MySQL集群搭建-MHA高可用架构
1 概述
1.1 MHA 简介
MHA - Master High Availability 是由 Perl 实现的一款高可用程序,出现故障时,MHA 以最小的停机时间(通常10-30秒)执行 master 的故障转移以及 slave 的升级。MHA 可防止复制一致性问题,并且易于安装,不需要改变现有部署。
MHA 由MHA manager和MHA node组成, MHA manager是一个监控管理程序,用于监控MySQL master状态; MHA node是具有故障转移的工具脚本,如解析 MySQL 二进制/中继日志,传输应用事件到Slave, MHA node在每个MySQL服务器上运行。
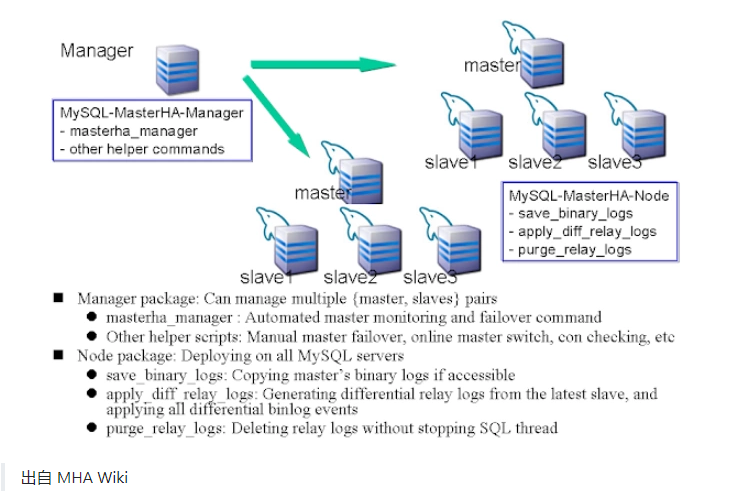
MHA manager调用MHA node工具脚本的方式是SSH到主机上然后执行命令,所以各节点需要做等效验证。
1.2 MHA 怎么保证数据不丢失
当Master宕机后,MHA会尝试保存宕机Master的二进制日志,然后自动判断MySQL集群中哪个实例的中继日志是最新的,并将有最新日志的实例的差异日志传到其他实例补齐,从而实现所有实例数据一致。然后把宕机Master的二进制日志应用到选定节点,并提升为 Master。
具体流程如下:
- 尝试从宕机
Master中保存二进制日志 - 找到含有最新中继日志的
Slave - 把最新中继日志应用到其他实例,实现各实例数据一致
- 应用从
Master保存的二进制日志事件 - 提升一个
Slave为Master - 其他
Slave向该新Master同步
从切换流程流程可以看到,如果宕机Master主机无法SSH登录,那么第一步就没办法实现,对于MySQL5.5以前的版本,数据还是有丢失的风险。对于5.5后的版本,开启半同步复制后,真正有助于避免数据丢失,半同步复制保证至少一个 (不是所有)slave 在 master 提交时接收到二进制日志事件。因此,对于可以处理一致性问题的MHA 可以实现"几乎没有数据丢失"和"从属一致性"。
1.3 MHA 优点和限制
优点
- 开源,用
Perl编写 - 方案成熟,故障切换时,
MHA会做日志补齐操作,尽可能减少数据丢失,保证数据一 - 部署不需要改变现有架构
限制
- 各个节点要打通
SSH信任,有一定的安全隐患 - 没有
Slave的高可用 - 自带的脚本不足,例如虚IP配置需要自己写命令或者依赖其他软件
- 需要手动清理中继日志
1.4 MHA 常用两种复制配置
单 master,多 slave
M(RW)
|
+-------+-------+
S1(R) S2(R) S3(R)
这种复制方式非常常见,当Master宕机时,MHA会选一个日志最新的主机升级为Master, 如果不希望个节点成为Master,把no_master设为1就可以。
多 master, 多 slave
M(RW)----M2(R, candidate_master=1)
|
+-------+-------+
S1(R) S2(R)
双主结构也是常见的复制模式,如果当前Master崩溃, MHA会选择只读Master成为新的Master
2 数据库环境准备
本次演示使用复制方式是主主从,主主从数据库搭建方式参考以前文章
2.1 节点信息
| IP | 系统 | 端口 | MySQL版本 | 节点 | 读写 | 说明 |
|---|---|---|---|---|---|---|
| 10.0.0.247 | Centos6.5 | 3306 | 5.7.9 | Master | 读写 | 主节点 |
| 10.0.0.248 | Centos6.5 | 3306 | 5.7.9 | Standby | 只读,可切换为读写 | 备主节点 |
| 10.0.0.249 | Centos6.5 | 3306 | 5.7.9 | Slave | 只读 | 从节点 |
| 10.0.0.24 | Centos6.5 | - | - | manager | - | MHA Manager |
| 10.0.0.237 | - | - | - | - | - | VIP |
2.2 架构图

2.3 参考配置
Master1
[client]
port = 3306
default-character-set=utf8mb4
socket = /data/mysql_db/test_db/mysql.sock
[mysqld]
datadir = /data/mysql_db/test_db
basedir = /usr/local/mysql57
tmpdir = /tmp
socket = /data/mysql_db/test_db/mysql.sock
pid-file = /data/mysql_db/test_db/mysql.pid
skip-external-locking = 1
skip-name-resolve = 1
port = 3306
server_id = 2473306
default-storage-engine = InnoDB
character-set-server = utf8mb4
default_password_lifetime=0
auto_increment_offset = 1
auto_increment_increment = 2
#### log ####
log_timestamps=system
log_bin = /data/mysql_log/test_db/mysql-bin
log_bin_index = /data/mysql_log/test_db/mysql-bin.index
binlog_format = row
relay_log_recovery=ON
relay_log=/data/mysql_log/test_db/mysql-relay-bin
relay_log_index=/data/mysql_log/test_db/mysql-relay-bin.index
log_error = /data/mysql_log/test_db/mysql-error.log
#### replication ####
log_slave_updates = 1
replicate_wild_ignore_table = information_schema.%,performance_schema.%,sys.%
#### semi sync replication settings #####
plugin_dir=/usr/local/mysql57/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_slave_enabled = 1
