

MySQL优化
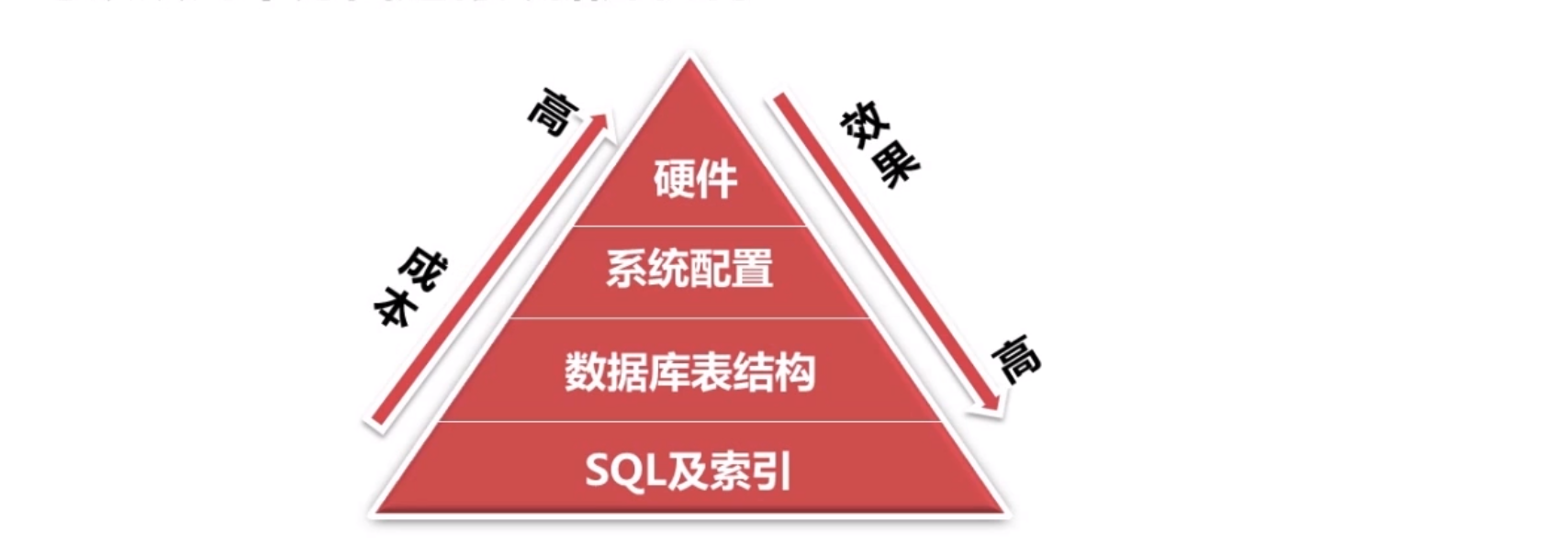
数据库优化目的
- 避免出现页面错误
- 增加DB稳定性
- 提高网站整体性能
DB优化方向
数据准备
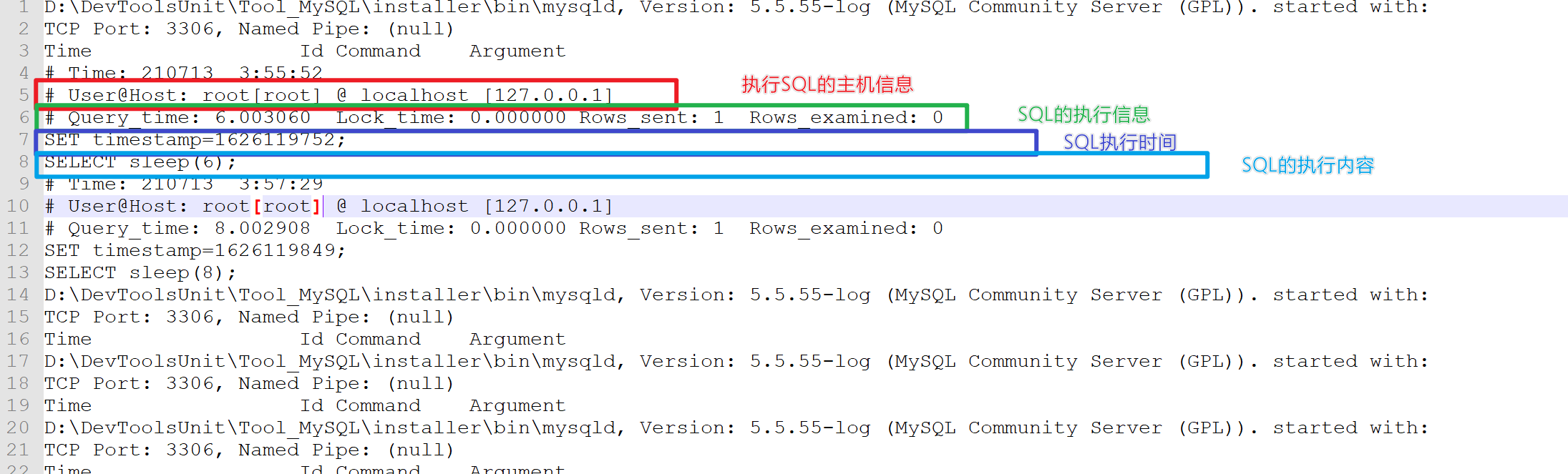
MySQL慢查询日志开启方式和存储格式
如何发现有问题的SQL 答:使用慢查询日志或EXPLAIN关键字进行语句分析

