数据库中的表达式
表达式模块作为在数据库系统的查询处理中几乎任何地方都在使用的模块,其实现的方式会极大影响数据库执行query的速度,如PostgreSQL中不同的表达式计算方式将会给TPC-H Q1带来5倍的性能差距,因此一个对查询处理能力有追求的数据库系统都会对自己的表达式性能做一些优化。所以我们决定观察下各个开源数据库的表达式实现,作为数据库的开发者可以从中获得一些启示少走弯路,作为使用者则可以了解到部分相关的特性以更好的使用。
PostgreSQL
PostgreSQL主要基于以下两点设计:
1. As much complexity as possible should be handled by expr init
2. Read-only make life much simpler
对于1,在一条query的执行中,表达式通常只会init一次,而表达式的evaluate会在query的执行过程中发生无数次,任何额外的指令重复无数次,其开销都是不可忽略的。
对于2,应该是query caching和parallel query方面的考虑,在不可变的plan上做这些事情会比较简单
表达式在代码中的实现
相关类的定义
PostgreSQL的表达式模块主要与以下几个类有关:
- Expr: 表达式的逻辑表示,表达式会被表达为由Expr作为节点的一颗树
- ExprState: 表达式执行中的核心部分,其中有几个关键成员:
ExprEvalStep[] steps表达式的指令序列,可以通过顺序执行这些执行来执行表达式ExprStateEvalFunc evalfunc表达式执行的入口,通过调用该函数进行表达式的执行<resvalue, resnull>用来存放表达式的结果。需要注意的是ExprEvalStep中也拥有这两个成员,用来存放中间结果
表达式的执行流程
如果粗略的分,表达式的执行可以分为两个阶段: Init(复杂) 和 Eval(简单),代码里面的流程如下:
- 表达式初始化,由函数
ExecInitExpr()完成
C
/* 'node' is the root of the expression tree to compile. */
/* 'parent' is the PlanState node that owns the expression. */
ExprState *
ExecInitExpr(Expr *node, PlanState *parent)
{
ExprState *state;
ExprEvalStep scratch = {0};
/* Special case: NULL expression produces a NULL ExprState pointer */
if (node == NULL)
return NULL;
/* Initialize ExprState with empty step list */
state = makeNode(ExprState);
state->expr = node;
state->parent = parent;
state->ext_params = NULL;
/* Insert EEOP_*_FETCHSOME steps as needed */
ExecInitExprSlots(state, (Node *) node);
/* Compile the expression proper */
ExecInitExprRec(node, state, &state->resvalue, &state->resnull);
/* Finally, append a DONE step */
scratch.opcode = EEOP_DONE;
ExprEvalPushStep(state, &scratch);
/* pick a suitable method to exec expr */
ExecReadyExpr(state);
return state;
}这个函数主要做了以下几点事情
- 创建一个ExprState,解析表达式的逻辑表示,生成对应的ExprEvalStep数组(调用ExecInitExprRec())。其中除了表达式对应的ExprEvalStep之前,还会在表达式开始前额外插入一些EEOP_*_FETCHSOME的step,这些step用于将对应field的值存入表达式(例如表达式t1.a > 5中的t1.a)
- 选择恰当的执行方式,并做一些相对应的前置准备,主要有两种执行方式:
- 解释执行,这里由分为传统的解释执行(switch case)和computed goto两种,由宏EEO_USE_COMPUTED_GOTO控制,在编译时决定。
- 编译执行,依靠LLVM将表达式编译为机器码执行。 2. 执行表达式,会依靠之前初始化时确定的执行方式:
- 解析执行,通过调用函数ExecInterpExprStillValid()Datum ExecInterpExprStillValid(ExprState *state, ExprContext *econtext, bool *isNull) { CheckExprStillValid(state, econtext); /* skip the check during further executions */ /* in general, state->evalfunc_private = ExecInterpExpr */ state->evalfunc = (ExprStateEvalFunc)state->evalfunc_private; /* and actually execute */ return state->evalfunc(state, econtext, isNull); }
