神经网络和深度学习(一)神经网络基础
1、什么是神经网络?
(1)房价预测模型Ⅰ:

神经网络:size x ——> O ——> price y
ReLU函数(Rectified linear unit 修正线性单元):修改线性的函数,避免出现price未负数的情况.
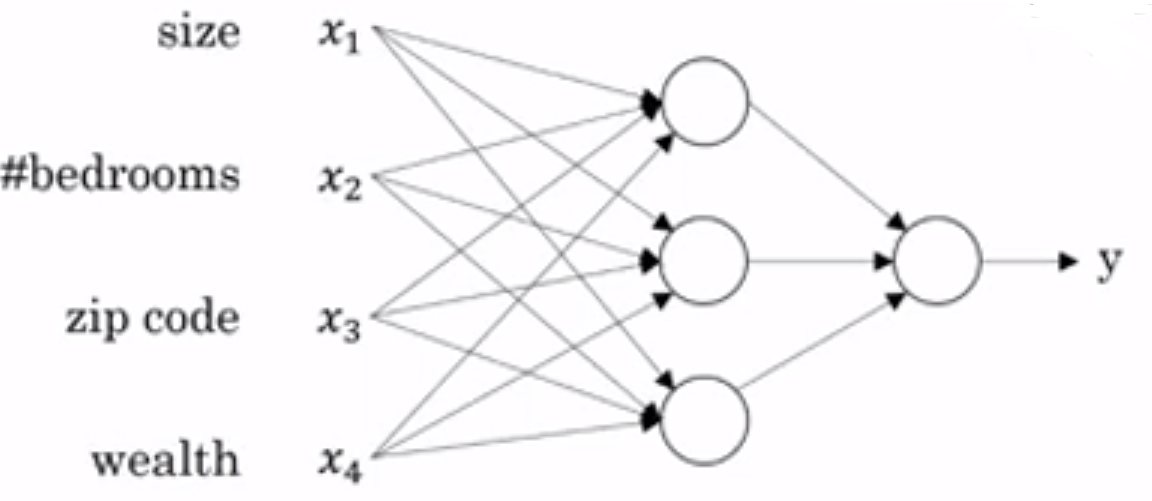
(2)房价预测模型Ⅱ:
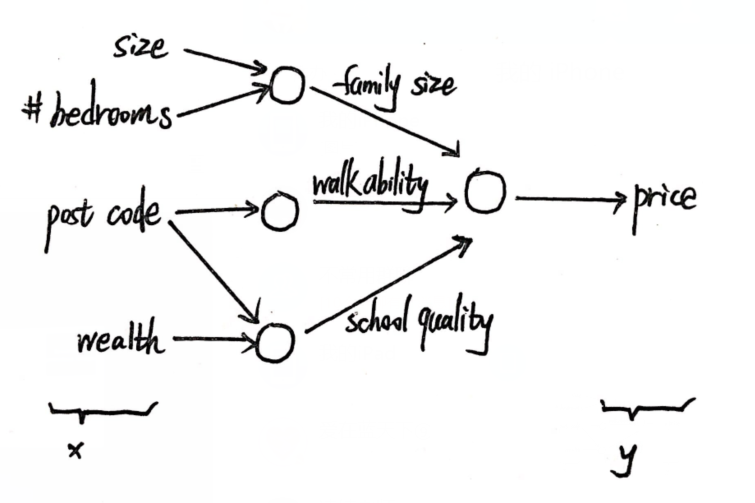
即神经网络为:
2、Binary classification(二分分类):
以识别照片中的猫为例
① 判定:若是猫,则 y = 1;若不是猫,则 y = 0.
② 图片规格:64*64,数字化表示:3个 64*64矩阵,分别表示Red Green Blue的强度值.
③ 样本x的向量长度:nx = 64*64*3 = 12288.
④ 训练集:{(x(1), y(1)), (x(2), y(2)), ..., (x(m), y(m))}.
⑤ 训练集数量:mtrain,测试集数量:mtest.