mysql> show variables like "%query_log%"; +---------------------+----------------------------------+ | Variable_name | Value | +---------------------+----------------------------------+ | slow_query_log | ON | | slow_query_log_file | D:/MySQL_data/slow_query_log.txt | +---------------------+----------------------------------+ 2 rows in set (0.00 sec) mysql> show variables like "long_query_time"; +-----------------+----------+ | Variable_name | Value | +-----------------+----------+ | long_query_time | 3.000000 | +-----------------+----------+ 1 row in set (0.00 sec)
慢查询日志分析工具 —— mysqldumpslow
慢查询日志分析工具 —— pt-query-digest
安装连接:

问题SQL分析

SQL以及索引优化 - EXPLAIN



COUNT()和MAX()优化
- MAX()
mysql> use sakila; Database changed mysql> select max(payment_date) from payment; +---------------------+ | max(payment_date) | +---------------------+ | 2006-02-14 15:16:03 | +---------------------+ 1 row in set (0.12 sec) mysql> explain select max(payment_date) from payment; +----+-------------+---------+------+---------------+------+---------+------+-------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+------+---------+------+-------+-------+ | 1 | SIMPLE | payment | ALL | NULL | NULL | NULL | NULL | 16451 | | +----+-------------+---------+------+---------------+------+---------+------+-------+-------+ 1 row in set (0.03 sec) mysql> create index idx_payment_date on payment(payment_date); Query OK, 0 rows affected (0.40 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select max(payment_date) from payment; +----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+ | 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away | +----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+ 1 row in set (0.00 sec)
- COUNT()
COUNT(*)和COUNT(1)都会将 null 统计在内
mysql> select * from tmp; +------+ | id | +------+ | NULL | | 2 | | 3 | | 0 | +------+ 4 rows in set (0.00 sec) mysql> select count(*) from tmp; +----------+ | count(*) | +----------+ | 4 | +----------+ 1 row in set (0.00 sec) mysql> select count(1) from tmp; +----------+ | count(1) | +----------+ | 4 | +----------+ 1 row in set (0.00 sec)
使用COUNT的正确案例
eg: 查出2006年电影数量
SELECT COUNT(release_year='2006' OR NULL) FROM film;
子查询优化

