
EF如何操作内存中的数据以及加载相关联表的数据:延迟加载、贪婪加载、显示加载
之前的EF Code First系列讲了那么多如何配置实体和数据库表的关系,显然配置只是辅助,使用EF操作数据库才是每天开发中都需要用的,这个系列讲讲如何使用EF操作数据库。老版本的EF主要是通过ObjectContext来操作数据库的,一看是Object打头的,自然相当庞大,方法也比较多。到了经典的4.1版本,EF小组推出了一些更简单好用的API,就是DbContext,它包括更常用的方法。看看EF小组是怎么说的,原话:
The Entity Framework 4.1 release also included another important feature, called the DbContext API. DbContext is the core of this API, which also contains other dependent classes. DbContext is a
lighter-weight version of the Entity Framework’s ObjectContext. It is
a wrapper over ObjectContext, and it exposes only those
features that Microsoft found were most commonly used by developers
working with Entity Frame-work. The DbContext also provides simpler
access to coding patterns that are more complex to achieve with the
ObjectContext. DbContext also takes care of a lot of common tasks for
you, so that you write less code to achieve the same tasks; this is
particularly true when working with Code First. Because Microsoft
recommends that you use DbContext with Code First。
继续补充下知识,看看DBContext的一些新特性:
一、EF DbContext 小试牛刀
系列文章开始的时候提示大家,必须学会且习惯使用sql Profiler(开始 - 程序 - Microsoft SQL Server 2008 - 性能工具 - Sql Server Profiler),它可以监控到ef生成的sql是什么样子的,这不仅可以帮助我们更好的学习EF的API,也可以监测写出来的EF方法效率如何。好的,废话不多说了,先上解决方案图:

本章节要操作的两个实体分别:
/// <summary> /// 景点类 /// </summary> [Table("Locations", Schema = "baga")] //生成的表名:baga.Locations public class Destination { public Destination() { this.Lodgings = new List<Lodging>(); } [Column("LocationID")] public int DestinationId { get; set; } [Required, Column("LocationName")] [MaxLength(200)] public string Name { get; set; } public string Country { get; set; } [MaxLength(500)] public string Description { get; set; } [Column(TypeName = "image")] public byte[] Photo { get; set; } public string TravelWarnings { get; set; } public string ClimateInfo { get; set; } public List<Lodging> Lodgings { get; set; } }
/// <summary> /// 住宿类 /// </summary> public class Lodging { public int LodgingId { get; set; } [Required] [MaxLength(200)] [MinLength(10)] public string Name { get; set; } public string Owner { get; set; } public decimal MilesFromNearestAirport { get; set; } [Column("destination_id")] public int DestinationId { get; set; } public Destination Destination { get; set; } }
实体不再做过多的介绍了,上个系列讲的很详细了。实体都是通过Data Annotation配置映射的,还不是很了解Data Anntation的看这里。
程序跑起来InitializeDBWithSeedData类会添加了一些测试数据到数据库中。ok,先小试下牛刀,添加一个方法PrintAllDestinations在控制台上打印出所有景点:
/// <summary> /// 查出所有景点 /// </summary> private static void PrintAllDestinations() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { foreach (var destination in context.Destinations) { Console.WriteLine(destination.Name); } } }
查出来的结果自然就是所有的景点类的名称:
Grand Canyon
Hawaii
Wine Glass Bay
Great Barrier Reef
如果按照以往手写ado的方式的话,要出来上面的结果得先select * from baga.Locations表,然后用dataTable存下结果集,再遍历dataTable才能拿到所有景点的名称;当然也可以用sqlDataReader的方式一行一行读取。随便一写就是几十行了。EF只要一行。再按照景点的名称排序下:
/// <summary> /// 按照名称排序 /// </summary> private static void PrintAllDestinationsSorted() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var query = from d in context.Destinations orderby d.Name select d; foreach (var destination in query) { Console.WriteLine(destination.Name); } } }
当然,查出来的数据也就是排序了的:
Grand Canyon
Great Barrier Reef
Hawaii
Wine Glass Bay
很简单,就是普通的linq写法,当然也有C# Lambda表达式的写法(文章结尾提供的源码里有)。下面的方法使用Find方法查询数据库:
/// <summary> /// Find方法查询数据库 /// </summary> private static void FindDestination() { Console.Write("Enter id of Destination to find: "); var id = int.Parse(Console.ReadLine()); using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var destination = context.Destinations.Find(id); if (destination == null) { Console.WriteLine("Destination not found!"); } else { Console.WriteLine(destination.Name); } } }
EF的find方法是先从内存中查询,内存中没有才查询数据库。为了演示添加一个方法:
/// <summary> /// 测试Find方法查询内存中的数据 /// </summary> private static void TestFindLocalData() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var query = from d in context.Destinations where d.Name == "Great Barrier Reef" select d; query.Load(); //加载名称为Great Barrier Reef的景点到内存中 Console.WriteLine(context.Destinations.Local.Count); //输出内存中的数据个数 var destination = context.Destinations.Find(4); if (destination == null) Console.WriteLine("Destination not found!"); else Console.WriteLine(destination.Name); } }
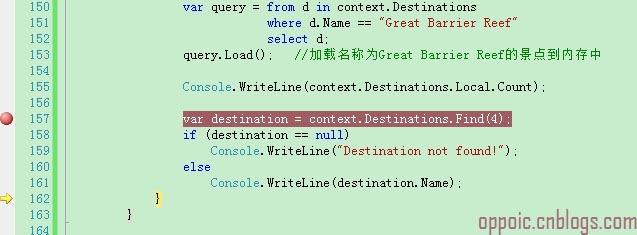
先从数据库加载Name为Great Barrier Reef的景点(destinationId为4)到内存中,然后调用find方法找4号destinationId,看看sql Profiler监控到的sql:

可见,程序跑完了也只有一条查询Name是Great Barrier Reef的sql,并没有发送查询destinationId为4的sql。destinationId为4的记录就是加载到内存中Name是Great Barrier Reef的记录,很明显,Find方法查询的是内存,内存中有就用内存中的。继续,使用Single方法查询单个实体:
/// <summary> /// 获取一个实体对象(Single) /// </summary> private static void FindGreatBarrierReef() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var query = from d in context.Destinations where d.Name == "Great Barrier Reef" select d; var reef = query.Single(); //差不到记录或者多条记录就报错 Console.WriteLine(reef.Description); } }
Single方法不太好用,不管是查不到记录还是查到多条记录都会抛错;使用SingleOrDefault方法,如果查不到记录就返回null,查到多条记录也会报错:
/// <summary> /// 获取一个实体对象(SingleOrDefault) /// </summary> private static void FindGreatBarrierReef() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var query = from d in context.Destinations where d.Name == "Great Barrier Reef" select d; var reef = query.SingleOrDefault(); if (reef == null) Console.WriteLine("Can't find the reef!"); else Console.WriteLine(reef.Description); } }
使用sql Profiler监控到如下sql被发送到了数据库。虽然是查一条记录,但是会Select TOP 2,这是为了肯定有一条满足的记录。
SELECT TOP (2) [Extent1].[LocationID] AS [LocationID], [Extent1].[LocationName] AS [LocationName], [Extent1].[Country] AS [Country], [Extent1].[Description] AS [Description], [Extent1].[Photo] AS [Photo], [Extent1].[TravelWarnings] AS [TravelWarnings], [Extent1].[ClimateInfo] AS [ClimateInfo] FROM [baga].[Locations] AS [Extent1] WHERE N'Great Barrier Reef' = [Extent1].[LocationName]
二、操作内存中的数据
