openGauss源码解析:AI技术(15)
8.3.3 慢SQL发现采取的策略
![]()
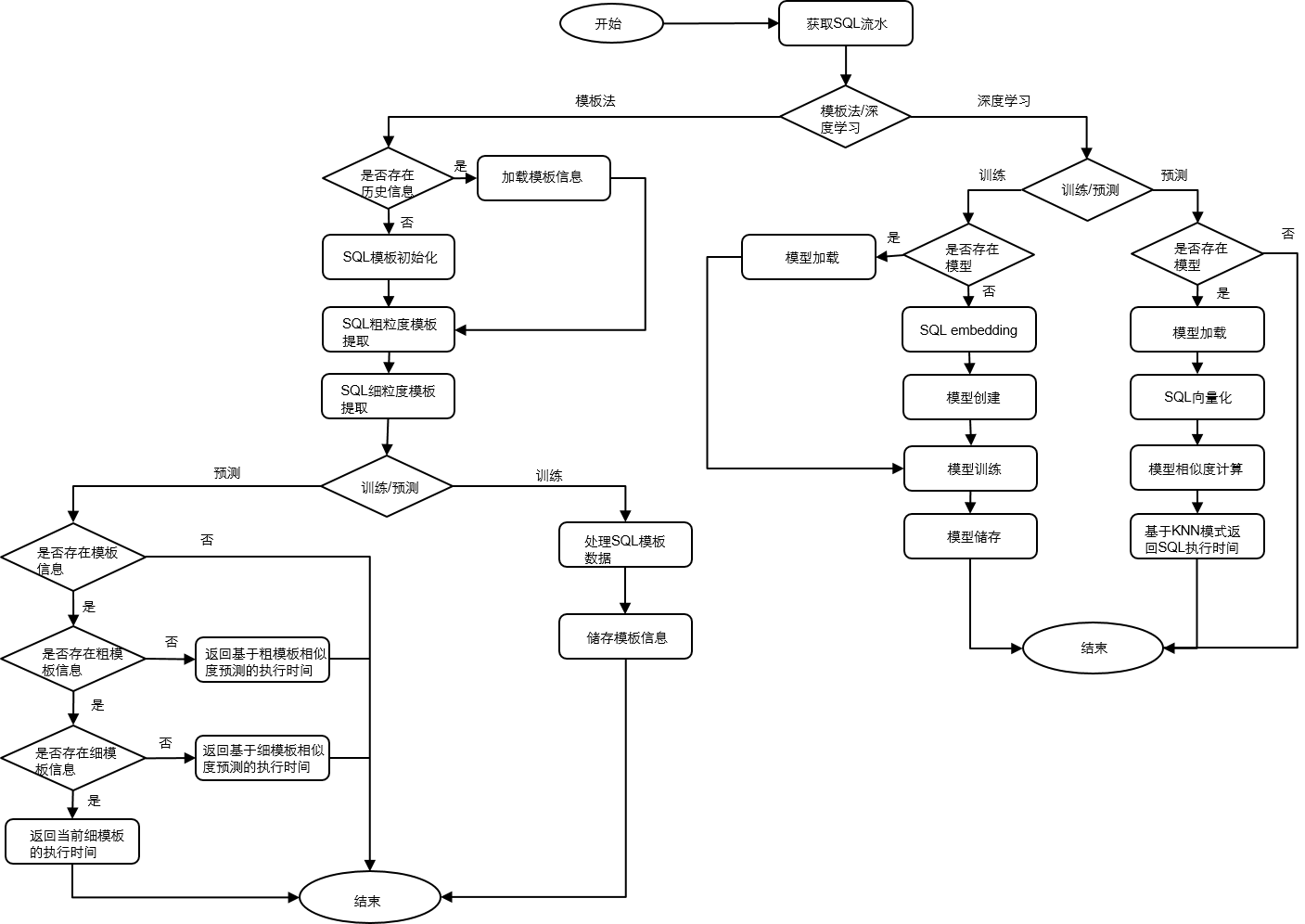
图8-11 慢SQL发现流程图
慢SQL发现工具SQLDiag的执行流程如图8-11所示,该过程可以分为两个部分,分别是基于模板化的方法和基于深度学习的方法,下面分别介绍一下。
1. 基于SQL模板化的流程
(1) 获取SQL流水数据。
(2) 检测本地是否存在对应实例的历史模板信息,如果存在,则加载该模板信息,如果不存在,则对该模板进行初始化。
(3) 基于SQL数据,提取SQL的粗粒度模板信息。粗粒度模板表示将SQL中表名、列名和其他敏感信息去除之后的SQL语句模板,该模板只保留最基本的SQL语句骨架。
(4) 基于SQL数据,提取SQL细粒度的模板信息。细粒度模板表示在粗粒度模板信息的基础上保留表名、列名等关键信息的SQL语句模板。细粒度模板相对粗粒度模板保留了更多SQL语句的信息。
(5) 执行训练过程时,首先构造SQL语句的基于粗粒度模板和细粒度模板信息,例如粗粒度模板ID、执行平均时间、细模板执行时间序列、执行平均时间和基于滑动窗口计算出的平均执行时间等。最后将上述模板信息进行储存。
(6) 执行预测过程时,首先导入对应实例的模板信息,如果不存在该模板信息,则直接报错退出;否则继续检测是否存在该SQL语句的粗粒度模板信息,如果不存在,则基于模板相似度计算方法在所有粗粒度模板里面寻找最相似的N条模板,之后基于KNN(k nearest neighbor,K近邻)算法预测出执行时间;如果存在粗粒度模板,则接着检测是否存在近似的细粒度模板,如果不存在,则基于模板相似度计算方法在所有细粒度模板里面寻找最相似的N条模板,之后基于KNN预测出执行时间;如果存在匹配的细粒度模板,则基于当前模板数据,直接返回对应的执行时间。
2. 基于深度学习的执行流程
(1) 获取SQL流水。
(2) 在训练过程中,首先判断是否存在历史模型,如果存在,则导入模型进行增量训练;如果不存在历史模型,则首先利用word2vector算法对SQL语句进行向量化,即图8-11中的SQL embeding过程。而后创建深度学习模型,将该SQL语句向量化的结果作为输入特征。基于训练数据进行训练,并将模型保存到本地。值得一提的是,该深度学习模型的最后一个全连接层网络的输出结果作为该SQL语句的特征向量。
(3) 在预测过程中,首先判断是否存在模型,如果模型不存在,则直接报错退出;如果存在模型,则导入模型,并利用word2vector算法将待预测的SQL语句进行向量化,并将该向量输入到深度学习网络中,获取该神经网络的最后一个全连接层的输出结果,即为该SQL语句的特征向量。最后,利用余弦相似度在样本数据集中进行寻找,找到相似度最高的SQL语句,将该结果返回即为该待预测SQL语句的预估执行时间。当然,如果是基于最新SQL语句执行时间数据集训练出的深度学习模型,则模型的回归预测结果也可以作为预估执行时间。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号