
openGauss源码解析(180)
openGauss源码解析:AI技术(27)
8.6.3 实现原理
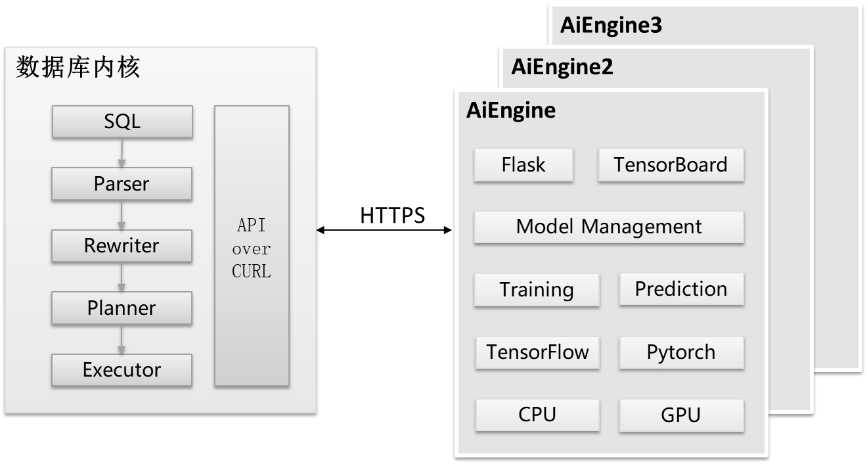
图8-15 AI查询性能预测架构示意图
总体而言,查询性能预测由数据库内核侧和AI Engine侧两个部分组成,如图8-15所示。
(1) 数据库内核侧除提供数据库基本功能外还需要对历史数据进行收集和持久化管理,并通过curl向AI Engine侧发送HTTPS请求。
(2) AI Engine提供模型训练、执行预测、模型管理等接口,基于Flask框架的服务端接受HTTPS请求,该流程如图8-16所示。
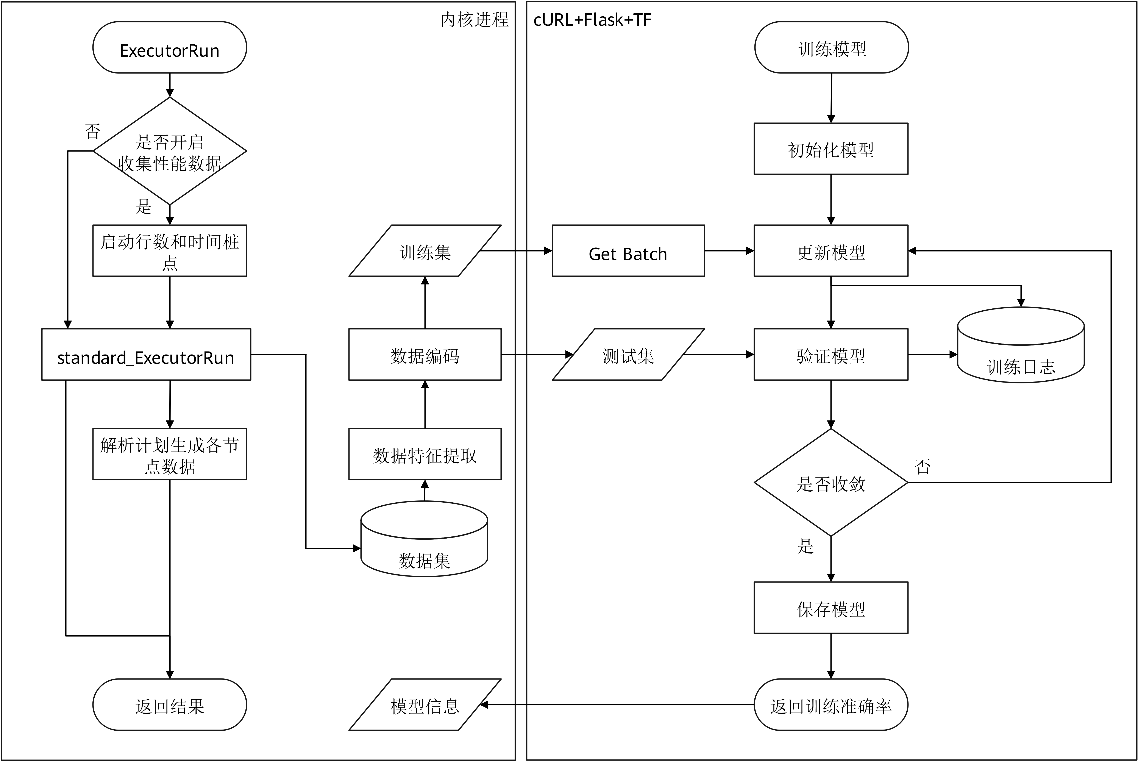
图 8-16 数据库内核和AI Engine进程关系示意图
开启数据收集相关参数后(其对性能可能有5%左右的影响,取决于实际业务负载情况),历史性能数据被持久化收集在数据库的系统表中,用于模型的训练。
模型训练之前,用户需要对模型参数进行配置(详见8.6.5使用示例)。用户训练指令下发之后,内核进程会向AI Engine侧发送configure请求,用于初始化机器学习模型。configure流程时序如图8-17所示。
