死锁检测与解决
背景:死锁的成因与解决方式
死锁 指两个实体在运行过程中因竞争资源而形成的一种僵局,如无外力作用,两个实体都无法向前继续推进。从操作系统的层面来看,实体可以是进程或线程,资源可以是设备/信号/消息等;从数据库的层面来看,实体可以是事务,资源可以是锁。从理论上来说,发生死锁需要同时满足以下四个条件:
- 互斥条件:实体对资源有排他控制权
- 请求和保持条件:实体在因获取资源而阻塞时,不释放已获取的资源
- 不抢占条件:实体不可剥夺其他实体已获得的资源,只能等待其他实体自行释放
- 环路等待条件:实体之间的等待关系形成环路
在 DBMS 中,四个条件有可能同时满足:
- 互斥条件:主流 DBMS 各自有着锁及锁兼容性的完备定义
- 请求和保持条件:事务遵循两阶段锁定 (2PL),在扩展阶段不会释放锁
- 不抢占条件:事务在 2PL 收缩阶段自行释放所有已获得的锁
- 环路等待条件:DBMS 内允许事务以非确定性的顺序获得表锁,因此事务之间可能形成等待环路
从理论上来说,解决死锁有如下几种策略:
- 死锁预防
- 死锁避免
- 死锁检测与解除
这三种策略的强度由紧至松,开销由高到低。如果采用偏紧迫的策略,或许可以解决死锁,但是紧迫策略的开销可能导致吞吐率的严重下降 (假设事务全都串行化)。如果死锁并不是一件经常发生的事情,那么采用紧迫策略而付出较大的开销是不划算的。因此,需要在具体场景下,根据对策略开销的预期、对死锁发生频率的预期、对资源吞吐量的预期,进行综合考虑,再选择合适的策略。在 PostgreSQL 中,对死锁的处理采用第三种策略:以较为宽松的策略允许事务向前推进,如果死锁发生,再通过特定的机制 检测并解除 死锁。
死锁检测的触发时机
由于 PostgreSQL 不对死锁的预防和避免做任何工作,事务如何察觉到自己可能陷入死锁?PostgreSQL 对发生死锁的预期比较乐观。执行事务的进程在获取锁时,发现锁因为正被其他事务持有,且请求锁的模式 (lock mode) 与持有锁的事务存在冲突而需要等待后:
- 设置一个死锁定时器,然后立刻进入睡眠,不检测死锁
- 如果定时器超时前,进程已经成功获得锁,那么定时器被提前取消,没有发生死锁
- 如果定时器超时,则进程被唤醒并执行死锁检测算法
只有定时器超时后,才执行死锁检测算法。这种设计避免对超时时间以内的每一个睡眠等待进程都执行一次死锁检测,这也是 乐观等待 策略的体现。定时器的超时时间通过 GUC 参数 deadlock_timeout 设置。
死锁检测的触发实现在 ProcSleep() 函数中。这是进程被阻塞而进入睡眠时的函数:
/* 标志,死锁等待是否超时 */
static volatile sig_atomic_t got_deadlock_timeout;
