
论文阅读笔记(六)【TCSVT2018】:Semi-Supervised Cross-View Projection-Based Dictionary Learning for Video-Based Person Re-Identification
Introduction
(1)Motivation:
① 现实场景中,给所有视频进行标记是一项繁琐和高成本的工作,而且随着监控相机的记录,视频信息会快速增多,因此需要采用半监督学习的方式,只对一部分的视频进行标记.
② 不同的相机有着不同的拍摄条件(如设备质量、图片尺寸等等),不同设备间的差异影响匹配的性能.
(2)Contribution:
① 提出一个半监督视频行人重识别方法(semi-supervised video-based person re-id approach).
② 设计了一个半监督字典学习模型(semi-supervised cross-view projection-based dictionary learning, SCPDL),学习特征投影矩阵(降低视频内部的变化)和字典矩阵(降低视频之间的变化).
③ 采用iLIS-VID和PRID2011数据集验证方法.
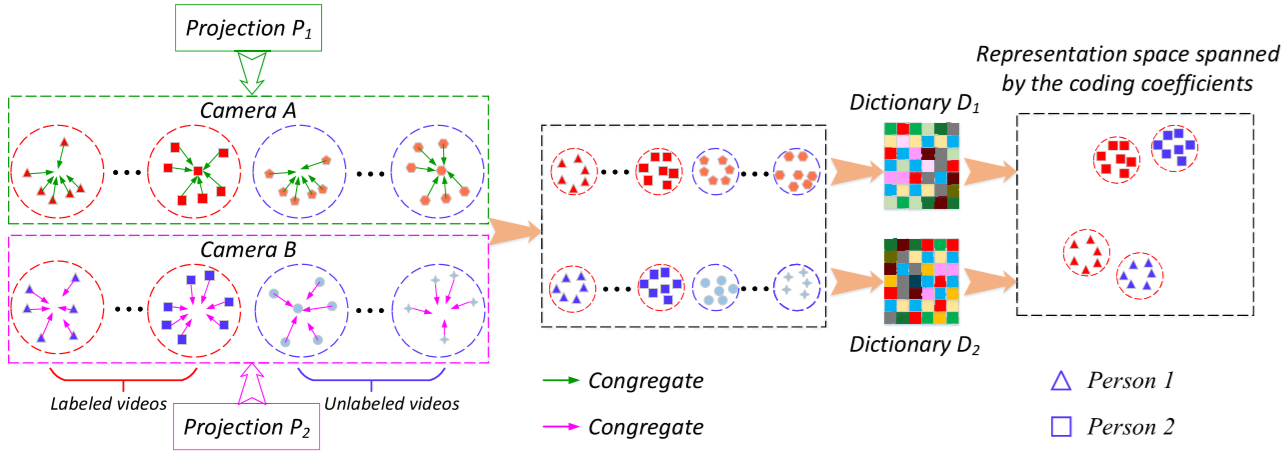
The proposed approach
(1)问题定义:
X = [XL, XU]:相机1中的视频,
Y = [YL, YU]:相机2中的视频,
其中 XL(p*n1)、YL(p*n3) 为标记的训练视频,XU(p*n2)、YU(p*n4) 为未标记的训练视频,n1、n2、n3、n4 为视频中包含的样本数,p 为样本的维数.
P1(p*q)、P2(p*q):相机1和相机2的特征投影矩阵,
其中 q 为投影特征的维数.
D1(q*m)、D2(q*m):相机1和相机2的字典矩阵,
其中 m 为字典的原子数量.
AL、AU、BL、BU:XL、XU、YL、YU 经过字典 D1、D2 后的编码(每个视频的特征向量转为了一个编码矩阵,如 ALi).
问题定义如下:
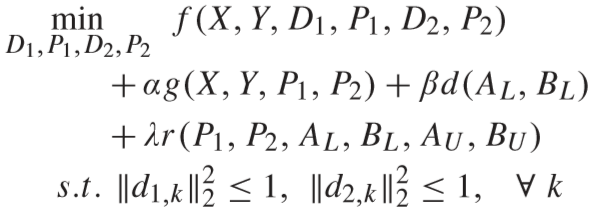
其中 α、β、λ 为平衡因子,d1,k (d2,k) 定义为 D1(D2) 的第 k 个原子.
具体如下:
f(X, Y, D1, P1, D2, P2) 为学习矩阵的保真度项(fidelity term):
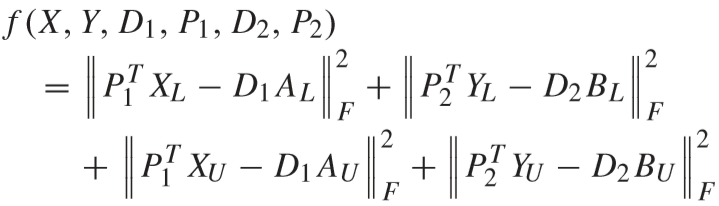
g(X, Y, P1, P2) 为视频聚合项(video congregating term):
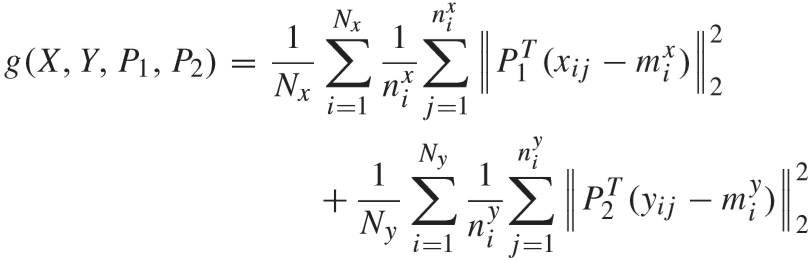
其中 Nx 和 Ny 分别为 X 和 Y 中行人视频的数量,nxi 和 nyi 分别为 X 和 Y 中第 i 个视频的样本数量,mxi 和 nyi 为 X 和 Y 中第 i 个视频所有样本的中心:
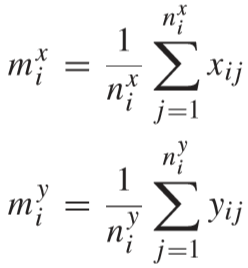
d(AL, BL) 为视频区分度项(video discriminant term),希望的结果是匹配项距离更小,不匹配项距离更大:
![]()
其中 γ 为平衡因子,S 是匹配成功的视频对,D 是不匹配的视频对,距离计算公式:
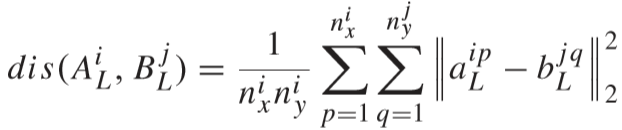
r(P1, P2, AL, BL, AU, BU) 为正则化项(regularization term):
![]()
(2)方法概要:
(3)优化算法:
① 初始化:
通过优化下面的两个公式,对投影矩阵 P1 和 P2 进行初始化,并通过特征分解的方式得到解(特征分解推导参考:【传送门】):
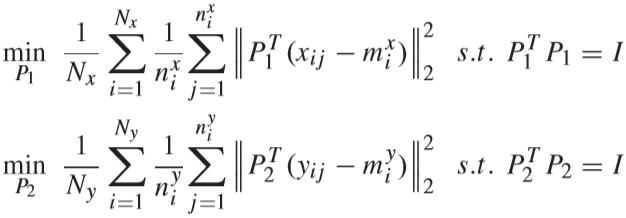
字典矩阵 D1 和 D2 采用随机生成的方法.
通过优化下面的四个公式,对 AL、AU、BL、BU 进行初始化,通过岭回归的方法进行求解(岭回归参考:【传送门】):
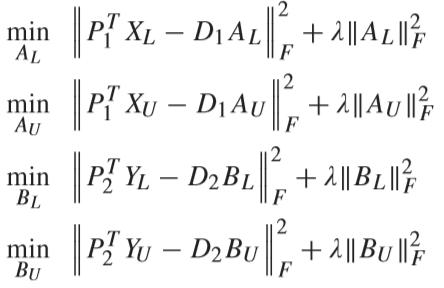
求解结果:
![]()
![]()
![]()
![]()
② 固定D1、D2、P1、P2,更新字典编码 AL、BL、AU、BU:

求解过程为对每一个视频 ALi 依次求解,先对 AL 进行求解(BL 类似),对下式进行求导得到解:
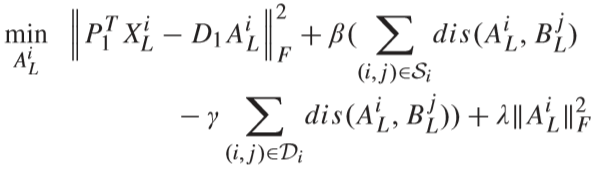
同理,对 AU、BU 进行更新.
③ 固定 AL、BL、AU、BU、D1、D2,更新 P1、P2:

通过求导得出解:
![]()
其中:![]()
![]()
其中:![]()
④ 固定 AL、BL、AU、BU、P1、P2,更新 D1、D2:
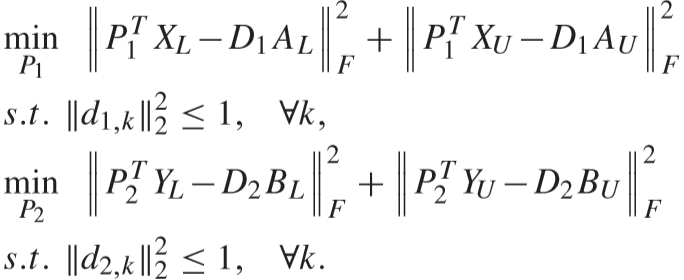
使用ADMM算法进行求解:
引入变量 S:
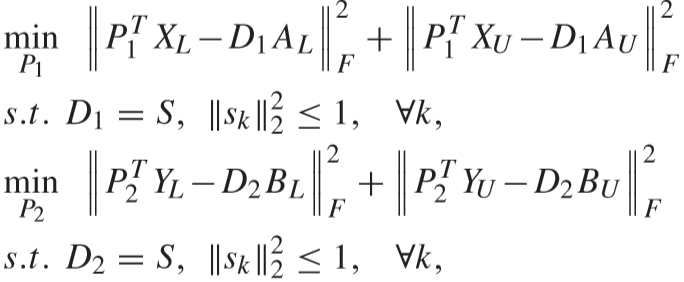
先对 D1 进行求解(D2 同理可得):

⑤ 算法总结:
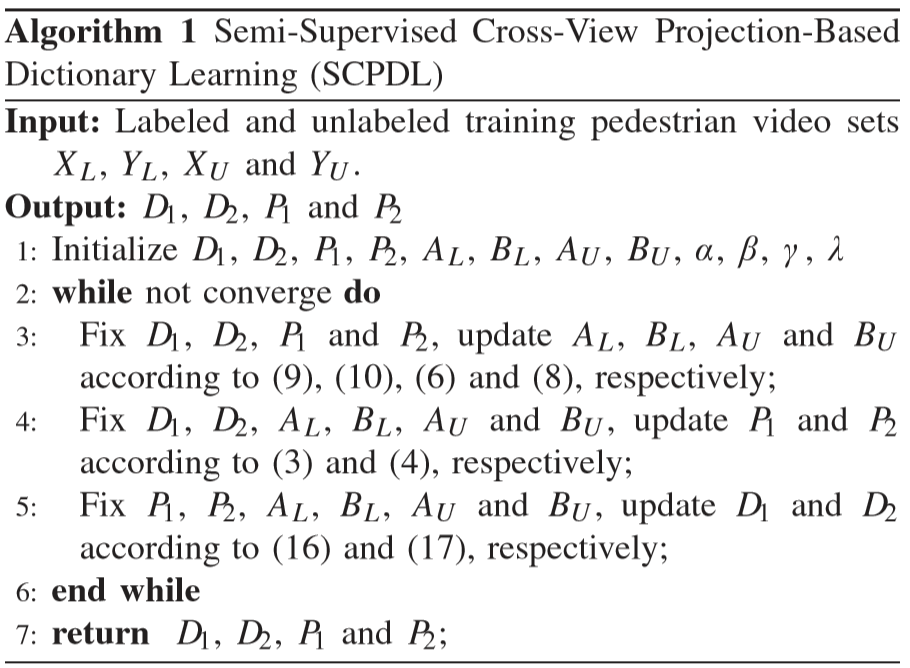
(4)识别过程:
通过上述内容,已经学习到了投影矩阵(P1, P2)、字典矩阵(D1, D2).
从相机1中得到待测视频的特征为 Xi,从相机2中得到视频特征库 Z = {Z1, ..., Zj, ..., Zn}.
识别过程:
① 计算待测视频的字典编码 Ai:
![]()
② 计算视频库所有视频的字典编码 Bj (j = 1, ...,n):
![]()
③ 计算 Ai 和 Bj (j = 1, ..., n) 的距离,并挑选出距离最近的匹配视频.
Experimental Results
(1)实验设置:
① 数据集:iLIDS-VID、PRID2011
参数(α、β等)训练阶段:将标记后的数据集划分,采用3折交叉验证法(分成3份,前2份作为训练集,第3份作为测试集,循环3次取平均测试结果)
评估训练阶段:总体数据集划分为一半标记的数据集,一半未标记的数据集.
② 对比方法:DVR、Salience+DVR、MS-Colour&LBP+DVR、STFV3D、STFV3D+KISSME、TDL、SI2DL、RCN.
③ 参数设置:对于参数 α、β、γ、λ、q、m,采用学习曲线选取最佳的参数.
最终的设置为:对于iLIDS-VID, α = 6、β = 3、γ = 0.05、λ = 0.03、q = 300、m = 220;对于PRID2011,α = 5、β = 4、γ = 0.06、λ = 0.05、q = 260、m = 240.
(2)实验结果:
① 在iLIDS-VID上的结果:
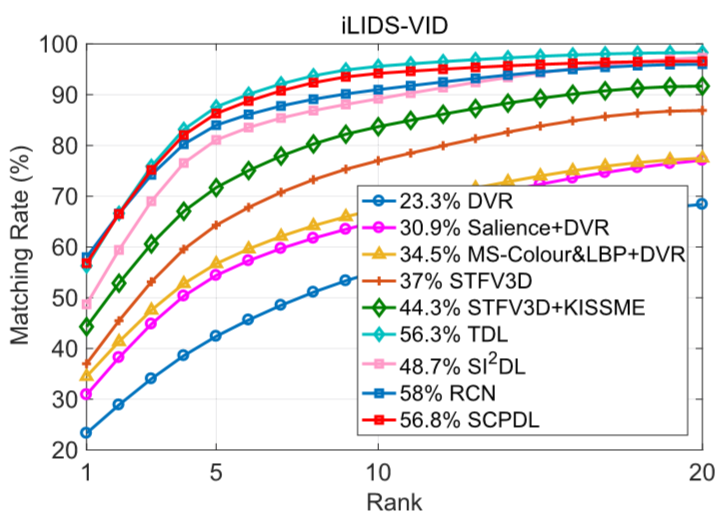
② 在PRID2011上的结果:
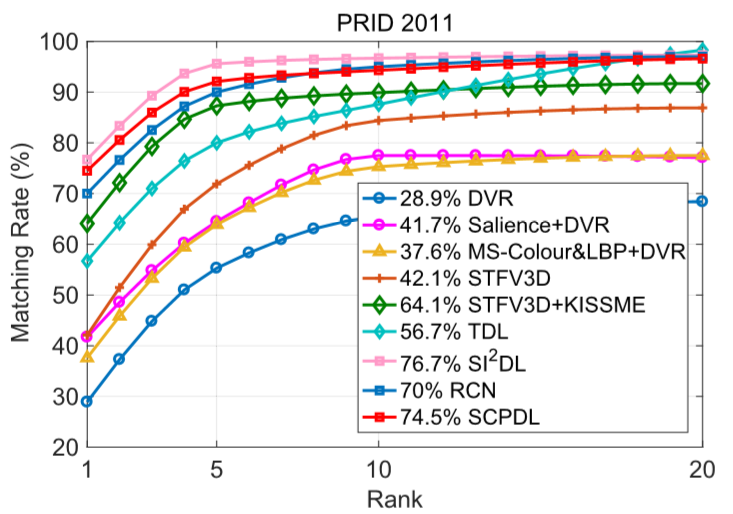
在rank-1阶段SCPDL方法比SI2DL差的可能原因: SCPDL是半监督学习的方法,只能使用一半的带标签数据进行训练,当相同数量的带标签数据时,性能将会更好.

