Linux内核之 内存管理
前面几篇介绍了进程的一些知识,从这篇开始介绍内存、文件、IO等知识,发现更不好写哈哈。但还是有必要记录下自己的所学所思。供后续翻阅,同时写作也是一个巩固的过程。
这些知识以前有文档涉及过,但是角度不同,这个系列站的角度更底层,基本都是从Linux内核出发,会更深入。所以当你都读完,然后再次审视这些功能的实现和设计时,我相信你会有种豁然开朗的感觉。
1、页
内核把物理页作为内存管理的基本单元。
尽管处理器的最小处理单位是字(或者字节),但是MMU(内存管理单元,管理内存并把虚拟地址转换为物理地址的硬件)通常以页为单位进行处理。所以从虚拟内存看,页也是最小单元。
体系不同,支持的页大小不同。大多数32位体系结构支持4KB的页,而64位体系结构一般会支持8KB的页。
内核用struct page结构体表示系统中的每个页,包含很多项比如页的状态(有没有脏,有没有被锁定)、引用计数(-1表示没有使用)等等。
page结构和物理页相关,和虚拟内存无关。所以它的描述是短暂的,仅仅记录当前的使用状况,当然也不会描述其中的数据。
内核用这个结构来管理系统中所有的页,所以内核知道哪些页是空闲的,如果在使用中拥有者又是谁。
这个拥有者有四种:用户空间进程、动态分配内存的内核数据、静态内核代码以及页高速缓存。
2、区
有些页是有特定用途的。比如内存中有些页是专门用于DMA的。
内核使用区的概念将具有相似特性的页进行分组。区是一种逻辑上的分组的概念,而没有物理上的意义。
区的实际使用和分布是与体系结构相关的。在x86体系结构中主要分为3个区:ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM。
ZONE_DMA区中的页用来进行DMA(直接内存访问)时使用。
ZONE_HIGHMEM是高端内存,其中的页不能永久的映射到内核地址空间,也就是说,没有虚拟地址。
剩余的内存就属于ZONE_NORMAL区,叫低端内存。
不是所有体系都定义全部区,有些体系结构,比如x86-64可以映射和处理64位的内存空间,所以它没有ZONE_HIGHMEM区,所有的物理内存都都处于ZONE_DMA和ZONE_NORMAL区。
每个区都用结构体struct zone表示。
3、接口
获得页
获得页使用的接口是alloc_pages函数与__get_free_page函数。后者也是调用了前者,只不过在获得了struct page结构体后使用page_address函数获得了虚拟地址。
我们在使用这些接口获取页的时候可能会面对一个问题,我们获得的这些页若是给用户态用,虽然这些页中的数据都是随机产生的垃圾数据,不过,虽然概率很低,但是也有可能会包含某些敏感信息。所以,更谨慎些,我们可以将获得的页都填充为0。这会用到get_zeroed_page函数。而这个函数又用到了__get_free_pages函数。
所以这三个函数最终都是使用了alloc_pages函数。
释放页
当我们不再需要某些页时可以使用下面的函数释放它们:
__free_pages(struct page *page, unsigned int order)
free_pages(unsigned long addr, unsigned int order)
free_page(unsigned long addr)
以上这些接口都是以页为单位进行内存分配与释放的。
kmalloc与vmalloc
在实际中内核需要的内存不一定是整个页,可能只是以字节为单位的一片区域。这两个函数就是实现这样的目的。
不同之处在于,kmalloc分配的是虚拟地址连续,物理地址也连续的一片区域,vmalloc分配的是虚拟地址连续,物理地址不一定连续的一片区域。
对应的释放内存的函数是kfree与vfree。
4、slab层
以页为最小单位分配内存对于内核管理系统中的物理内存来说的确比较方便,但内核自身最常使用的内存却往往是很小的内存块——比如存放文件描述符、进程描述符、虚拟内存区域描述符等行为所需的内存都远不及一页,一个整页中可以聚集多个这些小块内存。
为了满足内核对这种小内存块的需要,Linux系统采用了一种被称为slab分配器(也称作slab层)的技术。slab分配器的实现相当复杂,但原理不难,其核心思想就是“存储池”的运用。内存片段(小块内存)被看作对象,当被使用完后,并不直接释放而是被缓存到“存储池”里,留做下次使用,这无疑避免了频繁创建与销毁对象所带来的额外负载。
slab分配器扮演了通用数据结构缓存层的角色。
slab层把不同的对象划分为所谓高速缓存组,其中每个高速缓存组都存放不同类型的对象,每种对象对应一个高速缓存。