/* 死锁等待超时后,被信号处理函数调用 */
void
CheckDeadLockAlert(void)
{
int save_errno = errno;
got_deadlock_timeout = true; /* 设置死锁检测超时标志 */
SetLatch(MyLatch); /* 唤醒睡眠进程 */
errno = save_errno;
}
int
ProcSleep(LOCALLOCK *locallock, LockMethod lockMethodTable)
{
/* ... */
/* 超时标志初始化 */
got_deadlock_timeout = false;
/* ... */
/* 启动定时器 */
enable_timeout_after(DEADLOCK_TIMEOUT, DeadlockTimeout);
/* ... */
do
{
/* ... */
else
{
WaitLatch(MyLatch, WL_LATCH_SET, 0,
PG_WAIT_LOCK | locallock->tag.lock.locktag_type);
/* 进程被唤醒 */
ResetLatch(MyLatch);
/* 如果进程是因为死锁超时被唤醒,那么检测死锁 */
if (got_deadlock_timeout)
{
CheckDeadLock();
got_deadlock_timeout = false;
}
CHECK_FOR_INTERRUPTS();
}
/* ... */
} while (myWaitStatus == STATUS_WAITING);
/* ... */
/* 注销定时器 */
disable_timeout(DEADLOCK_TIMEOUT, false);
}原子变量 got_deadlock_timeout 指示死锁计时器是否超时,初始化为 false。设置超时计时器后,在超时处理函数 CheckDeadLockAlert() 中,这个值会被更新为 true。进程因超时而被唤醒后,就会进入 CheckDeadLock() 函数中检测死锁。
锁等待队列
如果进程需要睡眠等待一个锁,需要把自己放入锁的等待队列中。一般来说,进程会到队列的最后排队,PG 尽可能以先来后到的顺序授予锁。但是有一些例外:如果进程已经持有了与队列中某些进程冲突的锁,那么进程应当排到队列中第一个冲突进程之前。举个例子,假设目前:
- Lock A 正被 P1 进程持有,等待队列中已有 P2 进程
- Lock B 正被 P3 进程持有,等待队列中已有 P2 进程
LOCK A: [P1] --> P2
