论文阅读笔记(二十六)【AAAI2019】:Multi-Scale 3D Convolution Network for Video Based Person Re-Identification
Introduction
(1)Motivation:
当前的基于视频的reid可以大致分为以下两类工作:
① 提取帧级特征,通过池化或者加权学习生成视频特征;
② 提取帧级特征,应用RNN生成视频特征。
前者损失了帧的顺序信息,后者主要提取高阶特征但无法捕捉图像局部细节。
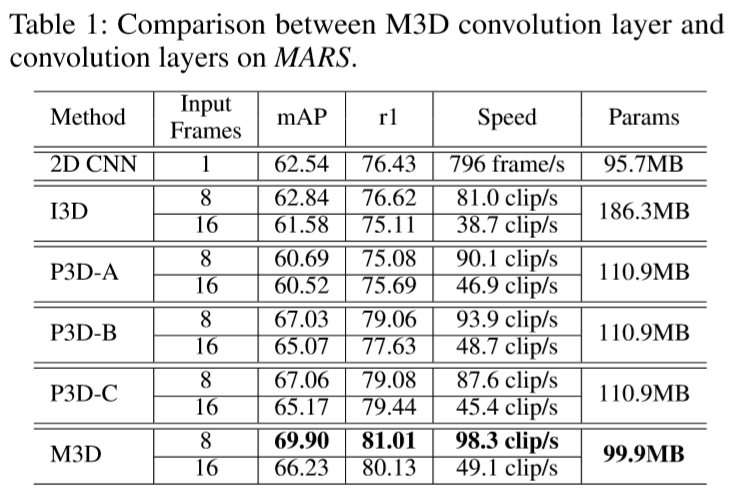
3D CNN对连续帧的视觉样貌和时间线索进行编码,但当前的3D CNN方法(如C3D)由于产生大量的参数,对模型训练和优化都带来巨大的困难。
下图为当前提出的一些卷积层:
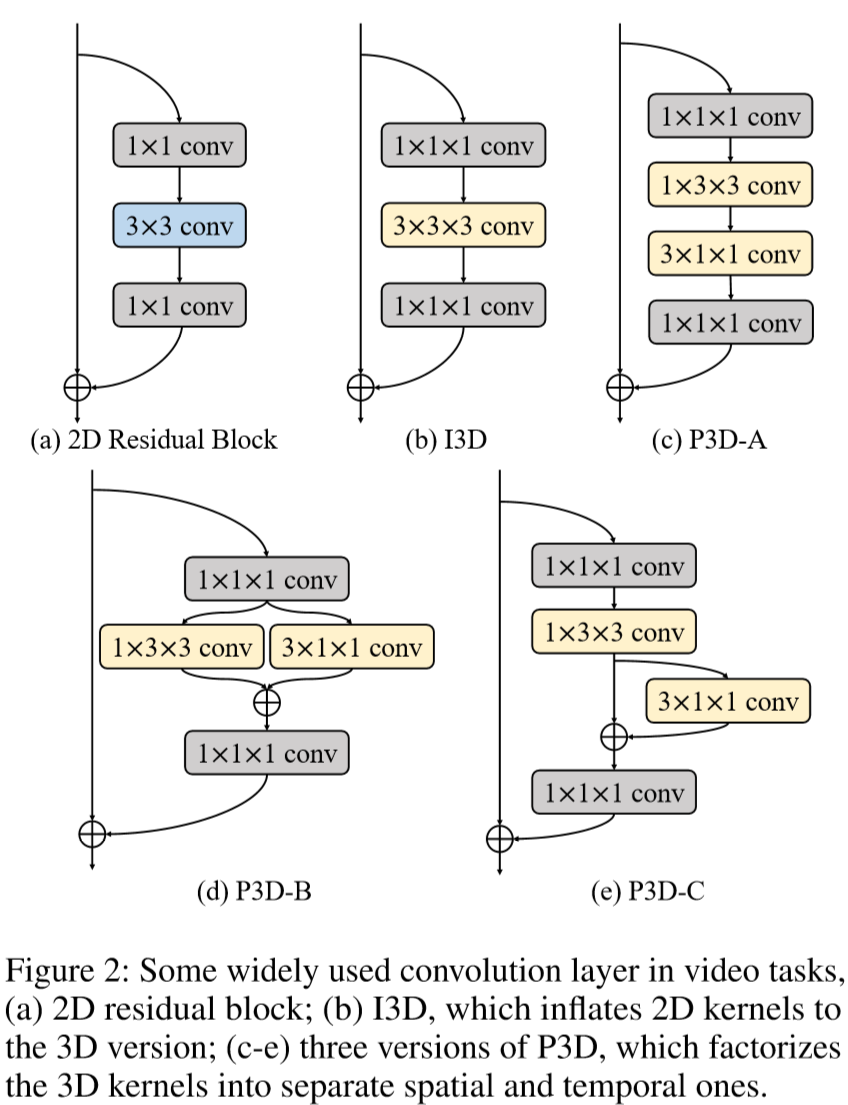
(2)Contribution:
① 提出了 Multi-scale 3D(M3D)卷积层,相比传统的3D CNN更高效更紧凑。M3D对不同的时间范畴采用多平行时间卷积核,在2D CNN中插入多个M3D。相比传统3D CNN,M3D更紧凑更容易训练;
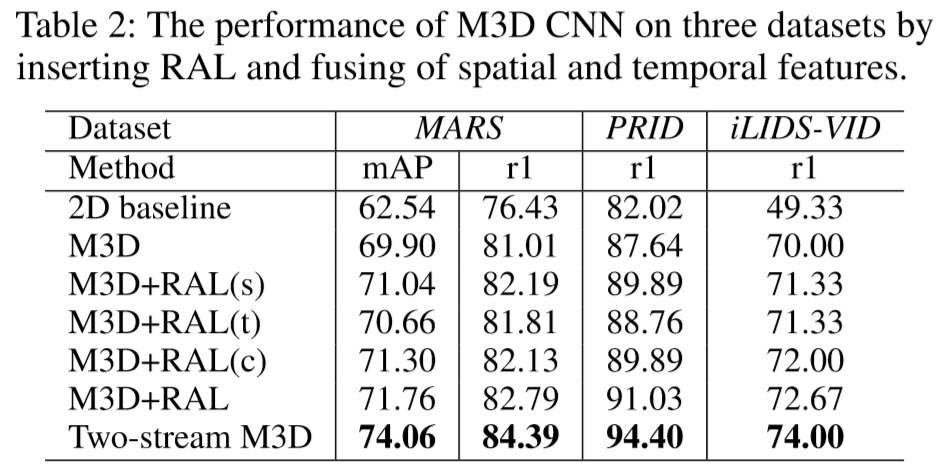
② 为了进一步改进时间线索,作者提出了Residual Attention Layer(RAL)来联合学习时空注意力掩码(mask),由此可以使得M3D CNN可以提取更有判别力的时间特征;
③ 引入2D CNN从视频序列中提取时空特征,与M3D CNN结合成双流卷积架构,将时空特征融合成基于视频的行人表征。
Two-stream M3D Convolution Network
