零基础学Python--------第10章 文件及目录操作
第10章 文件及目录操作
10.1 基本文件操作
在Python中,内置了文件(File)对象。在使用文件对象时,首先需要通过内置的open() 方法创建一个文件对象,然后通过对象提供的方法进行一些基本文件操作。例如,可以使用文件对象的write() 方法向文件中写入内容,以及使用close() 方法关闭文件等。下面将介绍如何应用Python的文件对象进行基本文件操作。
10.1.1 创建和打开文件
在Python中,想要操作文件需要先创建或者打开指定的文件并创建文件对象,通过内置的open() 函数实现。open() 函数的基本语法格式如下:
file = open(filename[,mode[,buffering]])
参数说明:
- file:被创建的文件对象。
- filename:要创建或打开文件的文件名称,需要使用单引号或双引号括起来。如果要打开的文件和当前文件在同一个目录下,那么直接写文件名称即可,否则需要制定完整路径。例如,要打开当前路径下的名称为status.txt 的文件,可以使用“status.txt”。
- mode:可选参数,用于指定文件的打开模式,其参数值如下表。默认的打开模式为只读(即r)。
| 值 | 说明 | 注意 |
| r | 以只读模式打开文件,文件的指针将会放在文件的开头 | 文件必须存在 |
| rb | 以二进制格式打开文件,并且采用只读模式。文件的指针将会放在文件的开头,一般用于非文本文件,如图片、声音等 | |
| r+ | 打开文件后,可以读取文件内容,也可以写入新的内容覆盖原有内容(从文件开头进行覆盖) | |
| rb+ | 以二进制格式打开文件,并且采用读写模式。文件的指针将会放在文件的开头。一般用于非文本文件,如图片、声音等 | |
| w | 以只写模式打开文件 | 文件存在,则将其覆盖,否则创建新文件 |
| wb | 以二进制格式打开文件,并且采用只写模式。一般用于非文本文件,如图片、声音等 | |
| w+ | 打开文件后,先清空原有内容,使其变为一个空的文件,对这个空文件有读写权限 | |
| wb+ | 以二进制格式打开文件,并且采用读写模式。一般用于非文本文件,如图片、声音等 | |
| a | 以追加模式打开一个文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于写入 | |
| ab | 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于写入 | |
| a+ | 以读写模式打开文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到字节的内容之后),否则,创建新文件用于读写 | |
| ab+ | 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写 |
- buffering:可选参数,用于指定读写文件的缓冲模式,值为0表达式不缓存;值为1表示缓存;如果大于1,则表示缓冲区的大小。默认为缓存模式。
使用open()方法可以实现以下几个功能:
1. 打开一个不存在的文件时先创建该文件
在默认的情况下,使用open() 函数打开一个不存在的文件,会抛出如下异常。
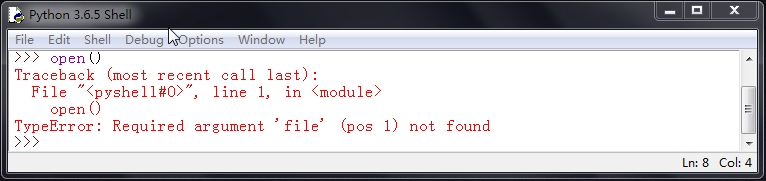
要解决上图错误,主要有以下两种方法:
- 在当前目录下(即与执行的文件相同的目录)创建一个名称为status.txt 的文件。
- 在调用open() 函数时,指定mode 的参数值为 w、w+、a、a+。这样,当打开的文件不存在时,就可以创建新的文件了。
实例01:创建并打开记录蚂蚁庄园动态的文件
首先输出一条提示信息,然后再调用open() 函数创建或打开文件,最后在输出一天提示信息,代码如下:
print("\n","="*10,"蚂蚁庄园动态","="*10) file = open('message.txt','w') # 创建或打开保存蚂蚁庄园动态信息的文件 print("\n 即将显示……\n")
2. 以二进制形式打开文件
使用open() 函数不仅可以以文本的形式打开文本文件,而且还可以以二进制形式打开非文本文件,如图片文件、音频文件、视频文件等。例如,创建一个名称为picture.png的图片文件,并且应用open() 函数以二进制方式打开文件。
以二进制方式打开该文件,不输出创建的对象的代码如下:
file = open('picture.png','rb') # 以二进制方式打开图片文件 print(file) # 输出创建的对象
3. 打开文件时指定编码方式
在使用open() 函数打开文件时,默认采用GBK编码,当被打开的文件不是GBK编码时,将抛出异常。