函数ExecInterpExpr中包含了一个巨大的switch-case块,其中的执行逻辑根据宏EEO_USE_COMPUTED_GOTO有所不同: - 如果EEO_USE_COMPUTED_GOTO未被定义,那么就是传统的解析执行,这时ExprEvalStep::opcode表示一个enum ExprEvalOp,switch将根据opcode跳转到合适的case执行
- 如果EEO_USE_COMPUTED_GOTO被定义,这时ExprEvalStep::opcode是一个指向某个case块代码的地址,执行时将不会反复通过switch执行,而将进行一连串的GOTO语句执行合适的逻辑
一个简单的执行(调用一个函数)的例子:
/* ----------- Utils ----------- */ #if defined(EEO_USE_COMPUTED_GOTO) // ... #define EEO_SWITCH() #define EEO_CASE(name) CASE_##name: // goto op_func_addr #define EEO_DISPATCH() goto *((void *) op->opcode) #else /* !EEO_USE_COMPUTED_GOTO */ #define EEO_SWITCH() starteval: switch ((ExprEvalOp)op->opcode) #define EEO_CASE(name) case name: // return to EEO_SWITCH(), interpret opcode of next op #define EEO_DISPATCH() goto starteval #endif /* EEO_USE_COMPUTED_GOTO */ #define EEO_NEXT() \ do { \ op++; \ EEO_DISPATCH(); \ } while (0) /* ----------- In ExecInterpExpr ----------- */ #if defined(EEO_USE_COMPUTED_GOTO) // goto opcode of 1st ExecStep EEO_DISPATCH(); #endif EEO_SWITCH() { // ... EEO_CASE(EEOP_FUNCEXPR) { // fcinfo包含函数入参(由前置ExprEvalStep计算) FunctionCallInfo fcinfo = op->d.func.fcinfo_data; Datum d; fcinfo->isnull = false; d = op->d.func.fn_addr(fcinfo); *op->resvalue = d; *op->resnull = fcinfo->isnull; // EEO_NEXT() will call EEO_DISPATCH() (goto NEXT_LABEL) EEO_NEXT(); } }
- 编译执行,通过调用函数ExecRunCompiledExpr()static Datum ExecRunCompiledExpr(ExprState *state, ExprContext *econtext, bool *isNull) { CompiledExprState *cstate = state->evalfunc_private; ExprStateEvalFunc func; CheckExprStillValid(state, econtext); llvm_enter_fatal_on_oom(); // get function ptr of expression func = (ExprStateEvalFunc) llvm_get_function(cstate->context, cstate->funcname); llvm_leave_fatal_on_oom(); Assert(func); /* remove indirection via this function for future calls */ state->evalfunc = func; return func(state, econtext, isNull); }
TiDB
与PG不同,TiDB的表达式看起来与MySQL比较相似,所有表达式都继承自Expression interface(对应MySQL中的Item),Expression类拥有一系列eval接口(对应纯虚函数Item::val_),表达式执行是后续遍历表达式树的过程,举个例子
func (s *builtinArithmeticPlusIntSig) evalInt(row chunk.Row) (val int64, isNull bool, err error) {
a, isNull, err := s.args[0].EvalInt(s.ctx, row)
if isNull || err != nil {
return 0, isNull, err
}
b, isNull, err := s.args[1].EvalInt(s.ctx, row)
if isNull || err != nil {
return 0, isNull, err
}
// ...
return a + b, false, nil
}对比下MySQL对应的实现
longlong Item_func_plus::int_op() {
longlong val0 = args[0]->val_int();
longlong val1 = args[1]->val_int();
longlong res = val0 + val1;
bool res_unsigned = false;
if ((null_value = args[0]->null_value || args[1]->null_value)) return 0;
// ...
return check_integer_overflow(res, res_unsigned);
}这样的实现好处是很容易保持行为与MySQL一致(表达式计算,隐式转换),对大部分的函数只需要把MySQL的实现翻译一下就可以了,不过比起在表达式上下了功夫的Postgre来说,性能可能会差一些(大量的函数调用),因此TiDB也采用了向量化执行表达式的方式来解决这个问题
TiDB的表达式向量化执行
目前的表达式实现
上文提到了TiDB这种与MySQL相似的表达式才运行时会产生大量函数调用,解决这个问题可以从两个方面考虑:
- 减少表达式计算时的函数调用:利用JIT技术在运行时将表达式编译成一个函数,减少函数调用
- 减少函数调用的开销:利用向量化技术,表达式每次运算会同时计算若干行的结果,均摊了函数调用的开销
Postgre提供了前者,而TiDB选择了后者,以TiDB中简单的filter为例,看看TiDB表达式的向量化实现
// SelectionExec represents a filter executor.
type SelectionExec struct {
baseExecutor
// batched: whether to use vectorized expressions
batched bool
filters []expression.Expression
// selected: result of vectorized expression
selected []bool
inputIter *chunk.Iterator4Chunk
inputRow chunk.Row
childResult *chunk.Chunk
memTracker *memory.Tracker
}filter类的定义并不复杂,接下来看看表达式是怎么执行的,先确定是否能够使用向量化表达式
func (e *SelectionExec) open(ctx context.Context) error {
// ...
// Vectorizable?
e.batched = expression.Vectorizable(e.filters)
if e.batched {
e.selected = make([]bool, 0, chunk.InitialCapacity)
}
e.inputIter = chunk.NewIterator4Chunk(e.childResult)
e.inputRow = e.inputIter.End()
return nil
}然后执行表达式
// Next implements the Executor Next interface.
func (e *SelectionExec) Next(ctx context.Context, req *chunk.Chunk) error {
req.GrowAndReset(e.maxChunkSize)
if !e.batched {
// row by row
return e.unBatchedNext(ctx, req)
}
for {
// ...
// vectorized
e.selected, err = expression.VectorizedFilter(e.ctx, e.filters, e.inputIter, e.selected)
if err != nil {
return err
}
e.inputRow = e.inputIter.Begin()
}
}在函数expression.VectorizedFilter中,如果Expression拥有vecEval*接口,就会调用这些接口进行批量计算,将结果存在selected中作为filter的结果,下面是TiDB向量化加法的实现
// unsigned a + b
func (b *builtinArithmeticPlusIntSig) plusUU(result *chunk.Column, lhi64s, rhi64s, resulti64s []int64) error {
// vectorized here
for i := 0; i < len(lhi64s); i++ {
if result.IsNull(i) {
continue
}
lh, rh := lhi64s[i], rhi64s[i]
// do overflow check...