不同于普通的ado.net写sql直接去库里取数据。EF还提供了从内存中取数据的方式,当然内存中的数据也是从数据库先取出来的。如上的查询写法都会发送数据到数据库查询数据,如果“Great Barrier Reef”这条数据是新标记添加但是还没插入数据库(没有调用上下文的saveChanges方法),那么如上查询都查不到数据(当然find方法是可以的,上面介绍了),需要在内存中查询(Querying Local Data)。为了演示,使用SingleOrDefault方法做个试验:
/// <summary> /// 测试查询新标记添加但是没被插入数据库的数据 /// </summary> private static void TestGetNewAddedData() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var destination = new DbContexts.Model.Destination { Name = "bingmayong", Country = "China", Description = "too boring~~~~~~" }; context.Destinations.Add(destination); //标记添加新实体,还没有调用SaveChanges方法提交到数据库 var query = from d in context.Destinations where d.Name == "bingmayong" select d; var reef = query.SingleOrDefault(); //查询Name是刚才添加的兵马俑的对象 if (reef == null) Console.WriteLine("Can't find the reef!"); else Console.WriteLine(reef.Description); context.SaveChanges(); //调用SaveChanges方法,添加才会被插入数据库 } }
输出结果:

结果显示找不到新添加的景点,但是程序跑完了,它明明在数据库里了。很明显不调用SaveChanges方法的时候,所有标记添加、删除、修改的数据都是在内存中的。SingleOrDefault方法就是直接去数据库取数据的,当然Find方法直接就可以撸出内存中的数据,内存中没有再去库里找。其他方法请自行查询官方API或者自己试验,这里不做过多演示了。继续介绍一些方法:
/// <summary> /// 查询内存中的数据 /// </summary> private static void GetLocalDestinationCount() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var count = context.Destinations.Local.Count; Console.WriteLine("Destinations in memory: {0}", count); } }
输出结果:Destinations in memory: 0 可见并没有去查询数据库,直接查的内存中的数据。直接用sql profiler跟踪下,也没有任何查询的sql发送到数据库。测试下查询数据库的:
/// <summary> /// 先加载数据库再查询本地数据 /// </summary> private static void GetLocalDestinationCountAfterCheckDB() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { foreach (var destination in context.Destinations) { Console.WriteLine(destination.Name); } var count = context.Destinations.Local.Count; Console.WriteLine("Destinations in memory: {0}", count); } }
这样就把所有数据都打印出来了,并且输出count值是4,正如预期,先把数据库中的值拿到Local本地,再输出count值。使用sql profiler跟踪到的sql:
SELECT [Extent1].[LocationID] AS [LocationID], [Extent1].[LocationName] AS [LocationName], [Extent1].[Country] AS [Country], [Extent1].[Description] AS [Description], [Extent1].[Photo] AS [Photo], [Extent1].[TravelWarnings] AS [TravelWarnings], [Extent1].[ClimateInfo] AS [ClimateInfo] FROM [baga].[Locations] AS [Extent1]
这种使用foreach遍历数据把数据加载到内存的方式有点不妥,不可能每次都先遍历把数据拿到内存中再操作,改用Load方法试试:
/// <summary> /// Load方法把数据加载到内存 /// </summary> private static void GetLocalDestinationCountWithLoad() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { context.Destinations.Load(); var count = context.Destinations.Local.Count; Console.WriteLine("Destinations in memory: {0}", count); } }
count值一样是4,产生的sql也跟上一个方法一模一样,但是Load方法还是比较实用的。linq写法是这样的:
/// <summary> /// Load方法把数据加载到内存(LINQ写法) /// </summary> private static void LoadAustralianDestinations() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var query = from d in context.Destinations where d.Country == "Australia" select d; query.Load(); var count = context.Destinations.Local.Count; Console.WriteLine("Aussie destinations in memory: {0}", count); } }
那么把数据加载到内存中有什么好处呢?上方法:
/// <summary> /// 操作内存中的数据 /// </summary> private static void LocalLinqQueries() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { context.Destinations.Load(); var sortedDestinations = from d in context.Destinations.Local orderby d.Name select d; Console.WriteLine("All Destinations:"); foreach (var destination in sortedDestinations) { Console.WriteLine(destination.Name); } var aussieDestinations = from d in context.Destinations.Local where d.Country == "Australia" select d; Console.WriteLine(); Console.WriteLine("Australian Destinations:"); foreach (var destination in aussieDestinations) { Console.WriteLine(destination.Name); } } }
先使用Load方法把Destination表的数据全部加载到内存中,然后在内存中排序并输出;再在内存中已经排序的数据里查出Country为Australia的数据。整个过程操作和输出数据多次,但是只查询了一次数据库。这就是操作内存中的数据的好处。好处归好处,但是不好的地方也很明显,操作内存中的数据,新添加、删除或者修改的数据,先前加载到内存中的数据就跟数据库里的不一致了。这里可以使用CollectionChanged事件来监控,内存中的数据增删改都会触发这个事件:
/// <summary> /// 监控内存中数据的变化 /// </summary> private static void ListenToLocalChanges() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { context.Destinations.Local.CollectionChanged += (sender, args) => { if (args.NewItems != null) { foreach (DbContexts.Model.Destination item in args.NewItems) { Console.WriteLine("Added: " + item.Name); } } if (args.OldItems != null) { foreach (DbContexts.Model.Destination item in args.OldItems) { Console.WriteLine("Removed: " + item.Name); } } }; context.Destinations.Load(); } }
在把Destination表的数据加载到内存前,监控了下CollectionChanged,打印结果是:
Added: Grand Canyon
Added: Hawaii
Added: Wine Glass Bay
Added: Great Barrier Reef
正如预期,都是添加到内存中,没有删除。实际开发中,可以多多利用CollectionChanged事件来监控内存中数据的状态。
三、加载关联表数据(Loading Related Data)
加载关联表数据就是加载主表数据的同时加载出和主表有外键关系的从表数据。项目中的表不可能都是单独的表,肯定都是存在一定主外键关系的,以往写ado的时候都是根据主表的主键去从表里查和其关联的数据,稍显笨拙。EF为提供了三种方式加载从表数据,写法不同生成的sql也不同,当然效率也不同。分别是:延迟加载、贪婪加载、显示加载:
1.延迟加载(Lazy Loading)
/// <summary> /// 延迟加载LazyLoading /// </summary> private static void TestLazyLoading() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var query = from d in context.Destinations where d.Name == "Grand Canyon" select d; var canyon = query.Single(); Console.WriteLine("Grand Canyon Lodging:"); if (canyon.Lodgings != null) { foreach (var lodging in canyon.Lodgings) { Console.WriteLine(lodging.Name); } } } }
类似使用主表对象打点调用从表的方式都是延迟加载(canyon.Lodgings)。上面的方法意思就是先去主表baga.Locations表里找Name值是Grand Canyon的对象,然后去从表Lodgings表里找destination_id等于这个对象的LocationID的数据。输入结果:
Grand Canyon Lodging:
Grand Hotel
Dave's Dump
注:使用延迟加载必须标注为virtual。本例是标注Destination类里的Lodgings为virtual:
public virtual List<Lodging> Lodgings { get; set; } //virtual 延迟加载
监控到的两段sql是:
SELECT TOP (2) [Extent1].[LocationID] AS [LocationID], [Extent1].[LocationName] AS [LocationName], [Extent1].[Country] AS [Country], [Extent1].[Description] AS [Description], [Extent1].[Photo] AS [Photo], [Extent1].[TravelWarnings] AS [TravelWarnings], [Extent1].[ClimateInfo] AS [ClimateInfo] FROM [baga].[Locations] AS [Extent1] WHERE N'Grand Canyon' = [Extent1].[LocationName]