在调用open() 函数时,通过添加encoding='utf-8'参数即可实现将编码指定为UTF-8.如果想要指定其他编码,可以将单引号中的内容替换为想要指定的编码即可。
file = open('notice.txt','r',encoding='utf-8')
10.1.2 关闭文件
打开文件后,需要及时关闭,以免对文件造成不必要的破坏。关闭文件可以使用文件对象的close() 方式实现。close() 方法的语法格式如下:
file.close()
其中,file 为打开的文件对象。
例如,关闭实例01中打开的file 对象,可以使用下面的代码:
flie.close() # 关闭文件对象
说明:close() 方法先刷新缓冲区中还没有写入的信息,然后再关闭文件,这样可以将没有写入到文件的内容写入到文件中。在关闭文件后,便不能再进行写入操作了。
10.1.3 打开文件时使用with 语句
打开文件后,要及时将其关闭,如果忘记关闭可能会带来意想不到的问题。另外,如果在打开文件时抛出异常,那么将导致文件不能被及时关闭。为了更好地避免此类问题发生,可以使用Python 提供的with 语句,从而实现在处理文件时,无论是否抛出异常,都能保证with 语句执行完毕后关闭已经打开的文件。with 语句的基本语法格式如下:
with expression as target:
with-body
参数说明:
- expression:用于指定一个表达式,这里可以是打开文件的open() 函数。
- target:用于指定一个变量,并且将expression的结果保存到该变量中。
- with-body:用于指定with 语句体,其中可以是执行with 语句后相关的一些操作语句。如果不想执行任何语句,可以直接使用pass 语句代替。
例如,将实例01修改为在打开文件时使用with 语句,修改后的代码如下:
print("\n","="*10,"蚂蚁庄园动态","="*10) with open('message.txt','w') as file: # 创建或打开保存蚂蚁庄园动态信息的文件 pass print("\n 即将显示……\n")
10.1.4 写入文件内容
在实例01中,虽然创建并打开一个文件,但是该文件中并没有任何内容,它的大小是0KB。Python 的文件对象提供了write() 方法,可以向文件中写入内容。write() 方法的语法格式如下:
file.write(string)
其中,file 为打开的文件对象;string 为要写入的字符串。
注意:在调用write() 方法向文件中写入内容的前提是在打开文件时,指定的打开模式为w(可写)或者a(追加),否则,将抛出异常。
实例02:向蚂蚁庄园的动态文件写入一条信息
首先应用open() 函数以写方式打开一个文件,然后再调用write() 方法向该文件中写入一条动态信息,再调用close() 方法关闭文件,代码如下:
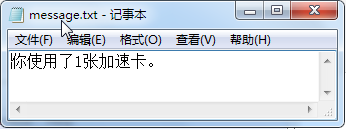
print("\n","="*10,"蚂蚁庄园动态","="*10) file = open('message.txt','w') # 创建或打开保存蚂蚁庄园动态信息的文件 # 写入一条动态信息 file.write("你使用了1张加速卡。\n") print("\n 写入了一条动态……\n") file.close() # 关闭文件对象
执行上面的代码:
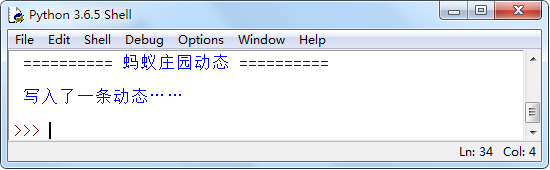
并创建了一个message.txt 的文件
注意:在写入文件后,一定要调用close() 方法关闭文件,否则写入的内容不会保存到文件中。这是因为当我们写入文件内容时,操作系统不会立刻把数据写入磁盘,而是先缓存起来,只有调用close() 方法时,操作系统才会保证把没有写入的数据全部写入磁盘。
多学两招:在向文件中写入内容后,如果不想马上关闭文件,也可以调用文件对象提供的flush() 方法,把缓冲区的内容写入文件,这样也能保证数据全部写入磁盘。
向文件中写入内容时,如果打开文件采用w(写入)模式,则先清空原文件中的内容,再写入新的内容;而如果打开文件采用a(追加)模式,则不覆盖原有文件的内容,只是在文件的结尾处增加新的内容。下面将对实例02的代码进行修改,实现在原动态信息的基础上再添加一条动态信息。修改后的代码如下:
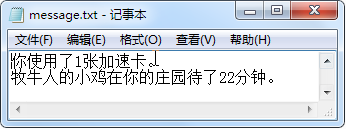
print("\n","="*10,"蚂蚁庄园动态","="*10) file = open('message.txt','a') # 创建或打开保存蚂蚁庄园动态信息的文件 # 追加一条动态信息 file.write("牧牛人的小鸡在你的庄园待了22分钟。\n") print("\n追加了一条动态……\n") file.close () # 关闭文件对象
执行上面代码后,打开message.txt 文件。