resulti64s[i] = lh + rh
}
return nil
}可以改进的地方
现在TiDB表达式向量化的batch size是固定的32。实际上不同的batch_size对性能会有所影响,主要取决于CPU cache的大小
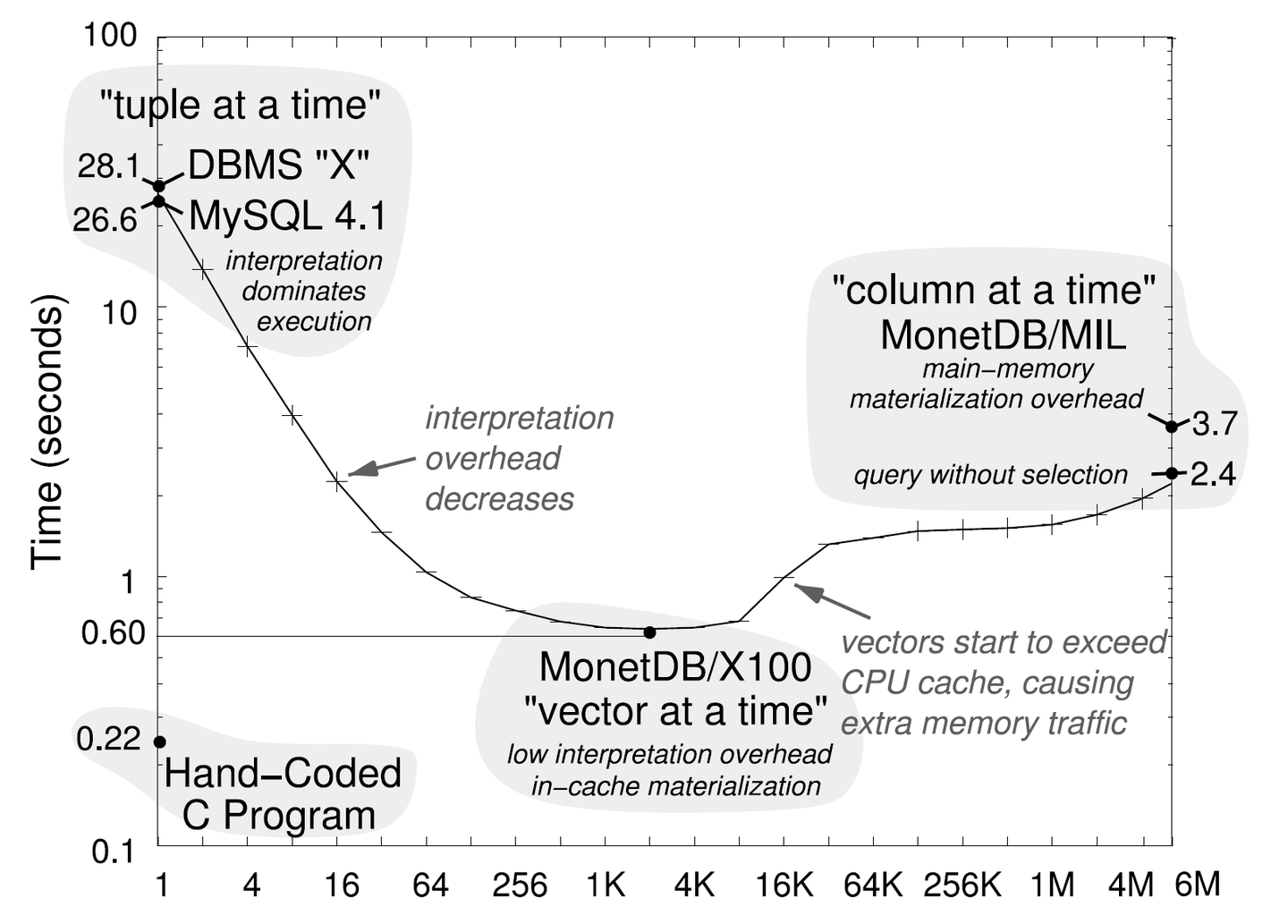
将来一个可能做的改进是根据表达式与CPU cache大小计算出一个合适的batch size让表达式的中间结果全部放在CPU的L1 cache中,同时最大程度减少函数调用的开销
PolarDB In-memory Column Index(IMCI)
PolarDB IMCI作为PolarDB的列式索引用于加强其应对复杂查询的能力,作为一个侧重分析性能的组件,其表达式实现也采用了大量的优化技术
表达式优化,向量化与SIMD
IMCI的数据以列式存储,因此向量化成为了很自然的选择,与此同时,我们也采用了PostgreSQL解析执行表达式时的优化:
- 只读的expression + 可读写的data slot
- 执行前消除递归,分解为若干ExprStep
另外,云上运行的软件与普通软件不同,由于云上硬件往往统一更新,因此对于云上运行的软件,我们可以利用机器硬件的特性进行优化,以一个简单的IF(x > 0, a, b)表达式为例,一个可能的向量化实现
void IF_func::vec_val_int(Pred *pred, Expr val1, Expr val2, int32_t *dst) {
size_t batch_size = this->batch_size;
uint8_t *pred_val = return val1->vec_val_bool();
// we can push down the mask to val1 and val2
// but in this example, it's harmless
int32_t *val1_val = return val1->vec_val_bool();
int32_t *val2_val = return val1->vec_val_bool();
for (size_t i = 0; i < batch_size; i++) {
if (Utils::test_bit(pred_val, i)) {
dst[i] = val1_val[i];
} else {
dst[i] = val2_val[i];
}
}
}这里会产生分支,可能会打断CPU的流水线,但如果机器硬件CPU支持AVX512,这个函数可以利用AVX512 SIMD重写