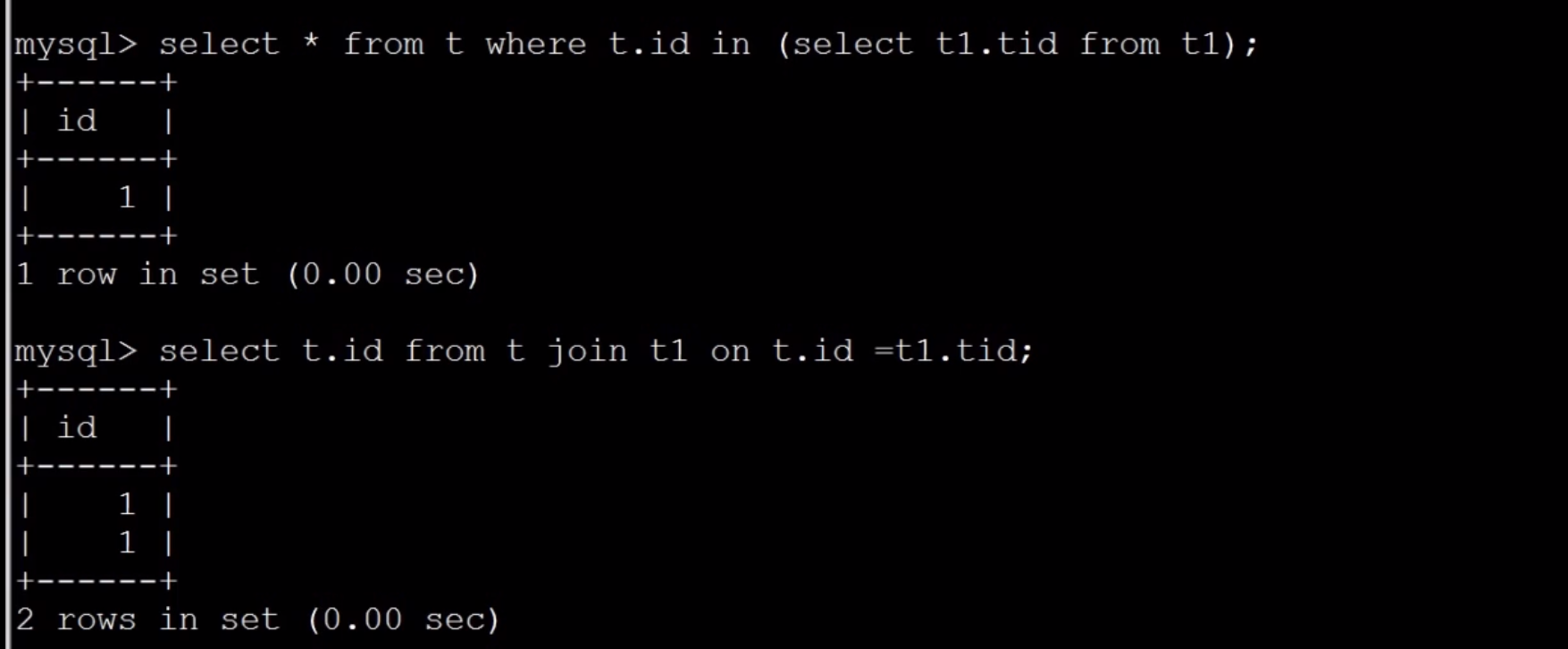
group by查询优化

limit查询优化

mysql> EXPLAIN select film_id, description from film order by title limit 50; +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ | 1 | SIMPLE | film | ALL | NULL | NULL | NULL | NULL | 949 | Using filesort | +----+-------------+-------+------+---------------+------+---------+------+------+----------------+ 1 row in set (0.00 sec)
- 优化1: 使用有索引的列或主键进行ORDER BY操作
mysql> EXPLAIN select film_id, description from film order by film_id limit 50; +----+-------------+-------+-------+---------------+---------+---------+------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------+ | 1 | SIMPLE | film | index | NULL | PRIMARY | 2 | NULL | 50 | | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------+ 1 row in set (0.04 sec)
- 优化2: 记录上次返回的主键,在下一次查询时使用主键过滤
mysql> EXPLAIN select film_id, description from film where film_id > 55 and film_id <= 60 order by film_id limit 1, 5; +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | film | range | PRIMARY | PRIMARY | 2 | NULL | 5 | Using where | +----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ 1 row in set (0.05 sec)
避免了数据量大时扫描过多的记录(保证索引有序)
建立合适的索引

- 如何判断指定字段的离散程度
mysql> select count(distinct customer_id), count(distinct staff_id) from payment; +-----------------------------+--------------------------+ | count(distinct customer_id) | count(distinct staff_id) | +-----------------------------+--------------------------+ | 599 | 2 | +-----------------------------+--------------------------+ 1 row in set (0.01 sec) customer_id的离散程度 高于 staff_id
索引优化SQL

- 如何查找重复以及冗余索引?