多学两招:在Python中的文件对象中除了提供了write() 方法,还提供了writelines() 方法,可以实现把字符串列表写入文件,但是不添加换行符。
10.1.5 读取文件
在Python中打开文件后,除了可以向其写入或追加内容,还可以读取文件中的内容。读取文件内容主要分为以下几种情况:
1. 读取指定字符
文件对象提供了read() 方法读取指定个数的字符,语法格式如下:
file.read([size])
参数说明:
- file:为打开的文件对象。
- size:可选参数,用于指定要读取的字符个数,如果省略,则一次性读取所有内容。
注意:在调用read() 方法读取文件内容的前提是在打开文件时,指定的打开模式为r(只读)或者r+(读写),否则抛出异常。
例如,要读取message.txt 文件中的前3个字符,可以使用下面的代码:
with open('message.txt','r') as file: # 打开文件 string = file.read(3) # 读取前3个字符 print(string)

使用read(size) 方法读取文件时,是从文件的开头读取的。如果想要读取部分内容,可以先使用文件对象的seek() 方法将文件的指针移动到新的位置,然后再应用read(size) 方法读取。seek() 方法的基本语法格式如下:
file.seek(offset[,whence])
参数说明:
- file:表示已经打开的文件对象。
- offset:用于指定移动的字符个数,其具体位置与whence 参数有关。
- whence:用于指定从什么位置开始计算。值为0 表示从文件开头计算,值为1表示从当前位置开始计算,值为2 表示从文件尾开始计算,默认为0。
注意:对于whence参数,如果在打开文件时,没有使用b 模式(即rb),那么只允许从文件头开始计算相对位置,从文件尾计算时就会抛出异常。
例如,想要从文件的第19个字符开始读取13个字符可以使用下面的代码:
with open('message.txt','r') as file: # 打开文件 file.seek(19) # 移动文件指针到新的位置 string = file.read(13) # 读取前13个字符 print(string)
如果采用GBK 编码的message.txt 文件内容为:
你使用了1张加速卡,小鸡撸起袖子开始双手吃饲料,进食速度大大加快。
那么执行上面的代码将显示以下结果:
小鸡撸起袖子开始双手吃饲料
说明:在使用seek() 方法时,如果采用GBK 编码,那么offset 的值是按一个汉字(包括中文标点符号)占两个字符计算,而采用UTF-8 编码,则一个汉字占3 个字符,不过无论采用何种编码英文和数字都是按一个字符计算的。这与read(size) 方法不同。
实例03:显示蚂蚁庄园的动态
print("\n","="*25,"蚂蚁庄园动态","="*25,"\n") with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件 message = file.read() # 读取全部动态信息 print(message) # 输出动态信息 print("\n","="*29,"over","="*29,"\n")
2. 读取一行
在使用read() 方法读取文件时,如果文件很大,一次读取全部内容到内存,容易造成内存不足,所以通常会采用逐行读取。文件对象提供了readline() 方法用于每次读取一行数据。readline() 方法的基本语法格式如下:
file.readline()
其中,file 为打开的文件对象。同read() 方法一样,打开文件时,也需要制定打开模式为r(只读)或者r+(读写)。
实例04:逐行显示蚂蚁庄园的动态
首先应用open()函数以只读方式打开一个文件,然后应用while语句创建循环,在该循环中调用readline()方法读取一条动态信息并输出,另外还需要判断内容是否已经读取完毕,如果读取完毕应用break语句跳出循环,代码如下:
print("\n","="*35,"蚂蚁庄园动态","="*35,"\n") with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件 number = 0 # 记录行号 while True : number += 1 line = file .readline() # 读取一行 if line =='': break # 跳出循环 print(number,line,end="\n") # 输出一行内容
print("\n","="*39,"over","="*39,"\n")
3. 读取全部行
读取全部行的作用同调用read() 方法时不指定size 类似,只不过读取全部行,返回的是一个字符串列表,每个元素为文件的一行内容。读取全部行,使用的是文件对象的readlines() 方法,其语法格式如下:
file.readlines()
其中,file为打开的文件对象。同read()方法一样,打开文件时,也需要指定打开模式为r(只读)或者r+(读写)。
例如,通过readlines()方法读取实例03中的message.txt文件,并输出读取结果,代码如下:
print("\n","="*25,"蚂蚁庄园动态","="*25,"\n") with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件 message = file.readlines() # 读取全部动态信息 print(message) # 输出动态信息 print("\n","="*29,"over","="*29,"\n")
从该运行结果中可以看出readlines()方法的返回值为一个字符串列表。在这个字符串列表中,每个元素记录一行内容。如果文件比较大时,采用这种方法输出读取的文件内容会很慢。这是可以将列表的内容逐行输出。例如,下面的代码可以修改为以下内容。
print("\n","="*25,"蚂蚁庄园动态","="*25,"\n") with open('message.txt','r') as file: # 打开保存蚂蚁庄园动态信息的文件 messageall = file.readlines() # 读取全部动态信息 for message in messageall: print(message) # 输出动态信息 print("\n","="*29,"over","="*29,"\n")
10.2 目录操作
目录也称文件夹,用于分层保存文件。通过目录可以分门别类地存放文件。我们也可以通过目录快速找到想要的文件。在Python中,并没有提供直接操作目录的函数或者对象,而是需要使用内置的os 和 os.path 模块实现。
说明:os 模块是Python内置的与操作系统功能和文件相关的模块。该模块中的语句的执行结果通常与操作系统有关,在不同操作系统上运行,可能回得到不一样的结果。
常用的目录操作主要有判断目录是否存在、创建目录、删除目录和遍历目录等,本节将详细介绍。
说明:本章的内容都是以Windows操作系统为例进行介绍的,所以代码的执行结果也都是在Windows操作系统下显示的。
10.2.1 os 和 os.path 模块
在Python 中,内置了os 模块及其子模块os.path 用于对目录或文件进行操作。在使用os 模块或者os.path 模块时,需要先应用import 语句将其导入,然后才可以应用它们提供的函数或者变量。
导入os 模块可以使用下面的代码:
import os
说明:导入os 模块后,也可以使用其子模块os.path。
导入os 模块后,可以使用该模块提供的通用变量获取与系统有关的信息。常用的变量有以下几个:
- name:用于获取操作系统类型。
例如,在Windows操作系统下输出os.name。
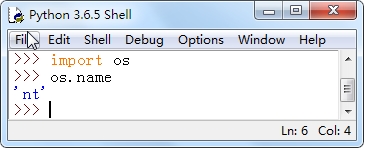
说明:如果os.name的输出结果为nt,则表示是Windows操作系统;如果是posix,则表示是Linux、Unix或Mac OS操作系统。
- linesep:用于获取当期操作系统上的换行符。
例如,在Windows操作系统下输出os.linesep。
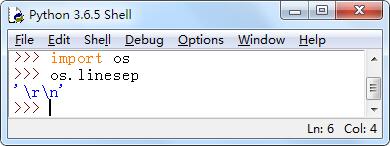
- sep:用于获取当前操作系统所使用的路径分隔符。
例如,在Windows操作系统下输出os.sep。

os 模块还提供了一些操作目录的函数。
| 函数 | 说明 |
| getcwd() | 返回当前的工作目录 |
| listdir(path) | 返回指定路径下的文件和目录信息 |
| mkdir(path[,mode]) | 创建目录 |
| makedirs(path1/paht2……[,mode]) | 创建多级目录 |
| rmdir(path) | 删除目录 |
| removedirs(path1/path2……) | 删除多级目录 |
| chdir(path) | 把path设置为当前工作目录 |
| walk(top[,topdown[,onerror]]) | 遍历目录树,该方法返回一个元组,包括所有路径名、所有目录列表和文件列表3 个元素 |
os.path 模块也提供了一些操作目录的函数。
| 函数 | 说明 |
| abspath(path) | 用于获取文件或目录的绝对路径 |
| exists(path) | 用于判断目录或者文件是否存在,如果存在则返回True,否则返回False |
| join(paht,name) | 将目录与目录或者文件名拼接起来 |
| splitext() | 分离文件名和扩展名 |
| basename(path) | 从一个目录中提取文件名 |
| dirname(path) | 从一个路径中提取文件路径,不包括文件名 |
| isdir(path) | 用于判断是否为有效路径 |
10.2.2 路径
用于定位一个文件或者目录的字符串被称为一个路径。在程序开发时,通常涉及两种路径,一种是相对路径,另一种是绝对路径。
1. 相对路径
在学习相对路径之前,需要先了解什么是当前工作目录。当前工作目录是指当前文件所在的目录。在Python中,可以通过os 模块提供的getcwd() 函数获取当前工作的目录。例如,在E:\program\Python\Code\demo.py 文件中,编写以下代码:
import os print(os.getcwd()) # 输出当前目录
执行上面的代码后
E:\program\Python\Code
相对路径就是依赖于当前工作目录的。如果在当前工作目录下,有一个名称为message.txt的文件,那么在打开这个文件时,就可以直接写上文件名,这是采用的就是相对路径,message.txt 文件的实际路径就是当前工作目录“E:\program\Python\Code”+相对路径“message.txt”,即“E:\program\Python\Code\message.txt”。
如果在当前工作目录下,有一个子目录demo,并且在孩子目录下保存着文件message.txt,那么在打开这个文件时就可以写上“demo/message.txt”,例如下面的代码:
with open("demo/message.txt") as file: # 通过相对路径打开文件 pass
说明:在Python中,指定文件路径时需要对路径分隔符“\”进行转义,即将路径中的“\”替换为“\\”,例如对于相对路径“demo\message.txt”需要使用““demo\\message.txt”代替。另外,也可以将路劲分隔符“\”采用“/”代替。
多学两招:在指定文件路径时,也可以在表示路径的字符串面前加上字母r(或R),那么该字符串将原样输出,这时路径中的分隔符就不需要再转义了。例如,上面的代码也可以修改为以下内容:
with open(r"demo/message.txt") as file: # 通过相对路径打开文件 pass
2. 绝对路径
绝对路径是指在使用文件时指定文件的实际路径。它不依赖于当前工作目录。在Python中,可以通过os.path模块提供的abspath()函数获取一个文件的绝对路径。abspath()函数的基本语法格式如下:
os.path.abspath(path)
其中,path为要获取绝对路径的相对路径,可以是文件也可以是目录。
例如,要获取相对路径”demo\message.txt”的绝对路径,可以使用下面的代码:
import os print(os.path.abspath(r"demo\message.txt")) # 获取绝对路径
如果当前工作目录为“E:\program\Python\Code\”,那么将得到以下结果:
E:\program\Python\Code\demo\message.txt
3. 拼接路径
如果想要将两个或者多个路径拼接到一起组成一个新的路径,可以使用os.path模块提供的join()函数实现。join()函数基本语法格式如下:
os.path.join(path1[,path2[,......]])
其中,path1、path2用于代表要拼接的文件路径,这些路径间使用逗号进行分隔。如果在要拼接的路径中,没有一个绝对路径,那么最后拼接出来的将是一个相对路径。
注意:使用os.path.join()函数拼接路径时,并不会检测该路径是否真实存在。
例如,需要将“E:\program\Python\Code\”和“demo\message.txt”路径拼接到一起,可以使用下面的代码。
import os print(os.path.join("E:\program\Python\Code\","demo\message.txt")) # 拼接字符串
执行上面的代码。
E:\program\Python\Code\demo\message.txt
说明:
在使用join()函数时,如果要拼接的路径中,存在多个绝对路径,那么以从左到右为序最后一次出现的路径为准,并且该路径之前的参数都将被忽略。例如,执行下面的代码:
import os print(os.path.join("E:\\code","E:\\python\\mr","Code","C:\\","demo")) # 拼接字符串
将得到拼接后的路径为“C:\demo”。
注意:把两个路径拼接为一个路径时,不要直接使用字符串拼接,而是使用os.path.join()函数,这样可以正确处理不同操作系统的路径分隔符。
10.2.3 判断目录是否存在
