移动端数据爬取
移动端数据爬取
fiddler抓包工具
Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。
客户端的所有请求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有响应,也都会先经过Fiddler然后发送到客户端,基于这个原因,Fiddler支持所有可以设置http代理为127.0.0.1:8888的浏览器和应用程序。
(1)下载fiddler之后直接一步下一步安装即可。 
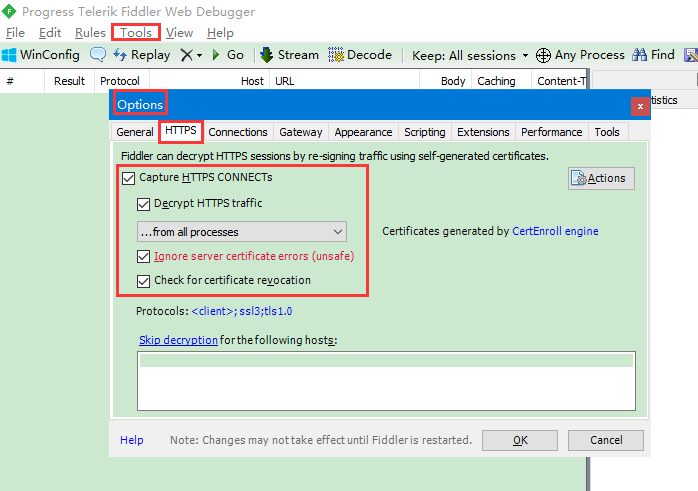
