LevelDB & RocksDB简介
LevelDB & RocksDB是两种内嵌数据库,从分布式开源库中来,又常用在分布式开源库和分布式系统中。今天主要是转载加整理,好好梳理一下。
一、LevelDB简介
设计思路
LevelDB的数据是存储在磁盘上的,采用LSM-Tree的结构实现。LSM-Tree将磁盘的随机写转化为顺序写,从而大大提高了写速度。为了做到这一点LSM-Tree的思路是将索引树结构拆成一大一小两颗树,较小的一个常驻内存,较大的一个持久化到磁盘,他们共同维护一个有序的key空间。写入操作会首先操作内存中的树,随着内存中树的不断变大,会触发与磁盘中树的归并操作,而归并操作本身仅有批量顺序写。如下图所示:
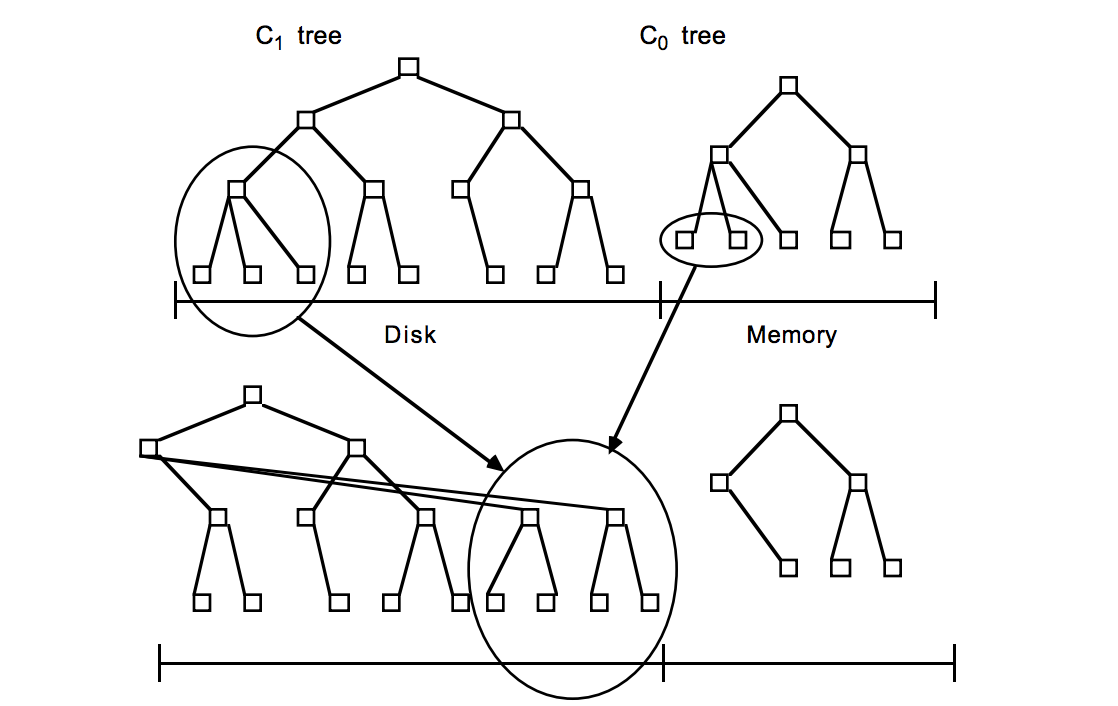
随着数据的不断写入,磁盘中的树会不断膨胀,为了避免每次参与归并操作的数据量过大,以及优化读操作的考虑,LevelDB将磁盘中的数据又拆分成多层,每一层的数据达到一定容量后会触发向下一层的归并操作,每一层的数据量比其上一层成倍增长。这也就是LevelDB的名称来源。
整体结构
具体到代码实现上,LevelDB有几个重要的角色,包括内存数据的Memtable,分层数据存储的SST文件,版本控制的Manifest、Current文件,以及写Memtable前的WAL。这里简单介绍各个组件的作用和在整个结构中的位置。

-
Memtable:内存数据结构,跳表实现,新的数据会首先写入这里;
-
Log文件:Commit Log,也称为提交日志。写Memtable前会先写Log文件,Log通过append的方式顺序写入。Log的存在使得机器宕机导致的内存数据丢失得以恢复;
-
Immutable Memtable:达到Memtable设置的容量上限后,Memtable会变为Immutable为之后向SST文件的归并做准备,顾名思义,Immutable Mumtable不再接受用户写入,同时会有新的Memtable生成;
-
SST文件:磁盘数据存储文件。分为Level 0到Level N多层,每一层包含多个SST文件;单层SST文件总量随层次增加成倍增长;文件内数据有序;其中Level0的SST文件由Immutable直接Dump产生,其他Level的SST文件由其上一层的文件和本层文件归并产生;SST文件在归并过程中顺序写生成,生成后仅可能在之后的归并中被删除,而不会有任何的修改操作。
-
Manifest文件: 清单文件。SSTable中的文件时按照记录的主键排序的,每个文件有最小的主键和最大的主键。清单文件记录这些元数据,包括属于哪个层级、文件名称、最小主键和最大主键。
-
Current文件: 当前文件记录了当前的清单文件名,即当前的Manifest,而Manifest可能有多个。
总之,当写入一个key-value的时候,首先写入log文件中,然后才会写入memtable中,然后当memtable到达一定程度时,然后转变成Immutable memtable,系统此时会重新创建新的memtable用于插入数据。然后Immutable memtable通过压缩数据存储到磁盘SSTable中。
合并Compaction