Master2
[client]
port = 3306
default-character-set=utf8mb4
socket = /data/mysql_db/test_db/mysql.sock
[mysqld]
datadir = /data/mysql_db/test_db
basedir = /usr/local/mysql57
tmpdir = /tmp
socket = /data/mysql_db/test_db/mysql.sock
pid-file = /data/mysql_db/test_db/mysql.pid
skip-external-locking = 1
skip-name-resolve = 1
port = 3306
server_id = 2483306
default-storage-engine = InnoDB
character-set-server = utf8mb4
default_password_lifetime=0
auto_increment_offset = 2
auto_increment_increment = 2
#### log ####
log_timestamps=system
log_bin = /data/mysql_log/test_db/mysql-bin
log_bin_index = /data/mysql_log/test_db/mysql-bin.index
binlog_format = row
relay_log_recovery=ON
relay_log=/data/mysql_log/test_db/mysql-relay-bin
relay_log_index=/data/mysql_log/test_db/mysql-relay-bin.index
log_error = /data/mysql_log/test_db/mysql-error.log
#### replication ####
log_slave_updates = 1
replicate_wild_ignore_table = information_schema.%,performance_schema.%,sys.%
#### semi sync replication settings #####
plugin_dir=/usr/local/mysql57/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_slave_enabled = 1
Slave
[client]
port = 3306
default-character-set=utf8mb4
socket = /data/mysql_db/test_db/mysql.sock
[mysqld]
datadir = /data/mysql_db/test_db
basedir = /usr/local/mysql57
tmpdir = /tmp
socket = /data/mysql_db/test_db/mysql.sock
pid-file = /data/mysql_db/test_db/mysql.pid
skip-external-locking = 1
skip-name-resolve = 1
port = 3306
server_id = 2493306
default-storage-engine = InnoDB
character-set-server = utf8mb4
default_password_lifetime=0
read_only=1
#### log ####
log_timestamps=system
log_bin = /data/mysql_log/test_db/mysql-bin
log_bin_index = /data/mysql_log/test_db/mysql-bin.index
binlog_format = row
relay_log_recovery=ON
relay_log=/data/mysql_log/test_db/mysql-relay-bin
relay_log_index=/data/mysql_log/test_db/mysql-relay-bin.index
log_error = /data/mysql_log/test_db/mysql-error.log
#### replication ####
log_slave_updates = 1
replicate_wild_ignore_table = information_schema.%,performance_schema.%,sys.%
#### semi sync replication settings #####
plugin_dir=/usr/local/mysql57/lib/plugin
plugin_load = "rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
loose_rpl_semi_sync_master_enabled = 1
loose_rpl_semi_sync_slave_enabled = 1
3 安装配置 MHA
3.1 下载 MHA
进入 MHA 下载页面 Downloads, 下载Manager和Node节点安装包,由于我的服务器是centos6,所以下载了MHA Manager 0.56 rpm RHEL6和MHA Node 0.56 rpm RHEL6
3.2 安装 MHA
Node安装
在所有主机(包括Manager)上执行
# 安装依赖
yum install perl perl-devel perl-DBD-MySQL
# 安装 node 工具
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
Manager安装
在 Manager 主机上执行
# 安装依赖
yum install -y perl perl-devel perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
# 安装 manager
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
3.3 创建 MHA 管理用户
管理用户需要执行一些数据库管理命令包括STOP SLAVE, CHANGE MASTER, RESET SLAVE
create user mha_manager@'%' identified by 'mha_manager';
