论文阅读笔记(八)【IEEEAccess2019】:High-Resolution and Low-Resolution Video Person Re-Identification: A Benchmark
Introduction
(1)Motivation:
监控视频中的行人,有的比较清晰,有的因为距离较远非常模糊. 在高低分辨率方面的行人重识别缺乏数据集和研究.
(2)Contribution:
① 提供了一个关于高低分辨率问题(person re-identification between low-resolution and high-resolution,PRLHV)的新数据集,即 HLVID.
② 提出了集合间半耦合映射距离矩阵学习方法(semi-coupled mapping based set-to-set distance learning approach,SMDL).
HLVID DataSet
记录人数:200人,50656张image,平均长度为126帧.
相机:2个,Camera A:1920*1080,Camera B:640*480.
行人帧的规格:高分辨率帧(HR):44*120 到 173*258,平均 105*203;低分辨率帧(LR):8*19 到 19*31,平均 11*21. 高分辨率帧的数量约为低分辨率数量的91倍.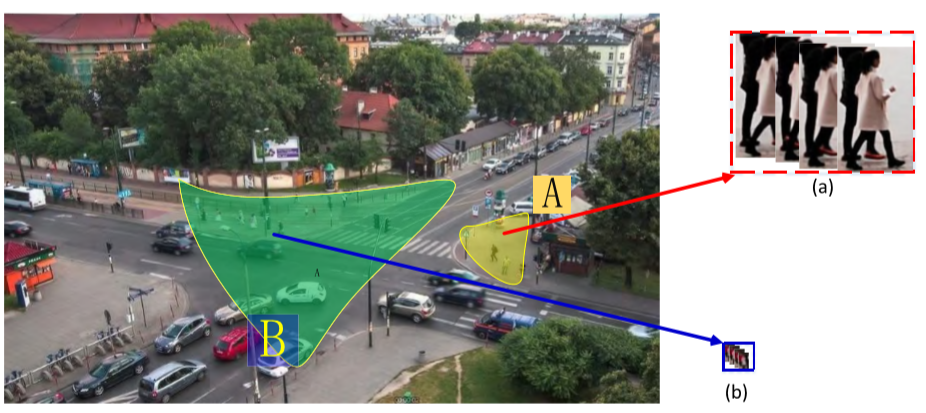
Approach
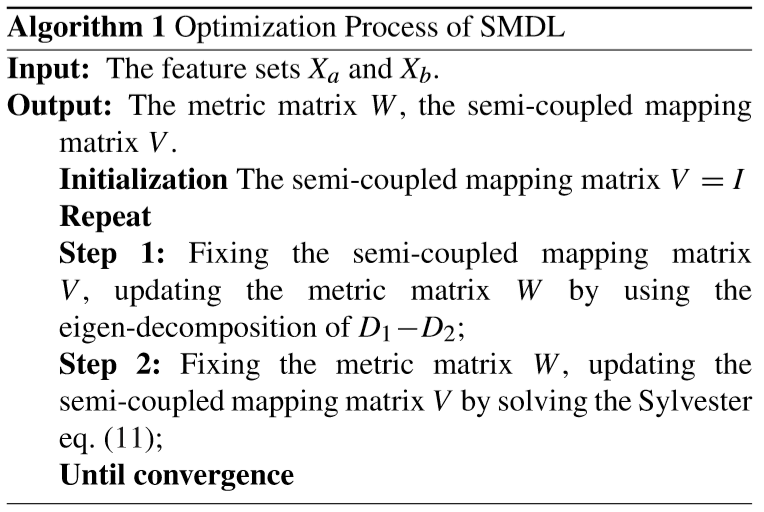
(1)SMDL方法:

① 目标函数(假设相机A拍摄的数据为高分辨率,B拍摄的数据为低分辨率):
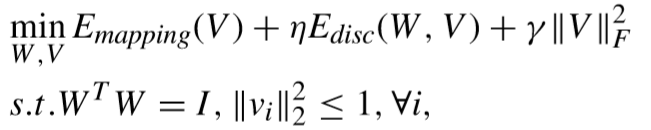
其中 W 表示距离矩阵,V表示高低分辨率对半耦合映射矩阵. 下文具体介绍目标函数中的两项.
② 半耦合映射项:
学习矩阵 V 的作用是将低分辨率行人的特征向着相匹配的高分辨率行人靠近.
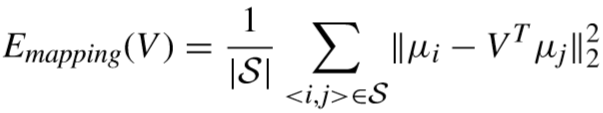
其中 S 为匹配的视频对,![]() ,ni 为 Xi 的特征数量.
,ni 为 Xi 的特征数量.
③ 距离区分度项:(不理解为什么要用 Ø,而不是用相同的 V,但下面的求导过程,两者又是等价的)

其中 D 为不匹配集合,d(.) 为马氏距离.
应用set-to-set distance model(SSD)计算视频间距离:(SSD模型待学习)
![]()
其中![]() ,a^、b^ 为系数向量,可以通过SSD模型计算得出(参考【From Point to Set: Extend the Learning of Distance Metrics;ICCV2013】).
,a^、b^ 为系数向量,可以通过SSD模型计算得出(参考【From Point to Set: Extend the Learning of Distance Metrics;ICCV2013】).
SSD模型的参数计算概述:
![]()
其中:![]()
④ 目标函数的具体化:
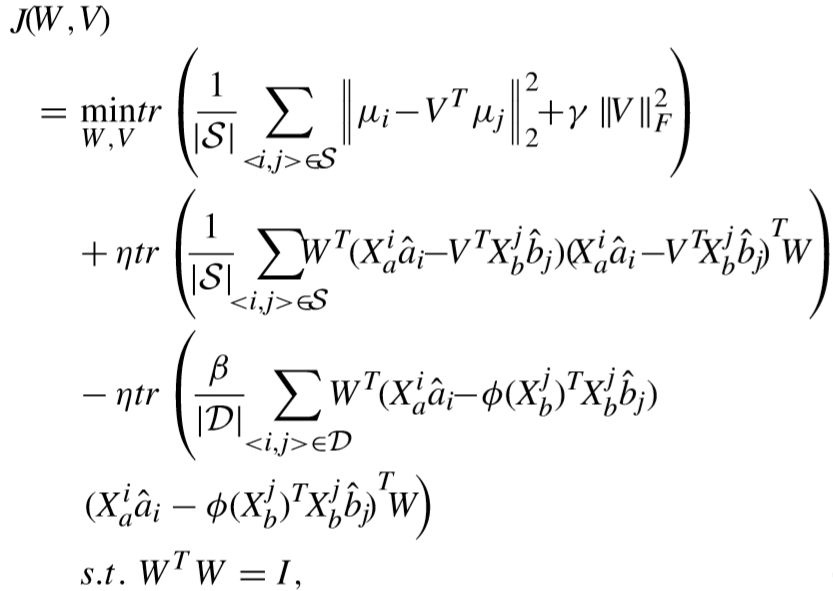
【注:矩阵的迹运算】
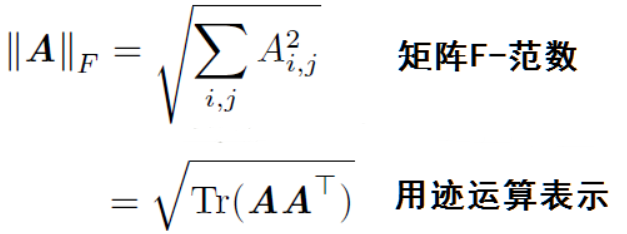
原计算为 XT*W*WT*X = (WT*X)T(WT*X) ,该结果预期是横向量*列向量,最终为实数,
这里看做 tr(WT*X*XT*W) = tr((WT*X) (WT*X)T),该结果预期是列向量*横向量,为矩阵,但迹运算也能得到相同的实数.
(2)优化模型:
① 确定 V 更新 W:
目标函数转化:
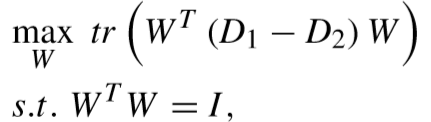
其中:
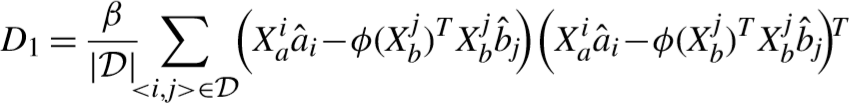
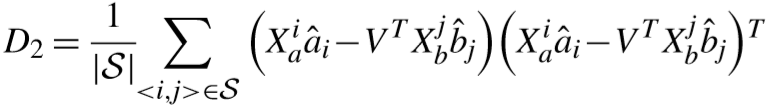
通过构造拉格朗日函数并求导,可得解:
![]()
转为求解特征向量.
② 确定 W 更新 V:
对目标函数进行求导,得:

导数为零,进行改写:![]()
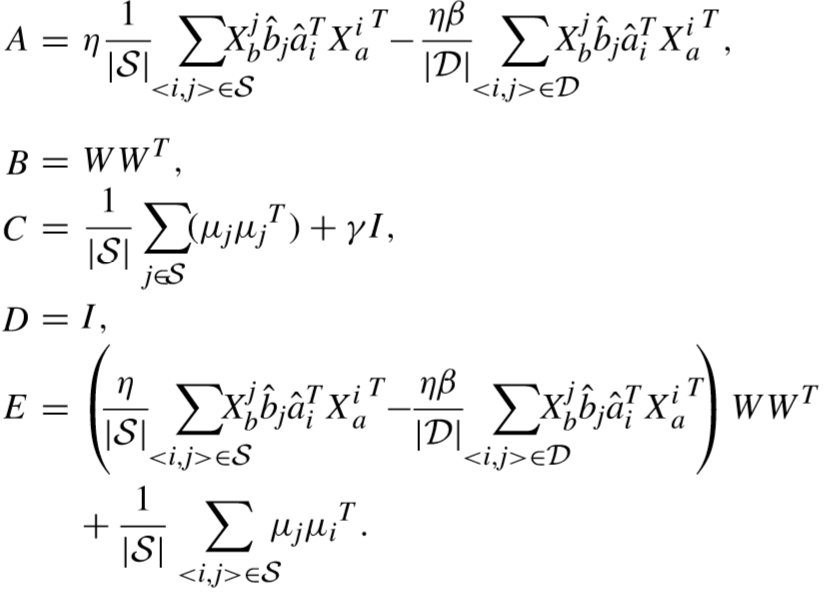
上式为标准西尔维斯特方程.(Sylvester,解法很多,尚未看懂)
③ 算法过程:
(3)识别过程:
通过训练得到的 W、V 计算距离,挑选出距离最近的视频:
![]() .
.
Experiment
(1)实验设置:
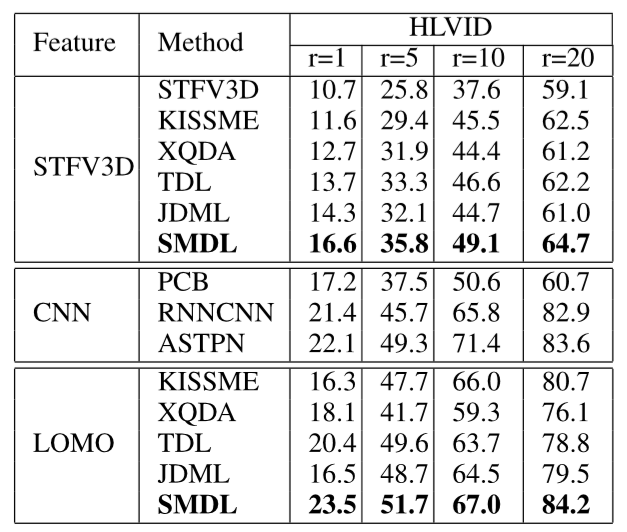
① 特征提取:STFV3D、LOMO、deeply-learning.
步态周期:FEP(Flow Energy Profile)
② 参数设置:β = 0.05;γ = 0.4;η = 0.03. 使用 5-fold cross validation.
③ 对比方法:STFV3D、KISSME、XQDA、TDL、JDML(常规方法);RNNCNN、ASTPN、PCB(深度学习方法).
(2)实验结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号