LOCK B: [P3] --> P2
此时,P3 想要获得 Lock A。如果它被添加到了 Lock A 等待队列的尾部:
LOCK A: [P1] --> P2 --> P3
LOCK B: [P3] --> P2
当 P1 进程释放 Lock A 后,将会唤醒 P2。P2 将获得 Lock A 后形成如下局面:
LOCK A: [P2] --> P3
LOCK B: [P3] --> P2
此时,P2 等待 P3 释放 Lock B,P3 等待 P2 释放 Lock A,形成了一个典型的死锁。为了避免发生这种情况,在 P3 加入 Lock A 队列时,需要找到会与自己已持有锁发生冲突的第一个进程 (P2),并插队到该进程之前:
LOCK A: [P1] --> P3 --> P2
LOCK B: [P3] --> P2
这个优化并不是必须的,因为后面将介绍的死锁检测算法也会干这件事 (重排等待队列的顺序)。但是这里提前这么做,可以避免一次死锁检测的超时。
Wait-For 图
由于 PostgreSQL 定义了各种锁的兼容性,同时服从 2PL,因此死锁产生的前三个条件 (互斥/请求和保持/不抢占) 已经满足。死锁检测函数只需要检测出发生了第四个条件 (环路等待),就能够确定发生了死锁。环路等待可被建模为一张 有向图:图的顶点代表进程,边代表进程间的等待关系。边总是从一个等待锁的进程指向一个正在持有锁且锁请求冲突的进程:
typedef struct
{
PGPROC *waiter; /* the leader of the waiting lock group */
PGPROC *blocker; /* the leader of the group it is waiting for */
LOCK *lock; /* the lock being waited for */
int pred; /* workspace for TopoSort */
int link; /* workspace for TopoSort */
} EDGE;如果有向图内出现了环路,那么意味着出现了死锁。为了解决死锁,应当牺牲图中的一个或多个顶点 (事务回滚) 以及连接它们的边,从而打破图中的环路。每一个进程进入死锁检测函数时,都会从 当前进程 出发,向自己依赖的等待关系进行深度优先搜索,同时构造等待图。三种可能的结果:
- 没有环路
- 有环路,但环路没有回到起点
- 有环路,且环路回到了起点 (当前进程)