(2)fiddler默认只支持http协议的转发,要想支持https协议的转发和抓取,需要进行设置,安装证书。(Tools---->Options---->HTTPS)
(3)允许其他设备也能使用fiddler进行代理转发请求和响应,需要如下配置:(Tools---->Options---->Connections),配置端口号如图8888

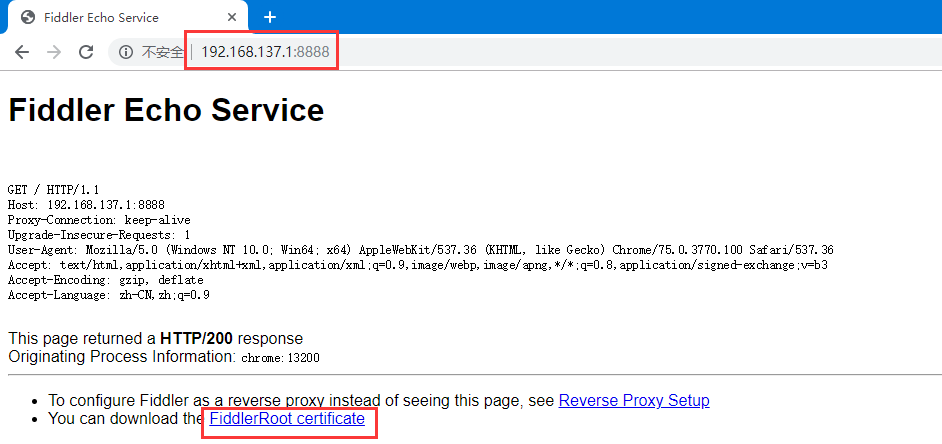
(4)在浏览器访问fiddler代理:http://localhost:8888或者http://192.168.137.1:8888,出现如下页面表示正常,FiddlerRoot certificate是移动端需要安装的证书。