(1)问题定义:
query视频序列为:![]() ,其中 T 为序列长度,
,其中 T 为序列长度,![]() 指第 t 帧图像。每个视频的特征可以表示为:
指第 t 帧图像。每个视频的特征可以表示为:![]() ,前者表示空间特征,后者表示时间特征,两者进行concat。
,前者表示空间特征,后者表示时间特征,两者进行concat。
对于基于图片的reid,空间特征提取方法通常采用2D CNN,作者有次采用现存的2D CNN方法处理每一帧,并进行平均池化,即:
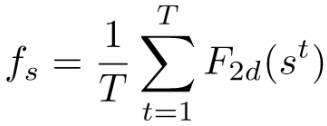
然而单纯的空间特征效果不佳,作者再使用M3D卷积网络提取多尺度时间线索,即:
![]()
2D CNN 和 M3D 网络组成了双流神经网络,如下图:
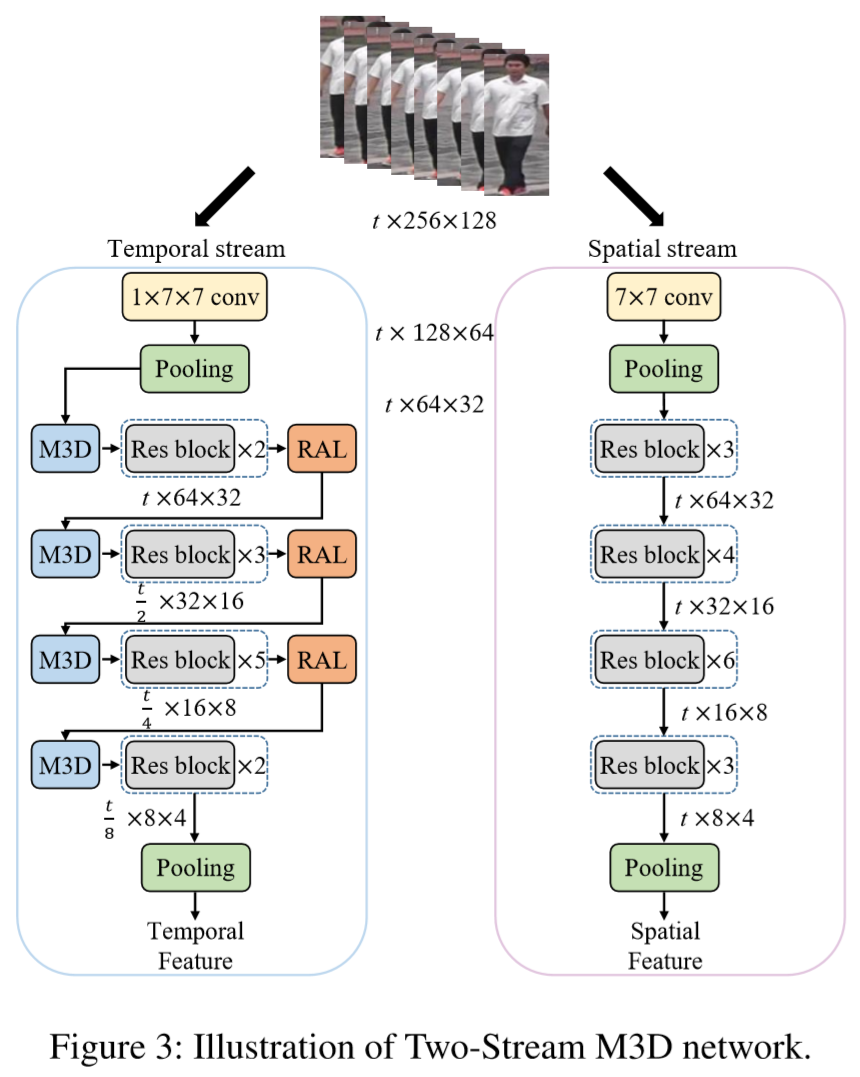
(2)M3D 卷积网络:
① 3D卷积:
一个视频片段可以看做4维张量 C * T * H * W,参数含义分别为颜色通道数、时间长度(帧数)、每帧高度、每帧宽度。3D卷积核为 t * h * w(省略了通道),其中 t 为时间深度,h 和 w 为空间尺寸。但如图2(b)-(e)的3D卷积,只能获取相邻3帧的联系,要想获得更长的时间线索,那就需要多卷积核concat成一个深层网络,因而导致参数剧增,难以训练。
② 多尺度3D卷积(Multi-scale):
受到空洞卷积(dilated convolution【传送门】)的启发(具体参考Yu and Koltun在2015的Multi-scale context aggregation by dilated convolutions. ),一个M3D层包含了一个空间卷积核和 n 个不同时间跨度的平行时间核。假设一个输入的特征为:![]() ,定义M3D层为:
,定义M3D层为:
![]()
其中 S 为空间卷积,![]() 为扩张率为 i 的时间卷积,具体计算如下:
为扩张率为 i 的时间卷积,具体计算如下:
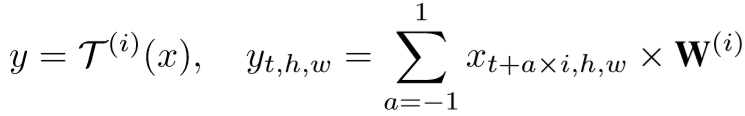
其中![]() 为第 i 个时间卷积核。
为第 i 个时间卷积核。
下图阐述了 n = 3 时M3D的细节,n控制着时间维度感受野的大小,当 n = 1 时,M3D即等同于P3D-C(详情参考Qiu, Yao, and Mei在2017的 Learning spatio-temporal representation with pseudo-3d residual networks. )

为了限制感受野大小不超过时间维度的尺寸,设置 n 的大小为:![]()
③ 残差注意力层(Residual Attention Layer):
由于不同的帧呈现不同的视觉质量,因此采用注意力机制,来区别对待不同的时空线索。假设输入的特征张量为![]() ,RAL输出的显著性注意力掩码为
,RAL输出的显著性注意力掩码为![]() ,残差注意力模型为:
,残差注意力模型为:
![]()
RAL的细节如下图所示:

M 的学习可以划分为三个低维度注意力掩码,从而降低参数:
![]()
其中![]() ,
,![]() ,
,![]()
![]() 分别表示空间、通道、时间掩码。
分别表示空间、通道、时间掩码。
④ 空间注意力掩码学习:
假设输入为![]() ,先进行全局时间池化,即:
,先进行全局时间池化,即:
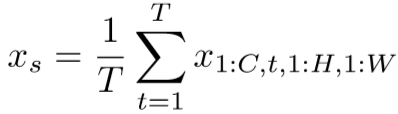
再进行两次卷积,第一次卷积将通道数降为1,第二次采用1*1卷积,即:
![]()
⑤ 通道注意力掩码学习:
先进行全局时空池化,即:
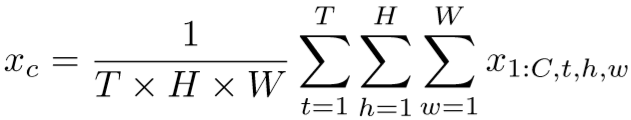
再进行两次卷积,第一次卷积采用bottlenect【传送门】将通道压缩至 ![]() ,其中 r 表示bottlenect reduction rate,作者设置为16,第二次卷积将通道恢复至c,即:
,其中 r 表示bottlenect reduction rate,作者设置为16,第二次卷积将通道恢复至c,即:
![]()
⑥ 时间注意力掩码学习:
结构与通道注意力掩码学习几乎一致,先进行全局时空池化,再通过两次1*1卷积。
Experiment
(1)实验设置:
① 数据集设置:PRID-2011,iLIDS-VID,MARS;
② 参数设置:图片尺寸256*128;对于2D CNN,batch size = 128,learning rate = 0.001,并在10次迭代后下降至0.1倍,总迭代次数为20次;对于3D CNN,对于 T = 8 时batch size = 24,对于T = 18时batch size = 12,总迭代次数为400,learning rate = 0.01,并在300次迭代后下降至0.1倍;
③ 实验细节:2D CNN 采用resnet50。
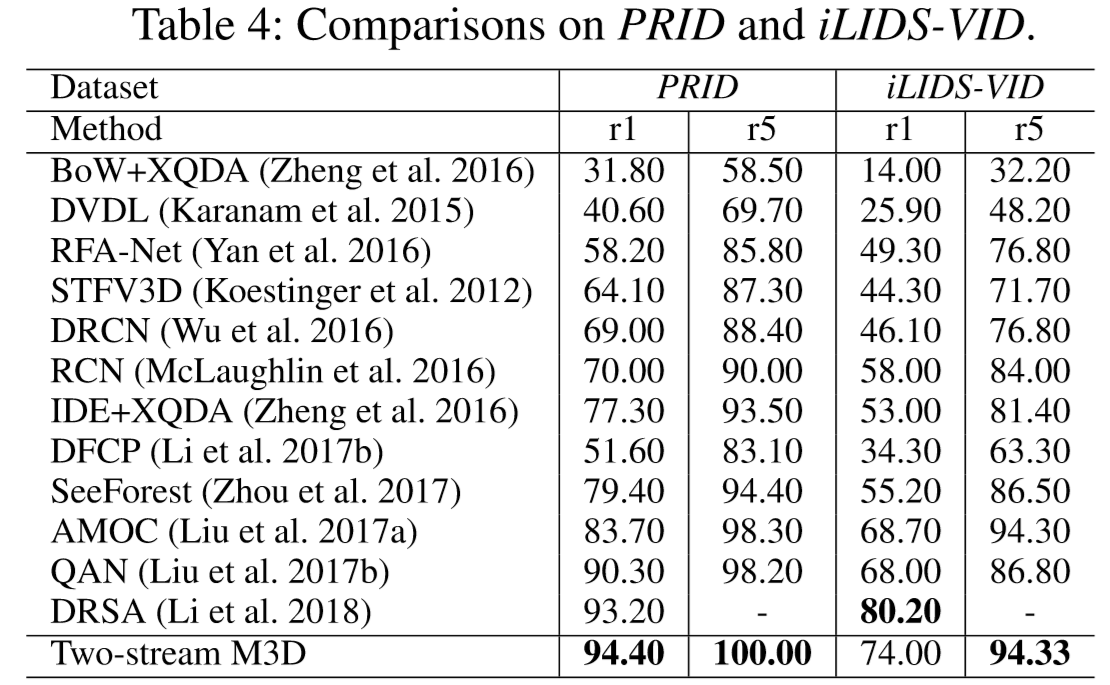
(2)实验结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号