只有第三种情况,死锁检测算法才会报告出现死锁。在后续处理中,通过取消当前进程的事务来破坏环路,解决死锁。对于第二种情况,取消当前进程不会对解除死锁有任何帮助,应当等 P2 进程发生死锁超时触发死锁检测时,从 P2 进程出发检测到一个回到 P2 的环路,P2 进程才会尝试回滚自己的事务,破坏这个环路。PostgreSQL 通过以下函数判断从当前进程出发是否存在等待关系环路:
static bool
FindLockCycle(PGPROC *checkProc,
EDGE *softEdges, /* output argument */
int *nSoftEdges) /* output argument */
{
nVisitedProcs = 0;
nDeadlockDetails = 0;
*nSoftEdges = 0;
return FindLockCycleRecurse(checkProc, 0, softEdges, nSoftEdges);
}
static bool
FindLockCycleRecurse(PGPROC *checkProc,
int depth,
EDGE *softEdges, /* output argument */
int *nSoftEdges) /* output argument */
{
/* DFS */
}等待队列重排序
如果从当前进程出发检测出了环路,在回滚自身事务之前,PostgreSQL 提供了一次 最后的挣扎机会:重新安排锁等待队列中进程的顺序。如果新的锁等待次序能够消除图中的环路,那么自身事务就无需回滚。这是 PG 死锁检测算法中最复杂的部分。
PostgreSQL 为区别于上述等待关系模型中的边 (hard edge),提出了所谓 soft edge 的概念。它们的区别:
- Hard edge:位于锁等待队列中的进程 A 指向持有该锁且 lock mode 冲突的进程 B (进程 B 已持有锁)
- Soft edge:位于锁等待队列中的进程 A 指向位于同一等待队列中的进程 B (进程 A、B 都未持有锁)
举个例子,假设:
- P1 正持有 4 级的 Lock A
- P2 请求持有 8 级的 Lock A,因 lock mode 冲突而进入等待队列
- P3 请求持有 5 级的 Lock A,因 lock mode 冲突而进入等待队列
LOCK A: [P1] --> P2 --> P3
L4 L8 L5
根据上述定义,从 P2 到 P1,从 P3 到 P1,各有一条 hard edge。而 P3 到 P2 虽然暂未形成 hard edge 关系,但是随着后续 P1 释放锁,P2 持有锁后,由于 P3 请求的 lock mode 与 P2 冲突,也将会形成一条 P3 到 P2 的 hard edge。因此,根据上述定义,P3 到 P2 之间形成了一条 soft edge:
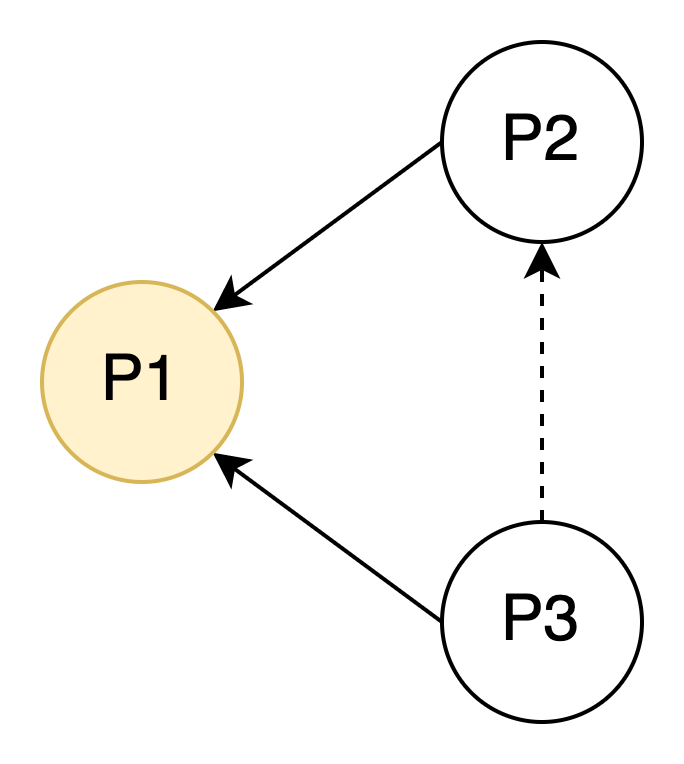
Soft edge 指的是目前暂时还没有形成,但是后续将会形成的等待关系。在检测死锁时,soft edge 比 hard edge 优先级低 (两个进程间同时存在 hard edge 和 soft edge 时,认为它们之间是 hard edge 关系),但同样是一条参与环路检测的边。由于 soft edge 等待关系中的两个进程 (如 P2、P3) 暂时都还没有获得锁,因此调换它们在等待队列中的相对顺序不会对图中已有的任何 hard edge 有影响,但可能导致其它 soft edge 的增加或减少。如果能找到一种相对顺序,使得图中包括 hard edge 和 soft edge 在内的环路被打破,那么锁等待队列按照这个顺序重排,就不再会产生死锁,当前事务也不需要回滚了。这个算法有一定的开销,但是在回滚一个事物的代价面前,还是值得试一试的。
举个例子:有三把锁 A、B、C,分别由四个事务 (T1、T2、T3、T4) 并发访问,S/X 分别表示共享锁/排他锁。其访问时序如下:
-------------------------------> time
Transaction 1 S(A)
Transaction 2 S(B) X(C)
Transaction 3 S(C) X(A)
Transaction 4 X(A) X(B)假设事务已按上述时序获取锁后,以执行 T3 事务的进程作为起点,将会构造出如下所示的 wait-for graph:
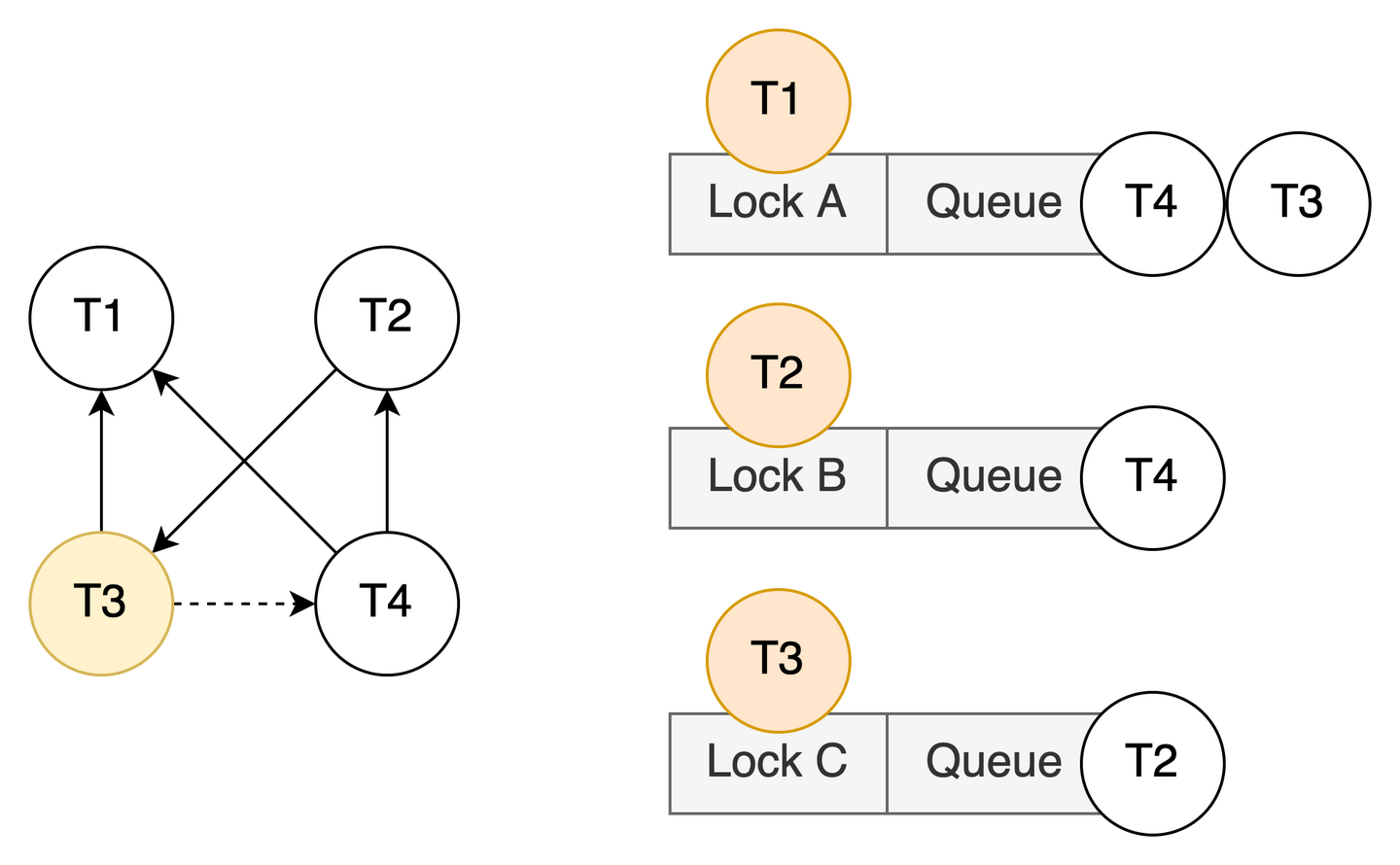
其中 T3 对 Lock A 加排他锁不仅导致 T3 到 T1 形成一条 hard edge,还导致 T3 到 T4 形成一条 soft edge:因为它们都位于 Lock A 的等待队列中,并且请求的 lock mode 冲突 (排他锁 vs 排他锁)。如图,T3、T4、T2 形成了环路。后续随着 T1 commit,T4 获得 Lock A,从 T3 到 T4 的 soft edge 将坐实为 hard edge:
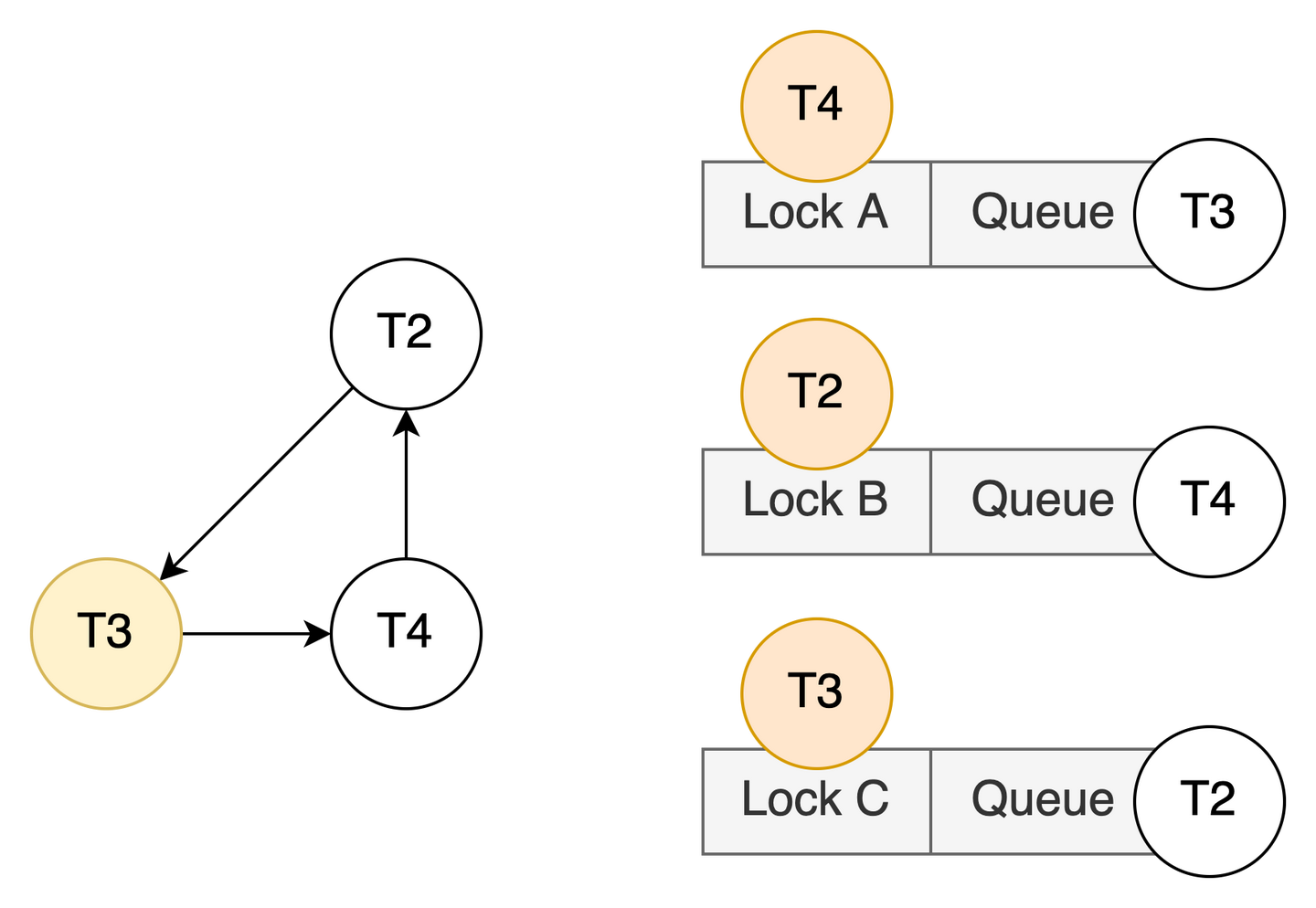
此时,将不得不对 T3 进行 rollback,才能解除死锁。那么如果对 Lock A 的等待队列进行重排序呢?试着反转从 T3 到 T4 的 soft edge 两端进程的顺序:
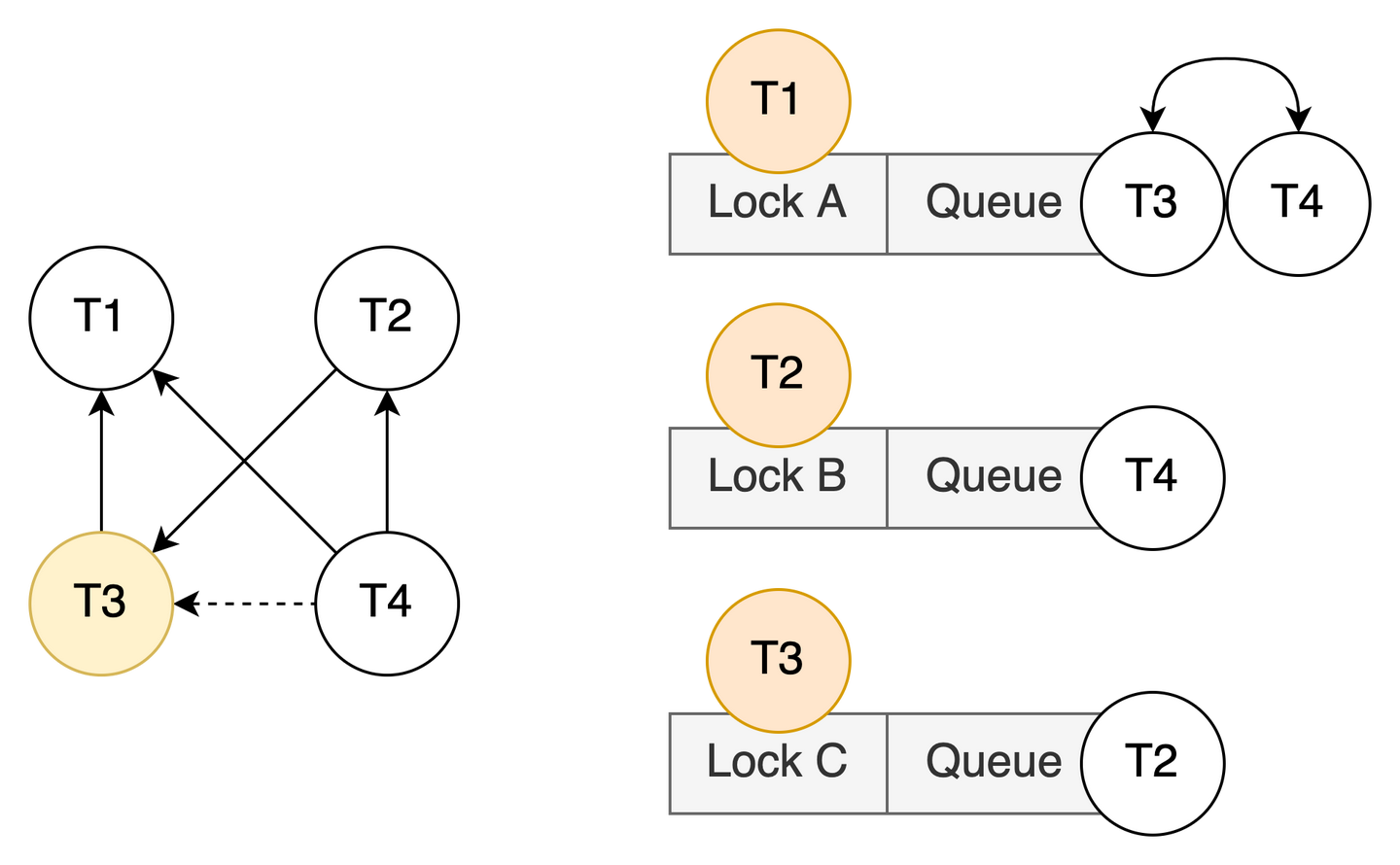