移动端设置
(1)移动端设备必须和fiddler在同一网段才能使用fiddler抓包,可以手机连接电脑热点,然后手动设置代理指定fiddler代理的ip(192.168.137.1)和端口(8888)。
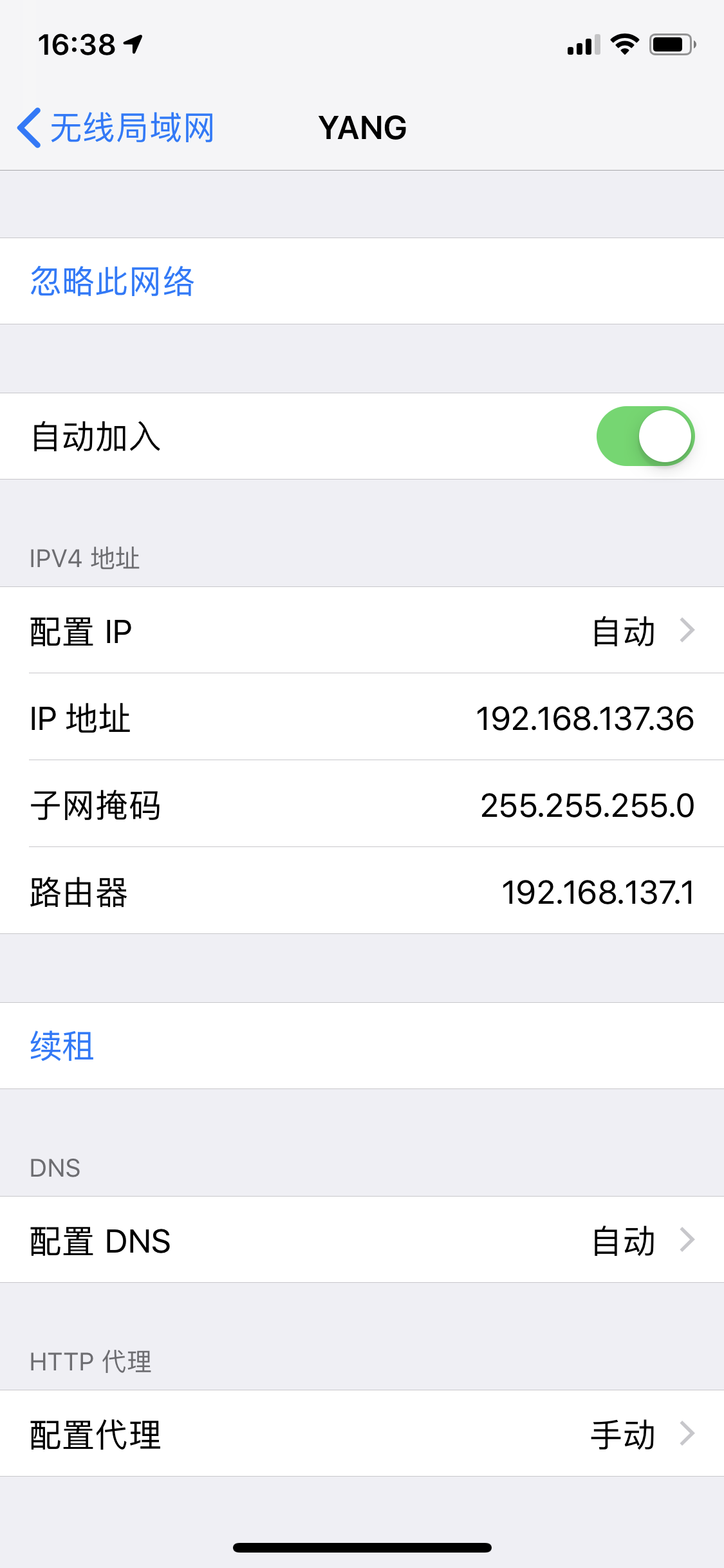
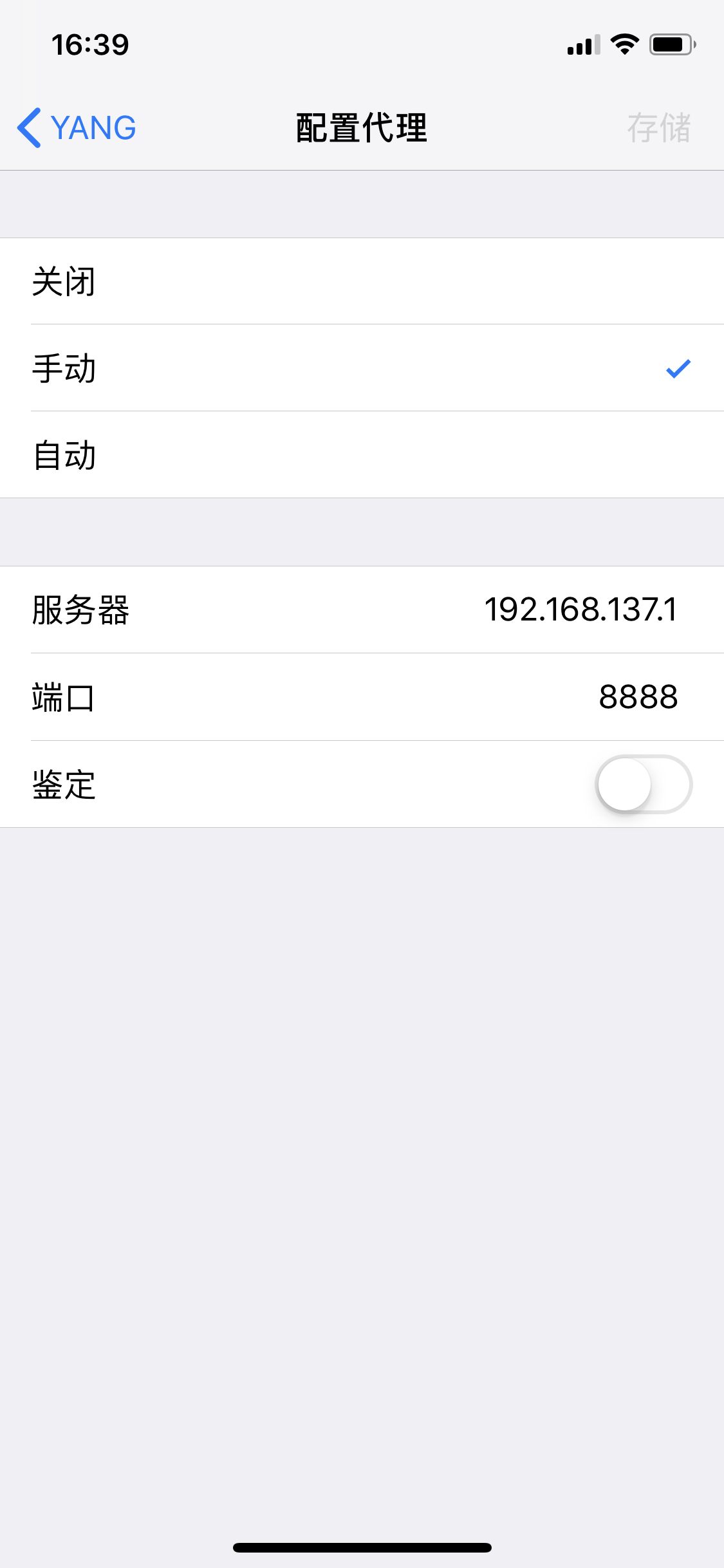
(2)证书安装:直接在浏览器输入http://192.168.137.1:8888,下载证书FiddlerRoot certificate后安装或者通过其他方式发送到手机进行安装信任!
