

论文阅读笔记(二)【IJCAI2016】:Video-Based Person Re-Identification by Simultaneously Learning Intra-Video and Inter-Video Distance Metrics
摘要
(1)方法:
面对不同行人视频之间和同一个行人视频内部的变化,提出视频间和视频内距离同时学习方法(SI2DL).
(2)模型:
视频内(intra-vedio)距离矩阵:使得同一个视频更紧凑;
视频间(inter-vedio)距离矩阵:使得两个匹配视频比不匹配视频距离更小.
设计了视频三元组(vedio triplet),提高学习矩阵的辨别力.
(3)数据集:
iLIDS-VID and PRID 2011 image sequence datasets
介绍
(1)当今大部分方法主要是基于图像的行人重识别(image-based),分为两类:特征学习和距离学习.
特征学习:从行人图像中提取特征,包括:显著性特征(salience features)、中层特征(mid-level features)、显著颜色特征(salient color features).
距离学习:学习高效的距离矩阵,最大化匹配准确率,包括:LMNN(large margin nearest neighbor)、KISSME(keep it simple and straightforward metric)、RDC(relative distance comparison).
(2)最近提出的两个视频Re-id方法:
提取时空特征(spatial-temporal)来表示每一个行人视频. 具体描述:
先对视频进行分割,生成若干片段(fragments/walking cycles),从每一个fragment中提取时空特征,并用提取出的特征来表示视频.
因此视频间Re-id也可视为集合匹配(set to set matching)的问题.
(3)难点:
受到光照(illumination)、姿态(pose)、视角(viewpoint)、遮挡(occlusion)的影响,不仅是多个行人视频间存在变化,在同一个行人视频中的不同帧(frame)也存在变化.

上述方法没有对视频内变化(intra-video variations)和视频间变化(inter-video variations)进行同时处理.
(4)降低集合间变化的方法:基于集合的距离学习(set-based distance learning)
已提出的方法有:MDA(manifold discriminant analysis)、SBDR(set-based discriminative ranking)、CDL(covariance discriminative learning)、SSDML(set-to-set distance metric learning)、LMKML(localized multi-kernel metric learning).
(5)Motivation:
① 现有主要Re-id算法是基于图片的;
② 基于视频的Re-id可以看做是对图像集合处理,但现有基于集合的距离学习方法并不是为解决基于视频的Re-id而设计的.
(6)Contribution:
① 提出了名为SI2DL的基于视频的Re-id方法;
② 设计了一个新的基于集合的距离学习模型;
③ 设计了一个新的视频关系模型(视频三元组);
④ 采用iLIDS-VID and PRID 2011数据集进行评估.
SI2DL
(1)问题定义:
① 训练集:X = [X1, ..., Xi, ..., XK]
每个行人视频 Xi 是 p*ni 维,即第 i 个视频含有 ni 个样本(sample),每个样本是 p 维,定义第 i 个视频的第 j 个样本为 xij.
② 直观上可以理解,如果让每一个视频内部更紧凑,视频之间的可分离性越明显. 由此引出视频内距离矩阵(intra-video distance metric)和视频间距离矩阵(inter-video distance metric).

③ 定义 J(V,W):
V:intra-video distance metrics,规格:p*K1
W:inter-video distance metrics,规格:K1*K2
vi:V矩阵的第 i 列,规格:p*1
wi:W矩阵的第 i 列,规格:p*1
f(V, X):视频内部的聚合项(congregating term)
g(W,V,X):视频之间的区分度项(discriminant term)
μ:权重平衡因子
SI2DL的框架:训练V和W,降低上述两项之和:

④ 计算 f(V,X):
使用每一个视频所有sample的均值来表示视频,即第 i 个视频 Xi 的均值为:
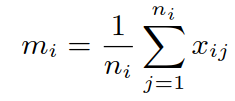
计算聚合项:N表示数据集中所有的图片帧数量

