论文阅读笔记(九)【TIFS2020】:True-Color and Grayscale Video Person Re-Identification
Introduction
(1)Motivation:
在现实场景中,摄像头会因为故障呈现灰白色,或者为了节省视频的存储空间而人工设置为灰白色。灰度图像(grayscale images)由8位存储,而彩色图像由24位存储。在节省存储空间的同时,也带来了信息丢失的问题,增加了行人重识别的难度。

通过对同一张照片的彩色版和灰度版进行余弦相似度(cosine similarity)计算,发现两者相似度在0.8左右,即灰度图像损失了约20%的有效信息。
定义本文彩色-灰度视频间行人重识别的问题:Color to Gray Video Person Re-identification (CGVPR).
(2)Contribution:
① 提供了一个新的基准数据集,命名为 true-color and grayscale video person re-identification dataset (CGVID);
② 提出了解决 CGVPR 的方法,命名为 semi-coupled dictionary pair learning (SDPL).
Dataset Description

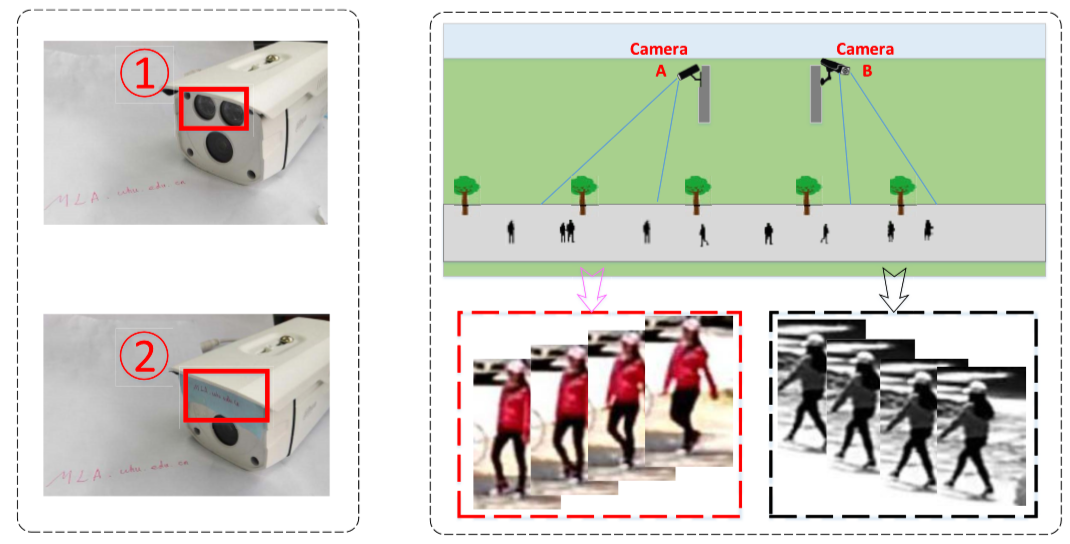
Our Approach
(1)视频重构错误项(video reconstruction error term):
彩色视频特征集合:A = [A1, A2, ..., AN]
灰度视频特征集合:B = [B1, B2, ..., BN]
其中 Ai = [ai1, ai2, ..., aini] 表示第 i 个视频的特征集合,aij 表示第 i 个视频的第 j 个步行周期的特征,每个特征维度为 d.
定义:彩色、灰度字典矩阵 DC 和 DG,A 和 B 通过字典矩阵的编码后的矩阵为 X 和 Y,视频内投影矩阵为 W 和 V.
视频重构错误项定义(目的是提高保真度):
![]()
异构视频投影项定义(目的是提高同一视频间的收敛):

其中 μi 定义为第 i 个行人视频的特征集合的中心.