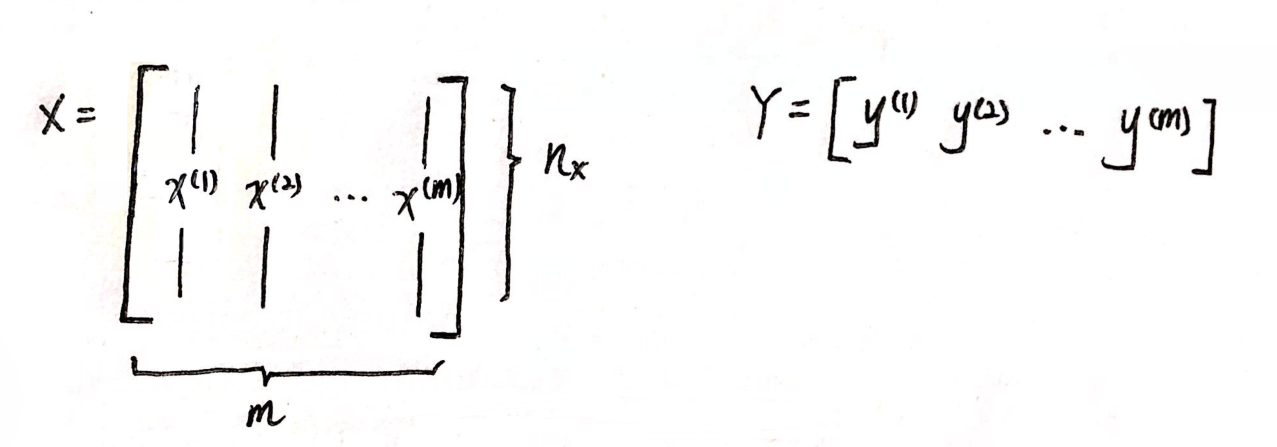
⑥ 矩阵X:有m列,每一列表示一个样本x(i).
⑦ 向量Y:长度为m.
3、Logistic regression(逻辑回归):
(1)问题定义:
给出 x,求 y^ = P(y = 1 | x),即在 x 的条件下,照片是猫的概率,y^ 的取值为[0, 1].
(2)解决思路:
给出参数 w(nx 长度向量),参数 b(常数).
输出 y^ = wTx + b( b 即 θ0,w 即 θ1~θnx).
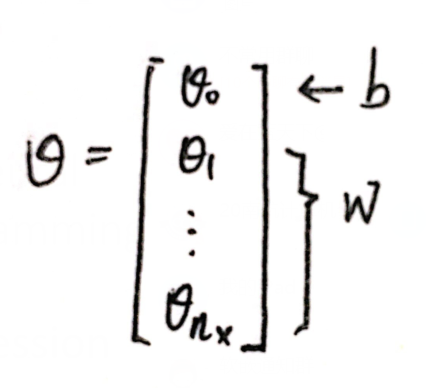
但这样输出的概率值会超出[0, 1]的范围,不合理.
使用sigmoid函数,对向量 x 添加x0 = 1,向量化计算 y^ = sigmoid(wTx +b) = sigmoid(θTx),将概率值限制在了[0, 1]内.
其中 sigmoid(z) = 1/(1 + e^(-z)).

问题转换为:求参数 w 和 b,使得 y^(i) 与 y(i) 相近.
4、Cost function(代价函数):
Loss/Error function (损失函数):![]()
在逻辑回归中的损失函数:![]()
如果 y = 1, L = - log(y^),则希望 y^ 越大;如果 y = 0,L = log(1 - y^),则希望 y^ 越小.
Cost function: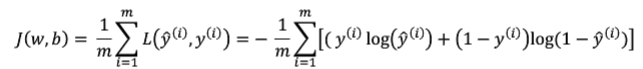
问题转换为:求参数 w 和 b,使得最小化 J(w, b).
5、计算图的导数计算:
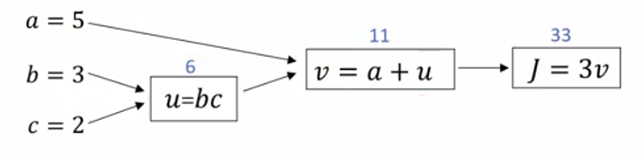
体会链式法则和反向传播:
dJ/dv = 3;
dv/da = 1,dJ/da = dJ/dv * dv/da = 3;
dv/du = 1,dJ/du = dJ/dv * dv/du = 3;
du/db = 2,dJ/db = dJ/du * du/db = 6;
du/dc = 3,dJ/dc = dJ/du * du/dc = 9.