exec sp_executesql N'SELECT [Extent1].[LodgingId] AS [LodgingId], [Extent1].[Name] AS [Name], [Extent1].[Owner] AS [Owner], [Extent1].[MilesFromNearestAirport] AS [MilesFromNearestAirport], [Extent1].[destination_id] AS [destination_id], [Extent1].[PrimaryContactId] AS [PrimaryContactId], [Extent1].[SecondaryContactId] AS [SecondaryContactId] FROM [dbo].[Lodgings] AS [Extent1] WHERE [Extent1].[destination_id] = @EntityKeyValue1',N'@EntityKeyValue1 int',@EntityKeyValue1=1
看到生成的sql就很明显的知道为何叫这种加载方式为延迟加载了吧。因为先发sql去查询主键对象,然后根据主键id去从表里查相关联的数据。以往写ado都是分两步写的,EF只需要一行。
但是延迟加载并不是那么美好,不恰当的使用会发送很多多余的sql到数据库:比如从数据库取Destioation表的50条记录遍历的时候打点调用了Lodging表的数据,这就使用了延迟加载,会发送了一条sql取50条Destination表数据,同时随着遍历会分别发送50条分别取Lodging表数据。这种情况使用join连表查询显然比延迟加载有效率的多。关闭延迟加载有两种方式:
1.去掉virtual;
2.context.Configuration.LazyLoadingEnabled =false;
2.贪婪加载(Eager Loading)
/// <summary> /// 贪婪加载EagerLoading /// </summary> private static void TestEagerLoading() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var allDestinations = context.Destinations.Include(d => d.Lodgings); foreach (var destination in allDestinations) { Console.WriteLine(destination.Name); foreach (var lodging in destination.Lodgings) { Console.WriteLine(" - " + lodging.Name); } } } }
很明显,使用了Include,加载Destination主表的所有数据并贪婪加载出了所有相关联的从表数据。输出结果:
Grand Canyon
- Grand Hotel
- Dave's Dump
Hawaii
Wine Glass Bay
Great Barrier Reef
只有一条sql被发送到了数据库:


SELECT [Project1].[LocationID] AS [LocationID], [Project1].[LocationName] AS [LocationName], [Project1].[Country] AS [Country], [Project1].[Description] AS [Description], [Project1].[Photo] AS [Photo], [Project1].[TravelWarnings] AS [TravelWarnings], [Project1].[ClimateInfo] AS [ClimateInfo], [Project1].[C1] AS [C1], [Project1].[LodgingId] AS [LodgingId], [Project1].[Name] AS [Name], [Project1].[Owner] AS [Owner], [Project1].[MilesFromNearestAirport] AS [MilesFromNearestAirport], [Project1].[destination_id] AS [destination_id], [Project1].[PrimaryContactId] AS [PrimaryContactId], [Project1].[SecondaryContactId] AS [SecondaryContactId] FROM ( SELECT [Extent1].[LocationID] AS [LocationID], [Extent1].[LocationName] AS [LocationName], [Extent1].[Country] AS [Country], [Extent1].[Description] AS [Description], [Extent1].[Photo] AS [Photo], [Extent1].[TravelWarnings] AS [TravelWarnings], [Extent1].[ClimateInfo] AS [ClimateInfo], [Extent2].[LodgingId] AS [LodgingId], [Extent2].[Name] AS [Name], [Extent2].[Owner] AS [Owner], [Extent2].[MilesFromNearestAirport] AS [MilesFromNearestAirport], [Extent2].[destination_id] AS [destination_id], [Extent2].[PrimaryContactId] AS [PrimaryContactId], [Extent2].[SecondaryContactId] AS [SecondaryContactId], CASE WHEN ([Extent2].[LodgingId] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C1] FROM [baga].[Locations] AS [Extent1] LEFT OUTER JOIN [dbo].[Lodgings] AS [Extent2] ON [Extent1].[LocationID] = [Extent2].[destination_id] ) AS [Project1] ORDER BY [Project1].[LocationID] ASC, [Project1].[C1] ASC
大家可能注意到了,上面的方法遍历的时候好像也使用了延迟加载(destination.Lodgings),但是按照上面关闭延迟加载的方法去掉virtual,跑下程序结果还是一样也能拿到从表数据,为何?我猜测是上面的Include方法已经拿到了主表和从表的所有数据(参考上面生成的sql),这个时候再.Lodgings就是从内存中拿的从表数据了,并未去数据库查询。
贪婪加载是很灵活的,可以写下如下贪婪加载,具体请自行调试和跟踪:
var AustraliaDestination = context.Destinations.Include(d => d.Lodgings).Where(d => d.Country == "Australia"); context.Lodgings.Include(l => l.PrimaryContact.Photo); context.Destinations.Include(d => d.Lodgings.Select(l => l.PrimaryContact)); context.Lodgings.Include(l => l.PrimaryContact).Include(l => l.SecondaryContact);
当然贪婪加载也有它不好的地方:看上面生成的sql自然就知道了,虽然贪婪加载生成的sql不多只有一条,但是随着我们贪婪加载的从表越多,生成的join也就越复杂,迟早有一个连自己都看不懂的嵌套join查询摆在面前让你崩溃。当然越复杂也就越耗费性能,这是明显的。
3.显示加载(Explicit Loading)
/// <summary> /// 显示加载ExplicitLoading /// </summary> private static void TestExplicitLoading() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var query = from d in context.Destinations where d.Name == "Grand Canyon" select d; var canyon = query.Single(); context.Entry(canyon).Collection(d => d.Lodgings).Load(); Console.WriteLine("Grand Canyon Lodging:"); foreach (var lodging in canyon.Lodgings) { Console.WriteLine(lodging.Name); } } }
跟延迟加载一样,主表从表数据分开加载,但是显示加载又几个好处:不需要标记virtual了;生成的sql更加清晰明白。跟踪到的sql:
SELECT TOP (2) [Extent1].[LocationID] AS [LocationID], [Extent1].[LocationName] AS [LocationName], [Extent1].[Country] AS [Country], [Extent1].[Description] AS [Description], [Extent1].[Photo] AS [Photo], [Extent1].[TravelWarnings] AS [TravelWarnings], [Extent1].[ClimateInfo] AS [ClimateInfo] FROM [baga].[Locations] AS [Extent1] WHERE N'Grand Canyon' = [Extent1].[LocationName]
exec sp_executesql N'SELECT [Extent1].[LodgingId] AS [LodgingId], [Extent1].[Name] AS [Name], [Extent1].[Owner] AS [Owner], [Extent1].[MilesFromNearestAirport] AS [MilesFromNearestAirport], [Extent1].[destination_id] AS [destination_id], [Extent1].[PrimaryContactId] AS [PrimaryContactId], [Extent1].[SecondaryContactId] AS [SecondaryContactId] FROM [dbo].[Lodgings] AS [Extent1] WHERE [Extent1].[destination_id] = @EntityKeyValue1',N'@EntityKeyValue1 int',@EntityKeyValue1=1
两条查询,先查主表,再查出从表数据。其实生成的sql和查出来的结果都和延迟加载一模一样,我个人更喜欢显示加载。结果:
Grand Canyon Lodging:
Grand Hotel
Dave's Dump
大家可能注意到了,显示加载使用的是Entry方法,贪婪加载是Include。Entry方法中文意思为“进入”,通俗点理解就是先进入一个实体,然后打点调用各种方法。Entry配合使用Reference和Collection方法,分别是查询单个实例和整个集合的数据。下面是一条查询单个实例的方法:
var lodging = context.Lodgings.First(); context.Entry(lodging).Reference(l => l.PrimaryContact).Load();
当然也可以使用IsLoaded方法判断相关联的从表数据是否已经从数据库加载出来了:
/// <summary> /// IsLoaded方法判断数据是否加载 /// </summary> private static void TestIsLoaded() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var canyon = (from d in context.Destinations where d.Name == "Grand Canyon" select d).Single(); var entry = context.Entry(canyon); Console.WriteLine("Before Load: {0}", entry.Collection(d => d.Lodgings).IsLoaded); entry.Collection(d => d.Lodgings).Load(); Console.WriteLine("After Load: {0}", entry.Collection(d => d.Lodgings).IsLoaded); } }
输出结果:
Before Load: False
After Load: True
IsLoaded方法有何意义呢?官方给出的解释:
If you are performing an explicit load, and the contents of the navigation property may
have already been loaded, you can use the IsLoaded flag to determine if the load is
required or not.