①安卓设备:把证书放入手机的内置或外置存储卡上,然后通过手机的"系统安全-》从存储设备安装"菜单安装证书。 然后找到拷贝的FiddlerRoot.cer进行安装即可。安装好之后,可以在信任的凭证中找到我们已经安装好的安全证书。

②苹果设备:在浏览器下载证书进入手机设置---->通用---->描述文件---->安装,然后设置---->通用---->关于本机---->证书信任设置---->开启fiddler证书信任

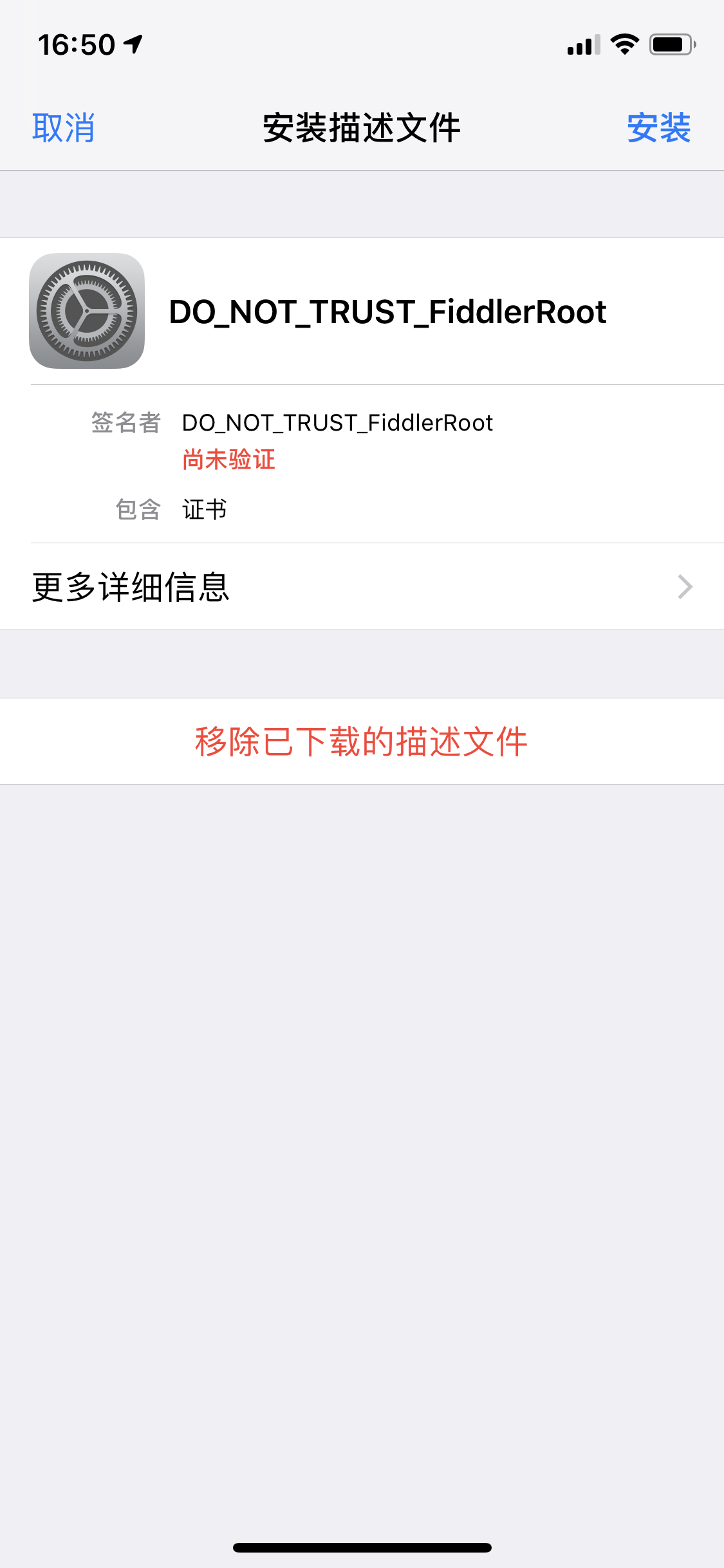
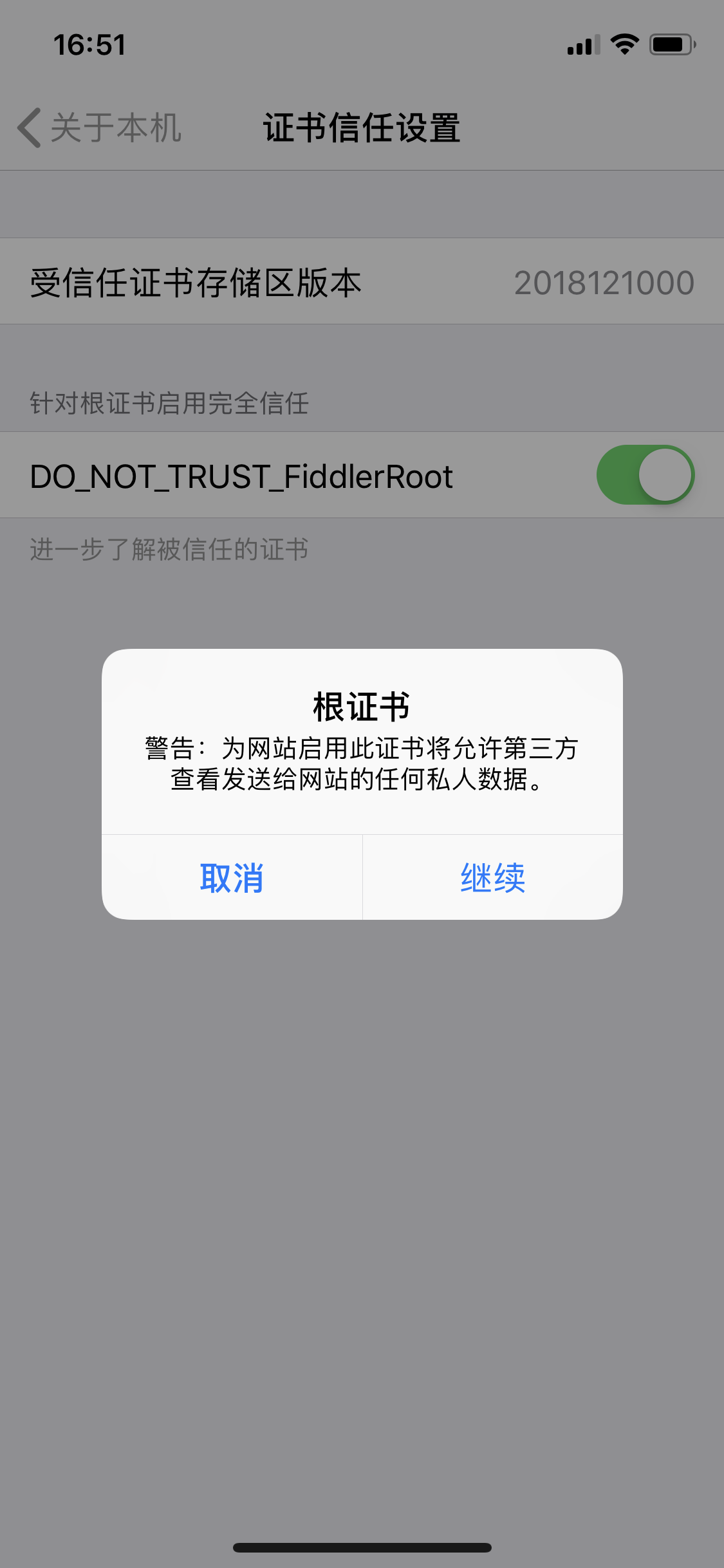
Fiddler对移动端请求进行抓包
案例一:句读app数据采集


1 ''' 2 手机app句读【广场】爬取 3 1.打开手机句读app 4 2.点击下边第三个导航,默认就是【广场】 5 3.在fiddler进行抓包,拿到api如下 6 4.向下滑动手机,查看抓包工具,找出请求链接进行对比,都是通过get请求,起始位置不同,因此可以简单在第一次请求时设置请求条数即可大量获取 7 ''' 8 import requests 9 num=10000#自定义采集数量 10 url=f'https://judouapp.com/api/v5/statuses?app_key=af66b896-665e-415c-a119-6ca5233a6963&channel=App%20Store&device_id=18a053095ad095fa6c331b7036f589a4&device_type=iPhone10%2C3&pagesign=&per_page={num}&platform=ios&signature=f99a2253c0636fd1de73e82de39fa0e6&system_version=12.3.1×tamp=1565141295&token=e11dda42765099ff0610bfce807ba440&version=3.8.0&version_code=51' 11 headers={ 12 'Accept':'*/*', 13 'Accept-Language':'zh-Hans-CN;q=1, en-CN;q=0.9, en-US;q=0.8', 14 'Connection':'keep-alive', 15 'Accept-Encoding':'br, gzip, deflate', 16 'User-Agent':'JudouRili/3.8.0 (iPhone; iOS 12.3.1; Scale/3.00)', 17 } 18 19 response=requests.get(url,headers=headers).json() 20 print(len(response["data"])) 21 fp=open('句读.txt','w',encoding='utf-8') 22 for index,data in enumerate(response["data"]): 23 nickname=data["user"]["nickname"] 