void IF_func::vec_val_int(Pred *pred, Expr val1, Expr val2, int32_t *dst) {
size_t batch_size = this->batch_size;
uint16_t *pred_val = return val1->vec_val_bool();
// we can push down the mask to val1 and val2
// but in this example, it's harmless
int32_t *val1_val = return val1->vec_val_bool();
int32_t *val2_val = return val1->vec_val_bool();
constexpr step = 64 / sizeof(int32_t);
for (size_t i = 0; i < batch_size; i++) {
size_t val_idx = (i * step);
auto val1_512 = _mm512_load_epi32(val1_val + val_idx);
auto val2_512 = _mm512_load_epi32(val2_val + val_idx);
_mm512_store_epi32(dst + val_idx, val2_512)
_mm512_mask_store_epi32(dst + val_idx, pred_val[i], val1_512)
}
}借助CPU对带mask指令的原生支持,我们能够消除分支,并且减少了循环的次数,IMCI也利用SIMD指令对表达式进行了优化以最大程度利用硬件为表达式加速
Type Reduction
对于列式存储的数据,因为同一列的数据排布在一起,相对于行式数据来说,压缩取得效果会更好一些,另一方面,由于SIMD寄存器宽度是固定的,因此每一个数据越短,一条SIMD指令能够处理的数据就越多,如果能够在压缩的数据上进行表达式计算,就可以加速我们的表达式,例如对于一个bigint列,如果其数据都在int16范围内,对于SIMD指令来说
_mm512_eval_epi64(...),一次处理8行数据_mm512_eval_epi16(...),一次处理32行数据
同样的指令,处理了4倍的数据。
在IMCI中,我们会根据数据压缩的情况在对表达式采取合适的优化以最大化SIMD指令的处理效率
SIMD对表达式的加速效果
下图展示了SIMD与Type Reduction对表达式的加速效果
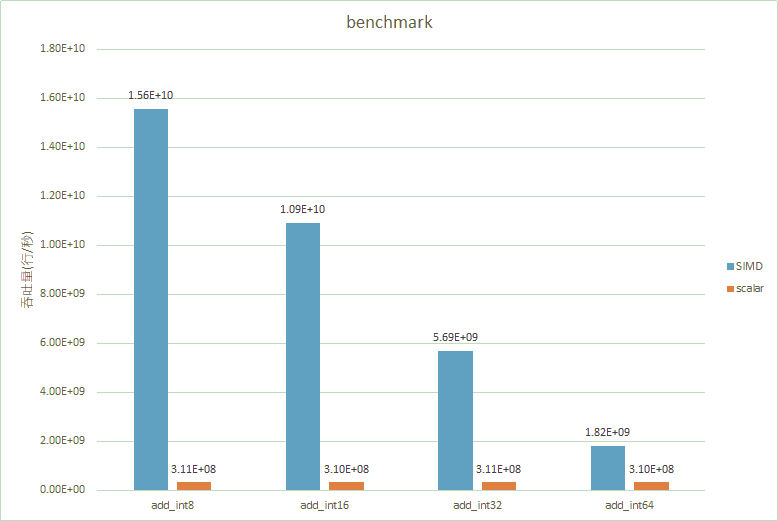