常见的高速缓存组有:进程描述符(task_struct结构体),索引节点对象(struct inode),目录项对象(struct dentry),通用页对象等等。
这些高速缓存又被划分为slab。slab由一个或多个物理连续的页组成,一般仅仅由一页组成。每个高速缓存可以由多个slab(页)组成。
每个高速缓存都使用struct kmem_cache结构表示,这个结构包含三个链表:slabs_full、slabs_partial和slabs_empty,均放在kmem_list3结构体内。这些链表的每个元素为slab描述符即struct slab结构体。
每个高速缓存需要创建新的slab即新的页,还是通过上面提到的__get_free_page()来实现的。通过最终调用free_pages()释放内存页。
一个高速缓存的创建和销毁使用kmem_cache_create与kmem_cache_destroy。
高速缓存中的对象的分配和释放使用kmem_cache_alloc与kmem_cache_free。
从上看出,slab层仍然是建立在页的基础之上,可以总结为slab层将 空闲页 分解成 众多相同长度的小块内存 以供 同类型的数据结构 使用。
5、进程地址空间
以上我们讲述了内核如何管理内存,内核内存分配机制包括了页分配器和slab分配器。内核除了管理本身的内存外,也必须管理用户空间中进程的内存。
我们称这个内存为进程地址空间,也就是系统中每个用户空间进程所看到的内存。Linux系统采用虚拟内存技术,所有进程以虚拟方式共享内存。Linux中主要采用分页机制而不是分段机制。
5.1 地址空间布局
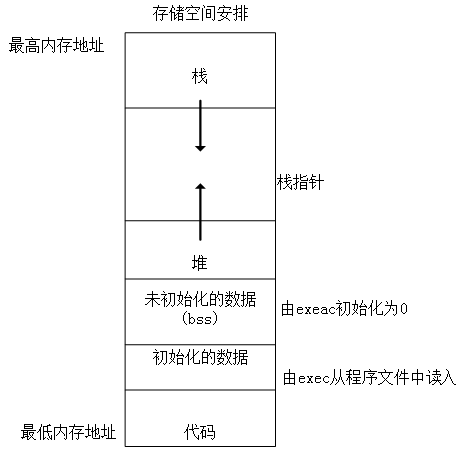
进程内存区域可以包含各种内存对象,从下往上依次为:
(1)可执行文件代码的内存映射,称为代码段。只读可执行。
(2)可执行文件的已初始化全局变量的内存映射,称为数据段。后续都是可读写。
(3)包含未初始化的全局变量,就是bass段的零页的内存映射。
(4)堆区,动态内存分配区域;包括任何匿名的内存映射,比如malloc分配的内存。
(5)栈区,用于进程用户空间栈的零页内存映射,这里不要和进程内核栈混淆,进程的内核栈独立存在并由内核维护,因为内核管理着所有进程。所以内核管理着内核栈,内核栈管理着进程。
(6)其他可能存在的:内存映射文件;共享内存段;C库或者动态链接库等共享库的代码段、数据段和bss也会被载入进程的地址空间。
5.2 内存描述符
内核使用内存描述符mm_struct结构体表示进程的地址空间,该结构体包含了和进程地址空间有关的全部信息。
1 struct mm_struct { 2 struct vm_area_struct *mmap; /* list of memory areas */ 3 struct rb_root mm_rb; /* red-black tree of VMAs */ 4 struct vm_area_struct *mmap_cache; /* last used memory area */ 5 unsigned long free_area_cache; /* 1st address space hole */ 6 pgd_t *pgd; /* page global directory */ 7 atomic_t mm_users; /* address space users */ 8 atomic_t mm_count; /* primary usage counter */ 9 int map_count; /* number of memory areas */ 10 struct rw_semaphore mmap_sem; /* memory area semaphore */ 11 spinlock_t page_table_lock; /* page table lock */ 12 struct list_head mmlist; /* list of all mm_structs */ 13 unsigned long start_code; /* start address of code */ 14 unsigned long end_code; /* final address of code */ 15 unsigned long start_data; /* start address of data */ 16 unsigned long end_data; /* final address of data */ 17 