LevelDB写入操作简单,但是读取操作比较复杂,需要在内存以及各个层级文件中按照从新到老依次查找,代价很高。为了加快读取速度, LevelDB内部执行Compaction操作来对已有的记录进行整理压缩,从而删除一些不再有效的记录,减少数据规模和文件数量。
Compaction分为两种。
Minor Compaction是指当内存中的MemTable大小到一定值时,将内存数据转储dump到SSTable中。
Major Compaction是指每个层级下有多个SSTable,当某个层级下的SSTable文件数目超过一定设置后, LevelDB会从这个层级中选择SSTable文件,将和高一级的SSTable文件进行合并。相当于执行多路归并:按照主键顺序依次迭代出所有SSTable文件中的记录,如果没有保存价值则直接丢掉,否则将其写入到新生成的SSTable文件中。
LevelDB 特点
1) LevelDB是一个持久化存储的KV系统,和Redis这种内存型的KV系统不同,LevelDB不会像Redis一样狂吃内存,而是将大部分数据存储到磁盘上。
2) LevleDB在存储数据时,是根据记录的key值有序存储的,就是说相邻的key值在存储文件中是依次顺序存储的,而应用可以自定义key大小比较函数。
3) LevelDB支持数据快照(snapshot)功能,使得读取操作不受写操作影响,可以在读操作过程中始终看到一致的数据。
4) LevelDB还支持数据压缩等操作,这对于减小存储空间以及增快IO效率都有直接的帮助。
二、RocksDB简介
Levledb是Google的两位Fellow (Jeaf Dean和Sanjay Ghemawat)设计和开发的嵌入式K-V系统,读写性能非常彪悍,官方网站报道其写性能40万/s,读性能达到6万/s,写操作要远快于读操作。Rocksdb是Facebook公司在Leveldb基础之上开发的一个嵌入式K-V系统,在很多方面对Leveldb做了优化和增强,更像是一个完整的产品,比如:
1)Leveldb是单线程合并文件,Rocksdb可以支持多线程合并文件,充分利用多核的特性,加快文件合并的速度,避免文件合并期间引起系统停顿;
LSM型的数据结构,最大的性能问题就出现在其合并的时间损耗上,在多CPU的环境下,多线程合并那是LevelDB所无法比拟的。不过据其官网上的介绍,似乎多线程合并还只是针对那些与下一层没有Key重叠的文件,只是简单的rename而已,至于在真正数据上的合并方面是否也有用到多线程,就只能看代码了。
RocksDB增加了合并时过滤器,对一些不再符合条件的K-V进行丢弃,如根据K-V的有效期进行过滤。
2)Leveldb只有一个Memtable,若Memtable满了还没有来得及持久化,则会减缓Put操作引起系统停顿;RocksDB支持管道式的Memtable,也就说允许根据需要开辟多个Memtable,以解决Put与Compact速度差异的性能瓶颈问题。
3)Leveldb只能获取单个K-V;Rocksdb支持一次获取多个K-V,还支持Key范围查找。
4)Levledb不支持备份;Rocksdb支持全量和增量备份。RocksDB允许将已删除的数据备份到指定的目录,供后续恢复。
5)压缩方面RocksDB可采用多种压缩算法,除了LevelDB用的snappy,还有zlib、bzip2。LevelDB里面按数据的压缩率(压缩后低于75%)判断是否对数据进行压缩存储,而RocksDB典型的做法是Level 0-2不压缩,最后一层使用zlib,而其它各层采用snappy。
6)RocksDB除了简单的Put、Delete操作,还提供了一个Merge操作,说是为了对多个Put操作进行合并,优化了modify的效率。站在引擎实现者的角度来看,相比其带来的价值,其实现的成本要昂贵很多。个人觉得有时过于追求完美不见得是好事,据笔者所测(包括测试自己编写的引擎),性能的瓶颈其实主要在合并上,多一次少一次Put对性能的影响并无大碍。
7)RocksDB提供一些方便的工具,这些工具包含解析sst文件中的K-V记录、解析MANIFEST文件的内容等。有了这些工具,就不用再像使用LevelDB那样,只能在程序中才能知道sst文件K-V的具体信息了。
8)其他优化:增加了column family,这样有利于多个不相关的数据集存储在同一个db中,因为不同column family的数据是存储在不同的sst和memtable中,所以一定程度上起到了隔离的作用。将flush和compaction分开不同的线程池,能有效的加快flush,防止stall拖延停顿。增加了对write ahead log(WAL)的特殊管理机制,这样就能方便管理WAL文件,因为WAL是binlog文件。
RocksDB的典型场景(低延时访问)
1)需要存储用户的查阅历史记录和网站用户的应用
2)需要快速访问数据的垃圾检测应用
3)需要实时scan数据集的图搜索query
4)需要实时请求Hadoop的应用
5)支持大量写和删除操作的消息队列
虽然说Rocksdb底层支持HDFS,数据可以多副本存储,但是前端没有分片,仍然无法满足分布式系统的可扩展要求。
实际中,可以将Levledb或者Rocksdb作为数据存储系统引擎,在其上面实现分片和多副本,从而实现一个真正的分布式存储系统,例如微信开源的PaxosStore,默认就是以Rocksdb作为其某个副本的存储介质,上层通过Paxos协议来保证副本之间的数据一致性。
相比LevelDB是不是觉得RocksDB彪悍的不可思议。但是虽然RocksDB在性能上提升了不少,在文件存储格式上跟LevelDB还是没什么变化的, 稍微有点更新的只是RocksDB对原来LevelDB中sst文件预留下来的MetaBlock进行了具体利用。
个人(参考资料4)觉得RocksDB尚未解决的地方:
- 依然是完全依赖于MANIFEST,一当该文件丢失,则整个数据库基本废掉。
- 合并上依然是整个文件载入,一些没用的Value将被多次的读入内存,如果这些Value很大的话,那没必要的内存占用将是一个可观的成本。
参考资料:
1.《大规模分布式存储系统原理解析与架构实战》
2.http://catkang.github.io/2017/01/07/leveldb-summary.html 有四篇关于LevelDB的文档。
3.https://www.zhihu.com/question/351366744/answer/862704911
4.https://blog.csdn.net/tzdjzs/article/details/20838945
5.https://blog.csdn.net/weixin_43618070/article/details/102317769
6.LSM简介


 浙公网安备 33010602011771号
浙公网安备 33010602011771号