论文阅读笔记(二十三)【ECCV2018】:Robust Anchor Embedding for Unsupervised Video Person Re-Identification in the Wild
Introduction
当前主要的非监督方法都采用相同的训练数据集,这些数据集在不同摄像头中是对称的,即不存在单个行人的错误项,这些方法将在实际场景中效果下降。在本方法中,作者引入了非对称数据,如下图所示,提出了一个在真实环境下的非监督深度神经网络。

提出一个标签估计方法:a novel Robust Anchor Embeding (RACE) framework。
Proposed Method
(1)概述:

通俗来说,先固定几个序列,给这几个序列加上标签作为anchor,然后输入一个未标签序列,找出距离最近的若干个anchor,用这些anchor加权表示出这个未标签序列,这样既得到了相似距离又得到了权重,我们希望距离越近越好,权重越大越好,综上计算出最佳的anchor,作为预测的标签,循环这个过程得到所有的标签。
(2)Anchor初始化:
【注】anchor表示不同行人的身份,但在假设下并不严谨,两个anchor也可能属于同一个人。
随机抽选 m 个anchor序列 ![]() 传入预训练的ImageNet模型,分别表示不同的行人,即:
传入预训练的ImageNet模型,分别表示不同的行人,即:![]() ,其中
,其中 ![]() 表示帧级特征向量的集合,l 表示对应的初始化标签。
表示帧级特征向量的集合,l 表示对应的初始化标签。
在本文中,采用classification loss(Person re-identification: Past, present and future. 提出)来作为训练的基础结构。【待阅读】
(3)标签估计:
① 鲁棒的Anchor嵌入方法:
定义未标签的视频序列为:![]()
