
论文阅读笔记(十)【CVPR2016】:Recurrent Convolutional Network for Video-based Person Re-Identification
Introduction
该文章首次采用深度学习方法来解决基于视频的行人重识别,创新点:提出了一个新的循环神经网络架构(recurrent DNN architecture),通过使用Siamese网络(孪生神经网络),并结合了递归与外貌数据的时间池,来学习每个行人视频序列的特征表示。
Method
(1)特征提取架构:
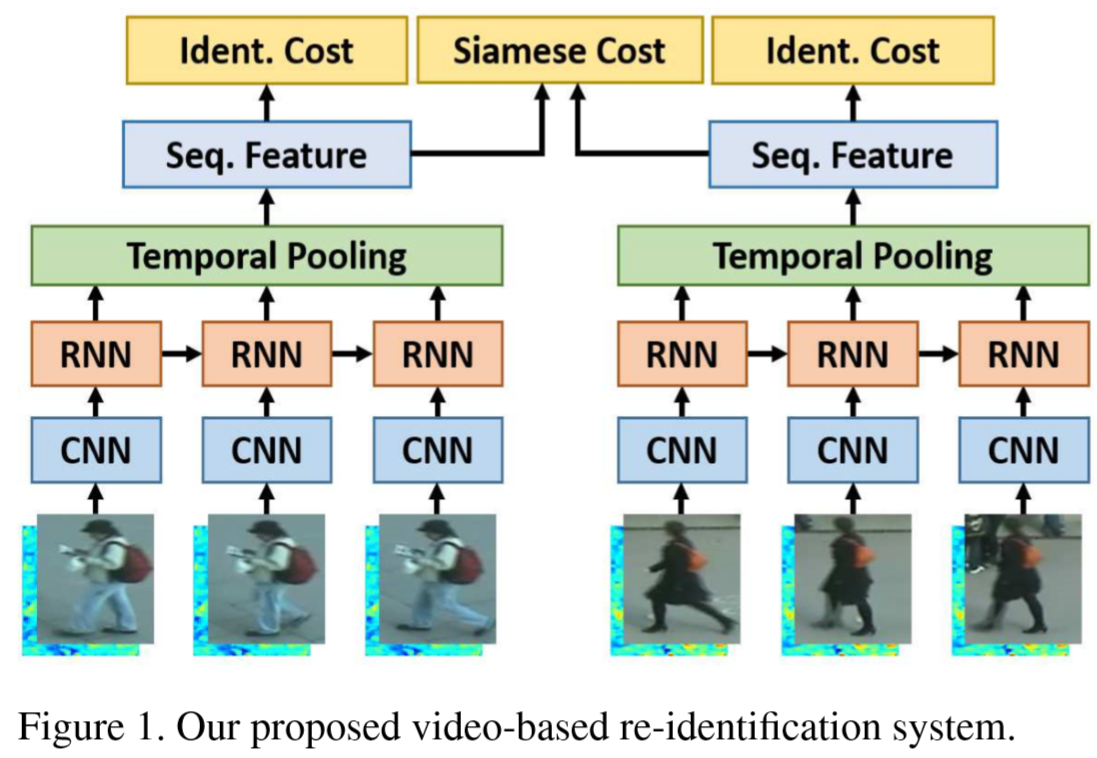
第一层:卷积神经网络,提取每个行人的外貌特征向量;
第二层:循环神经网络,让网络更好的提取时空信息;
第三层:时间池,让网络将不同长度的视频序列总结为一个特征向量.
Siamese网络:通过训练,将来自同一个人的视频特征变得更近,将来自不同人的视频特征变的更远.
(2)输入:
包括两部分:光流(optical flow)、颜色通道(colour channel)
光流对行人的步态等动作线索进行编码,而颜色通道对行人的样貌和穿着进行编码.
(3)卷积神经网络:
对每一个步行时刻(time-step,可以理解为组成步态周期的一个单元)进行卷积神经网络处理,把输入的图片记为 x,则输出为向量 f = C(x).
卷积神经网络架构:
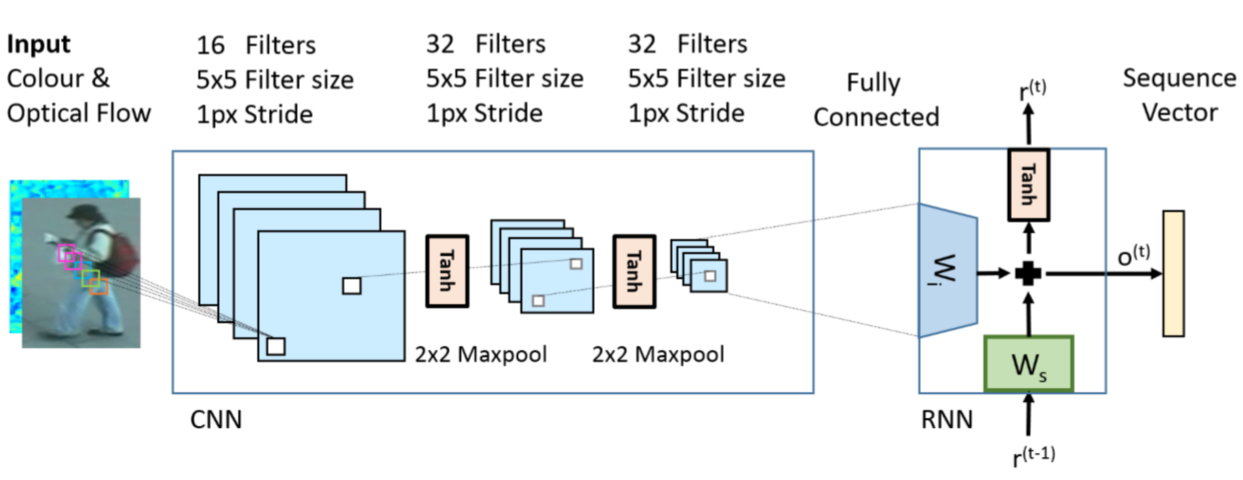
激活函数采用tanh,池化层采用最大maxpool,即:
![]()
s = s(1), ..., s(T) 表示为一个视频序列,T 为视频序列的长度,s(t) 为在时间 t 时的图片帧.
每个图片都要经过CNN来产生一个特征向量,即 f(t) = C(s(t)),其中 f(t) 是CNN最后层的向量表示.
(4)递归神经网络:基础介绍【传送门】
f(t) 表示 s(t) 在CNN最后层的向量表示,则RNN输出为:
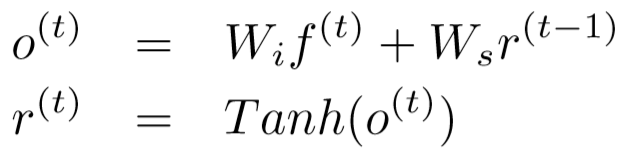
o(t) 规格:e * 1
f(t) 规格:N * 1
r(t-1) 规格:e * 1
Wi 规格:e * N
Ws 规格:e * e
f(t) 包含当前时刻的图像信息,r(t-1) 包含上一时刻的图像信息,对所有时刻的特征使用全连接层. r(t) 初始为零向量.
(5)时间池:
虽然RNNs可以捕获时间信息,但依然存在不足:
① RNN的输出偏向于较后的时刻;
② 时间序列分析通常需要在不同的时间尺度下提取信息(如语音识别中,提取的尺度包括:音节、单词、短语、句子、对话等).
解决方法:增加一个时间池化层(temporal pooling layer),该层从所有时刻收集信息,避免了偏向后面时刻的问题.
在时间池化层中,所有时刻RNN后的输出为{o(1), ..., o(T)},提出两个方法:
① 平均池化层:
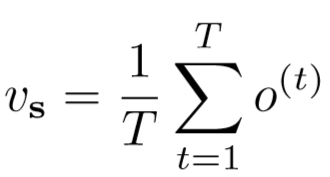
② 最大池化层:(即向量的每一个元素都是从 T 个时刻中的对应位置挑选出的最大值)
![]()
(6)训练策略:
① 孪生神经网络:基础知识【传送门】
给出一对视频序列 (si, sj),每个序列都通过CNN、RNN提取出特征向量,即 vi = R(si),vj = R(sj),孪生神经网络的训练目标为:(采用的距离为欧式距离)

② 识别验证:
预测特征向量 v 是第 q 个身份的概率为:
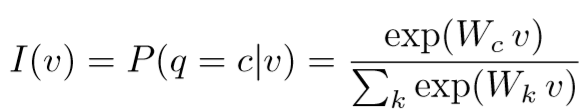
一共有 K 个可能身份,Wc 和 Wk 表示权重矩阵 W 的第 c 和 k 列.
③ 损失函数:
![]()
Experiments
(1)实验设置:
① 数据集 :iLIDS-VID、PRID-2011,一半用于训练,一半用于测试,运行10次计入平均值.
② 参数设置:孪生神经网络中 m = 2,特征空间维度 e = 128,梯度下降学习率 α = 1e-3,batchsize = 1,epochs = 300.
③ 硬件条件:GTX-980 GPU(运行1天)
④ 数据预处理:采用了裁剪和镜像的形式对数据进行增强. 将图像转为YUV色域,每个颜色通道被标准化为零均值和单位方差,使用Lucas-Kanade算法【传送门】计算每对帧之间的水平和垂直光流通道. 光流通道正规化为[-1,1]. 第一层神经网络的输入有5层通道,其中3层为颜色通道,2层为光流通道.
(2)实验结果:
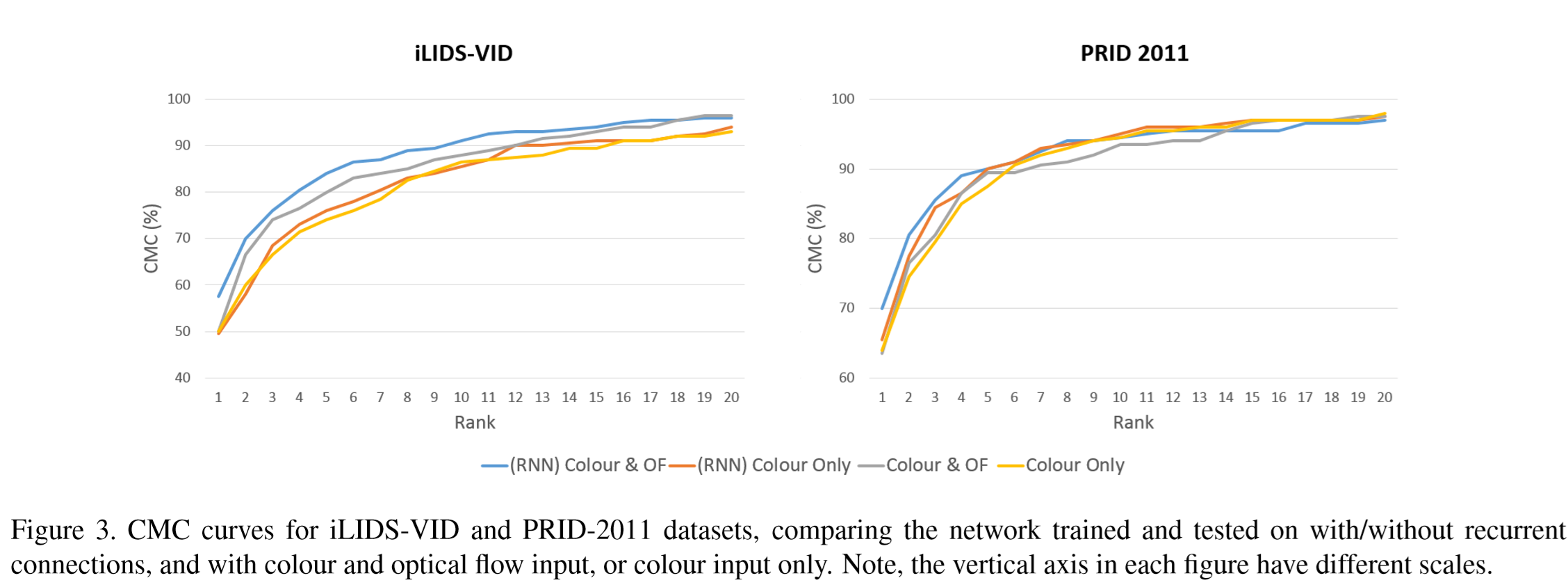
① 比较了有无循环连接、有无光流特征情况下的实验结果.
② 比较时间池中使用平均池化、最大池化和基准方法(其它参考文献中的方法)的效果.

③ 比较不同视频序列长度的效果.

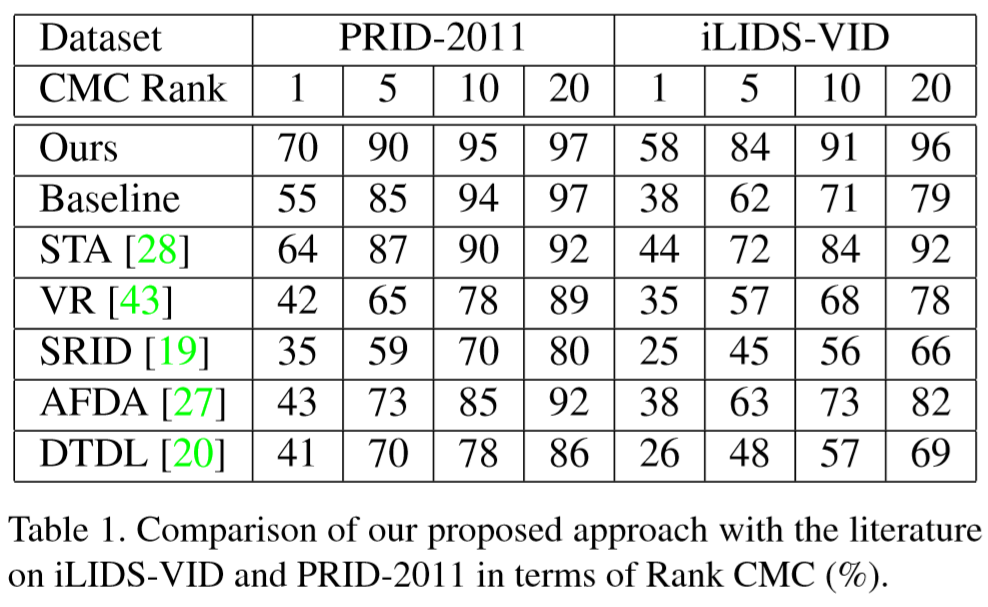
④ 与其它方法的对比.
⑤ 跨数据集测试,在数据集A训练,但在数据集B测试.