(2)半耦合映射项(semi-coupled mapping term):
目的是为了使得编码后的两个矩阵更接近,通过学习映射矩阵 P 来弥补灰度图像的信息损失. 该项定义为:
![]()
(3)距离区分度项(discriminative fidelity term):
目的是为了缩小相同行人视频间距离,增大不同行人视频间距离. 该项定义为:
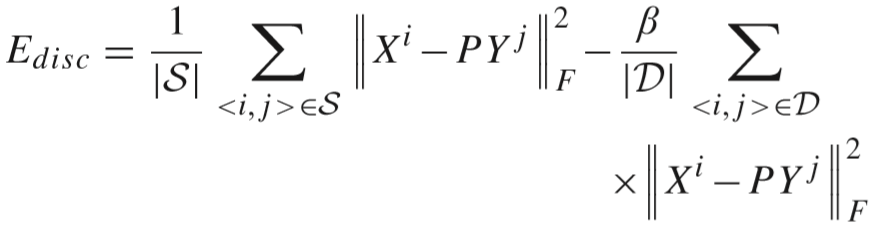
(4)目标函数:
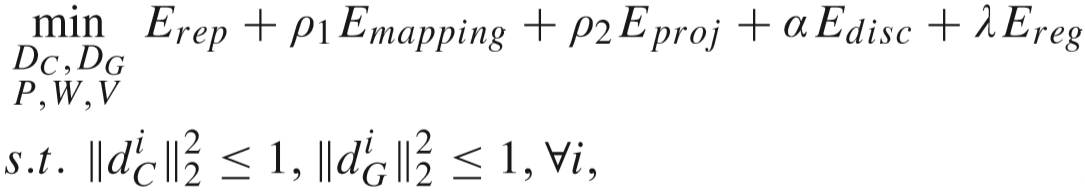
其中 α 和 λ 是平衡因子,ρ1 和 ρ2 分别控制了视频间投影矩阵和视频内映射的效果,一般设置为 1 / N.
Ereg为正则化项目,等于:![]() .
.
模型的思路:

The Optimization of SDPL
(1)更新 W 和 V:
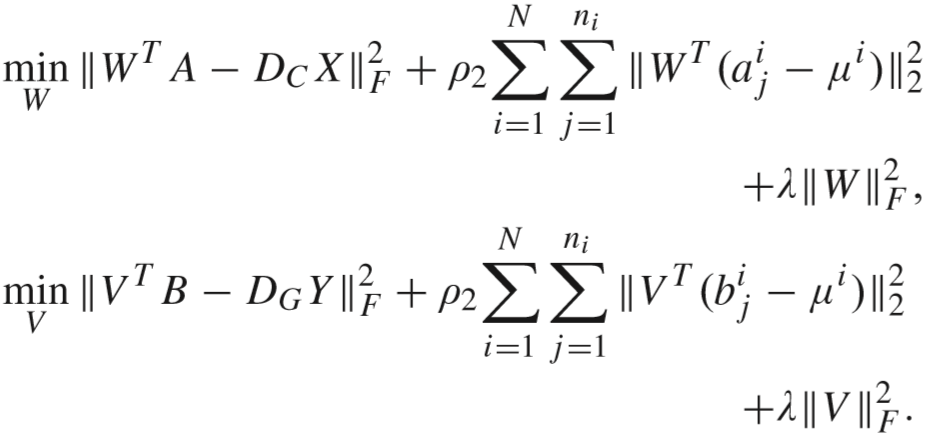
通过求导得到解:
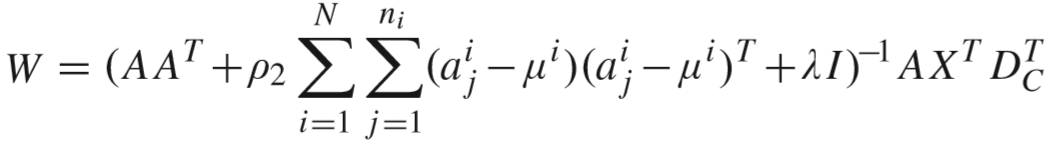
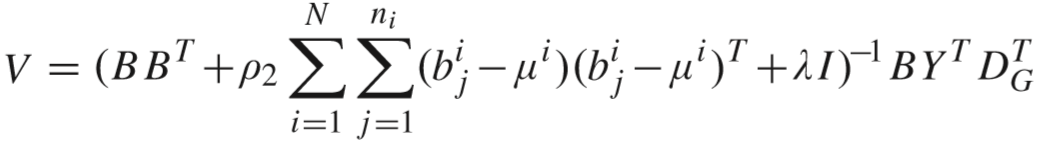
推导过程:中间跳过了计算步骤,详见论文笔记3【传送门】. V 的计算类似,略.