![]() 。初始的帧级特征向量集合采用平均池化或者最大池化转化为单向量特征。考虑到一些帧存在跟踪偏差,即产生了离群帧(outlier frame),作者采用了regularized affine hull(RAH,From point to set: Extend the learning of distance metrics提出)【待阅读】,理解为对帧进行加权,得到 d 维的特征向量,即:
。初始的帧级特征向量集合采用平均池化或者最大池化转化为单向量特征。考虑到一些帧存在跟踪偏差,即产生了离群帧(outlier frame),作者采用了regularized affine hull(RAH,From point to set: Extend the learning of distance metrics提出)【待阅读】,理解为对帧进行加权,得到 d 维的特征向量,即:
![]()
对于标签估计,首先学习embedding向量(姑且叫做嵌入向量)wi, 用于衡量未标签的特征序列![]() 和anchor集合
和anchor集合![]() 间的关系。学习到第 i 个未标签序列的最近的 k 个anchors,即
间的关系。学习到第 i 个未标签序列的最近的 k 个anchors,即![]() ,k 远远小于 m,用这 k 个anchors来联合表示该未标签序列,即定义如下系数学习问题(Robust AnChor Embeding问题,RACE):
,k 远远小于 m,用这 k 个anchors来联合表示该未标签序列,即定义如下系数学习问题(Robust AnChor Embeding问题,RACE):

该公式的第一项为embedding term,旨在限制未标签项与anchors之间的差异;
第二项为smoothing term,旨在权重越大的anchor距离越近,其中 d<i> 为相似度,理解为到各个anchor的距离,⊙ 为对应元素相乘,该项计算为:
![]()
RACE问题将高维的CNN表征转为低维的权重映射,来降低算力损耗。
该问题为标准二次规划问题,优化方法:
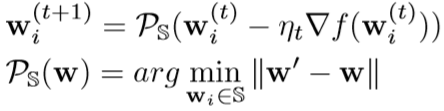
具体求解见:
Efficient projections onto the l 1-ball for learning in high dimensions
Large graph construction for scalable semi-supervised learning
From point to set: Extend the learning of distance metrics
【待阅读】
(4)top-k count 标签估计:
如果两个视频序列属于同一个行人,那么它们在不同的衡量维度上需要非常接近。具体来说,如果未标签序列 xi 属于行人![]() ,需要满足两个条件:
,需要满足两个条件:
① ![]() 应当是距离 xi 最近的部分anchor之一,定义为:
应当是距离 xi 最近的部分anchor之一,定义为:![]() ;
;
② ![]() 应当足够大。
应当足够大。
定义预测的标签为:
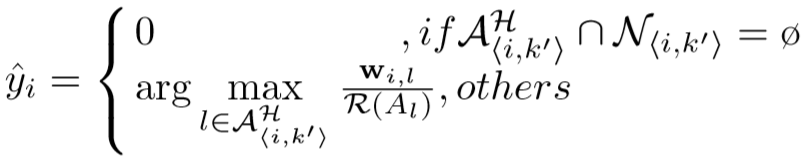
其中![]() 表示
表示![]() 在
在![]() 中的排名。
中的排名。
【疑问:![]() 已经是最近的 k 个最近的anchor了,为什么还要判断是不是最近的 k' 个?】
已经是最近的 k 个最近的anchor了,为什么还要判断是不是最近的 k' 个?】
Experimental Results
(1)实验设置:
① 数据集:PRID-2011,iLIDS-VID,MARS;
② 参数设置:dropou = 0.5;图片resize = 128*256;learning rate(MARS)= 0.003,learning rate(PRID-2011, iLIDS-VID) = 0.01,并每20个epoch下降0.1;k = 15,k’ = 1;λ = 0.1。
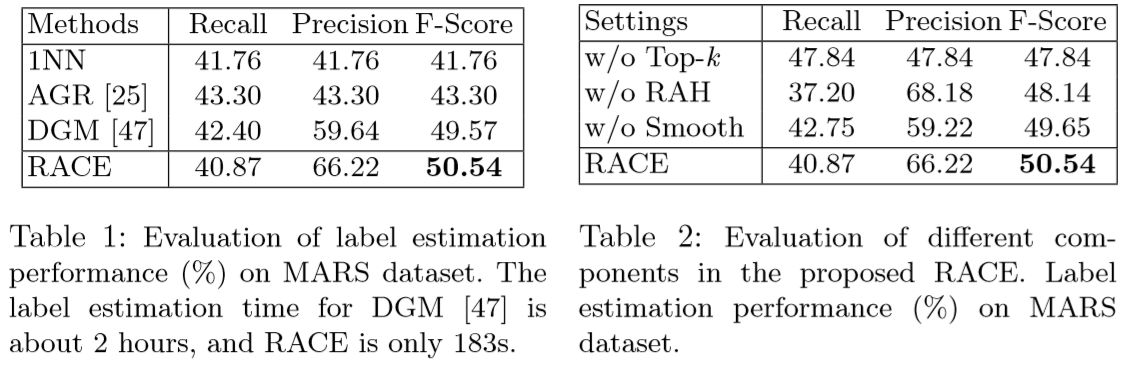
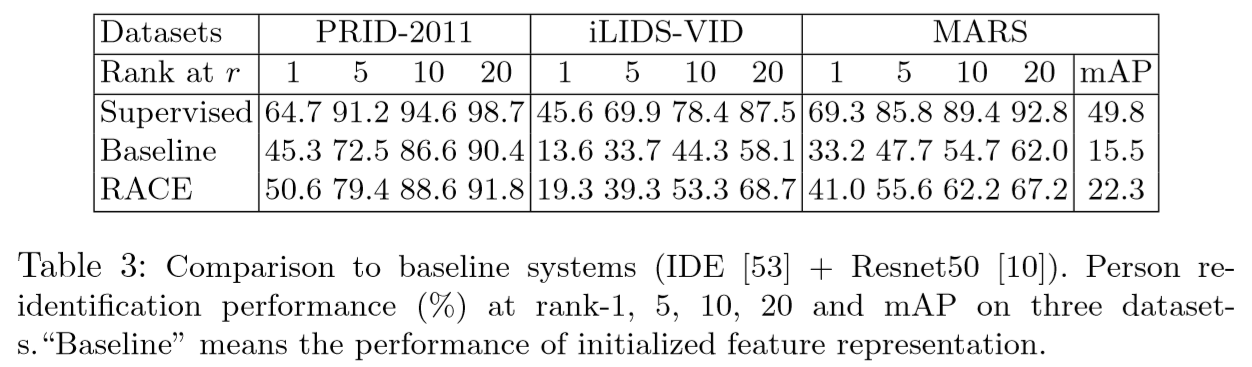
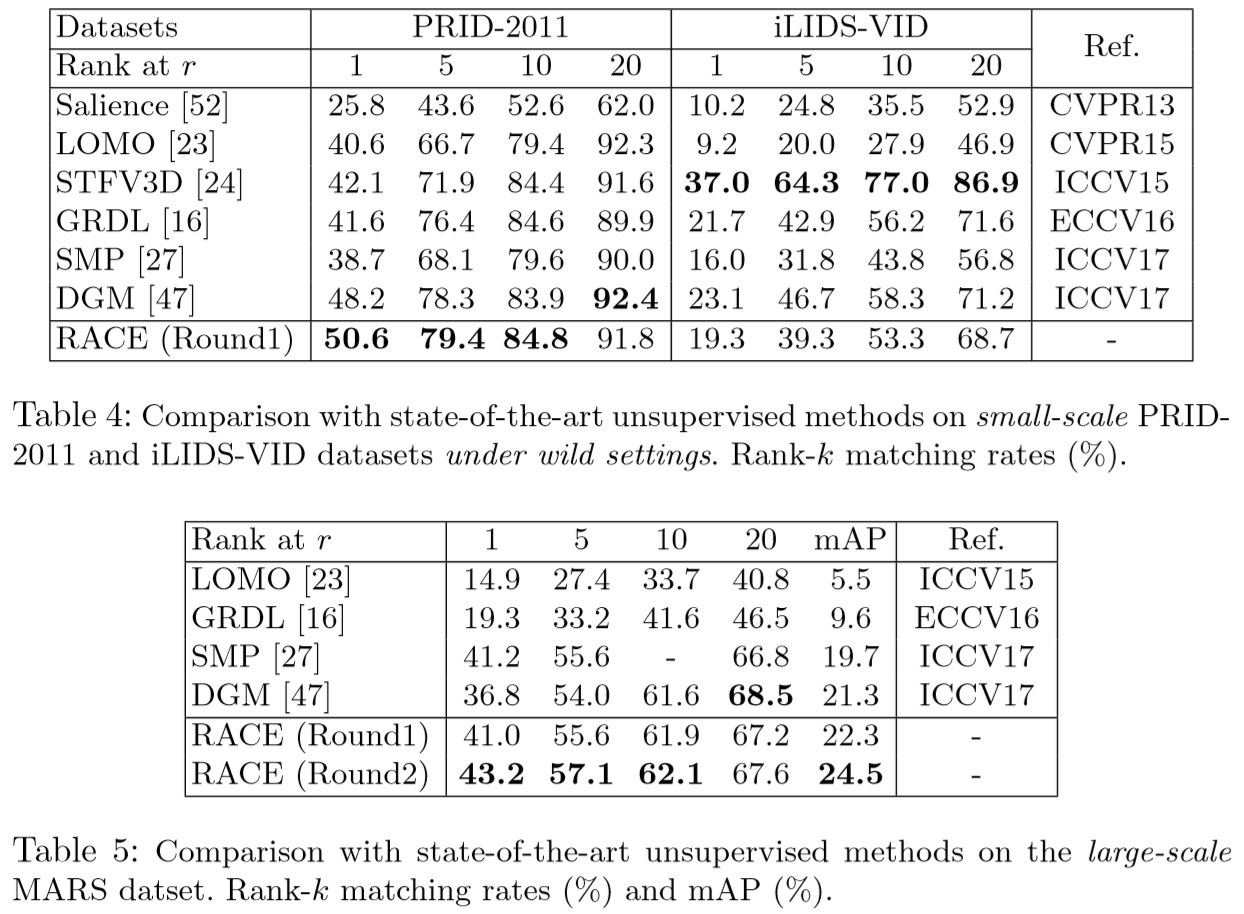
(2)实验结果: