
(一) 从零开始搭建Spark Standalone集群环境搭建
本文主要讲解spark 环境的搭建
主机配置 4核8线程,主频3.4G,16G内存
虚拟环境: VMWare
虚拟环境系统:Ubuntu 14.10
虚拟机运行环境:
- jdk-1.7.0_79(64bit)
- hadoop-2.6.0.tar.gz
- scala-2.10.4.tar
- spark-1.5.0-bin -hadoop-2.6.0.tgz
(一)样本虚拟机的搭建
1)虚拟机安装ubuntu,每个分配3G内存,完成后后输入如下命令来获得root权限:
#sudo passwd
2)ubuntu下源的更改:
#sudo gedit /etc/apt/sources.list
找到一个还用的源替换掉 /etc/apt/sources.list中原来的内容
执行更新:
#sudo apt-get update
3)安装ssh,以便远程登录
ssh-client : 本机作为客户机通过ssh链接远程的服务器
ssh-server:本机作为远程服务器,可以被客户机链接
#sudo apt-get install ssh-client
注意上述命令可能出现问题 “依赖 :openssh-client (= 1:6.6p1-2ubuntu1)”
使用 这条命令即可解决: #sudo apt-get install ssh-client= 1:6.6p1-2ubuntu1
接下来安装#sudo apt-get install ssh-server (或者 apt-get install openssh-server)
4)查看ssh服务是否启动
#ps -e |grep ssh
显现出sshd 则说明安装成功
5)更新vim
#sudo apt-get remove vim
#sudo apt-get install vim
6)修改/etc/ssh/sshd_config 文件,使得本机允许远程连接,现在即可通过putty,xshell等连接该机
# Authentication:
LoginGraceTime 120
PermitRootLogin yes
StrictModes yes
7)修改host主机名
#vi /etc/hostname 将该文件该为spark1
然后 #vi /ect/hosts 改成与上述文件相同的名字
重启 #hostname 查看是否生效
8)注意虚拟机的网络设置为桥接
#ifconfig 可来查看网络状态
9)根据求查看是否需要固定IP
设置静态IP方法如下:
#sudo vim /etc/network/interfaces
#修改如下部分:
auto eth0
iface eth0 inet static
address 192.168.0.117
gateway 192.168.0.1 #这个地址你要确认下 网关是不是这个地址
netmask 255.255.255.0
network 192.168.0.0
broadcast 192.168.0.255
因为以前是dhcp解析,所以会自动分配dns服务器地址,而一旦设置为静态ip后就没有自动获取到的dns服务器了,设置静态IP地址后,再重启后就无法解析域名。想重新设置一下DNS,有两个办法:
- 通过/etc/network/interfaces,在它的最后增加一句:
dns-nameservers 8.8.8.8
8.8.8.8是Google提供的DNS服务,这里只是举一个例子,你也可以改成电信运营商的DNS。重启后DNS就生效了。
- 通过修改:
/etc/resolvconf/resolv.conf.d/base(这个文件默认是空的)
在里面插入:
nameserver 8.8.8.8
nameserver 8.8.4.4
如果有多个DNS就一行一个,修改好保存,然后执行resolvconf -u再看/etc/resolv.conf,最下面就多了2行:
nameserver 8.8.8.8
nameserver 8.8.4.4
可以看到我们的设置已经加上了,然后再ping一个域名,当时就可以解析了,无需重启。
以上测试在我这里测试可想行不通,最后还是没有修改,完全是桥接,DHCP自动获取的,好在学校内部重启后IP地址是不变的,所以暂时先这样了,以后变了再改
10)关闭防火墙 #ufw disable
11)安装jdk
下载对应版本的JDK,切记X64为64位系统X86_64为64位系统,否则为32位
解压tar -zxvf jdk1.7.0_79 -C /usr/lib
配置环境变量 #vi /etc/priofile ,添加如下字段
export JAVA_HOME=/usr/lib/jdk1.7.0_79
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使改动生效 source /etc/profile
验证 java-version
12)安装scala
方法类似于java,上传scala2.10.4包,解压,#tar -zxvf scala-2.10.4.tgz -C /usr/lib/scala
到/etc/profile里配置路径:
export SCALA_HOME=/usr/lib/scala/scala-2.10.4
export PATH=$PATH:${SCALA_HOME}/bin
输入如下命令使得配置生效#source /etc/profile
验证 #scala -version
13)克隆该样本机,克隆出4个备份,然后分别配置每个机器的主机名与IP地址。
改玩后自行测试看每个机器是否正确
14)设置ssh免密码连接(注意公钥汇总的命名)
这里参考http://www.cnblogs.com/shishanyuan/p/4701510.html
15)下载hadoop-2.6.0_x64.tar.gz包 ,将该包解压到/app/hadoop/文件夹下,并在切换到#cd /app/hadoop/hadoop-2.6.0/,创建三个文件夹#mkdir tmp #mkdir name #mkdir data
16)接下来要配置hadoop环境变量