可以看出SIMD指令对于表达式的加速还是很明显的。
向量化与JIT: 表达式的未来
上文已经介绍了目前数据库系统中常见的两种优化: 向量化与JIT编译执行,如果单独拆出来看这两个技术的话,他们的优缺点如下:
- 向量化:简单,通用,相较于最传统的逐行解析执行来说足够有效
- JIT编译:可以对表达式做一些额外的优化(依靠编译器),但是需要考虑代价(编译时间)如果Query本身是很简单的Query(IndexScan),那么这个代价会比较明显,在AP查询中这个代价就不太起眼
数据库的表达式,或者更进一步来说,整条SQL实际上都是一段代码,除了顶层的优化(数据库的优化器)之外,一些微观层面上的优化也许直接交给编译器是更好的选择,实际上现在也已经有将整条Query编译为二进制代码执行的数据库出现(Hyper, NoisePage)。
另一方面实际上这两种优化手段也并不对立,我们也可以编译向量化执行的代码,甚至依靠LLVM平台无关的IR,我们甚至可以实现跨平台使用SIMD指令,所以与其认为向量化和JIT是两种优化,不如说向量化是一种实现方式,JIT则基于已有的实现通过编译进行优化,不过虽然这么说,这两个技术的结合依然会带来一些问题:
- JIT在数据库中的实现会比较麻烦,实际上相当于用另一种语言(LLVM IR)开发数据库的执行器,会比较别扭,并且调试等操作都会更麻烦。
- 虽然两个方向是正交的,但是两个优化加在一起可能会造成1+1<2的效果,如果结合编译时间和1,就会出现”值不值“的问题
对于第一个问题,PostgreSQL提供了一个解决方案,先将源码编译为LLVM IR,运行时读取进内存供内核使用,如图所示:
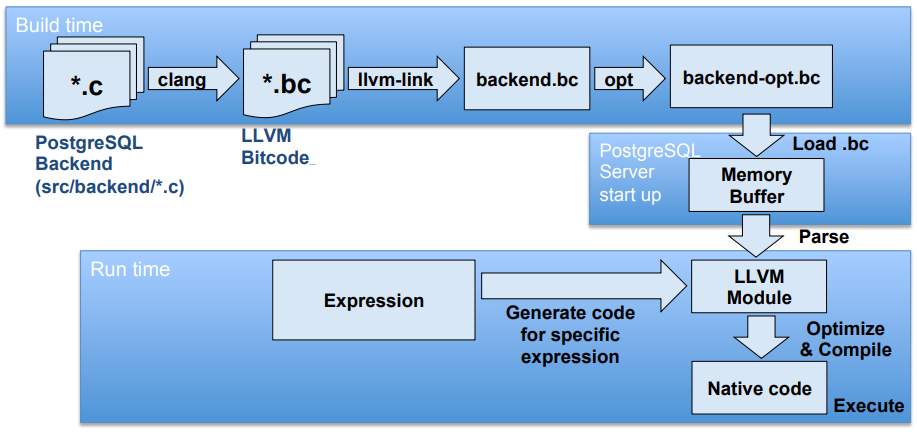
实际上,这是一个在已有的实现上添加JIT功能的示范,这样可以极大程度应用已有的C语言实现,免于大量LLVM IR的手动编写。
对于第二个问题,Hyper提供了一个可能的结合方案:在列式压缩数据上的Scan采用了向量化技术,其上的算子使用tuple-at-a-time的编译执行技术。
几个还需要思考的地方:
- 对于PostgreSQL的JIT集成方式,对于表达式来说是很合理且方便的,但如果要借鉴并应用到一个已有的系统(不仅是表达式,还有执行框架),合理的代码结构设计依然很重要。
- 对于Hyper的结合方式,我们能不能在向量化执行模型上进行类似的结合?对于一些很难使用向量化执行的场景(hash join, order by),也许可以利用编译执行来加速执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号