论文阅读笔记(二十四)【AAAI2018】:Video-Based Person Re-Identification via Self Paced Weighting
Introduction
(1)Motivation:
① 大部分基于视频的reid方法把视频序列看做图片集,没有注意到动作遮挡引起质量差异,(带噪声的序列称为未正规化序列)。
② 有的方法采用了跟踪步态周期的光流算法,但方法在噪声的影响下很难获得可靠的光流估计。
(2)Contribution:
提出了 self pace weighting(SPW)方法,解决以下两个问题:
① 将视频序列划分为若干相同的子序列,并判断状态(噪声/干净);
② 评估噪声的情况,并得到一个鲁棒的距离度量。
对应 ①,作者定义了 sequence stability measure(SSM)来自动将未正规化的视频序列划分为多个子序列;
对于 ②,受到 curriculum learning(简单概括就是先学习容易的情况再去学习复杂的情况)的启发,提出了一个 self paced outlier detection(SPOD)方法来评估噪声的等级,并提出了一个adaptice weighted multi-pair distance metric learning 方法来衡量视频序列之间的距离。
Proposed Approaches
(1)概述:
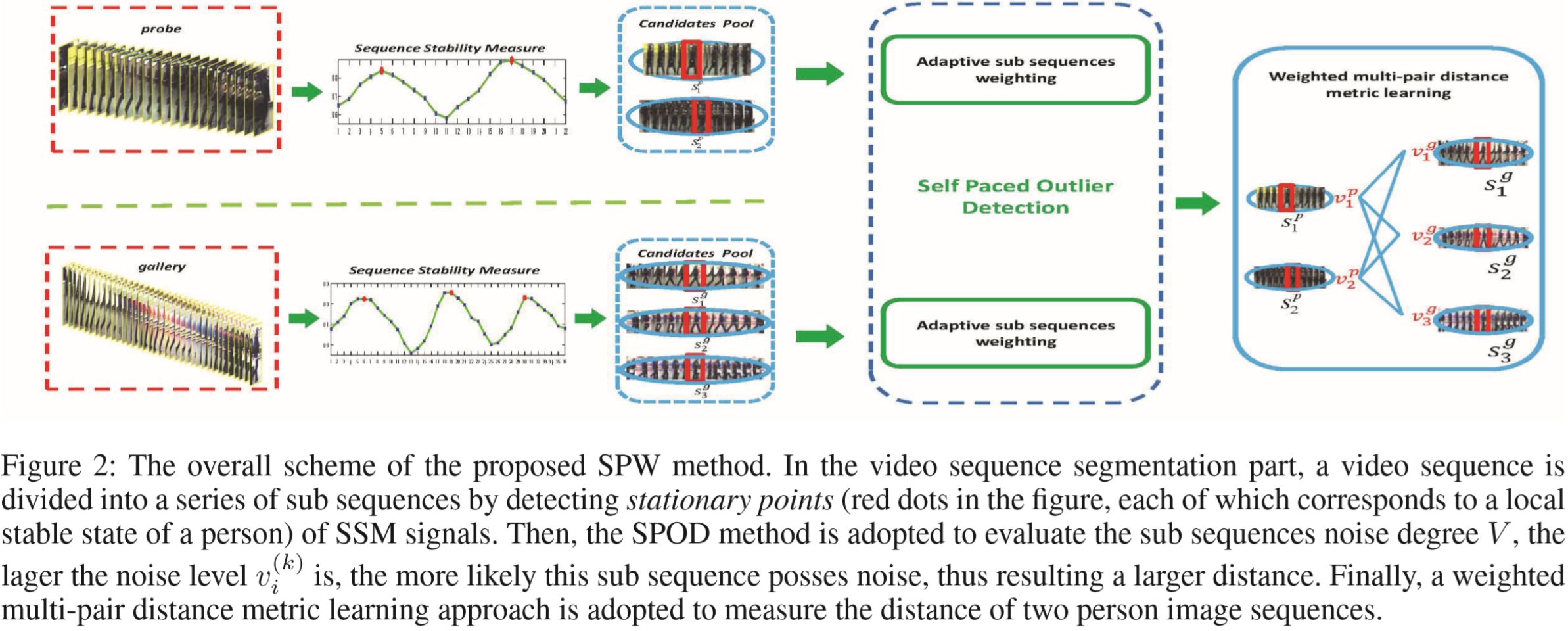
(2)视频序列分割:

不同于采用光流信息的方法,作者将视频按照遮挡信息进行分割,如上图所示。
作者采用了 Ayvaci, Raptis, and Soatto 2010 在 Occlusion detection and motion estimation with convex optimization 提出的遮挡信息【待阅读】,如下图所示。定义 oi 为 相邻两帧 Ii 和 Ii-1 之间的遮挡信息,定义![]() 为稳定性衡量,表示帧的变化差异。
为稳定性衡量,表示帧的变化差异。

定义一个视频序列![]() ,则计算帧的稳定性为:
,则计算帧的稳定性为:
![]()
序列的稳定性衡量为:![]() ,并用高斯平滑来降低噪声。最后按照局部最大值进行分割,得到子序列集合
,并用高斯平滑来降低噪声。最后按照局部最大值进行分割,得到子序列集合![]() ,每个子序列为局部最大值点 {t} 周围 L 长度范围内,即
,每个子序列为局部最大值点 {t} 周围 L 长度范围内,即 ![]() ,L 为局部最大值和局部最小值的距离。
,L 为局部最大值和局部最小值的距离。
(3)自步异常检测:
① 问题描述:
假设查询视频序列为 p,对应视频库含有 n 个视频,则将每个视频划分为一系列子序列,即 ![]()
![]() ,K = n + 1,mi 表示每个视频序列包含的子序列的数量,且
,K = n + 1,mi 表示每个视频序列包含的子序列的数量,且![]() 。定义权重向量
。定义权重向量![]() ,每个元素为
,每个元素为![]() 。
。
设定 ![]() ,(Y到底是什么?怎么理解?ranking score是什么?)。对每个子序列都预估一个 ranking score,同一个视频的子序列都含有相同的 ranking score,定义为
,(Y到底是什么?怎么理解?ranking score是什么?)。对每个子序列都预估一个 ranking score,同一个视频的子序列都含有相同的 ranking score,定义为![]()
![]() ,则 ranking 损失为:
,则 ranking 损失为:
![]()
其中 ![]() ,
,![]() 。
。
我的理解:当两个序列距离很近时,w 值很大,这时候希望两者的 ranking score 很相近,以至于这项趋近于0。
优化函数参照 Jiang et al. 2014 在 Self-paced learning with diversity 所提【待阅读】,为:
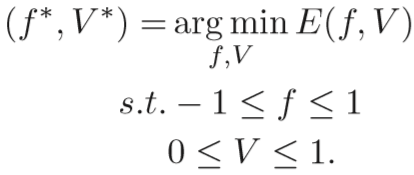
优化目标为:![]()
其中![]() 为子序列的噪声等级,ranking 损失集合
为子序列的噪声等级,ranking 损失集合 ![]() ,阈值 β。
,阈值 β。
依据阈值进行判断,若小于阈值β,则损失为0(我的理解是允许适度的误差)。越小甚至为0的 l 损失,会使得 1 - v 越大,即 v 越小; 越大的 l 损失会使得 v 越大,即噪声越大。

跟以往加上一个正规化项不一样,这里减去了一个正规化项,主要是为了提高 v 分散的多样性,我的理解是尽可能让 v 的非零项分散到不同序列中。
② 优化方法:
step1:固定 V,优化 f,即目标函数变为:
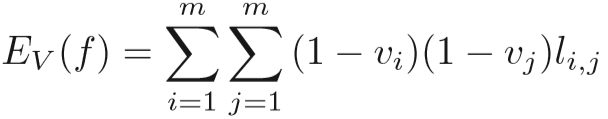
可以用常规的凸优化方法解决;
step2:固定 f,优化 V,即目标函数变为:

可以用CCCP算法进行解决【待阅读】。
(3)多视频对加权距离度量:
query集:![]()
gallery集:![]()
距离度量:

其中:![]()
当两者的噪声很大,那么 z 就会趋近于1,距离值就会增大,否则,z 趋近于 1/2,相对而言距离值减小。
Experiments



 浙公网安备 33010602011771号
浙公网安备 33010602011771号