首先切换到 #cd /app/hadoop/hadoop-2.6.0/etc/hadoop,打开如下文件#vi hadoop-env.sh,加入如下路径:
export JAVA_HOME=/usr/lib/ivm/jdk1.7.0_79
export PATH=$PATH:/app/hadoop/hadoop-2.6.0/bin
配置好后输入# source hadoop-env.sh使得配置生效,接下来#hadoop version测试是否配置成功。
17)配置yarn-env.sh
在/app/hadoop/hadoop-2.6.0/etc/hadoop打开配置文件yarn-env.sh
#cd /app/hadoop/hadoop-2.6.0/etc/hadoop
#sudo vi yarn-env.sh
加入配置内容,设置JAVA_HOME路径
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_79
使用source yarn-env.sh使之生效
18)配置core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://spark1:9000</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://spark1:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/app/hadoop/hadoop-2.6.0/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.hduser.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hduser.groups</name> <value>*</value> </property> </configuration>
19)配置hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>spark1:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/app/hadoop/hadoop-2.6.0/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/app/hadoop/hadoop-2.6.0/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
20)配置mapred-site.xml,一般情况下,只有一个mapred-site.xml.template ,# cp mapred-site.xml.template mapred-site.xml复制出来一份即可:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>spark1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>spark1:19888</value> </property> </configuration>
21)配置yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>spark1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>spark1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>spark1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>spark1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>spark1:8088</value> </property> </configuration>
22)配置slaves
#vi slaves
在slaves里加入:
spark1
spark2
spark3
spark4
23)用scp分别向各个节点分发配置好的hadoop
在个个slave里建立对应的文件目录 /app/hadoop/, spark1切换到/app/hadoop目录下
# scp hadoop-2.6.0 root@spark2:/app/hadoop
# scp hadoop-2.6.0 root@spark3:/app/hadoop
# scp hadoop-2.6.0 root@spark4:/app/hadoop
24)格式化namenode
#cd /app/hadoop/hadoop-2.6.0
#hadoop namenode -format
25)启动hdfs
$cd /app/hadoop/hadoop-2.6.0/sbin
$./start-dfs.sh
启动hdfs时候,报如下错误:Error: Cannot find configuration directory: /etc/hadoop,则应该在 /etc/profile里加入如下配置:
#hadoop
export HADOOP_HOME=/app/hadoop/hadoop-2.6.0
export YARN_HOME=/app/hadoop/hadoop-2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
并且#source etc/profile 使得其生效
若slave中部分datanode没启动,则#./stop-all.sh,然后删除所有节点中的tmp,name,data三个文件夹,重新建立新的空文件夹
格式化namenode #hadoop namenode -format,现在启动应该正常了!
26)验证hdfs是否成功启动
#jps ,此时在spark1上面运行的进程有:NameNode、SecondaryNameNode和DataNode