grant all on *.* to mha_manager@'%';
flush privileges;
3.4 增加 MySQL 用户 sudo 权限
配置 VIP 需要有 sudo 权限
打开/etc/sudoers文件, 增加一条
root ALL=(ALL) ALL
# 这个是增加的
mysql ALL=(ALL) NOPASSWD: ALL
然后把Defaults requiretty注释掉
# Defaults requiretty
3.5 配置各主机免密码登陆
所有主机执行
# 进入 mysql 用户
su - mysql
# 生成密钥对, 执行命令,然后按回车
ssh-keygen -t rsa
# 复制公钥到相应主机
ssh-copy-id mysql@10.0.0.247
ssh-copy-id mysql@10.0.0.248
ssh-copy-id mysql@10.0.0.249
ssh-copy-id mysql@10.0.1.24
3.6 配置 Manager
新建/etc/masterha目录,我们把配置文件放到这里
mkdir /etc/masterha
创建配置文件/etc/masterha/app1.cnf, 写上配置
[server default]
manager_workdir=/etc/masterha # 设置 manager 的工作目录, 可以自己调整
manager_log=/etc/masterha/manager.log # 设置 manager 的日志文件
master_binlog_dir=/data/mysql_log/test_db # 设置 master binlog 的日志的位置
master_ip_failover_script= /etc/masterha/script/master_ip_failover # 设置自动 failover 时的切换脚本, 脚本参考附件
master_ip_online_change_script= /etc/masterha/script/master_ip_online_change # 设置手动切换时执行的切换脚本, 脚本参考附件
user=mha_manager # 设置管理用户, 用来监控、配置 MySQL(STOP SLAVE, CHANGE MASTER, RESET SLAVE), 默认为 root
password=mha_manager # 设置管理用户密码
repl_user=repl # 设置复制环境中的复制用户名
repl_password=repl # 设置复制用户的密码
ping_interval=1 # 发送 ping 包的时间间隔,三次没有回应就自动进行 failover
remote_workdir=/tmp # 设置远端 MySQL 的工作目录
report_script=/etc/masterha/script/send_report # 设置发生切换后执行的脚本
# 检查脚本
secondary_check_script= /usr/bin/masterha_secondary_check-s 10.0.0.247 -s 10.0.0.248
shutdown_script="" #设置故障发生后关闭故障主机脚本(可以用于防止脑裂)
ssh_user=mysql #设置 ssh 的登录用户名
[server1]
hostname=10.0.0.247
port=3306
[server2]
hostname=10.0.0.248
port=3306
candidate_master=1 # 设置为候选 master, 如果发生宕机切换,会把该节点设为新 Master,即使它不是数据最新的节点
check_repl_delay=0 # 默认情况下,一个 Slave 落后 Master 100M 的中继日志,MHA 不会选择它作为新的 Master,因为这对于 Slave 恢复数据要很长时间,check_repl_delay=0 的时候会忽略延迟,可以和 candidate_master=1 配合用
[server3]
hostname=10.0.0.249
port=3306
no_master=1 # 从不将这台主机升级为 Master
ignore_fail=1 # 默认情况下,如果有 Slave 节点挂了, 就不进行切换,设置 ignore_fail=1 可以忽然它
创建配置文件/etc/masterha/app2.cnf, 以备用Master 为 Master, 方便切换后启动MHA
[server default]
manager_workdir=/etc/masterha # 设置 manager 的工作目录, 可以自己调整
manager_log=/etc/masterha/manager.log # 设置 manager 的日志文件
master_binlog_dir=/data/mysql_log/test_db # 设置 master binlog 的日志的位置
master_ip_failover_script= /etc/masterha/script/master_ip_failover # 设置自动 failover 时的切换脚本
master_ip_online_change_script= /etc/masterha/script/master_ip_online_change # 设置手动切换时执行的切换脚本
user=mha_manager # 设置管理用户, 用来监控、配置 MySQL(STOP SLAVE, CHANGE MASTER, RESET SLAVE), 默认为 root
password=mha_manager # 设置管理用户密码
repl_user=repl # 设置复制环境中的复制用户名
repl_password=repl # 设置复制用户的密码
ping_interval=1 # 发送 ping 包的时间间隔,三次没有回应就自动进行 failover
remote_workdir=/tmp # 设置远端 MySQL 的工作目录
report_script=/etc/masterha/script/send_report # 设置发生切换后执行的脚本
# 检查脚本
secondary_check_script= /usr/bin/masterha_secondary_check -s 10.0.0.248 -s 10.0.0.247
shutdown_script="" #设置故障发生后关闭故障主机脚本(可以用于防止脑裂)
ssh_user=mysql #设置 ssh 的登录用户名
[server1]
hostname=10.0.0.248
port=3306
[server2]
