自我学习与理解:keras框架下的深度学习(二)二分类和多分类问题
本文第一部分是对数据处理中one-hot编码的讲解,第二部分是对二分类模型的代码讲解,其模型的建立以及训练过程与上篇文章一样;在最后我们将训练好的模型保存下来,再用自己的数据放入保存下来的模型中进行分类(在后面的文章中会详细讨论如何使用自己的数据去训练模型,或者让保存下来的模型去处理自己的数据)。第三部分是多分类模型,多分类的过程和二分类很相似,只是在代码中有些地方需要做出调整。
第二部分是本文的重点。
一:one-hot编码
通过第一篇文章我们知道,对于使用keras来进行深度学习网络的搭建,因为keras中已经把深度学习的步骤都打包成函数或者文件,我们只需要调用即可,所以我们需要在数据的处理(怎么把数据处理好放入框架里面)和参数的调整上用功夫。在本文中,我们讨论一种数据处理的方法:ong-hot编码,即根据一个矩阵生成一个只有0和1的矩阵,0表示之前的矩阵在这个索引处没有数值,1表示之前的矩阵在这个索引处有数值。比如说有一条数据是a=[1,8,4,2],使用one-hot编码生成一行10列的矩阵,那么将会是[0,1,1,0,1,0,0,0,1,0],表示这个矩阵表示分别在索引1,2,3,8处有数值,而其他地方没有数值(one-hot矩阵的列数要大于a矩阵中数值的最大数)。
下面我们在pycharm中随机生成一个[3,10],取值在0到20之间的矩阵,然后生成[3,20]的one-hot矩阵。
1.首先生成[3,10]的矩阵a:
import numpy as np c1 = np.random.choice(20,10,replace=False) #在0到20之间我们随机选择10不重复的数字,replace=False 表示选择的数字不能有重复 c2 = np.random.choice(20,10,replace=False) c3 = np.random.choice(20,10,replace=False) a = np.array([c1,c2,c3]) #把前面三个[1,10]矩阵合成[3,10]矩阵
我们使用np.random.choice(20,10,replace=False)来生成10个在0到20之间不重复的数字,replace= False表示生成的数字不能有重复。
2.然后我们根据矩阵a生成one-hot矩阵b:
def one_hot(sample,dim=20): result = np.zeros((len(sample),dim)) for i,sample in enumerate(sample): #enumerate会给i和sample自动编组 result[i,sample] = 1. #索引在哪个位置有数值,就给赋值为1 return result b = ver(a)
(1)在第一行代码中,我们创建一个one-hot函数。
(2)第二行代码我们生成一个行是数据个数,列是20的全零矩阵result(列是矩阵a中数值最大的数)。
(3)第三行代码中的enumerate函数表示将一个可遍历的数据对象(如列表)组合为一个索引序列,同时列出数据和数据下标。比如说我们选择随机给定一个矩阵:
list_a = [[2,3,4,5],[4,6,2,4]]
然后打印矩阵list_a和使用enumerate函数后的矩阵:
print('list_a为:',list_a) print('enumerate函数生成的矩阵为:',list(enumerate(list_a)))
输出结果如下:
list_a为: [[2, 3, 4, 5], [4, 6, 2, 4]]
enumerate函数生成的矩阵为: [(0, [2, 3, 4, 5]), (1, [4, 6, 2, 4])]
整个过程:
list_a = [[2,3,4,5],[4,6,2,4]] print('list_a为:',list_a) print('enumerate函数生成的矩阵为:',list(enumerate(list_a))) 输出结果: list_a为: [[2, 3, 4, 5], [4, 6, 2, 4]] enumerate函数生成的矩阵为: [(0, [2, 3, 4, 5]), (1, [4, 6, 2, 4])]
第四行代码表示在sample有数值的索引处赋值为1.
最后返回result矩阵,并且根据数据a生成one-hot矩阵b。
(4)打印矩阵a和b,显示结果:
print(b) 结果: a= [[ 6 15 14 9 19 13 4 1 2 3] [ 9 11 14 17 13 12 2 10 4 18] [18 2 11 8 5 14 13 12 19 16]] b= [[0. 1. 1. 1. 1. 0. 1. 0. 0. 1. 0. 0. 0. 1. 1. 1. 0. 0. 0. 1.] [0. 0. 1. 0. 1. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 0. 0. 1. 1. 0.] [0. 0. 1. 0. 0. 1. 0. 0. 1. 0. 0. 1. 1. 1. 1. 0. 1. 0. 1. 1.]]
