openGauss源码解析(85)
openGauss源码解析:事务机制源码解析(16)
5. 支持NUMA-aware数据和线程访问分布
NUMA远端访问:内存访问涉及访问线程和被访问内存两个的物理位置。只有两者在同一个NUMA Node中时,内存访问才是本地的,否则就会涉及跨Node远端访问,此时性能开销较大。
Numactl开源软件提供了libnuma库允许应用程序方便地将线程绑定在特定的NUMA Node或者CPU列表,可以在指定的NUMA Node上分配内存。下面对openGauss代码可能涉及的api进行描述。
(1) “int numa_run_on_node(int node);”将当前任务及子任务运行在指定的Node上。该API对应函数如下所示。
numa_run_on_node函数在特定节点上运行当前任务及其子任务。在使用numa_run_on_node_mask函数重置节点关联之前,这些任务不会迁移到其他节点的CPU上。传递-1让内核再次在所有节点上调度。成功时返回0;错误-1时返回,错误码记录在errno中。
(2) “void numa_set_localalloc(void);”将调用者线程的内存分配策略设置为本地分配,即优先从本节点进行内存分配。该API对应函数如下所示。
numa_set_localalloc函数 设置调用任务的内存分配策略为本地分配。在此模式下,内存分配的首选节点为内存分配时任务正在执行的节点。
(3) “void numa_alloc_onnode(void);”在指定的NUMA Node上申请内存。该API对应函数如下所示。
numa_alloc_onnode函数在特定节点上分配内存。分配大小为系统页的倍数并向上取整。如果指定的节点在外部拒绝此进程,则此调用将失败。与函数系列Malloc(3)相比,此函数相对较慢。必须使用numa_free函数释放内存。错误时返回NULL。
openGauss基于NUMA架构进行了内部数据结构优化。
1) 全局PGPROC数组优化
优化前PGPROC[]
优化后PGPROC* []
PGPROC[]
Node 0
PGPROC[]
Node 1
PGPROC[]
Node 2
PGPROC[]
Node 3
图5-24 全局PGPROC数组优化
如图5-24所示,对每个客户端连接系统都会分配一个专门的PGPROC结构来维护相关信息。ProcGlobal->allProcs原本是一个PGPROC结构的全局数组,但是其物理内存所在的NUMA Node是不确定的,造成每个事务线程访问自己的PGPROC结构时,线程可能由于操作系统的调度在多个NUMA Node间,而对应的PGPROC结构的物理内存位置也是无法预知,大概率会是远端访存。
由于PGPROC结构的访问较为频繁,根据NUMA Node的个数将这个全局结构数组分为多份,每份分别使用numa_alloc_onnode来固定NUMA Node分配内存。为了尽量减少对当前代码的结构性改动,将ProcGlobal->allProcs由PGPROC* 改为PGPROC**。对应所有访问ProcGlobal->allProcs的地方均需要做相应调整(多了一层间接指针引用)。相关代码如下:
#ifdef __USE_NUMA
if (nNumaNodes > 1) {
ereport(INFO, (errmsg("InitProcGlobal nNumaNodes: %d, inheritThreadPool: %d, groupNum: %d",
nNumaNodes, g_instance.numa_cxt.inheritThreadPool,
(g_threadPoolControler ? g_threadPoolControler->GetGroupNum() : 0))));
int groupProcCount = (TotalProcs + nNumaNodes - 1) / nNumaNodes;
size_t allocSize = groupProcCount * sizeof(PGPROC);
for (int nodeNo = 0; nodeNo < nNumaNodes; nodeNo++) {
initProcs[nodeNo] = (PGPROC *)numa_alloc_onnode(allocSize, nodeNo);
if (!initProcs[nodeNo]) {
ereport(FATAL, (errcode(ERRCODE_OUT_OF_MEMORY),
errmsg("InitProcGlobal NUMA memory allocation in node %d failed.", nodeNo)));
}
add_numa_alloc_info(initProcs[nodeNo], allocSize);
int ret = memset_s(initProcs[nodeNo], groupProcCount * sizeof(PGPROC), 0, groupProcCount * sizeof(PGPROC));
securec_check_c(ret, "\0", "\0");
}
} else {
#endif
2) 全局WALInsertLock数组优化
