。采用的损失包含:帧级的交叉熵损失、视频级的交叉熵损失、三元组损失。
(2)RM模块:
计算两个向量之间的关系最简单的方法是求向量的内积,但其结果只能表明向量间的相似度,忽视了局部的相似度和差异。另一个常用计算方法是计算元素差异,但这种方法包含了冗余信息,且计算量大。因此作者提出了RM模块来计算两个特征之间的关系向量。
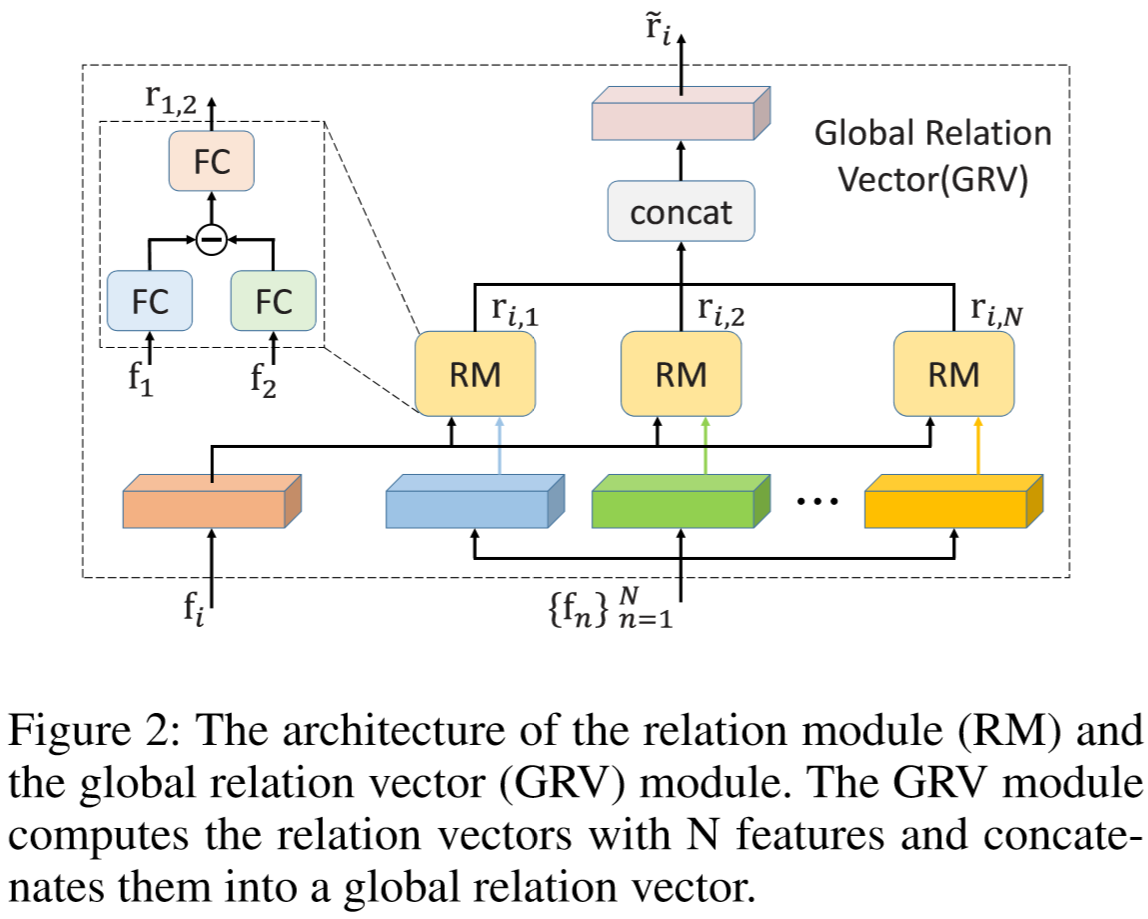
两个特征之间的差异度计算为:![]() ,其中
,其中![]()
![]() ,
,![]() ,其中
,其中![]() ,最终得到相关性向量为:
,最终得到相关性向量为:![]() ,其中
,其中![]() 。
。
(3)RGSA模块:
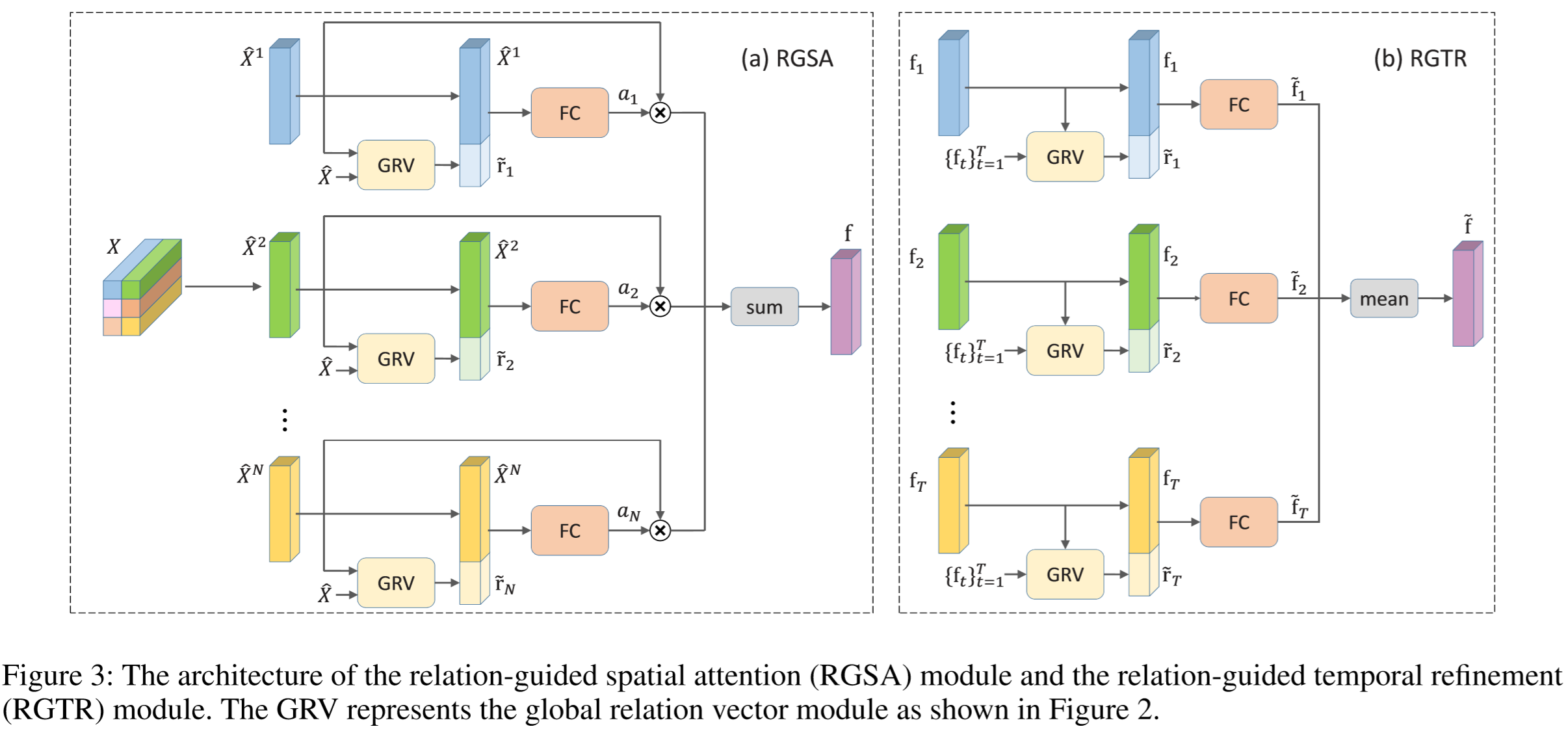
假定图像的特征映射为![]() ,其中
,其中![]() 表示不同的空间元素,每个元素都表示为 C 维的特征向量,将特征重构为
表示不同的空间元素,每个元素都表示为 C 维的特征向量,将特征重构为![]() ,针对每一个空间元素都计算其与其它位置元素的相关性向量,即:
,针对每一个空间元素都计算其与其它位置元素的相关性向量,即:
![]()
与位置 i 有关的相关性向量concat为:
![]()