3.总代码:
import numpy as np c1 = np.random.choice(20,10,replace=False) #在0到20之间我们随机选择10不重复的数字,replace=False 表示选择的数字不能有重复 c2 = np.random.choice(20,10,replace=False) c3 = np.random.choice(20,10,replace=False) a = np.array([c1,c2,c3]) #把前面三个[1,10]矩阵合成[3,10]矩阵 def ver(sample,dim=20): result = np.zeros((len(sample),dim)) for i,sample in enumerate(sample): #enumerate会给i和sample自动编组 result[i,sample] = 1. #索引在哪个位置有数值,就给赋值为1 return result b = ver(a) print('a=',a) print('b=',b)
以上就是对数据处理的one-hot方法,下面我们详细讲解keras框架下的二分类问题。
二:二分类问题
对于二分类问题,我们这里采用的数据集是IMDB,它包含50000条严重两极分化的评论,数据集分为用于训练的25000跳评论和用于测试的25000条评论,两者都包含50%的证明评论和50%的负面评论。
1, 对于数据的预处理
首先我们使用keras导入imdb数据集:
from keras.datasets import imdb (train_data,train_label),(test_data,test_label)=imdb.load_data(num_words=10000)
其过程和手写体的导入过程一样,不过多了一个参数的导入:num_woeds表示只保留训练数据集前10000个最常出现的单词,低频率的单词会被舍去(比如说人名)
在train_data内的数据是1到10000的数字,表示每个数字出现的频率;而train_label是0或1的单个数字,0表示负面评论,1表示正面评论。比如说我们打印第一个数据以及它的标签(打印过程代码不算入最后的总代码,只是查看数据):
print(train_data[0]) print(train_label[0]) [1, 14, 22, 16, …19, 178, 32] 1
第一个数据一共包含218个单词,而它的标签是1。
这里,你很可能会有问题,为什么要把单词变成数字?这样深度学习的框架是怎么学习到评论的好坏的?我的理解是比如说给我们人类一些数字,当给你的是单数的时候就给你糖,当是偶数的时候就给你一个惩罚,次数多了之后我们就知道了单数表示这有糖,是好的。类似于这个,负面评论中可能有很多负面的单词,因为它们是编号码的,所以负面的单词不太可能出现在正面评论中,又或者出现的次数很少。所以我们把单词变成纯数字,交给深度学习去处理,从而得到一个正面或者负面评价的结果(让单纯的数值赋予其不同的意义)。
言归正传,在导入数据后,我们需要对数据进行处理,在把数据给到深度学习的时候,我们需要把数据变成张量,把数据向量化(简化数据)所以我们采用one-hot编码的方法,把train_data和test_data中的数据变成元素只有0和1的矩阵,至于train_label和test_label,因为只有单独的一个数据,我们用numpy把它进行one-hot编码,具体代码如下:
def one_hot(sample,dim=10000): result = np.zeros((len(sample),dim)) for i,sample in enumerate(sample): result[i,sample] = 1 return result train_data = one_hot(train_data) test_data = one_hot(test_data) train_label = np.asarray(train_label).astype('float32') test_label = np.asarray(test_label).astype('float32')
one-hot的方法在上面已经详细讲述过了,所以这里不详细讲解;在这里我们定义一个one_hot函数,然后把train_data和test_data的数据放进去处理。我们打印train_data[0]和train_lable[0]看看数据是什么样的:
print(train_data[0]) print(test_label[0]) [0. 1. 1. ... 0. 0. 0.] 0.0
2.搭建网络框架
在这里我们采用三层全连接层,其中前两层是16个隐藏层,采用的函数时relu激活函数;最后是一层输出一个标量,表示评论的情感,采用sigmid激活函数。代码如下所示:
from keras import models from keras import layers model = models.Sequential() model.add(layers.Dense(16,activation='relu',input_shape=(10000,))) model.add(layers.Dense(16,activation='relu')) model.add(layers.Dense(1,activation='sigmoid'))
对于全连接层(Dense)来说,16个隐藏单元,表示将输入的数据投影到16维表示空间中。Relu函数是一个非线性的激活函数,其函数为:。假设输入的数据是X(单列矩阵),那么假设经过16个隐藏单元的全连接层后的输出为Z,则可以得到:Z=Relu(dot(W,X)+b)。其中W表示权重矩阵,其形状是(X,16),b是偏执向量,含有16个数值。当隐藏单元个数越大时,网络越能学到复杂的表示,但是其计算代价也会更高。
3.编译
model.compile( optimizer='rmsprop', #可以导入包,自己定义 loss='binary_crossentropy', metrics=['accuracy'] )
在编译中,我们可以自定义损失函数loss,通过导入keras中的优化器,对其参数进行修改,从而使模型得到更好的效果。下面是导入损失函数的代码(替换上面的代码):
from keras import optimizers model.copile( optimizer= optimizers.RMSprop(lr=0.001), #可以导入包,自己定义 loss='binary_crossentropy', metrics=['accuracy'] )
为了更好的理解优化器的内容,我们可以在keras的文件里面找到optimizers.py文件,里面包含着很多个类,每个类都是一种优化器的具体过程。我们找到RMSprop优化函数:
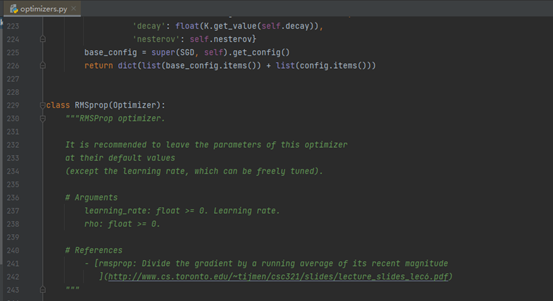
然后查看lr,如图所示:
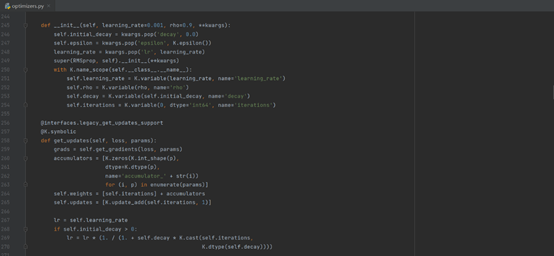
4.循环训练
训练开始前,我们需要说明一点,就是在训练阶段(先不去管测试集),我们需要在训练集中分出一部分数据来进行检测,检测我们的模型泛化能力,也就是检测模型遇到新数据时的表现(有时候虽然准确率高,其实是模型把数据和对应的标签背了下来,对新数据的处理会十分差劲)所以,在我们开始循环时,我们在训练集中抽一部分做验证集,具体代码如下:
train_data_val = train_data[:10000] train_data = train_data[10000:] train_label_val = trian_label[:10000] train_label = trian_label[10000:]
其中在train_data和train_label中抽出10000个数据和标签作为验证集(validation),剩下的作为训练集。注:[:10000]表示取0到9999索引的数据(也就是取10000个数据,但是不要10000)
下面我们把数据丢入网络中进行训练以及验证:
history=model.fit(train_data,train_label,epochs=100,batch_size=512,validation_data=(train_data_val,train_lable_val ))
其中,我们把模型训练以及验证得到的结果赋值给history(model.fit()中得到的结果是以字典的形式返回)这样方便我们后面画图查看模型训练以及验证的情况;上述函数fit中的参数于上文一致,不过多了一个验证的过程,即:validation_data=(train_data_val,train_lable_val )
下面我们引用history中的参数,画图查看训练以及验证的情况,代码如下:
history_dict=history.history loss_values = history_dict['loss'] val_loss_values=history_dict['val_loss'] epochs=range(1,len(loss_values)+1) plt.plot(epochs,loss_values,'bo',label='training loss') plt.plot(epochs,val_loss_values,'b',label='validation loss') plt.title('training and validation') plt.xlabel('epochs') plt.ylabel('loss') plt.legend() plt.show()
第一行代码表示,我们使用history函数调用history中的参数赋值给history_dict,第二行第三行表示取出训练损失值和验证损失值(在这里,若是不知道history中有什么值,可以在运行时查看页面,history会有四个key以及他们返回的value,其中key分别是:loss,val_loss,acc,val_acc;分别表示损失值,验证损失值,准确率,验证准确率)
第四行表示画图的横坐标.
