
爬虫之图片懒加载技术、selenium工具与PhantomJS无头浏览器
图片懒加载
图片懒加载是一种网页优化技术。图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间。为了解决这种问题,通过前后端配合,使图片仅在浏览器当前视窗内出现时才加载该图片,达到减少首屏图片请求数的技术就被称为“图片懒加载”。
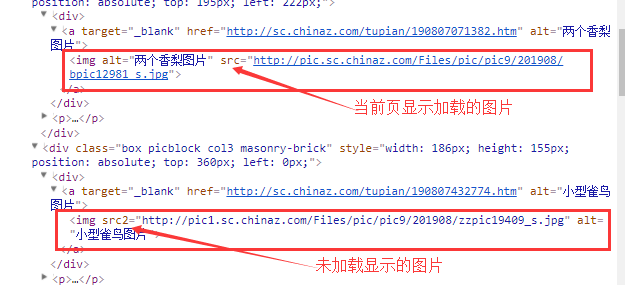
在网页源码中,在img标签中首先会使用一个“伪属性”(通常使用src2,original......)去存放真正的图片链接而并非是直接存放在src属性中。当图片出现到页面的可视化区域中,会动态将伪属性替换成src属性,完成图片的加载。
因此在爬虫时,对当前页加载的数据进行分析发起请求获取解析数据会出现数据解析不完整,究其原因很有可能是图片的懒加载技术导致,因此要在爬虫时要特别注意准确解析数据!(比如站长素材高清图片的爬取)
selenium自动化(测试)工具
简介
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
环境安装
- 下载安装selenium:pip install selenium
- 下载浏览器驱动程序:
- 查看驱动和浏览器版本的映射关系:
以百度搜索为例:


1 ''' 2 下载浏览器驱动程序:https://npm.taobao.org/mirrors/chromedriver 3 查看驱动和浏览器版本的映射:http://blog.csdn.net/huilan_same/article/details/51896672 4 ''' 5 import time 6 from lxml.html.clean import etree 7 8 from selenium import webdriver#pip install selenium 导入浏览器驱动 9 #(1)创建(谷歌等)浏览器,参数为浏览器驱动位置 10 browser=webdriver.Chrome(r"./chromedriver.exe") 11 12 13 #(2)通过浏览器发起get请求 14 browser.get('https://www.baidu.com/') 15 16 17 #(3)进行关键字搜索等页面操作 18 #①定位搜索框标签(可通过多种方式进行定位) 19 search_input=browser.find_element_by_id('kw') 20 #②定位搜索按钮 21 search_button=browser.find_element_by_xpath('//input[@id="su"]') 22 #③在输入框输入关键字 23 search_input.send_keys('selenium') 24 time.sleep(2) 25 #④清空输入框 26 search_input.clear() 27 time.sleep(2) 28 search_input.send_keys('selenium工具包') 29 time.sleep(2) 30 #⑤点击搜索按钮 31 search_button.click() 32 time.sleep(2) 33 #⑥向下滑动滚动条到底部 34 browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") 35 time.sleep(2) 36 #⑦向下滑动滚动条到顶部 37 browser.execute_script("window.scrollTo(0,-document.body.scrollHeight)") 38 time.sleep(2) 39 40 41 #获取当前页面内容进行说数据解析 42 page_text=browser.page_source 43 print(etree.HTML(page_text).xpath('//span[@class="nums_text"]/text()')[0]) 44 45 46 # 处理弹出的警告页面:确定accept() 和 取消dismiss() 47 # browser.switch_to_alert().accept() 48 # time.sleep(2) 49 50 51 #(3)关闭浏览器 52 # browser.close() 53 browser.quit()
浏览器驱动
Selenium支持非常多的浏览器,如Chrome、Firefox、Edge等,还有Android、BlackBerry等手机端的浏览器。另外,也支持无界面浏览器PhantomJS。
from selenium import webdriver browser = webdriver.Chrome() browser = webdriver.Firefox() browser = webdriver.Edge() browser = webdriver.PhantomJS() browser = webdriver.Safari()
节点交互(文本输出与清空)
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用
send_keys()方法,清空文字时用clear()方法,点击按钮时用click()方法。import time
from selenium import webdriver
browser=webdriver.Chrome(r"./chromedriver.exe")
browser.get('https://www.baidu.com/')
search_input=browser.find_element_by_id('kw')search_input.send_keys('selenium')#输入文字
time.sleep(2)
search_input.clear()#清空文字
time.sleep(2)
动作链
一些交互动作是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
1 # 实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现 2 import time 3 from selenium import webdriver 4 from selenium.webdriver import ActionChains 5 6 browser = webdriver.Chrome(r'./chromedriver.exe') 7 browser.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable") 8 9 # 分析页面标签可以发现页面中嵌套了html,实用的是frame框架,因此需要先定位iframe 10 browser.switch_to_frame("iframeResult") # 通过id定位iframe 11 12 # 找到要拖动的标签和要拖动到的标签 13 start = browser.find_element_by_id("draggable") 14 end = browser.find_element_by_id("droppable") 15 # 实例化动作对象 16 actions = ActionChains(browser) 17 18 # (1)拖拽动作,参数为起始对象,perform()立即执行 19 # actions.drag_and_drop(start,end).perform() 20 # time.sleep(2) 21 22 # (2)缓慢执行拖动动作 23 actions.click_and_hold(start) 24 for i in range(5): 25 actions.move_by_offset(xoffset=18,yoffset=0).perform() 26 time.sleep(0.5) 27 actions.release() 28 start.click() 29 time.sleep(2) 30 31 32 # 处理页面的弹出警示框 33 browser.switch_to_alert().accept() 34 time.sleep(2) 35 36 browser.close() 37 browser.quit()
执行JavaScript
对于某些操作,Selenium API并没有提供。比如,下拉进度条,它可以直接模拟运行JavaScript,此时使用
execute_script()方法即可实现。