其中:![]() ,得到空间的注意力得分:
,得到空间的注意力得分:
![]()
其中![]() ,最终特征向量融合了空间注意力,为:
,最终特征向量融合了空间注意力,为:
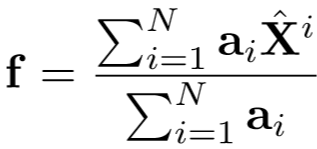
(4)RGTR模块:
通过上述模块提取得到帧级的特征向量![]() ,通过RM模块提取帧之间的相关性向量:
,通过RM模块提取帧之间的相关性向量:
![]()
将关于 t 帧的相关性向量进行concat,为:
![]()
与原特征进行融合,为:
![]()
最终视频级的特征向量为:
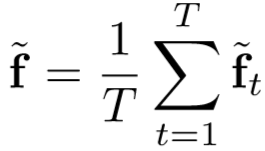
(5)损失函数:
对视频级特征、帧级特征采用交叉熵损失,分别为![]() 、
、![]() ,总交叉熵损失为:
,总交叉熵损失为:
![]()
三元组损失计算为:
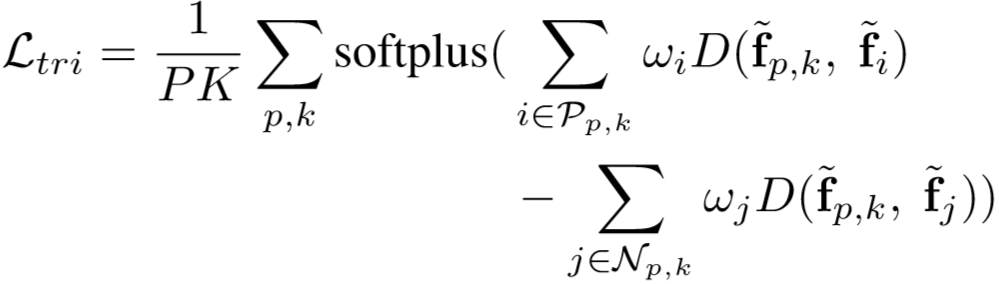
其中: ,
,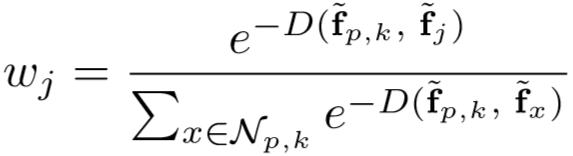 ,
,![]() ,
,![]() 为距离函数。
为距离函数。
全局损失为:
![]()
Experiment
(1)实验设置:
① 数据集:MARS、DukeMTMC-VideoReID、iLIDS-VID、PRID-2011;