在等待队列中将 T3 调整到 T4 之前,此时从 T3 到 T4 的 soft edge 没有了。由于 T4 和 T3 的锁请求 lock mode 依旧冲突 (排他锁 vs 排他锁),从 T4 到 T3 将会形成一条 soft edge。此时图中不存在任何环路,因此无需回滚 T3。死锁解除了,也没有任何事务发生回滚。
死锁检测对 Group Locking 的支持
目前,PostgreSQL 支持并行执行,这意味着死锁可能发生在几个进程组之间,而不是几个独立的进程之间。这种设计并没有给 PG 的死锁检测的算法带来很多改动,因为 PG 目前规定同一个 parallel group 内的所有进程之间获取锁时不会发生冲突,同一个组内的进程可以同时对同一个表获取自斥的锁。如果不这样设计,在组内进程之间很容易发生 自死锁。
PG 在共享内存的进程数据结构 PGPROC 中维护了三个 field 支持 group locking:
lockGroupLeader- 当进程不参与并行执行时,该指针为空
- 当进程参与并行执行,并成为 parallel leader 时,该指针指向自己
- 当进程参与并行执行,并成为 parallel worker 时,该指针指向 parallel leader
lockGroupMembers当进程成为 parallel leader 时启用,是维护 parallel group 内的 leader 和所有 parallel worker 的链表lockGroupLink指向进程自身在上述链表中的节点
/*
* Support for lock groups. Use LockHashPartitionLockByProc on the group
* leader to get the LWLock protecting these fields.
*/
PGPROC *lockGroupLeader; /* lock group leader, if I'm a member */
dlist_head lockGroupMembers; /* list of members, if I'm a leader */
dlist_node lockGroupLink; /* my member link, if I'm a member */在死锁检测代码中,判断两个进程是否存在等待关系时,会首先判断两个进程的 lockGroupLeader 是否相同 (两个进程是否属于同一个 parallel group)。如果两个进程同属一个 parallel group,那么这两个进程之间的锁请求不会发生冲突,因而不存在等待关系,跳过。寻找 hard edge 时的处理:
/* 获取已经持有锁的进程队列,遍历 (找 hard edge) */
procLocks = &(lock->procLocks);