WALInsertLock用来对WAL Insert操作进行并发保护,可以配置多个,比如16。优化前,所有的WALInsertLock都在同一个全局数组,并通过共享内存进行分配。事务线程运行时在整个全局数组中分配其中的一个Insert Lock进行使用,因此大概率会涉及远端访存,即多个线程会进行跨Node、跨P竞争。WALInsertLock也可以按NUMA Node单独分配内存,并且每个事务线程仅使用本Node分组内的WALInsertLock,这样就可以将数据竞争限定在同一个NUMA Node内部。基本原理如图5-25所示。
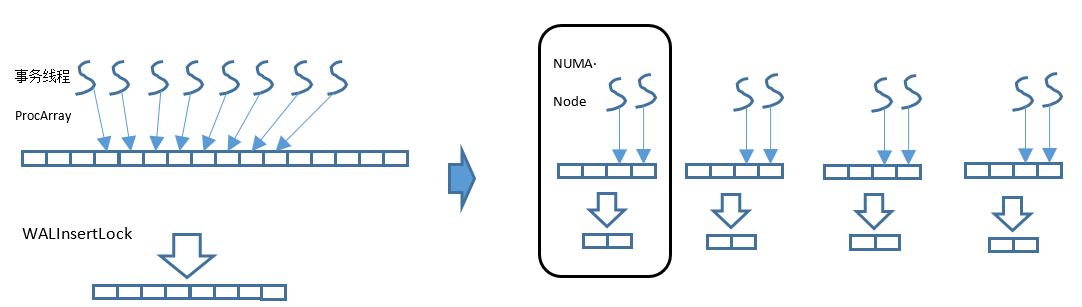
图5-25 全局WALInsertLock数组优化原理
假如系统配置了16个WALInsertLock,同时NUMA Node配置为4个,则原本长度为16的数组将会被拆分为4个数组,每个数组长度为4。全局结构体为“WALInsertLockPadded **GlobalWALInsertLocks”,线程本地WALInsertLocks将由指向本Node内的WALInsertLock[4],不同的NUMA Node下拥有不同地址的WALInsertLock子数组。GlobalWALInsertLocks则用于跟踪多个Node下的WALInsertLock数组,以方便遍历。WALInsertLock分组方式如图5-26所示。
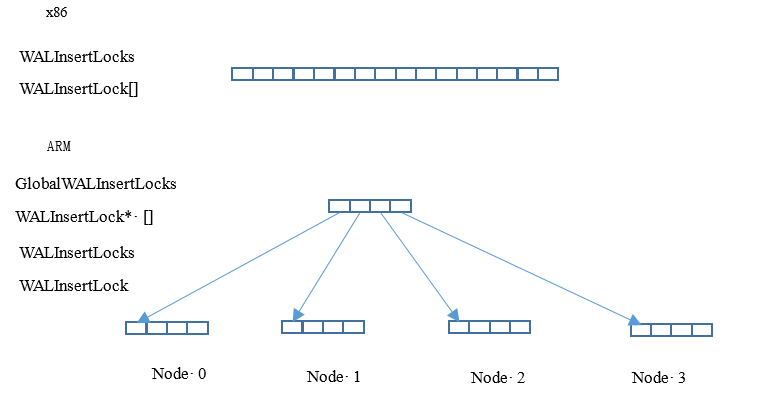
图5-26 WALInsertLock分组示意图
初始化WALInsertLock结构体的代码如下:
WALInsertLockPadded** insertLockGroupPtr =
(WALInsertLockPadded**)CACHELINEALIGN(palloc0(nNumaNodes * sizeof(WALInsertLockPadded*) + PG_CACHE_LINE_SIZE));
#ifdef __USE_NUMA
if (nNumaNodes > 1) {
size_t allocSize = sizeof(WALInsertLockPadded) * g_instance.xlog_cxt.num_locks_in_group + PG_CACHE_LINE_SIZE;
for (int i = 0; i < nNumaNodes; i++) {
char* pInsertLock = (char*)numa_alloc_onnode(allocSize, i);
if (pInsertLock == NULL) {
ereport(PANIC, (errmsg("XLOGShmemInit could not alloc memory on node %d", i)));
}
add_numa_alloc_info(pInsertLock, allocSize);
insertLockGroupPtr[i] = (WALInsertLockPadded*)(CACHELINEALIGN(pInsertLock));
}
} else {
#endif
char* pInsertLock = (char*)CACHELINEALIGN(palloc(
sizeof(WALInsertLockPadded) * g_instance.attr.attr_storage.num_xloginsert_locks + PG_CACHE_LINE_SIZE));
insertLockGroupPtr[0] = (WALInsertLockPadded*)(CACHELINEALIGN(pInsertLock));
#ifdef __USE_NUMA
}
#endif
在ARM平台下,访问WALInsertLock需遍历GlobalWALInsertLocks两维数组,第一层遍历NUMA Node,第二层遍历Node内部的WALInsertLock数组。
WALInsertLock引用的LWLock内存结构在ARM平台下也进行的相应的优化适配,代码如下所示:
typedef struct
{
LWLock lock;
#ifdef __aarch64__
pg_atomic_uint32xlogGroupFirst;
#endif
XLogRecPtrinsertingAt;
} WALInsertLock;
这里的lock成员变量将引用共享内存中的全局LWLock数组中的某个元素,在WALInsertLock优化之后,尽管WALInsertLock已经按照NUMA Node分布了,但是其引用的LWLock却无法控制其物理内存位置,因此在访问WALInsertLock的lock时仍然涉及了大量的跨Node竞争。因此将LWLock直接嵌入到WALInsertLock内部,从而将使用的LWLock一起进行NUMA分布,同时还减少了一次缓存访问。
5.4 小结
本章主要介绍了openGauss事务及并发控制的机制。
事务系统将SQL、执行及存储模块串联起来,是数据库的重要角色:收到外部命令,根据当前内部系统状态,决定执行走向。保证了事务处理的连贯性及正确性。
本章除了介绍openGauss最基础最核心的事务系统外,还详细描述了openGauss是如何基于鲲鹏服务器做出性能优化的。
总而言之,用“急如闪电,稳如泰山”来形容openGauss的事务及并发控制模块是最适合不过了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号