24 content=data["content"] 25 url=data["share_url"] 26 published_at=data["published_at"] 27 fp.write(f'{index+1}/{num+1}[{published_at}]{nickname}----{url}\n\t{content}\n\n------------------------------------')
案例二:抖音app小视频爬取
1 ''' 2 通过抓包工具获取抖音个人信息的请求连接,通过requests请求获取视频连接; 3 此案例是登陆之后好友的抖音视频,注意cookie有效期 4 ''' 5 import os 6 import requests 7 url = 'https://api-hl.amemv.com/aweme/v1/aweme/post/?version_code=7.2.1&pass-region=1&pass-route=1&js_sdk_version=1.17.4.3&app_name=aweme&vid=03AF1BE2-1C49-42F4-9280-4CA78E8554F3&app_version=7.2.1&device_id=48188949731&channel=App%20Store&mcc_mnc=46001&aid=1128&screen_width=1125&openudid=bb6af869d6a21b959b2efc1414af434af4244f52&os_api=18&ac=WIFI&os_version=12.3.1&device_platform=iphone&build_number=72100&device_type=iPhone10,3&iid=80760036119&idfa=FA5BEC32-3917-4E54-92C1-8130C8B5C9FC&min_cursor=0&user_id=104290453971&count=21&max_cursor=0' 8 headers = { 9 'Connection':'keep-alive', 10 'x-Tt-Token':'00c5298f55f17f29df1f5870c60971c74eff742bc167d881418c39c6384740987a57ff8920ac697ca665a8c8dea7e50ec42', 11 'sdk-version':'1', 12 'User-Agent':'Aweme 7.2.1 rv:72100 (iPhone; iOS 12.3.1; zh_CN) Cronet', 13 'x-tt-trace-id':'00-d3ac15e52ed8ee0f911103e2f883d140-d3ac15e52ed8ee0f-01', 14 'Accept-Encoding':'gzip, deflate', 15 