hostname=10.0.0.247
port=3306
candidate_master=1 # 设置为候选 master, 如果发生宕机切换,会把该节点设为新 Master,即使它不是数据最新的节点
check_repl_delay=0 # 默认情况下,一个 Slave 落后 Master 100M 的中继日志,MHA 不会选择它作为新的 Master,因为这对于 Slave 恢复数据要很长时间,check_repl_delay=0 的时候会忽略延迟,可以和 candidate_master=1 配合用
[server3]
hostname=10.0.0.249
port=3306
no_master=1 # 从不将这台主机升级为 Master
ignore_fail=1 # 默认情况下,如果有 Slave 节点挂了, 就不进行切换,设置 ignore_fail=1 可以忽然它
注意:使用的时候去掉注释
3.7 配置切换脚本
管理 VIP 方式
MHA管理VIP有两种方案,一种是使用Keepalived,另一种是自己写命令实现增删VIP,由于Keepalived容易受到网络波动造成VIP切换,而且无法在多实例机器上使用,所以建议写脚本管理VIP。
当前主机的网卡是eth0, 可以通过下列命令增删 VIP
up VIP
sudo /sbin/ifconfig eth0:1 10.0.0.237 netmask 255.255.255.255
down VIP
sudo /sbin/ifconfig eth0:1 down
配置切换脚本
master_ip_failover , master_ip_online_change和send_report脚本在附录里面
更改 mysql 配置
MHA的检测比较严格,所以我们把除Master外的节点设为read_only, 有必要可以写进配置文件里面
# mysql shell
set global read_only=1;
MHA需要使用中继日志来实现数据一致性,所以所有节点要设置不自动清理中继日志
# mysql shell
set global relay_log_purge=0;
也可以写入配置文件
# my.cnf
relay_log_purge=0
MHA 常用命令
Manager
masterha_check_ssh 检查 MHA 的 SSH 配置状况
masterha_check_repl 检查 MySQL 复制状况
masterha_manger 启动 MHA
masterha_stop 停止 MHA
masterha_check_status 检测当前 MHA 运行状态
masterha_master_monitor 检测 master 是否宕机
masterha_master_switch 手动故障转移
masterha_conf_host 添加或删除配置的 server 信息
Node
save_binary_logs 保存 master 的二进制日志
apply_diff_relay_logs 对比识别中继日志的差异部分
purge_relay_logs 清除中继日志(MHA中继日志需要使用这个命令清除)
命令的使用方法可以通过执行命令 --help 得到
验证 SSH 是否成功、主从状态是否正常
在 manager 节点执行 masterha_check_ssh --conf=/etc/masterha/app1.cnf 检测SSH状态,下面是执行结果
[mysql@chengqm ~]$ masterha_check_ssh --conf=/etc/masterha/app1.cnf
Thu Dec 20 19:47:18 2018 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Thu Dec 20 19:47:18 2018 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Thu Dec 20 19:47:18 2018 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Thu Dec 20 19:47:18 2018 - [info] Starting SSH connection tests..
Thu Dec 20 19:47:19 2018 - [debug]
Thu Dec 20 19:47:18 2018 - [debug] Connecting via SSH from mysql@10.0.0.247(10.0.0.247:22) to mysql@10.0.0.248(10.0.0.248:22)..
Thu Dec 20 19:47:19 2018 - [debug] ok.
Thu Dec 20 19:47:19 2018 - [debug] Connecting via SSH from mysql@10.0.0.247(10.0.0.247:22) to mysql@10.0.0.249(10.0.0.249:22)..
Thu Dec 20 19:47:19 2018 - [debug] ok.
Thu Dec 20 19:47:19 2018 - [debug]
Thu Dec 20 19:47:19 2018 - [debug] Connecting via SSH from mysql@10.0.0.248(10.0.0.248:22) to mysql@10.0.0.247(10.0.0.247:22)..
Thu Dec 20 19:47:19 2018 - [debug] ok.
Thu Dec 20 19:47:19 2018 - [debug] Connecting via SSH from mysql@10.0.0.248(10.0.0.248:22) to mysql@10.0.0.249(10.0.0.249:22)..
Thu Dec 20 19:47:19 2018 - [debug] ok.
Thu Dec 20 19:47:20 2018 - [debug]
Thu Dec 20 19:47:19 2018 - [debug] Connecting via SSH from mysql@10.0.0.249(10.0.0.249:22) to mysql@10.0.0.247(10.0.0.247:22)..
Thu Dec 20 19:47:20 2018 - [debug] ok.
Thu Dec 20 19:47:20 2018 - [debug] Connecting via SSH from mysql@10.0.0.249(10.0.0.249:22) to mysql@10