proclock = (PROCLOCK *) SHMQueueNext(procLocks, procLocks,
offsetof(PROCLOCK, lockLink));
while (proclock)
{
PGPROC *leader;
/* 队列中的等待进程,以及该进程所在组的 leader */
proc = proclock->tag.myProc;
pgxact = &ProcGlobal->allPgXact[proc->pgprocno];
leader = proc->lockGroupLeader == NULL ? proc : proc->lockGroupLeader;
/* A proc never blocks itself or any other lock group member */
/* 如果两个进程属于不同的 lock group (leader 不同),才可能存在等待关系 */
if (leader != checkProcLeader)
{
/* 检测两个进程之间是否存在 hard edge */
}
/* 下一个等待进程 */
proclock = (PROCLOCK *) SHMQueueNext(procLocks, &proclock->lockLink,
offsetof(PROCLOCK, lockLink));
}寻找 soft edge 时的处理:
/* 获取已经持有锁的进程队列,遍历 (找 soft edge) */
for (i = 0; i < queue_size; i++)
{
PGPROC *leader;
/* 等待队列上的进程,以及该进程所在组的 leader */
proc = procs[i];
leader = proc->lockGroupLeader == NULL ? proc :
proc->lockGroupLeader;
/* 如果两个进程同属一个 lock group (leader 相同),那么不可能发生锁冲突,跳出 */
if (leader == checkProcLeader)
break;
/* Is there a conflict with this guy's request? */
/* 两个进程属于不同 lock group,则继续检测锁冲突 */
if ((LOCKBIT_ON(proc->waitLockMode) & conflictMask) != 0)
{
/* 检测两个进程之间是否存在 soft edge */
}
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号