
流式大数据计算实践(2)----Hadoop集群和Zookeeper
一、前言
1、上一文搭建好了Hadoop单机模式,这一文继续搭建Hadoop集群
二、搭建Hadoop集群
1、根据上文的流程得到两台单机模式的机器,并保证两台单机模式正常启动,记得第二台机器core-site.xml内的fs.defaultFS参数值要改成本机的来启动,启动完毕后再改回来
2、清空数据,首先把运行单机模式后生成的数据全部清理掉
rm -rf /work/hadoop/nn/current rm -rf /work/hadoop/dn/current
hdfs namenode -format
3、启动集群
(1)storm1作为namenode节点,所以在这台机上面执行命令启动namenode
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --script hdfs start namenode
(2)storm2作为datanode节点,所以在这台机上面执行命令启动datanode
$HADOOP_PREFIX/sbin/hadoop-daemon.sh --script hdfs start datanode
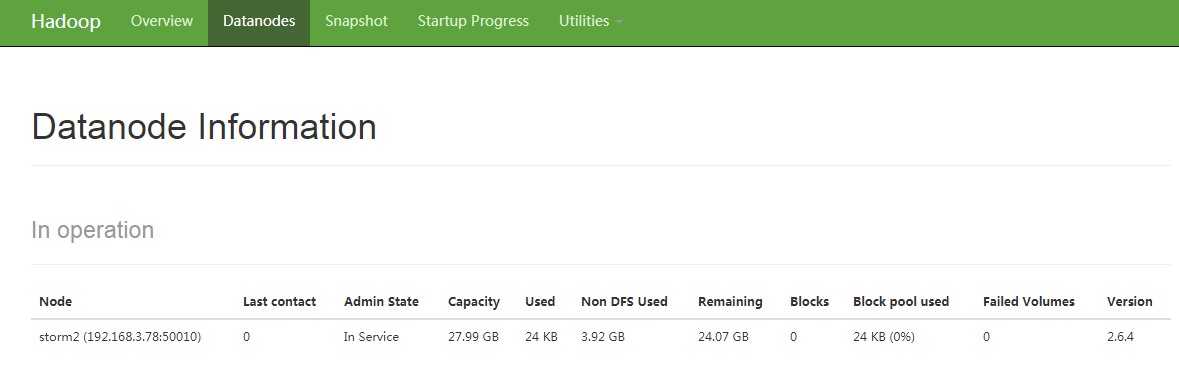
(3)通过jps命令可以看到对应的节点,然后通过50070的控制台可以看到storm2的datanode节点
三、ZooKeeper
1、Zookeeper是分布式框架经常要用到的应用协调服务,相当于让分布式内的每个组件同步起来
2、Zookeeper安装
(1)下载Zookeeper的tar.gz包,并解压
(2)配置环境变量
vim /etc/profile #set zookeeper env export ZOOKEEPER_HOME=/work/soft/zookeeper-3.4.13 export PATH=$PATH:$ZOOKEEPER_HOME/bin source /etc/profile
(3)配置ZooKeeper
①进入到Zookeeper目录的conf文件夹,可以看到里面有一个配置文件的模板zoo_sample.cfg,将模板复制一份到zoo.cfg
②然后编辑内容,只需要修改Zookeeper的存放数据的目录(记得创建对应文件夹)
vim /work/soft/zookeeper-3.4.13/conf/zoo.cfg dataDir=/work/zookeeper/data
③继续编辑bin目录下的zkEnv.sh文件来修改Zookeeper存放日志的目录(记得创建对应文件夹)
vim /work/soft/zookeeper-3.4.13/bin/zkEnv.sh ZOO_LOG_DIR=/work/zookeeper/logs
④进入到刚刚设定的数据目录,创建一个文件myid,并写入本台机器的Zookeeper Id,这个id的取值范围是1-255,我这里取得分别是1和2
vim /work/zookeeper/data/myid 1
(4)启动单机版Zookeeper
①首先启动Zookeeper
$ZOOKEEPER_HOME/bin/zkServer.sh start
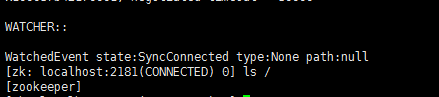
②进入到Zookeeper的控制台查看数据目录是否正常
$ZOOKEEPER_HOME/bin/zkCli.sh ls /
(5)启动集群版Zookeeper
①先停止单机版
$ZOOKEEPER_HOME/bin/zkServer.sh stop
②把刚刚单机版产生的数据删除,执行删除目录时,一定要小心不要输错,还有记得再把刚才的myid文件创建出来- -
rm -rf /work/zookeeper/data/* rm -rf /work/zookeeper/logs/*
③进入Zookeeper的conf目录,编辑zoo.cfg,在文件末尾配置Zookeeper集群的节点信息
vim /work/soft/zookeeper-3.4.13/conf/zoo.cfg server.1=storm1:2888:3888 server.2=storm2:2888:3888
④在每台机器启动Zookeeper,然后通过jps命令查看进程是否存在
$ZOOKEEPER_HOME/bin/zkServer.sh start jps

⑤使用查看集群状态命令,在每台机器执行,可以发现一台是leader,另一台是follower,说明集群是OK的
$ZOOKEEPER_HOME/bin/zkServer.sh status



 浙公网安备 33010602011771号
浙公网安备 33010602011771号