第五到十一行是画图,运行以上代码,将会得到的图形如图所示:
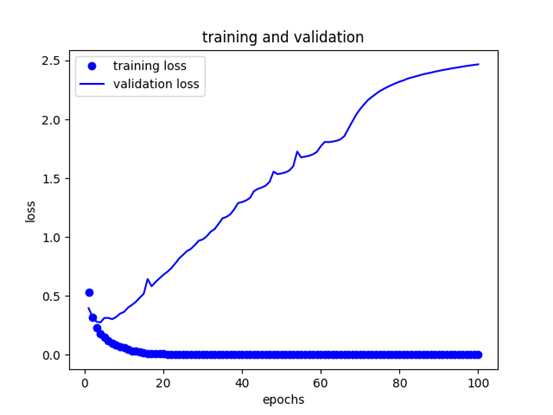
图中训练集的损失值是不断下降,逼近于零,但是当模型运行验证集的时候,也就是遇见新的数据时,在大概第4个epoch的地方,其验证集的损失值直线上升,出现过拟合现象。对于过拟合的处理有很多方法,会在以后的文章中阐述,这里我们让epochs为4,总共运行4论就结束,让其处于在验证集最佳的位置。(这里只画了损失值的图像,对于准确率(acc)的图像可以自行编写代码查看)我们最后更改把histor=model.fit()这句代码更改成如下代码:
history=model.fit(train_data,train_label,epochs=4,batch_size=512,validation_data=(train_data_val,train_lable_val ))
5.测试训练的网络模型
result = model.evaluate(test_data,test_label) print(result)
最后使用evaluate函数进行模型的最后测试,并且把数值打印出来,查看测试的结果。结果:[0.32555921449184416, 0.8685600161552429],准确率可到达86%。
7.总代码:
from keras.datasets import imdb from keras import models from keras import layers (train_data,train_label),(test_data,test_label)=imdb.load_data(num_words=10000) def one_hot(sample,dim=10000): result = np.zeros((len(sample),dim)) for i,sample in enumerate(sample): result[i,sample] = 1 return result train_data = one_hot(train_data) test_data = one_hot(test_data) train_label = np.asarray(train_label).astype('float32') test_label = np.asarray(test_label).astype('float32') model = models.Sequential() model.add(layers.Dense(16,activation='relu',input_shape=(10000,))) model.add(layers.Dense(16,activation='relu')) model.add(layers.Dense(1,activation='sigmoid')) model.compile( optimizer='rmsprop', #可以导入包,自己定义 loss='binary_crossentropy', metrics=['accuracy'] ) train_data_val = train_data[:10000] #[:10000] train_data = train_data[10000:] train_label_val = trian_label[:10000] train_label = trian_label[10000:] history=model.fit(train_data,train_label,epochs=4,batch_size=512,validation_data=(train_data_val,train_lable_val )) history_dict=history.history loss_values = history_dict['loss'] val_loss_values=history_dict['val_loss'] epochs=range(1,len(loss_values)+1) plt.plot(epochs,loss_values,'bo',label='training loss') plt.plot(epochs,val_loss_values,'b',label='validation loss') plt.title('training and validation') plt.xlabel('epochs') plt.ylabel('loss') plt.legend() plt.show() result = model.evaluate(test_data,test_label) print(result)
8.用训练好的模型处理自己的数据
在我们使用自己的数据识别的时候,我们先把自己的模型保存下来,在代码的最后我们加上下面的代码保存模型:
model.save('tow_classes.h5')
(类似的,我们可以在网上下载别人训练好的模型然后进行自己数据的识别)我们会在旁边文件目录里面看到保存的该模型:

然后我们在保存的模型下文件的同目录下,重新创建一个.py文件,进行自己数据的处理。
首先我们使用keras导入自己的模型文件:
from keras import models model=models.load_model('tow_classes.h5')
然后我们随机制造一组数据放入模型中进行预测(可以套用到之前手写体数字识别的模板中,不过得对图片进行处理)
随机生成数据a(这里只做示范,数据没有包含任何信息):
a0 = np.random.choice(2000,200,replace=False) a1 = np.random.choice(2000,200,replace=False) a2 = np.random.choice(2000,200,replace=False) a3 = np.random.choice(2000,200,replace=False) a4 = np.random.choice(2000,200,replace=False) a = np.array([[a1],[a2],[a3],[a4]])
随机生成4组数据,组成a矩阵
然后把矩阵a用one-hot编码:
def one_hot(sample,dim=10000): result=np.zeros((len(sample),dim)) for i,sample in enumerate(sample): result[i,sample] = 1 return result b=one_hot(a)
最后把b矩阵丢入模型得到一个分类的概率值以及最后分类的结果:
predict = model.predict(b)
predict_class = model.predict_classes(b)
打印结果查看:
print(predict) print(predict_class) [[0.02564826] [0.46361473] [0.98723143] [0.07622854]] [[0] [0] [1] [0]]
模型把第一、二、四组的数据分成第一类,把第三组数据分成第二类。
总代码:
from keras import models import numpy as np model=models.load_model('tow_classes.h5') a0 = np.random.choice(2000,200,replace=False) a1 = np.random.choice(2000,200,replace=False) a2 = np.random.choice(2000,200,replace=False) a3 = np.random.choice(2000,200,replace=False) a4 = np.random.choice(2000,200,replace=False) a = np.array([[a1],[a2],[a3],[a4]]) def one_hot(sample,dim=10000): result=np.zeros((len(sample),dim)) for i in enumerate(sample): result[i] = 1 return result b=one_hot(a) predict = model.predict(b) predict_class = model.predict_classes(b) print(predict) print(predict_class)
三、多分类问题
对于多分类问题,其模型框架与二分类十分类似,只是有几个个地方稍有不同,在多分类模型中,我们采用路透社数据集,它包含许多短新闻以及其对应的主题。一共包含46个不同的主题,每组至少有10组样本(数据集详情,参考reuters中的源代码)。
这里直接上总代码:
from keras.datasets import reuters from keras import layers from keras import models from keras.utils import to_categorical import numpy as np #1对数据的处理 (train_data,train_labels),(test_data,test_labels) = reuters.load_data(num_words=10000) def ver(sequence,dim=46): resules=np.zeros((len(sequence),dim)) for i,sequence in enumerate(sequence): #编号 属于哪个新闻社 resules[i,sequence]=1 #有数据的地方标1 return resules x_trian=ver(train_data) x_test=ver(test_data) one_hot_trian_labels = to_categorical(train_labels) one_hot_test_labels = to_categorical(test_labels) x_val=x_trian[:1000] partial_x_train=x_trian[1000:] y_val=one_hot_trian_labels[:1000] partial_y_train=one_hot_trian_labels[1000:] #2.搭建网络框架 model=models.Sequential() model.add(layers.Dense(64,activation='relu',input_shape=(10000,))) model.add(layers.Dense(64,activation='relu')) model.add(layers.Dense(46,activation='softmax')) #3.编译 model.compile( optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'] ) #4.循环训练 history=model.fit(partial_x_train,partial_x_train,epochs=9,batch_size=512,validation_data=(x_val,y_val))
#5.测试训练的网络模型 result = model.evaluate(x_test,one_hot_test_labels) print(result)
多分类的数据处理和二分类一样,但是有几点不同:1.我们把验证集的划分移到了前面(dim变成了46,表示有46个报社)。2.在搭建网络框架中,第一二层全连接层的隐藏元个数变成了64,最后输出变成了46,其激活函数变成了softmax激活函数。(注意:以上没有写出画图的代码,画图代码与二分类一样,最后得到结果是模型到了第九次左右的效果为最佳;在画图前,可以先让模型运行几十次,如,让epochs=30,最后得到图像后,根据图像获得合适的epochs)
在最后我们可以与二分类模型一样,保存训练好的模型,自己模拟一组数据放入模型中进行分类预测(在自己模拟数据放入模型预测之前,需要查看数据的格式,如查看训练集数据的第一个数据格式:print(trian_data[0].size))。(在后续的文章中,我们会从零开始制作自己的数据集,然后利用深度学习模型来进行处理)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号