spark2-spark4上运行的有DataNode

25)启动yarn
#cd /app/hadoop/hadoop-2.6.0/sbin
#./start-yarn.sh
此时在spark1上的进程有:NameNode、SecondaryNameNode、DataNode、NodeManager和ResourceManager
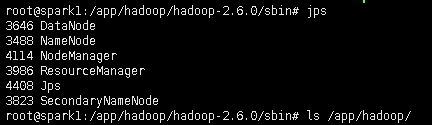
spark2-spark4上的进程有:DataNode NodeManager
至此,hadoop安装已经完成!!!接下来就是spark的安装!
27)跑一下hadoop附带的例子来测试是否安装成功,下面以wordcount为例。
28)首先到spark官网下载hadoop2.6对应的安装包,spark1.5.0-bin-hadoop2.6.tgz,上传到/ooon,解压缩# tar -zxvf spark1.5.0-bin-hadoop2.6.tgz -C /app/hadoop,切换到spark主目录,#cd /app/hadoop/spark-1.5.0-bin-hadoop-2.6.0
29)配置spark的环境变量, 打开配置文件/etc/profile, 定义SPARK_HOME并把spark路径加入到PATH参数中
SPARK_HOME=/app/hadoop/spark-1.5.0
PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
30)配置conf/spark-env.sh
# conf/
#cp spark-env.sh.template spark-env.sh
#vi spark-env.sh
在最后介入如下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_79
export SPARK_MASTER_IP=spark1 (注意这里有个坑,若是你的IDE环境搭建在spark1以外的机器上,这里最好直接写成spark1的IP172.21.75.100,血泪史)
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=1g
source spark-env.sh使得配置生效。
31)配置slaves,如下

32)scp分发到各个节点
#cd /app/hadoop
#scp -r spark-1.5.0-bin-hadoop-2.6.0 root@spark2:/app/hadoop
#scp -r spark-1.5.0-bin-hadoop-2.6.0 root@spark3:/app/hadoop
#scp -r spark-1.5.0-bin-hadoop-2.6.0 root@spark3:/app/hadoop
接下来启动spark
#cd sbin
#./start-all.sh
spark1的进程有:

spark2-spark4的进程有:

现在spark也装好了!!!
33)在浏览器中输入地址172.21.75.102:8080,可以看到集群的状态

34)验证客户端连接
进入hadoop1节点,进入spark的bin目录,使用spark-shell连接集群
$cd /app/hadoop/spark-1.1.0/bin
$./spark-shell --master spark://spark1:7077 --executor-memory 500m
在命令中只指定了内存大小并没有指定核数,所以该客户端将占用该集群所有核并在每个节点分配500M内存, 下图可见其分配情况

现在,我们已经通过spark-shell连接到了集群,现在就可以运行一下spark的示例wordcount
35)运行wordcound
首先上传数据到hdfs,#hadoop fs -mkdir -p /usr/hadoop/testdata
$./spark-shell --master spark://spark1:7077 --executor-memory 512m --driver-memory 500m
接下来在shark-shell里键入如下代码执行wordcount的计算
scala>val rdd=sc.textFile("hdfs://hadoop1:9000/user/hadoop/testdata/core-site.xml") scala>rdd.cache() scala>val wordcount=rdd.flatMap(_.split(" ")).map(x=>(x,1)).reduceByKey(_+_) scala>wordcount.take(10) scala>val wordsort=wordcount.map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1)) scala>wordsort.take(10)
结果如下:Array[(String, Int)] = Array(("",100), (the,7), (</property>,6), (<property>,6), (under,3), (in,3), (License,3), (this,2), (-->,2), (file.,2))
35)最后需要注意的是学校的IP变化后的处理
除了 /etc/hosts 需要处理外,另外 spark-env.sh 也需要制定spark-master 的IP
source spark-env.sh使得配置生效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号