对公式的理解:
VT(xij-mi)的矩阵规格运算:(K1*p)*(p*1) = K1*1
VT在这里产生了改变向量长度的作用,将距离进行了矩阵变化,使得视频内sample围绕中心进行靠近.
⑤ 定义三元组(video triplet):
参数:视频 Xi,Xj,Xk,对应 mi,mj,mk
其中 Xj 是 Xi 的正确匹配,而 Xk 是 Xi 的错误匹配,
满足![]()
称 Xi,Xj,Xk 为三元组,记为<i,j,k>.
⑥ 计算 g(W,V,X):|D|表示三元组的数量.
计算区分度项:
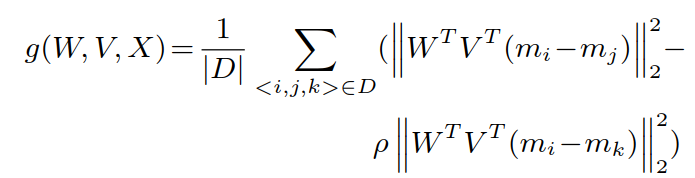
其中 ρ 是惩罚项:![]()
两个范式之间的差值可以理解为:正确匹配的距离和错误匹配的距离之差,期望的结果是正确匹配的距离更小,错误匹配的距离更大,也就是这个差值更小.
为什么要加这个惩罚项?个人的理解是:为了保证区分度项始终是正值.
简写 ρ = exp(- b 式/ a 式),ρ < 1. 若 a 式的值比 b 式小很多,那么 ρ 会很小,b 式会被削弱,(a式 - ρ*b式)结果为正;若 a 式的值比 b 式大很多,那么 ρ 会接近1,那么(a式 - ρ*b式)结果也为正.
⑦目标函数:
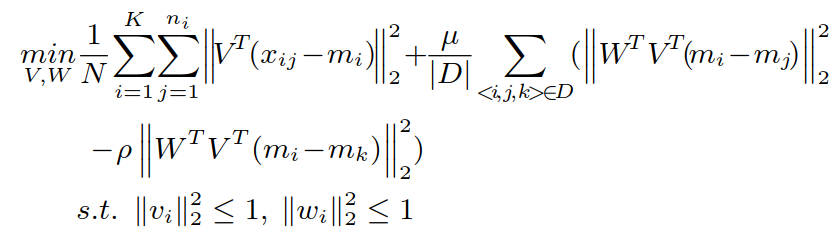
(2)SI2DL的优化:
① 由于上面的公式不是凸的,需要将问题进行转化:

其中 M1 和 M2 矩阵的元素分别为:![]() 和
和![]() ,其中<i,j,k>属于D.
,其中<i,j,k>属于D.
(为什么?可能是凸优化方面的问题,还没有去学习,对这个公式的转化也不理解)
【注】Frobenius范式的计算方式:![]()
② 确定 V、W 来更新 A、B:
初始化 V:
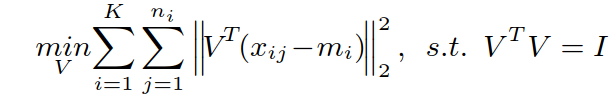
通过构建拉格朗日函数,并对其求导,得到结果:![]()
其中 ![]()
个人推导过程【不一定准确】:
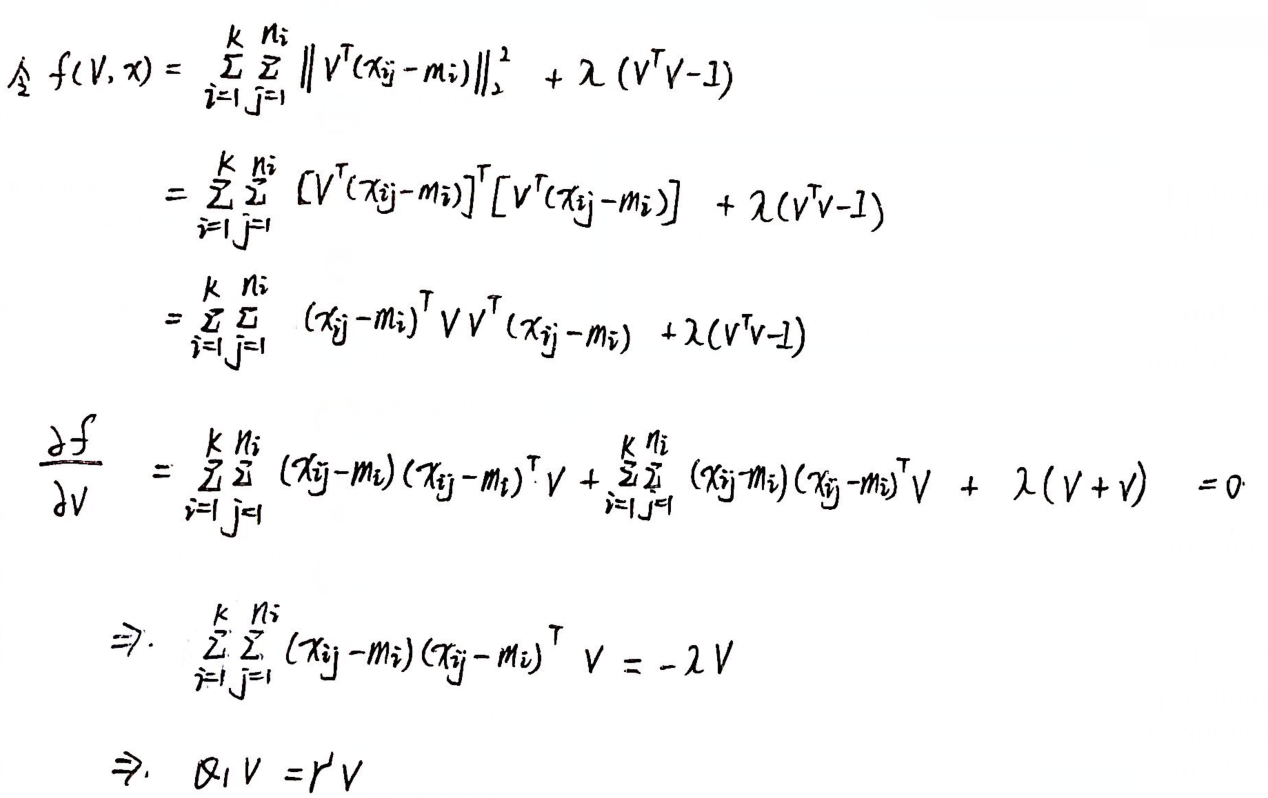
问题转化为了特征分解问题,选取 K1 个特征向量作为 V 的初始化.
初始化W:

采用同样的方法,选取 K2 个特征向量作为 W 的初始化.
当 V 和 W 确定后,通过优化下面的公式来获得 A 和 B :
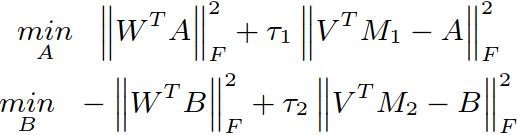
③ 确定 A、B、W 来更新 V:
当 A、B、W 确定后,优化问题转化为:
![]()
其中: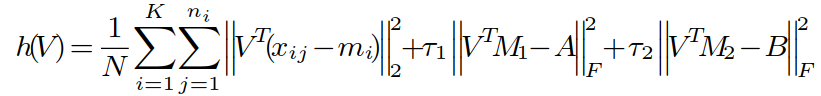
使用 ADMM算法 对上述的公式进一步转化:
首先引入变量S:![]()
ADMM算法:
④ 确定 A、B、V 来更新W:
当 A、B、W 确定后,优化问题转化为:
![]()
同样使用ADMM算法把问题进一步优化,求解出 W.
⑤ SI2DL 算法总结:

(3)使用 V,W 矩阵对结果进行预测:
视频库(gallery video):Y = [Y1, ..., Yi, ..., Yn]
第 i 个视频为 Yi,规格为:p * li,其中 li 为 Yi 中的样本数量.
待测视频 Zi 的规格为:p * ni,其中 ni 为 Zi 中的样本数量.
Yi / Zi 的第 j 个样本记为 yij / zij.
识别过程:
① 计算 Zi 和 Yi 的一阶表示: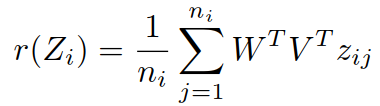
② 计算两者间的距离:![]()
③ 在视频库中挑选出距离最近的视频,作为 Zi 的匹配结果.
实验结果
(1)实验设置:
① 对比试验:
discriminative video fragments selection and ranking (DVR)
改进版:Salience+DVR 、 MSColour&LBP+DVR
spatial-temporal fisher vector representation (STFV3D)
改进版:STFV3D+KISSME
② 参数设置:
对于iLIDS-VID数据集(K1,K2) = (2200,80),μ = 0.00005、τ1 = 0.2、τ2 = 0.2;
对于PRID数据集(K1,K2) = (2500,100),μ = 0.00005、τ1 = 0.1、τ2 = 0.1;
③ 评估设置:
数据集50%用作训练集,50%用作测试集.
测试集中第1个相机的数据用作测试组,第2个相机的数据用作视频库.
使用CMC曲线评测,CMC曲线的介绍:【传送门】
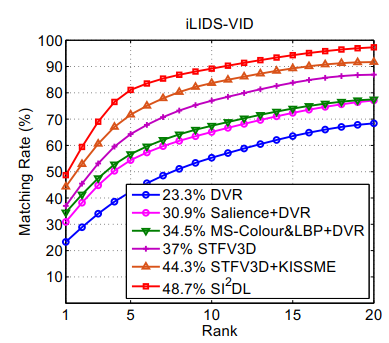
(2)在iLIDS-VID数据集上的评测结果:
该数据集含有300个行人的600个图像序列,每个行人都有来自两个相机拍摄的图像序列.
每个图像序列含有22-192帧,平均还有71帧.
(3)在PRID2011数据集上的测评结果:
Cam-A含有385个行人的图像序列,Cam-B含有749个行人的图像序列.
每个序列含有5-675帧,平均含有84帧.(低于20帧的需要被忽略)