unsigned long start_brk; /* start address of heap */ 18 unsigned long brk; /* final address of heap */ 19 unsigned long start_stack; /* start address of stack */ 20 unsigned long arg_start; /* start of arguments */ 21 unsigned long arg_end; /* end of arguments */ 22 unsigned long env_start; /* start of environment */ 23 unsigned long env_end; /* end of environment */ 24 unsigned long rss; /* pages allocated */ 25 unsigned long total_vm; /* total number of pages */ 26 unsigned long locked_vm; /* number of locked pages */ 27 unsigned long def_flags; /* default access flags */ 28 unsigned long cpu_vm_mask; /* lazy TLB switch mask */ 29 unsigned long swap_address; /* last scanned address */ 30 unsigned dumpable:1; /* can this mm core dump? */ 31 int used_hugetlb; /* used hugetlb pages? */ 32 mm_context_t context; /* arch-specific data */ 33 int core_waiters; /* thread core dump waiters */ 34 struct completion *core_startup_done; /* core start completion */ 35 struct completion core_done; /* core end completion */ 36 rwlock_t ioctx_list_lock; /* AIO I/O list lock */ 37 struct kioctx *ioctx_list; /* AIO I/O list */ 38 struct kioctx default_kioctx; /* AIO default I/O context */ 39 };
mmap和mm_rb描述的对象是一样的:该地址空间中全部内存区域(all memory areas)。
mmap是以链表的形式存放,而mm_rb是以红黑树存放,前者有利于遍历所有数据,而后者有利于快速搜索定位到某个地址。所有的mm_struct结构体都通过自身的mmlist域连接在一个双向链表中,该链表的首元素是init_mm内存描述符,它代表init进程的地址空间。
再往下看,可以看到地址空间几个区(堆栈)对应的变量的定义。
我们再回顾下在内核进程管理中,进程描述符task_struct是在内核空间中缓存,也就是我们上面描述的slab层。
而task_struct中有个mm域指向的就是该进程使用的内存描述符,再通过current->mm便可以指向当前进程的内存描述符。fork函数利用copy_mm()函数就实现了复制父进程的内存描述符,而子进程中的mm_struct结构体实际是通过文件kernel/fork.c中的allocate_mm()宏从mm_cachep slab缓存中分配得到的。通常,每个进程都有唯一的mm_struct结构体。
因为进程描述符和进程的内存描述符都是处于slab层,所以它们元素的分配和释放都由slab分配器来管理。
5.3 虚拟内存区域
内存区域由vm_area_struct结构体描述,见上面的mmap域,内存区域在内核中也经常被称作虚拟内存区域(Virtual Memory Area,VMA)。
它描述了指定地址空间内连续区间上的一个独立内存范围。
内核将每个内存区域作为一个单独的内存对象管理,每个内存区域都拥有一致的属性。结构体如下:
1 struct vm_area_struct { 2 struct mm_struct *vm_mm; /* associated mm_struct */ 3 unsigned long vm_start; /* VMA start, inclusive */ 4 unsigned long vm_end; /* VMA end , exclusive */ 5 struct vm_area_struct *vm_next; /* list of VMA's */ 6 pgprot_t vm_page_prot; /* access permissions */ 7 unsigned long vm_flags; /* flags */ 8 struct rb_node vm_rb; /* VMA's node in the tree */ 9 union { /* links to address_space->i_mmap or i_mmap_nonlinear */ 10 struct { 11 struct list_head list; 12 void *parent; 13 struct vm_area_struct *head; 14 } vm_set; 15 struct prio_tree_node prio_tree_node; 16 } shared; 17 struct list_head anon_vma_node; /* anon_vma entry */ 18 struct anon_vma *anon_vma; /* anonymous VMA object */ 19 struct vm_operations_struct *vm_ops; /* associated ops */ 20 unsigned long vm_pgoff; /* offset within file */ 21 struct file *vm_file; /* mapped file, if any */ 22 void *vm_private_data; /* private data */ 23 };
每个内存描述符都对应于地址进程空间中的唯一区间。vm_mm域指向和VMA相关的mm_struct结构体。
一个内存区域的地址范围是[vm_start, vm_end),vm_next指向该进程的下一个内存区域。
两个独立的进程将同一个文件映射到各自的地址空间,它们分别都会有一个vm_area_struct结构体来标志自己的内存区域;但是如果两个线程共享一个地址空间,那么它们也同时共享其中的所有vm_area_struct结构体。
在上面的vm_flags域中存放的是VMA标志,标志了内存区域所包含的页面的行为和信息。和物理页访问权限不同,VMA标志反映了内核处理页面所需要遵循的行为准则,而不是硬件要求。而且vm_flags同时包含了内存区域中每个页面的消息或者内存区域的整体信息,而不是具体的独立页面。如下表所述:

开头三个标志表示代码在该内存区域的可读、可写和可执行权限。
第四个标志VM_SHARD说明了该区域包含的映射是否可以在多进程间共享,如果被设置了,表示共享映射;否则未被设置,表示私有映射。
其中很多状态在实际使用中都非常有用。
5.4 mmap()和do_mmap():创建地址空间
内核使用do_mmap()函数创建一个新的线性地址空间。但如果创建的地址区间和一个已经存在的地址区间相邻,并且它们具有相同的访问权限的话,那么两个区间将合并为一个。如果不能合并,那么就确实需要创建一个新的vma了,但无论哪种情况,do_mmap()函数都会将一个地址区间加入到进程的地址空间中。这个函数定义在linux/mm.h中,如下
unsigned long do_mmap(struct file *file, unsigned long addr, unsigned long len, unsigned long prot,unsigned long flag, unsigned long offset)
这个函数中由file指定文件,具体映射的是文件中从偏移offset处开始,长度为len字节的范围内的数据,如果file参数是NULL并且offset参数也是0,那么就代表这次映射没有和文件相关,该情况被称作匿名映射(file-backed mapping)。如果指定了文件和偏移量,那么该映射被称为文件映射(file-backed mapping)。
其中参数prot指定内存区域中页面的访问权限:可读、可写、可执行。
flag参数指定了VMA标志,这些标志指定类型并改变映射的行为,请见上一小节。