数据库结构优化



数据库表范式优化`
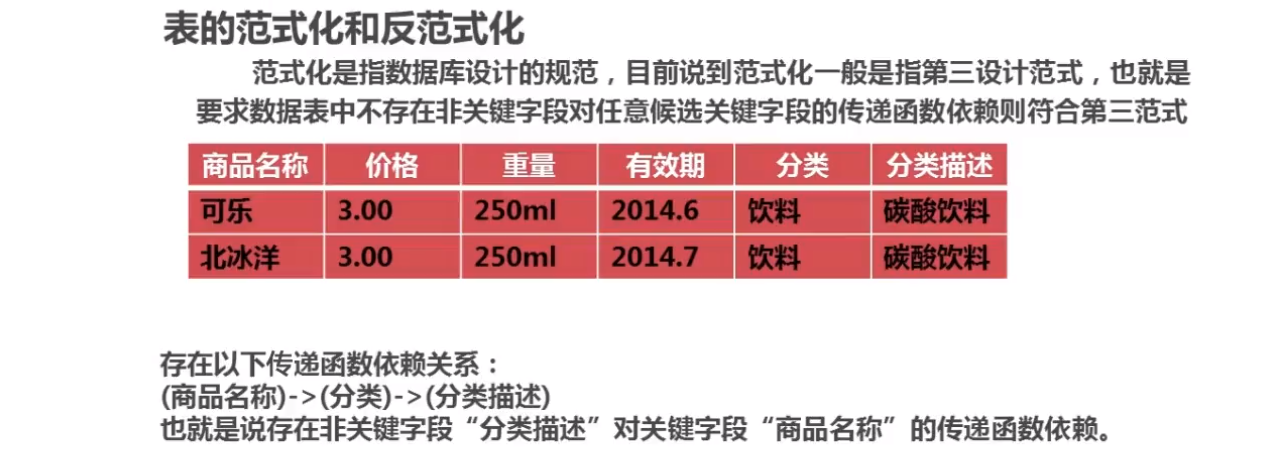
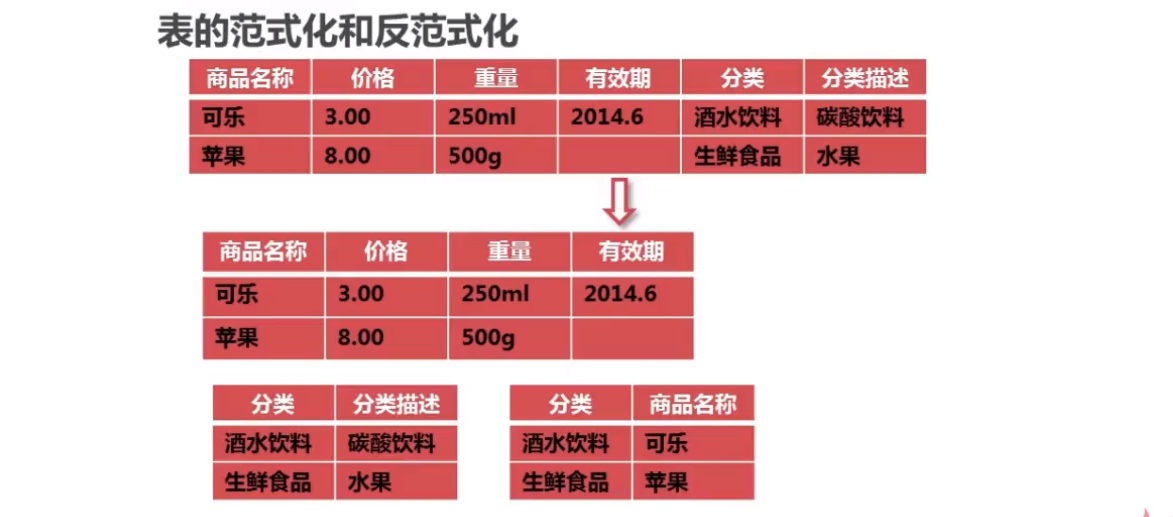
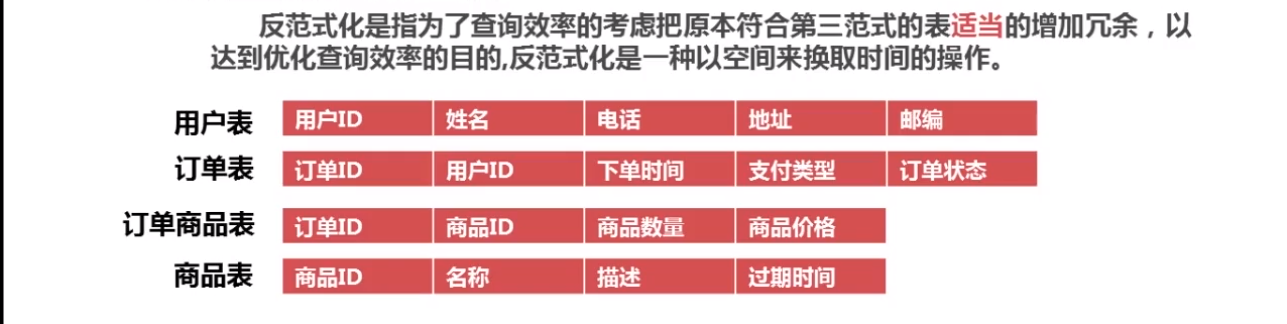
反范式优化

数据库表的垂直拆分

数据库表的水平拆分

数据库系统配置优化


MySQL配置文件优化


学而不思则罔,思而不学则殆!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具
2020-08-14 Maven构建多模块项目(Build more than one project at once)