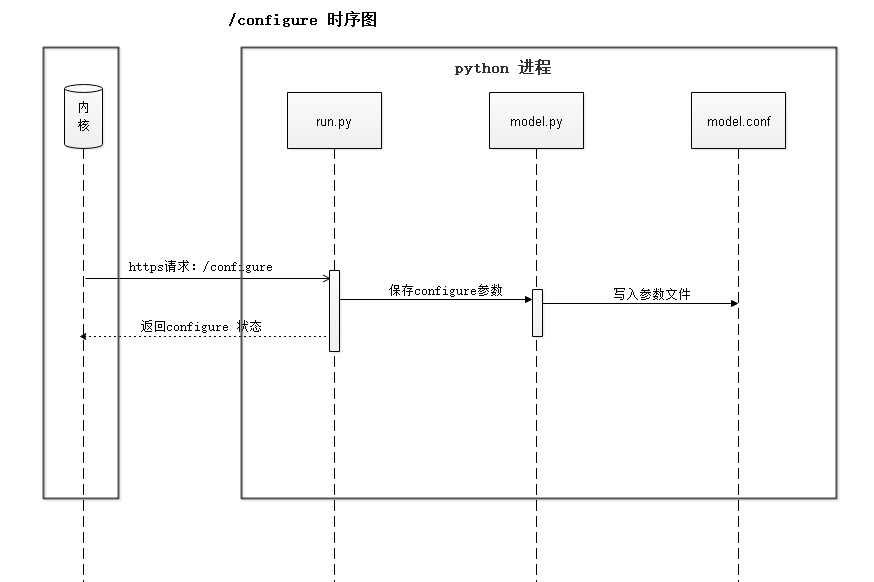
图8-17 configure流程时序图
模型配置成功后,内核进程向AI Engine侧发送train请求,触发训练,该流程如图8-18所示。
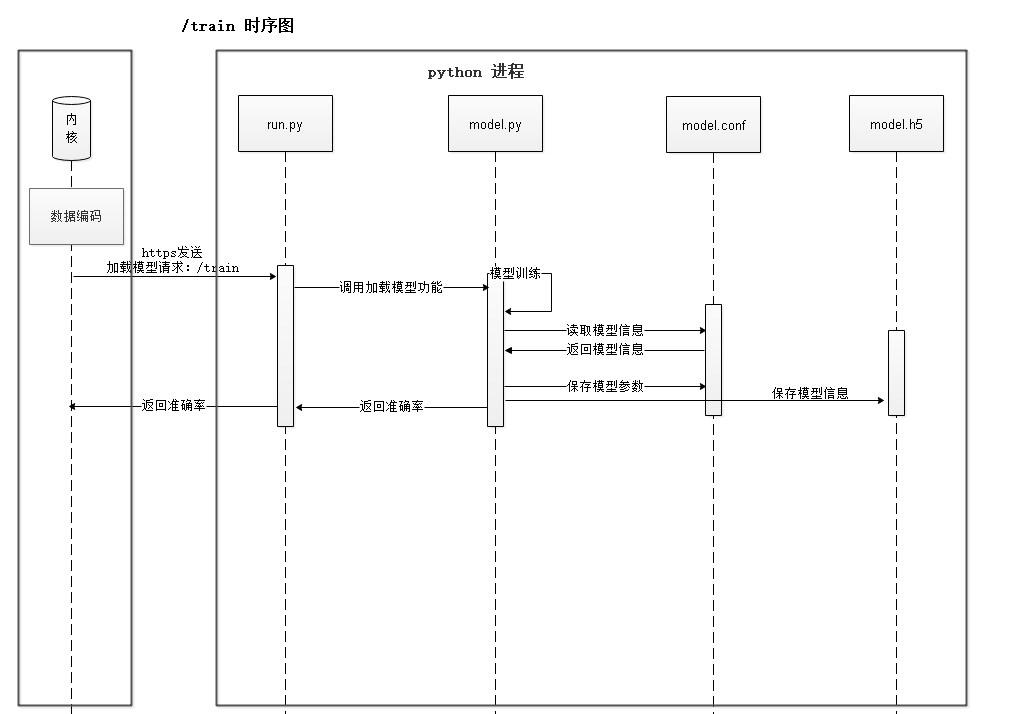
图8-18 train流程时序图
模型训练之后,用户下发预测指令,数据库会先向AI Engine侧发送setup请求,用于模型加载,加载成功后发送predict请求得到预测结果,如图8-19所示。
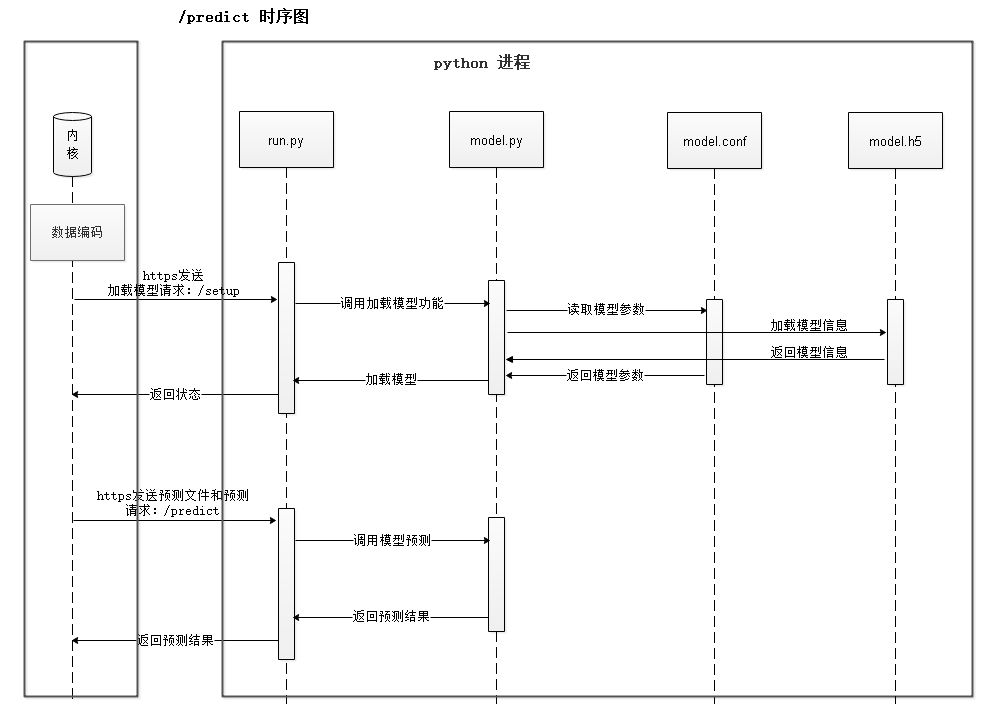
图8-19 模型预测完整流程时序图,分为setup和predict两个阶段
本特性架构上支持多模型,目前已实现R- LSTM模型,该模型架构如图8-20所示。
计划中,算子间的执行顺序也会影响算子的性能。基于这种特性,我们使用了LSTM神经网络模型来学习计划中算子间这种有意义的依赖关系,并根据行数/时间预测的场景对模型的结构、损失函数、优化算法等方面进行针对性的优化,提高此场景下学习和预测的准确率。