② 实验细节:在训练阶段随机从视频中挑选T帧,每个batch包含 P 个行人ID,每个行人ID包含 K 个视频;数据输入采取随机翻转、随机擦除;骨干网络采用预训练的ResNet50;训练阶段选取帧数为T/2;采用4块NVIDIA Tesla V100 GPU进行训练测试;
③ 参数设置:P = 18,K = 4,即batch size = 72 T;输入图像规格为 256*128;训练器为Adam,其weight decay = 5*10-4;迭代次数为375次;学习率为3*10-4,在125个epoch和250个epoch后均下降到0.1倍。
(2)实验结果:

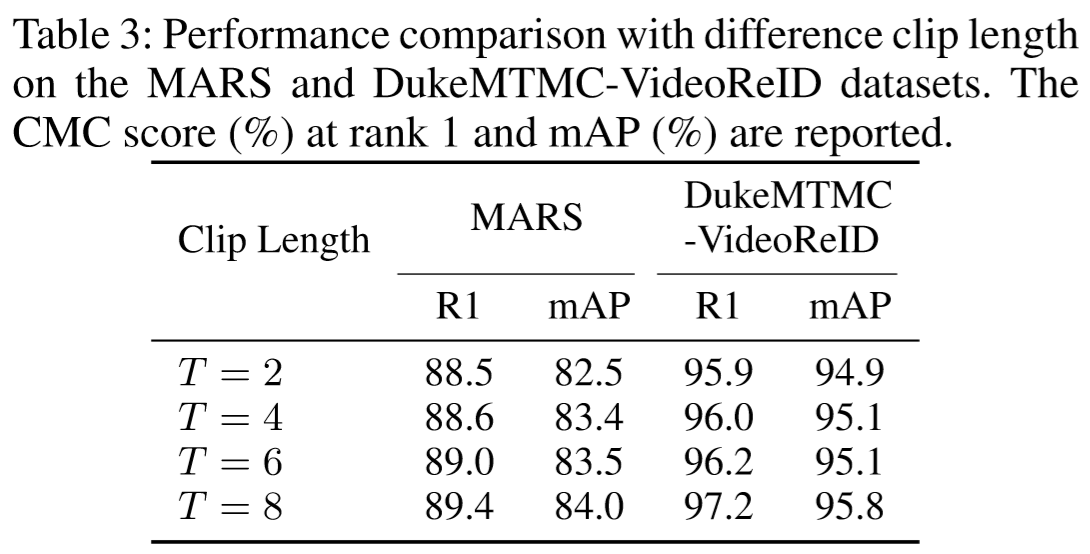
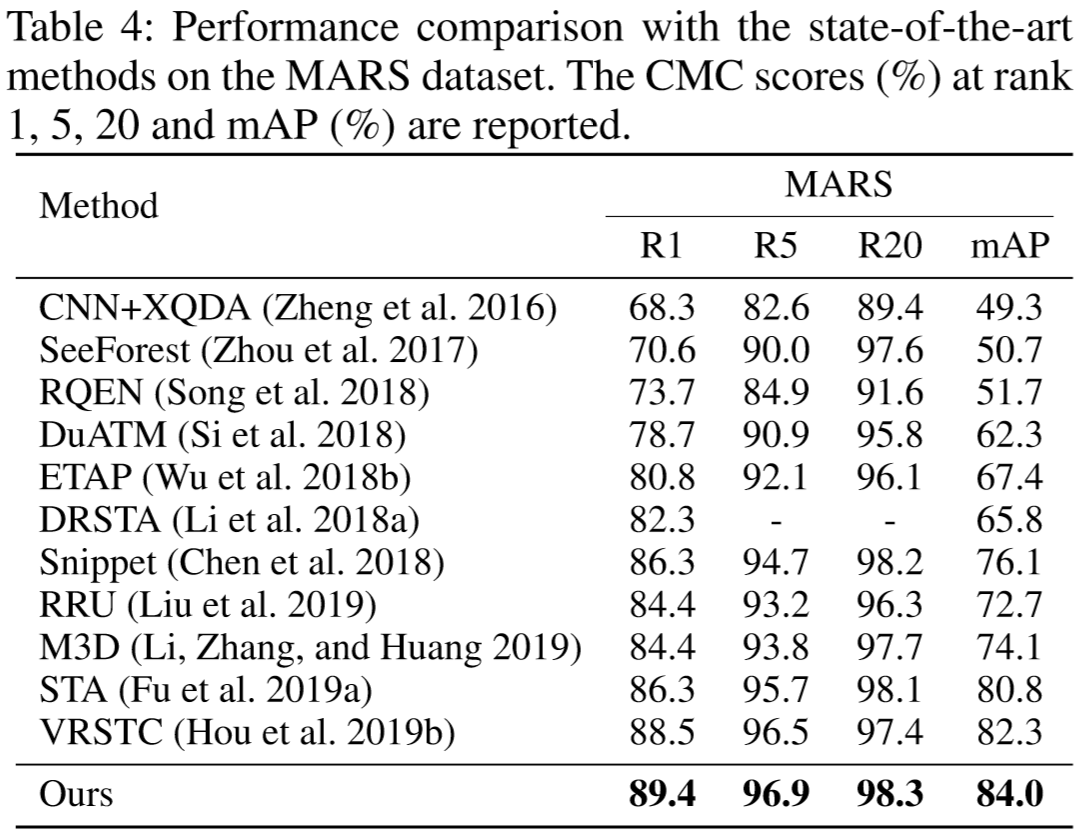
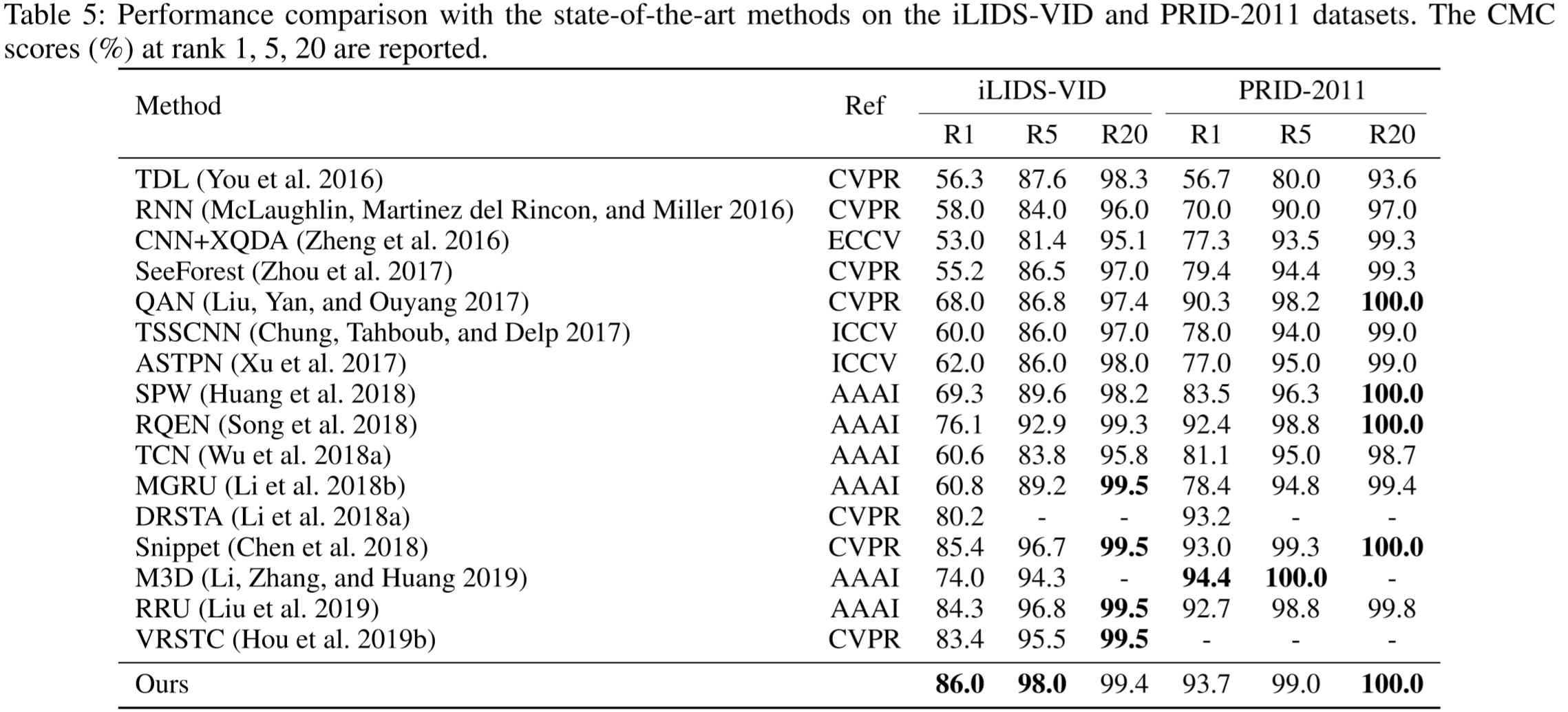
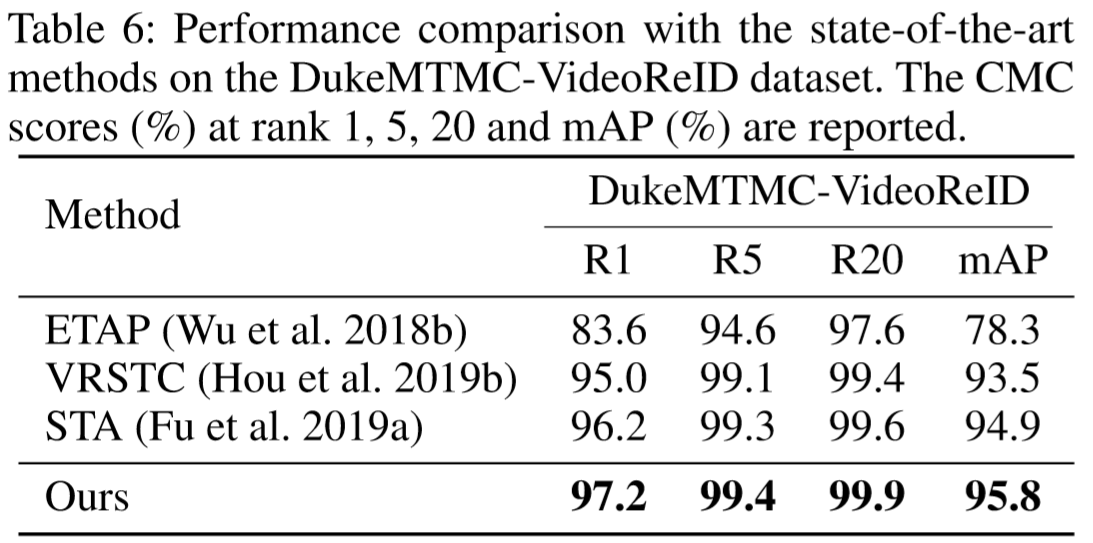
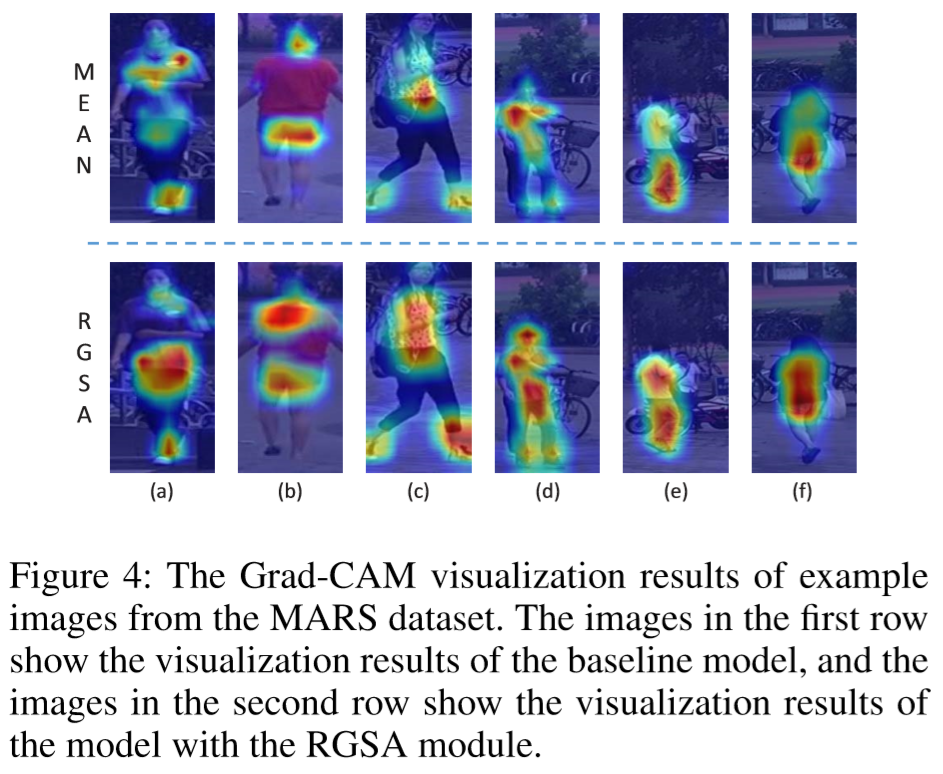
(3)方法效果可视化:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号