如果系统调用do_mmap的参数中有无效参数,那么它返回一个负值;否则,它会在虚拟内存中分配一个合适的新内存区域,如果有可能的话,将新区域和临近区域进行合并,否则内核从vm_area_cachep长字节(slab)缓存中分配一个vm_area_struct结构体,并且使用vma_link()函数将新分配的内存区域添加到地址空间的内存区域链表和红黑树中,随后还要更新内存描述符中的total_vm域,然后才返回新分配的地址区间的初始地址。
在用户空间,我们可以通过mmap()系统调用获取内核函数do_mmap()的功能。
5.5 munmap()和do_munmap():删除地址空间
do_mummp()函数从特定的进程地址空间中删除指定地址空间,该函数定义在文件linux/mm.h中,如下:
int do_munmap(struct mm_struct *mm, unsigned long start, size_t len)
第一个参数指定要删除区域所在的地址空间,删除从地址start开始,长度为len字节的地址空间,如果成功,返回0,否则返回负的错误码。
与之相对应的用户空间系统调用是munmap,它是对do_mummp()函数的一个简单封装。
5.6 malloc()的实现
我们知道malloc()是C库中实现的。C库对内存分配的管理还有calloc()、realloc()、free()等函数。
事实上,malloc函数是以brk()或者mmap()系统调用实现的。
brk和sbrk主要的工作是实现虚拟内存到内存的映射。在Linux系统上,程序被载入内存时,内核为用户进程地址空间建立了代码段、数据段和堆栈段,在数据段与堆栈段之间的空闲区域用于动态内存分配。我们回到内存结构mm_struct中的成员变量start_code和end_code是进程代码段的起始和终止地址,start_data和 end_data是进程数据段的起始和终止地址,start_stack是进程堆栈段起始地址,start_brk是进程动态内存分配起始地址(堆的起始地址),还有一个 brk(堆的当前最后地址),就是动态内存分配当前的终止地址。所以C库的malloc()在Linux上的基本实现是通过内核的brk系统调用。brk()是一个非常简单的系统调用,内核再执行sys_brk()函数进行内存分配,只是简单地改变mm_struct结构的成员变量brk的值。而sbrk不是系统调用,是C库函数。系统调用通常提供一种最小功能,而库函数通常提供比较复杂的功能。
下面我们整理一下在进程空间堆中用brk()方式进行动态内存分配的流程:
C库函数malloc()调用Linux系统调用函数brk(),brk()执行系统调用陷入到内核,内核执行sys_brk()函数,sys_brk()函数调用do_brk()进行内存分配
malloc()---------->brk()-----|----->sys_brk()----------->do_brk()------------>vma_merge()/kmem_cache_zalloc()
用户空间------> | 内核空间
系统调用---------->
mmap()系统调用也可以实现动态内存分配功能,即5.4节我们提到的匿名映射。
那什么时候调用brk(),什么时候调用mmap()呢?通过阈值M_MMAP_THRESHOLD来决定。该值默认128KB。可以通过mallopt()来进行修改设置。
所以当需要分配的内存大于该阈值,选择mmap();否则小于等于该阈值,选择brk()分配。
最后,mmap分配的内存在调用munmap后会立即返回给系统,而brk/sbrk而受M_TRIM_THRESHOLD的影响。该环境变量同样通过mallopt()来设置,该值代表的意义是释放内存的最少字节数。
此时,str1和str2的内存只是简单的标记为“未使用”,如果这两处内存是相邻的则会进行合并,这种算法也称为“伙伴内存算法(buddy memory allocation scheme)”。这种算法高速简单,但同时也会生成碎片。包括内碎片(一次分配内存不够整页,最后一页剩下的空间)和外碎片(多次或者反复分配造成中间的空闲页太小不够后续的一次分配)。
从上可以看出,在一定条件下,假如释放了str3的内存,堆的大小是可以紧缩的。
最后我们以一张图结束今天的主题,内存分配流程图:
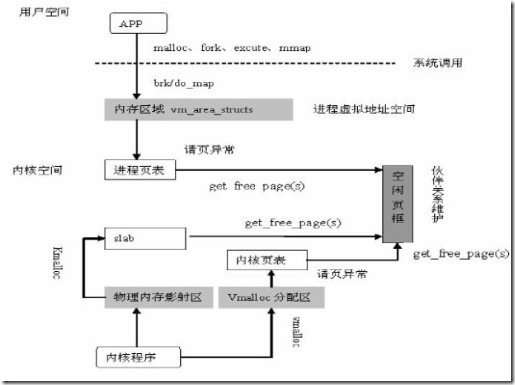
推荐阅读:存储系列之 虚拟内存:分页技术
参考资料:
《Linux内核设计与实现》原书第三版
https://www.cnblogs.com/bizhu/archive/2012/10/09/2717303.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号