意思就是:IsLoaded方法判断从表数据是否已经加载了。很明显,适当使用IsLoaded方法也可以提高写EF方法的效率。
如上的各种加载方式等都是通过EF或者linq的形式把数据加载到了内存中,然后再进行排序,筛选等操作,最后展示到界面上的。来看一个方法:
/// <summary> /// 在内存中操作 /// </summary> private static void QueryLodgingDistance() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var canyonQuery = from d in context.Destinations where d.Name == "Grand Canyon" select d; var canyon = canyonQuery.Single(); var distanceQuery = from l in canyon.Lodgings where l.MilesFromNearestAirport <= 10 select l; foreach (var lodging in distanceQuery) { Console.WriteLine(lodging.Name); } } }
这个方法很简单,意思就是先查出Name为Grand Canyon的Destination,然后去查出从表Lodging里距离最近机场不到10公里的住宿的地方,最后遍历输出。很明显使用了延迟加载(canyon.Lodgings),生成的sql:
exec sp_executesql N'SELECT [Extent1].[LodgingId] AS [LodgingId], [Extent1].[Name] AS [Name], [Extent1].[Owner] AS [Owner], [Extent1].[MilesFromNearestAirport] AS [MilesFromNearestAirport], [Extent1].[destination_id] AS [destination_id], [Extent1].[PrimaryContactId] AS [PrimaryContactId], [Extent1].[SecondaryContactId] AS [SecondaryContactId] FROM [dbo].[Lodgings] AS [Extent1] WHERE [Extent1].[destination_id] = @EntityKeyValue1',N'@EntityKeyValue1 int',@EntityKeyValue1=1
我只需要查出Grand Canyon附近距离机场不到10公里住宿的地方,而上面的sql把Grand Canyon附近所有住宿的地方都加载到了内存中,然后在内存中做筛选的,自然不符合性能的要求,修改为:
/// <summary> /// 改进:在数据库中操作 /// </summary> private static void QueryLodgingDistancePro() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var canyonQuery = from d in context.Destinations where d.Name == "Grand Canyon" select d; var canyon = canyonQuery.Single(); var lodgingQuery = context.Entry(canyon).Collection(d => d.Lodgings).Query(); var distanceQuery = from l in lodgingQuery where l.MilesFromNearestAirport <= 10 select l; foreach (var lodging in distanceQuery) { Console.WriteLine(lodging.Name); } } }
有什么区别呢?认真看肯定看的出来了,使用了Query方法,查询操作是在数据库操作的,而不是加载到了内存中再筛选的。看看生成的sql:
exec sp_executesql N'SELECT [Extent1].[LodgingId] AS [LodgingId], [Extent1].[Name] AS [Name], [Extent1].[Owner] AS [Owner], [Extent1].[MilesFromNearestAirport] AS [MilesFromNearestAirport], [Extent1].[destination_id] AS [destination_id], [Extent1].[PrimaryContactId] AS [PrimaryContactId], [Extent1].[SecondaryContactId] AS [SecondaryContactId] FROM [dbo].[Lodgings] AS [Extent1] WHERE ([Extent1].[destination_id] = @EntityKeyValue1) AND ([Extent1].[MilesFromNearestAirport] <= cast(10 as decimal(18)))',N'@EntityKeyValue1 int',@EntityKeyValue1=1
看看这条sql,小于等于10作为查询条件了,查出来的数据自然就是满足要求的数据了,这样就只会加载需要的数据到内存中,这就是效率的问题,认真研究EF的API之后,写程序的时候自然就知道对应生成的sql是什么样子的,复不复杂、会有什么性能上的损失。Perfect。再举一例:
/// <summary> /// 查询个数 /// </summary> private static void QueryLodgingCount() { using (var context = new DbContexts.DataAccess.BreakAwayContext()) { var canyonQuery = from d in context.Destinations where d.Name == "Grand Canyon" select d; var canyon = canyonQuery.Single(); var lodgingQuery = context.Entry(canyon) .Collection(d => d.Lodgings) .Query(); var lodgingCount = lodgingQuery.Count(); Console.WriteLine("Lodging at Grand Canyon: " + lodgingCount); } }
从数据库中算好个数再输出,而不是把所有记录都加载到内存中,然后在内存中算个数。当然也可以一起使用Query和Load方法,先过滤好需要的数据再加载到内存中:
context.Entry(canyon).Collection(d => d.Lodgings).Query().Where(l => l.Name.Contains("Hotel")).Load();
总之,调用Load方法就会加载数据到内存中,加载之前做好过滤就是在数据库中的,加载之后再过滤就是在内存中的操作,如果只需要简单求count,显然前者更合适。
感谢阅读,本章源码。后续还有更精彩的文章带你了解EF DbContext的各种增删改查,请保持关注!
EF DbContext 系列文章导航:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号