'Cookie':'tt_webid=6640617808751937028; __tea_sdk__user_unique_id=6640617808751937028; _ga=GA1.2.1852759965.1533561988; odin_tt=9f303c67997d51ed06eb85033ded2c41c8a051aafc15049d416669246d4a8fc9fbb0ee3cb48b15736c2cd7a1c68e0066; sid_guard=c5298f55f17f29df1f5870c60971c74e%7C1563533383%7C5184000%7CTue%2C+17-Sep-2019+10%3A49%3A43+GMT; uid_tt=d91cf1be6d56ed8851460c54c4bb7b47; sid_tt=c5298f55f17f29df1f5870c60971c74e; sessionid=c5298f55f17f29df1f5870c60971c74e; install_id=80760036119; ttreq=1$10c1e479908eed52765e8ee12a84e43e2253c1f3', 16 'X-Khronos':'1565148064', 17 'X-Pods':'', 18 'X-Gorgon':'83000e560000c220307e34ef71495882f95411d88045512c5c4a', 19 20 } 21 response_json = requests.get(url, headers=headers).json()#相应的是json格式 22 video_list=response_json["aweme_list"] 23 #创建好友视频信息列表 24 video_url=[] 25 for video_info in video_list: 26 nickname =video_info["author"]["nickname"]#昵称 27 gender=video_info["author"]["gender"]#性别 28 desc=video_info["desc"]#文字描述 29 print(desc) 30 player_addr=video_info["video"]["play_addr"]["url_list"][0]#播放地址 31 video_url.append((f'{nickname}({gender})',desc,player_addr)) 32 33 print(video_url) 34 #循环遍历视频列表,分条采集视频数据 35 for video in video_url: 36 if not os.path.exists(video[0]): 37 os.mkdir(video[0]) 38 path = os.path.join(video[0], video[1] + '.mp4') 39 with open(path,'wb')as f: 40 f.write(requests.get(video[2]).content)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号