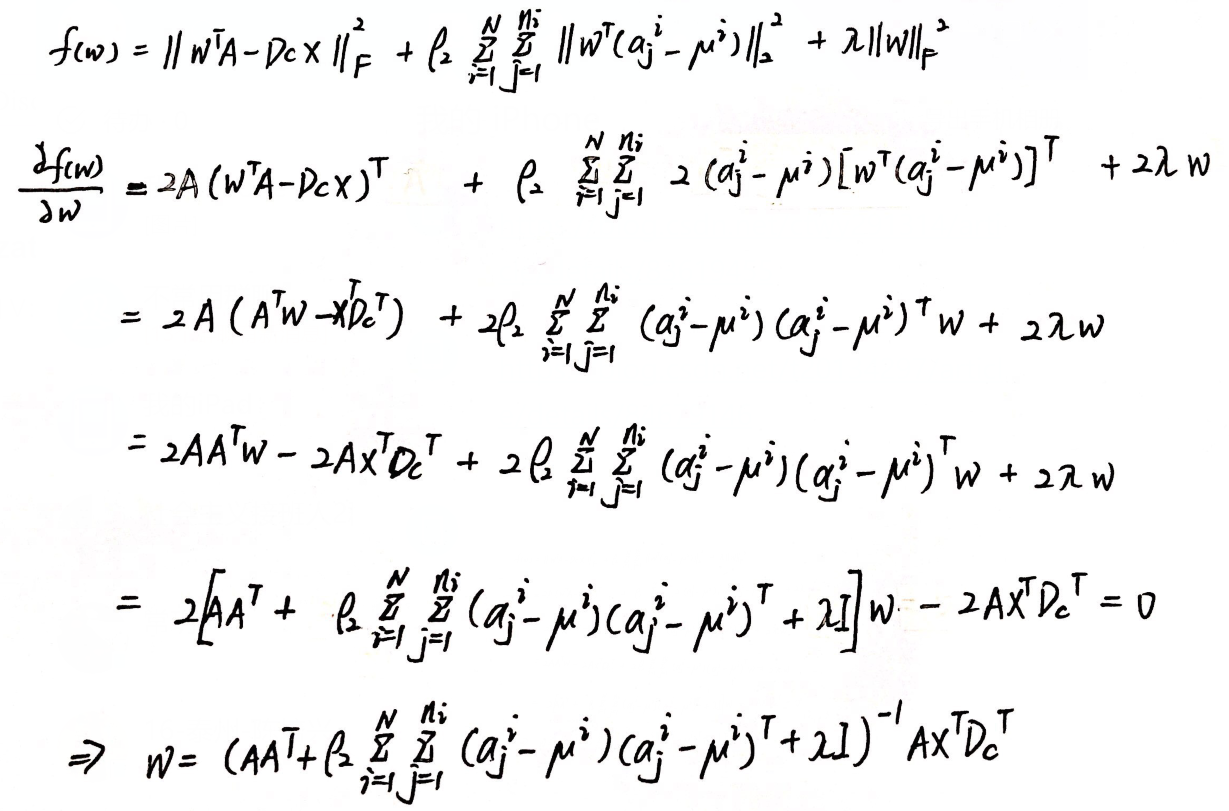
(2)更新 X 和 Y:

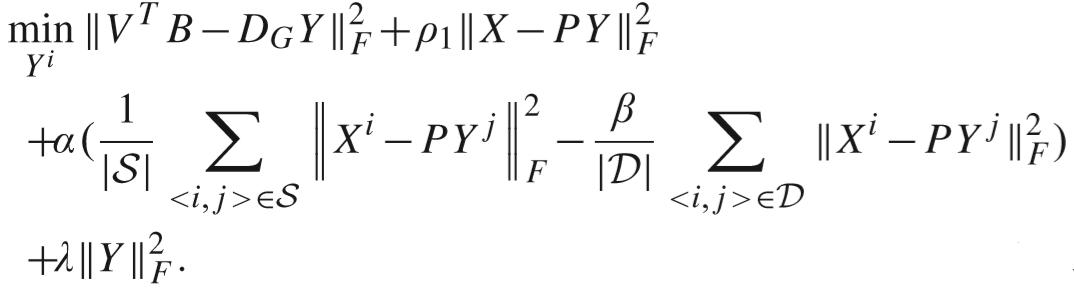
通过求导得到解:
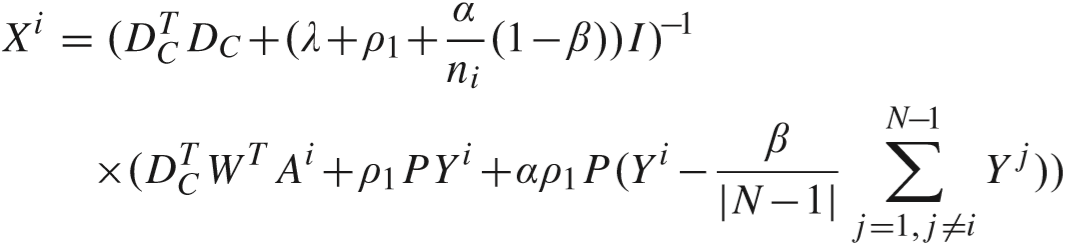