输入:查询计划树,各节点上的算子类型,对应表名列名以及过滤条件。
输出:行数、startup time、total time、Peak Memory。
在编码(encoding)阶段,每个计划节点(plan node)被编码成固定长度,连接成序列作为输入LSTM神经网络的特征值。
LSTM具有多个重复神经网络模块组成的链式网络,在每个模块中都有三个函数来决定历史时序中的哪些信息将被传递到下一个时序的网络模块中。最后一个模块的输出值即为模型返回的预测结果。
其中,是当前时序模块的输入,是前一个时序的输出信息,使用sigmoid()函数得到当前细胞状态中将要输出的部分;表示所有历史时序保留的信息,通过tanh函数处理后与当前状态输出信息相乘得到此状态的输出,将具有三个元素的一维向量 [startup time, total time, cardinality] 的预测结果同真实数据进行比较,使用ratio-error计算模型的损失函数。
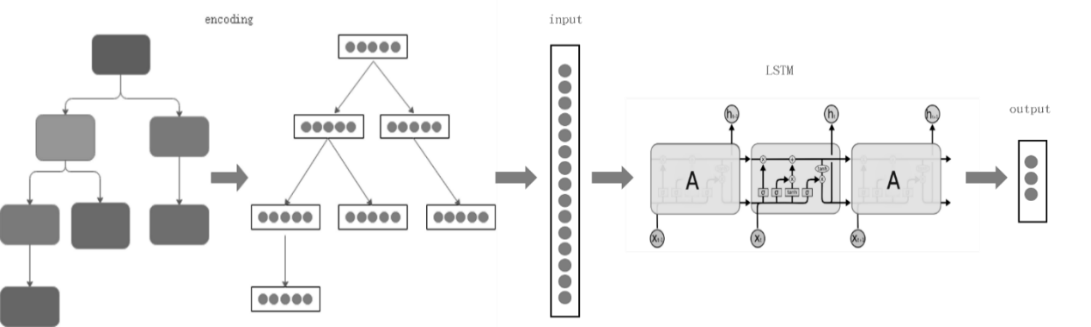
图8-20 模型架构图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号