论文阅读笔记(十二)【CVPR2018】:Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning
Introduction
(1)Motivation:
大量标记数据成本过高,采用半监督的方式只标注一部分的行人,且采用单样本学习,每个行人只标注一个数据。
(2)Method:
对没有标记的数据生成一个伪标签(pseudo labels),将标记的数据和部分伪标签的数据作为扩充数据集进行训练。
但这种方法引入了很多不可信的训练样本,制约了训练模型的性能。
(3)Contribution:
① 为了在单样本学习中更好的利用未标签数据,提出了步进学习方法EUG(Exploit the Unknown Gradually)。介绍如下:
通过单样本数据集训练CNN模型;
EUG迭代更新CNN模型,分为两步:
标签估计:对未标记数据生成伪标签,根据预测的可信度选择伪标签数据训练,
模型更新:使用扩充数据集对CNN重新训练。
② 采用基于距离的抽样准则进行标签估计和样本选择,显著提高了标签估计的性能。

The Progressive Model
(1)预备工作:
符号定义:
标记数据:L = {(x1, y1), ..., (xnl, ynl)}, |L| = nl
未标记数据:U = {(xnl+1), ..., (xnl+nu)}, |U| = nu
训练标记数据集的目标函数:
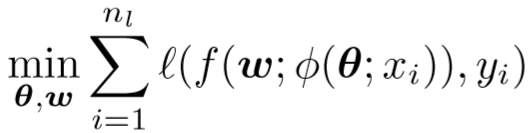
其中, Φ 表示一个嵌入函数,含有参数 θ,表示提取数据 xi 的特征(可视为CNN);
f 是一个含有参数 w 的函数,用于将 Φ 函数提取出的特征分类为 k 维的置信度估计(k表示行人的数量);
l 表示损失函数。
将未标记的数据考虑在内,单样本学习目标函数转为:
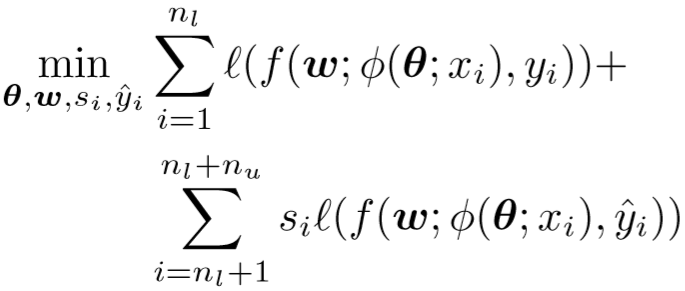
其中,yi^ 表示生成伪标签的第 i 个未标记数据;
si 属于 {0, 1},用于选择放进训练的未标记数据。
(2)框架:
提出一个步进学习方法来解决优化问题,即先优化 θ 和 w,再优化 y^ 和 s。
定义 S 为选择的伪标签的集合:![]()
特征提取函数 Φ 采用一个带有时间平均池化的CNN模型ETAP-Net,该网络基于ResNet-50的架构,在分类层之前添加了全连接层和时间平均池化层。通过时间平均池化,每个tracklet包含的多个帧级特征转为tracklet级特征。在标签估计阶段,每个未标记的视频tracklet都会计算与已标记tracklet的距离,并将最近的数据进行伪标记。

(3)渐进式高效抽样策略:
① 抽样策略:如何保证抽选的伪标签样本的可靠性?
作者提出了一个动态的抽样策略,逐渐增加选择的伪标签样本数量。
② 抽样标准:对于单样本训练的行人重识别问题,什么才是一个高效的抽样标准?
作者提出了一个高效的抽样标准,采用了特征空间的距离度量(最近邻)来衡量可靠性。
具体策略如下:
对于每一个未标记数据,定义不相似度代价函数,其中 xi 属于 U:
![]()
设置第 t 次迭代的伪标签索引:
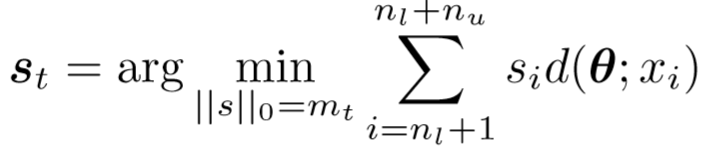
其中 mt 表示选择的伪标签集合的大小,迭代定义为:mt = mt-1 + p*nu,p为增量因子,属于(0, 1),控制伪标签集合的增长速度。
如何确定增量因子 p ?将 p 设置为一个很小的数值,使得 mt 在迭代中逐渐增大。
算法流程:

Experiments
(1)实验设置:
① 数据集:MARS和DukeMTMC
② 参数设置:momentum = 0.5,weight decay = 0.0005, batch size = 16, epochs = 70,lr = 0.1(前55个epochs),lr = 0.01(后15个epochs)
③ 数据处理:采用ImageNet进行预训练;每个tracklet选取16帧作为输入。
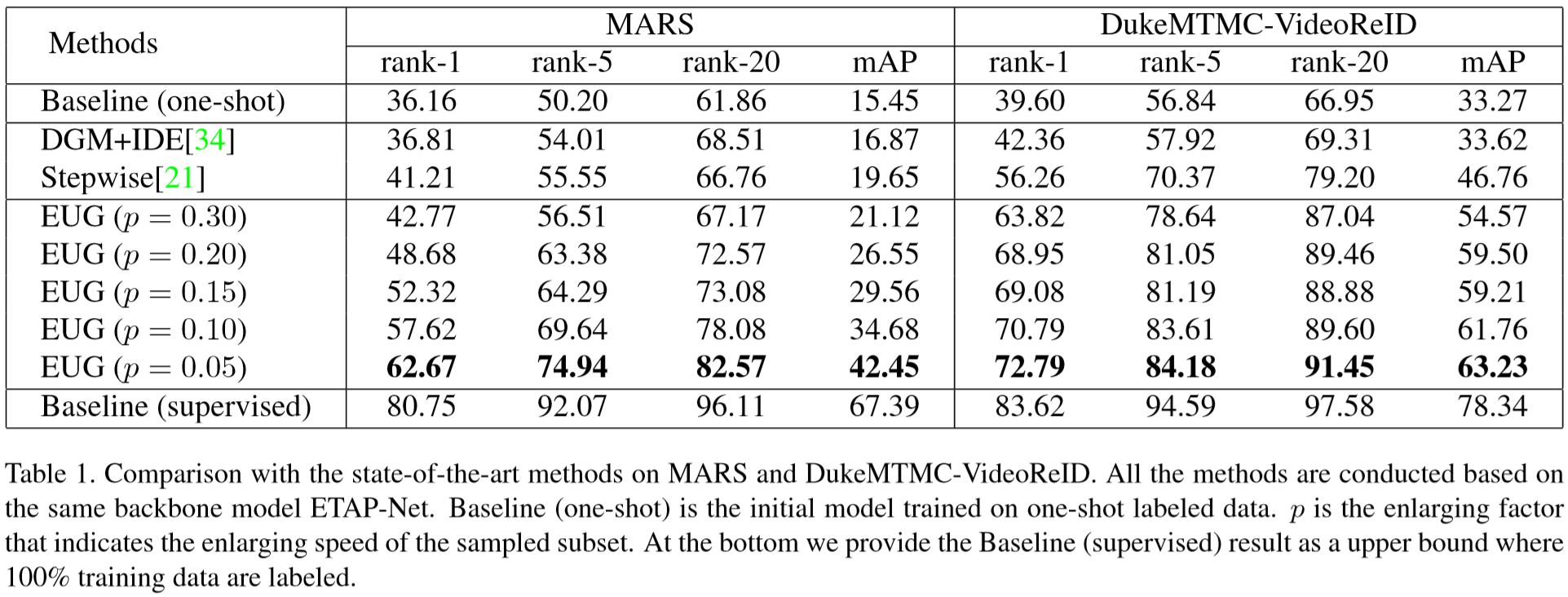
(2)实验结果:

其他读者的阅读笔记【传送门】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号