6、Gradient Descent(梯度下降):
(1)梯度下降过程:

(2)含有2个特征量,单个样本的情况:
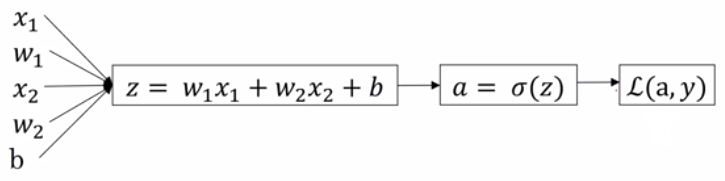
"da" = dL/da = -y/a + (1-y)/(1-a)
"dz" = dL/dz = dL/da * da/dz = [-y/a + (1-y)/(1-a)] * a(1-a) = a-y
"dw1" = dL/dw1 = dL/dz * dz/dw1 = (a-y)*x1
"dw2" = dL/dw2 = dL/dz * dz/dw2 = (a-y)*x2
"db" = dL/db = dL/dz * dz/db = (a-y)*1 = a-y
梯度下降流程(一次梯度更新):
w1 = w1 - α*dw1 = w1 - α*(a-y)*x1
w2 = w2 - α*dw2 = w2 - α*(a-y)*x2
b = b - α*db = b - α*(a-y)
(3)含有2个特征量,m 个样本的情况:
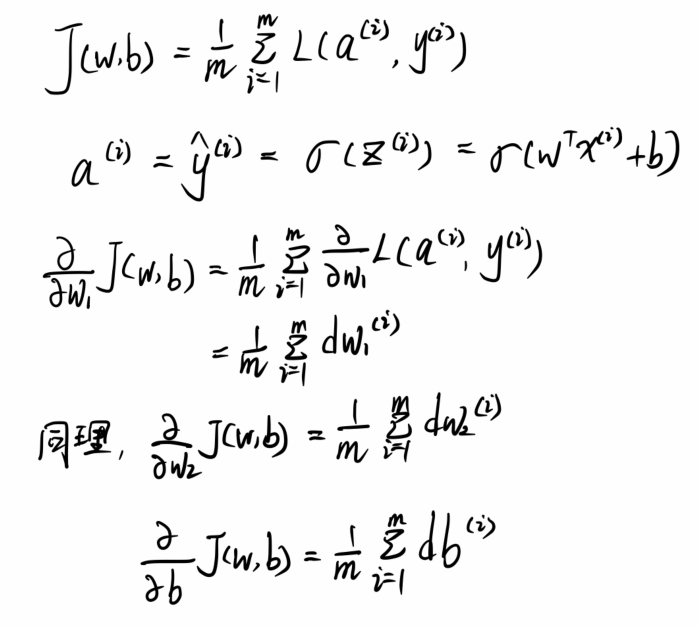
梯度下降过程:
Repeat{
w1 = w1 - α/m*∑dw1(i) = w1 - α/m*∑(a-y)*x1(i)
w2 = w2 - α/m*∑dw2(i) = w2 - α/m*∑(a-y)*x2(i)
b = b - α/m*∑db(i) = b - α/m*∑(a-y)
}
7、向量化:
循环计算:效率低
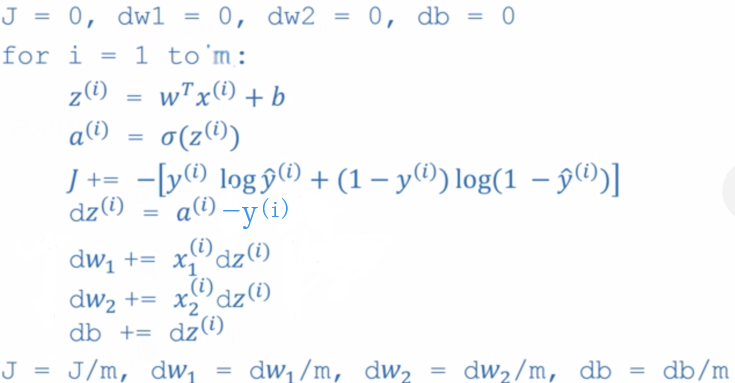
向量化计算:效率高
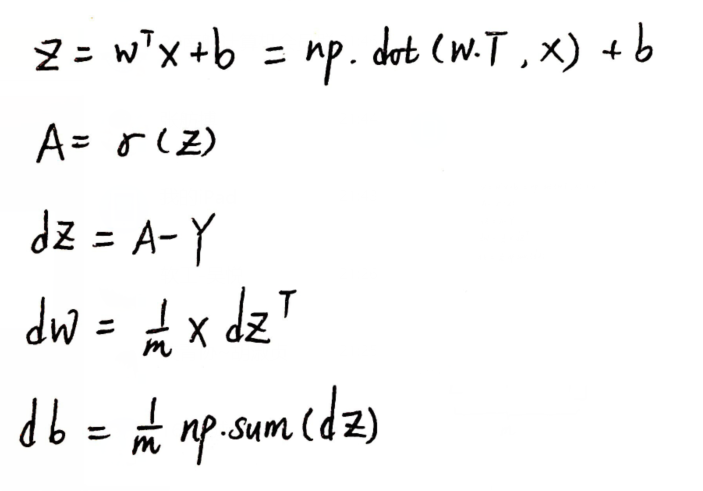

 浙公网安备 33010602011771号
浙公网安备 33010602011771号