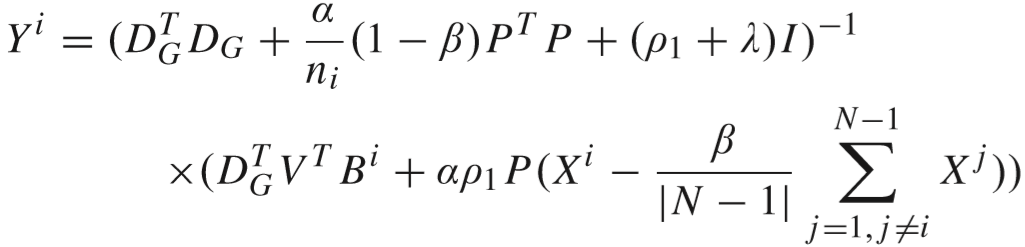
推导过程:得到的解有细微差别(Y 的求解同理,略). 这里 |S| = 1.
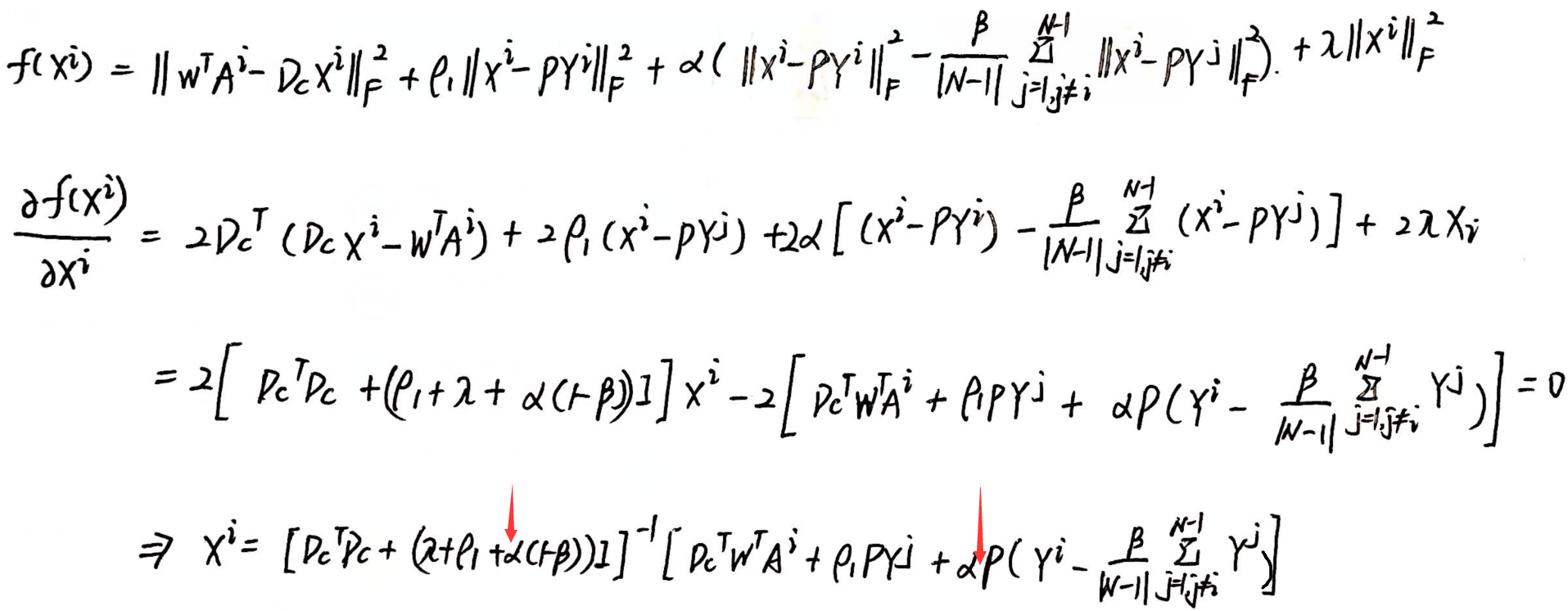
(3)更新 DC 和 DG:
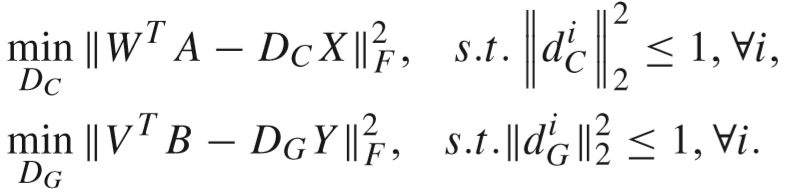
使用ADMM算法进行求解.
(4)更新 P:
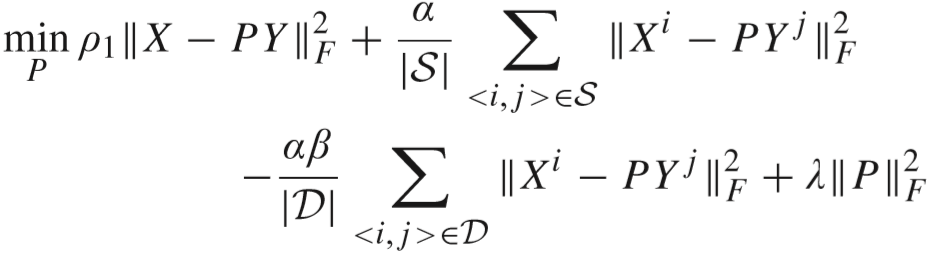
通过求导得出解:
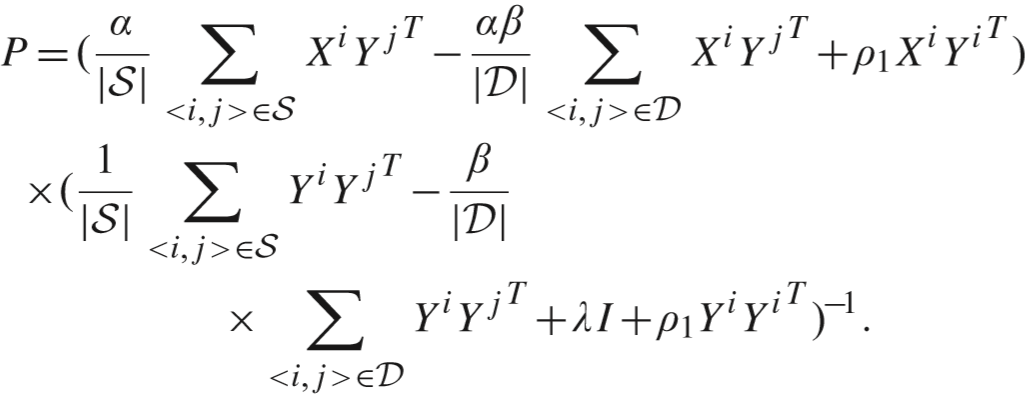
推导过程:得到的解有细微差别.
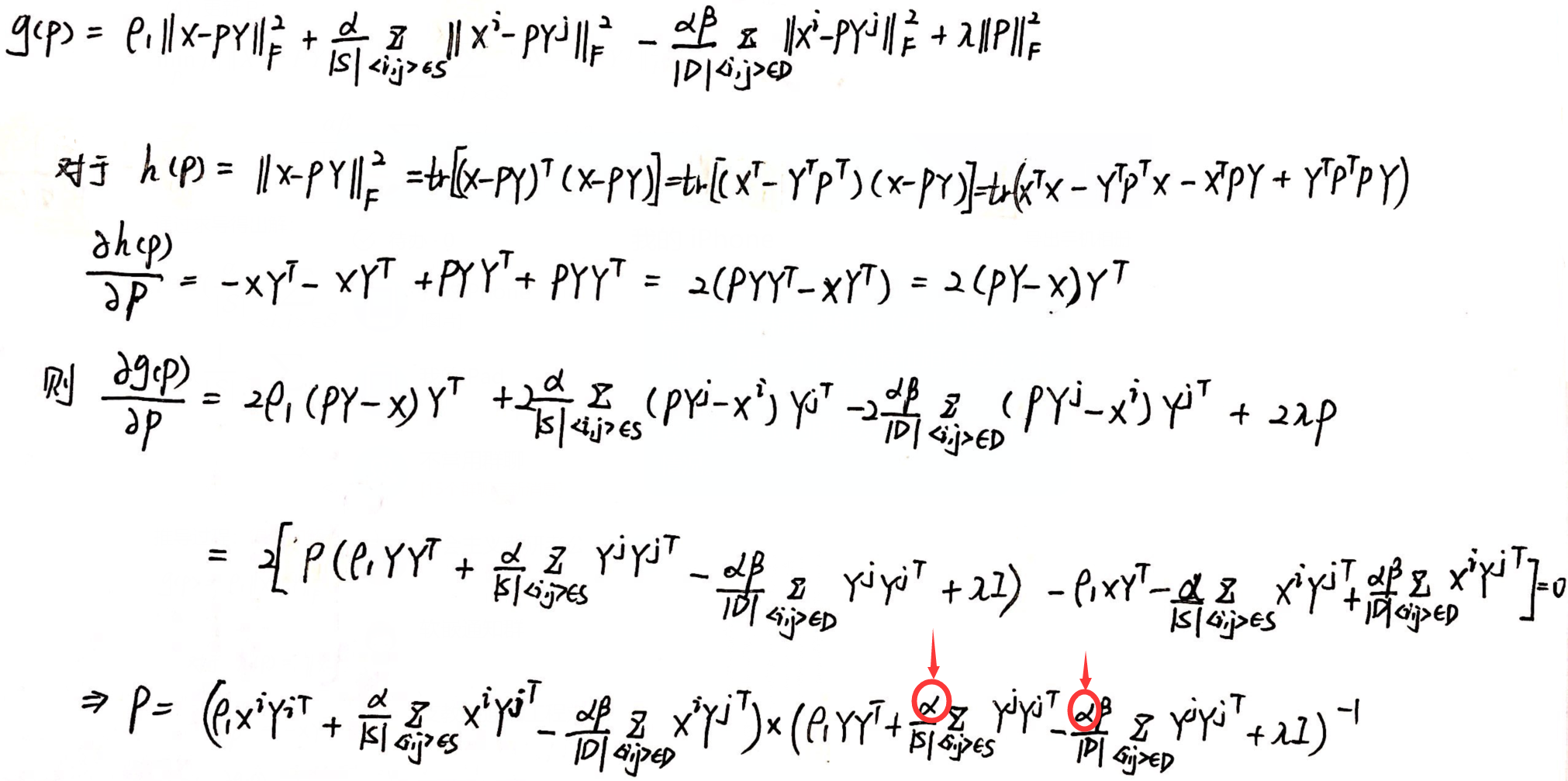
(5)优化算法:

(6)视频匹配:
① 对灰度视频特征 F 进行编码(设置 Y = 0):
![]()
② 对彩色视频特征 C 进行编码(设置 X = 0):
![]()
③ 计算两者距离,并挑选出距离最近的匹配视频.
④ 算法流程:

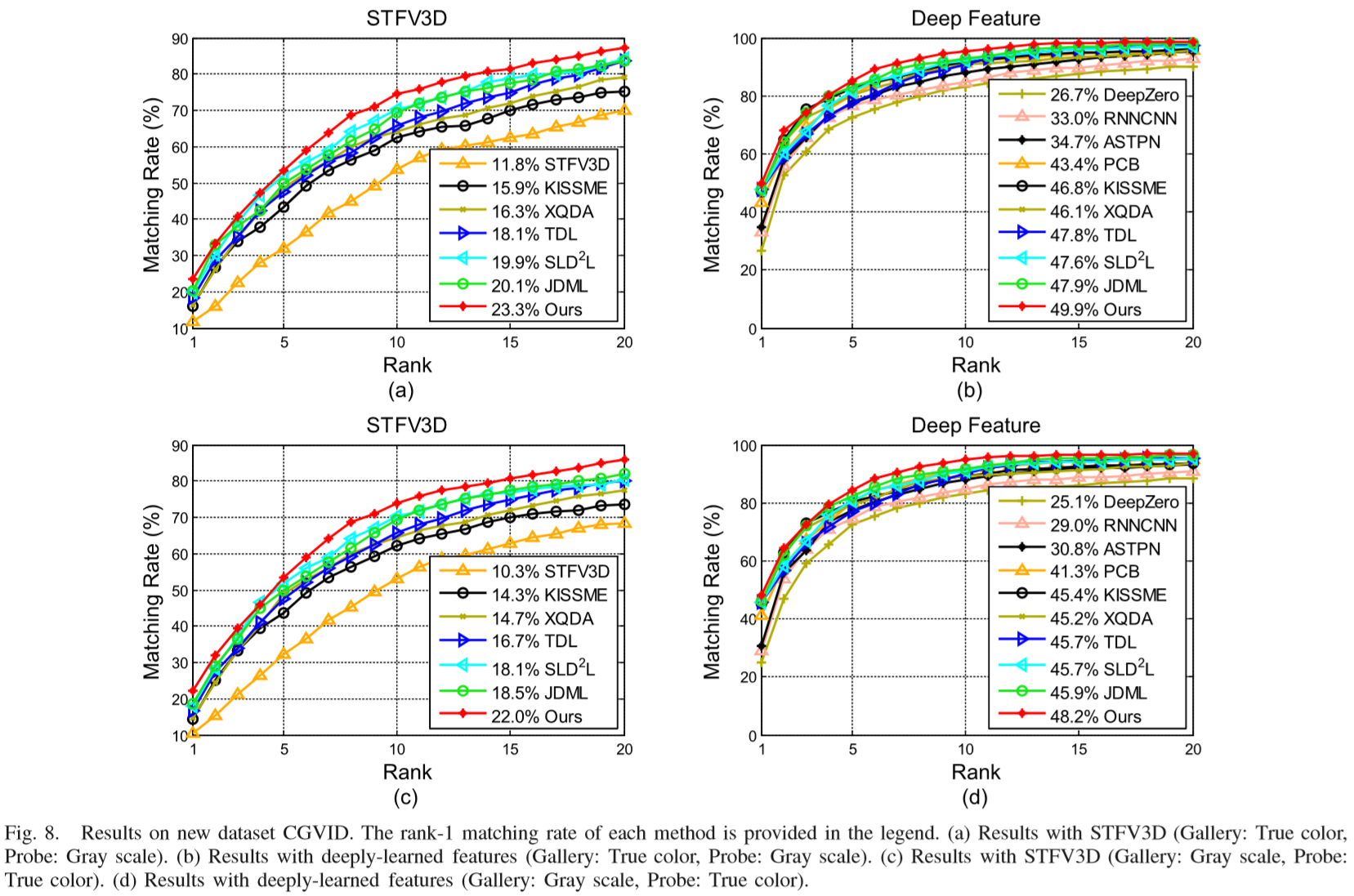
Experiments
(1)实验设置:
① 特征提取:STFV3D、深度学习特征PCB.
② 参数设置:α = 0.04,β = 0.06,λ = 0.2, ρ1 = ρ2 = 1 / N. 5-fold cross validation.
③ 对比方法:
字典学习方法:STFV3D,TDL,KISSME,XQDA,SI2DL,JDML;
深度学习方法:RNNCNN,ASTPN,DeepZero,PCB.
(2)实验结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号