
1. JMM简介:
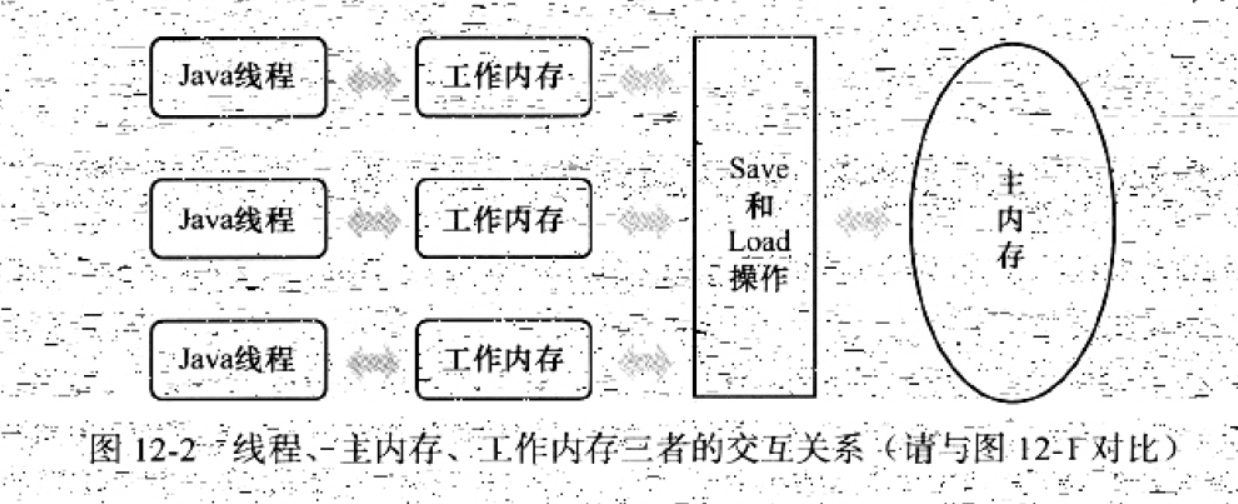
JMM表示了主内存和工作内存之间的关系:
1. 主内存:只有一份,保存着所有变量。
即计算机内存条、即堆
2. 线程的工作内存:每线程都有一份且对其他线程不可见,保存着从主存中的变量的副本(其实是变量的引用)。
即计算机单核CPU的寄存器+单核CPU的高速缓存、即栈
3. 线程通信(线程之间变量的传递),需要工作内存(CPU)——>主内存——>工作内存(CPU)
2. 高速缓存:
因为cpu速度远远大于内存速度,为了不让CPU从主存中读写数据,所以产生了高速(多级)缓存,CPU计算之后从高速(多级)缓存将结果写入主存中。
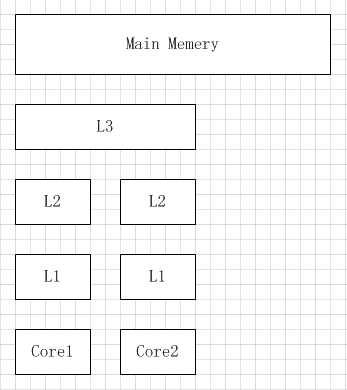
CPU查找顺序依次是L1、L2、L3、主存。
其中L1是L2的子集,L2是L3的子集,L1到L3缓存容量依次增大,查找耗时依次增大。
L1与CPU core对应,是单核独占的,不会出现其他核修改的问题。一般L2也是单核独占。而L3在同插槽的所有CPU共享的,有可能操作同一份数据。
3. 伪共享:
3.1 伪共享的概念:
高速缓存是以缓存行(cacheline)为单位存储的。
最常见的缓存行大小是64个字节(32位CPU就是32字节?),并且它有效地引用主内存中的一块地址。
一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。
所以,如果你访问一个 long 数组,当数组中的一个值被加载到缓存中,它会额外加载另外 7 个,以致你能非常快地遍历这个数组。
而如果你在数据结构中的项在内存中不是彼此相邻的(如链表),你将得不到免费缓存加载所带来的优势,并且在这些数据结构中的每一个项都可能会出现缓存未命中。
如果存在这样的场景,有多个线程操作不同的成员变量,但是相同的缓存行,这个时候会发生什么?。没错,伪共享(False Sharing)问题就发生了!
伪共享:如果多个核的线程在操作同一个缓存行中的不同变量数据,那么就会出现频繁的缓存失效,
这种不合理的资源竞争情况学名伪共享(False Sharing),会严重影响机器的并发执行效率。
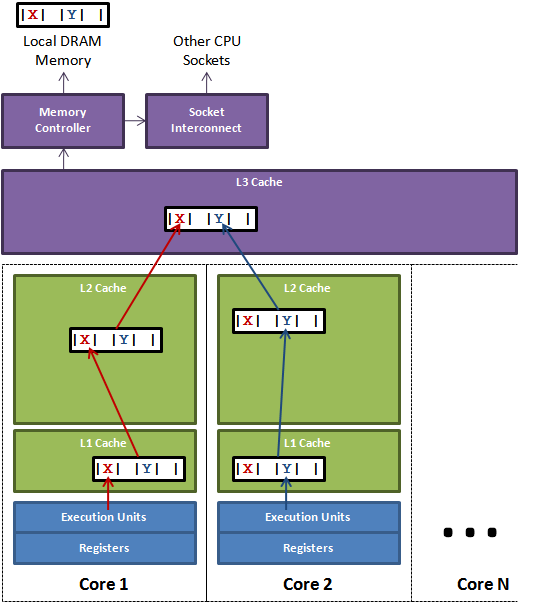
3.2 伪共享缺点场景:
上图中,一个运行在处理器 core1上的线程想要更新变量 X 的值,同时另外一个运行在处理器 core2 上的线程想要更新变量 Y 的值。
但是,这两个频繁改动的变量都处于同一条缓存行。
两个线程就会轮番发送 RFO 消息,占得此缓存行的拥有权。
当 core1 取得了拥有权开始更新 X,则 core2 对应的缓存行需要设为 I 状态。
当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。
轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上可能都是失效数据,所以就会从L3 缓存甚至是主存读取数据,很慢。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
3.3 对象占用的空间:
64位系统环境下,默认开启压缩-XX:+UseCompressedOops:
对象占用空间 =
对象头(
Mark Word (32位JVM,4字节)(64位JVM,8字节)
+ Klass指针 (32位JVM,4字节)(64位JVM,8字节)(64位JVM && 默认开启压缩-XX:+UseCompressedOops,4字节)
+ Array length (固定为4字节,因为数组最大长度是int最大值)
)
(Klass指针的大小根据是否开启压缩而定-XX:+UseCompressedOops)
+ 实例数据(
对象内部的基本类型属性:根据其大小而定比如 int=4字节 。byte 1;boolean 1;char 2;short 2;int 4;float 4;long 8;double 8
+ 对象内部的引用类型属性:只需要占用其 Klass指针部分即可( 即4字节或者8字节)
)
+ 对齐填充(
补齐为8字节的倍数
)
3.4 伪共享的解决
伪共享常用解决方式1:
写代码手动填充。(目前好像都是对Long的填充)
先计算好对象占用的空间(对象头+实例数据+对齐填充),然后再加几个属性填充成64字节甚至是128字节(看需求而定
伪共享常用解决方式2:
类名用@Contended注释。
内部的实现应该是占用了128字节。
伪共享解决方式的应用:
ConcurrentHashMap的CounterCell

 浙公网安备 33010602011771号
浙公网安备 33010602011771号