1 import time 2 from selenium import webdriver 3 4 browser = webdriver.Chrome() 5 browser.get('https://www.jd.com/') 6 time.sleep(1) 7 browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')#操作滚动条 8 time.sleep(2) 9 browser.execute_script('alert("123")')#操作警示弹窗 10 time.sleep(2) 11 browser.switch_to_alert().accept() 12 time.sleep(2) 13 browser.quit()
获取页面源码数据
通过
page_source属性可以获取网页的源代码,接着就可以使用解析库(如正则表达式、Beautiful Soup、pyquery等)来提取信息了。
1 import time 2 from lxml.html.clean import etree 3 4 from selenium import webdriver 5 6 browser=webdriver.Chrome(r"./chromedriver.exe") 7 browser.get('https://www.baidu.com/') 8 search_input=browser.find_element_by_id('kw') 9 search_button=browser.find_element_by_xpath('//input[@id="su"]') 10 search_input.send_keys('selenium工具包') 11 time.sleep(2) 12 search_button.click() 13 time.sleep(2) 14 15 page_text=browser.page_source#获取页面源码 16 print(etree.HTML(page_text).xpath('//span[@class="nums_text"]/text()')[0]) 17 browser.quit()
前进和后退
模拟浏览器的前进和回退功能
1 import time 2 from selenium import webdriver 3 browser=webdriver.Chrome() 4 5 browser.get('https://www.baidu.com/') 6 browser.get('https://www.jd.com/') 7 browser.get('https://www.sina.com.cn/') 8 9 time.sleep(3) 10 browser.back()#浏览器后退 11 time.sleep(3) 12 browser.forward()#浏览器前进 13 time.sleep(3) 14 browser.close()
规避被检测识别
不少大网站有对selenium采取了监测机制。比如正常情况下我们用浏览器访问淘宝等网站的 window.navigator.webdriver的值为 undefined。而使用selenium访问则该值为true。因此需要设置Chromedriver的启动参数来解决问题。
在启动Chromedriver之前,为Chrome开启实验性功能参数
excludeSwitches,它的值为['enable-automation']
1 from selenium import webdriver 2 from selenium.webdriver import ChromeOptions 3 option=ChromeOptions() 4 option.add_experimental_option('excludeSwitches', ['enable-automation']) 5 browser=webdriver.Chrome(options=option) 6 7 browser.get('https://www.baidu.com/')
Cookie处理
selenium模拟浏览器操作,可以不用考虑在页面数据获取时cookie问题,但是如果想操作cookie,使用Selenium也是可以实现的,例如获取、添加、删除Cookies等。
1 from selenium import webdriver 2 browser = webdriver.Chrome() 3 browser.get('https://www.baidu.com') 4 print(browser.get_cookies()) 5 browser.add_cookie({'name': 'name', 'value': '12345'}) 6 print(browser.get_cookies()) 7 browser.delete_all_cookies() 8 print(browser.get_cookies())
phantomJS
PhantomJS是一款无界面的浏览器,其自动化操作流程和上述操作谷歌浏览器是一致的。由于是无界面的,为了能够展示自动化操作流程,PhantomJS为用户提供了一个截屏的功能,使用save_screenshot函数实现。PhantomJS下载地址:https://phantomjs.org/download.html,目前已经停止维护和更新,因此不建议使用,可以使用谷歌的无头浏览器。
1 from selenium import webdriver 2 import time 3 4 # phantomjs路径 5 path = r'PhantomJS驱动路径' 6 browser = webdriver.PhantomJS(path) 7 8 # 打开百度 9 url = 'http://www.baidu.com/' 10 browser.get(url) 11 12 time.sleep(3) 13 14 browser.save_screenshot(r'phantomjs\baidu.png') 15 16 # 查找input输入框 17 my_input = browser.find_element_by_id('kw') 18 # 往框里面写文字 19 my_input.send_keys('美女') 20 time.sleep(3) 21 #截屏 22 browser.save_screenshot(r'phantomjs\meinv.png') 23 24 # 查找搜索按钮 25 button = browser.find_elements_by_class_name('s_btn')[0] 26 button.click() 27 28 time.sleep(3) 29 30 browser.save_screenshot(r'phantomjs\show.png') 31 32 time.sleep(3) 33 34 browser.quit()
谷歌无头浏览器
1 import time 2 from selenium import webdriver 3 from selenium.webdriver.chrome.options import Options 4 # 创建一个参数对象,用来控制chrome以无界面模式打开 5 chrome_options=Options() 6 chrome_options.add_argument('--headless') 7 chrome_options.add_argument('--disable-gpu') 8 9 #谷歌浏览器驱动路径 10 chrome_path=r'chromedriver.exe'#当前目录 11 12 #创建浏览器对象 13 # browser=webdriver.Chrome(executable_path=chrome_path, chrome_options=chrome_options) 14 browser=webdriver.Chrome(chrome_path,chrome_options=chrome_options) 15 16 17 browser.get('https://www.baidu.com/') 18 time.sleep(4) 19 browser.save_screenshot('baidu.png')#截图 20 browser.quit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号