在Python中,有时需要判断给定的目录是否存在,这时可以使用os.path模块 提供的exists()函数实现。exists()函数的基本语法格式如下:
os.path.exists(path)
其中,path为要判断的目录,可以采用绝对路径,也可以采用相对路径。
返回值:如果给定的路径存在,则返回True,否则返回False。
例如,要判断绝对路径“C:\demo”是否存在,可以使用下面的代码:
import os print(os.path.exists("C:\\demo")) # 判断目录是否存在
执行上面的代码,如果在C盘根目录下没有demo子目录,则返回False,否则返回True。
……
10.2.4 创建目录
在Python中,os模块提供了两个创建目录的函数,一个用于创建一级目录,另一个用于创建多级目录。
1. 创建一级目录
创建一级目录是指一次只能创建一级目录。在Python中,可以使用os模块提供的mkdir()函数实现。通过函数只能创建指定路径中的最后一级目录,如果该目录的上一级不存在,则抛出FileNotFoundError异常。
os.mkdir(path,mode=0o777)
参数说明:
- path:用于指定要创建的目录,可以使用绝对路径,也可以使用相对路径。
- mode:用于指定数值模式,默认值为0777。该参数在非UNIX系统上无效或被忽略。
例如,在Windows系统上创建一个C:\demo目录,可以使用下面的代码:
import os os.mkdir("C:\\demo") # 创建C:\demo目录
执行代码后,将在C盘根目录下创建一个demo目录。
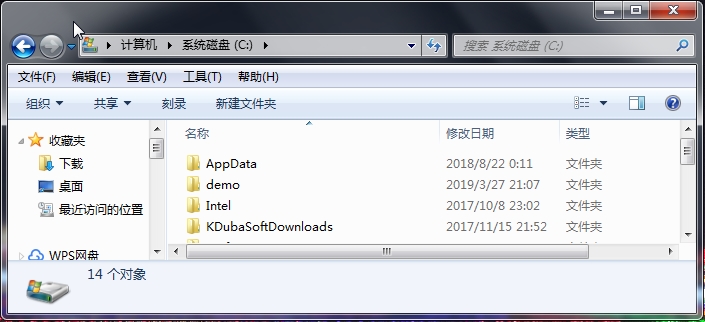
如果在创建路径时已经存在将抛出FileNotFoundError异常。
要解决上面的问题,可以在创建目录前,先判断指定的目录是否存在,只有当目录不存在时才创建。具体代码如下:
import os path = "C:\\demo" # 指定要创建的目录 if not os.path.exists(path): # 判断目录是否存在 os.mkdir(path) # 创建目录 print("目录创建成功!") else: print("该目录已经存在!")
执行上面的代码,将显示“该目录已经存在!”。
注意:如果指定的目录有多级,而且最后一级的上级目录中有不存在的,则抛出FileNotFoundError异常,并且目录创建不成功。要解决该问题有两种方法,一种是使用创建多级目录的方法(将在后面进行介绍)。另一种是编写递归函数调用os.mkdir()函数实现,具体代码如下:
import os # 导入标模块os def mkdir(path): # 定义递归创建目录的函数 if not os.path.isdir(path): # 判断是否为有效路径 mkdir(os.path.split(path)[0]) # 递归调用 else: # 如果目录存在,直接返回 return os.mkdir(path) # 创建目录 mkdir("D:/mr/test/demo") # 调用mkdir递归函数
2. 创建多级目录
使用mkdir()函数只能创建一级目录,如果想创建多级目录,可以使用os模块提供的makedirs()函数,该函数用于采用递归的方式创建目录。makedirs()函数的基本语法格式如下:
os.makedirs(name,mode=0o777)
参数说明:
- name:用于指定要创建的目录,可以使用绝对路径,也可以使用相对路径。
- mode:用于指定数值模式,默认值为0777。该参数在非UNIX系统上无效或被忽略。
例如,在Windows系统上,刚刚创建的C:\demo目录下,再创建子目录test\dir\mr(对应的目录为:C:\demo\test\dir\mr),可以使用下面的代码。
import os os.makedirs("C:\\demo\\test\\dir\\mr") # 创建C:\demo\test\dir\mr目录
……
10.2.5 删除目录
删除目录可以使用通过使用os模块提供的rmdir()函数实现。通过rmdir()函数删除目录时,只有当要删除的目录为空时才起作用。rmdir()函数的基本语法格式如下:
os.rmdir(path)
其中,path为要删除的目录,可以使用相对路径,也可以使用绝对路径。
例如,要删除刚刚创建的“C:\demo\test\dir\mr”目录,可以使用下面的代码:
import os os.rmdir("C:\\demo\\test\\dir\\mr") # 创建C:\demo\test\dir\mr目录
执行上面的代码后,将删除“C:\demo\test\dir”目录下的mr目录。
注意:如果要删除的目录不存在,那么将抛出“FileNotFoundError:[WinError2]系统找不到指定的文件”异常。因此,在执行os.rmdir()函数前,建议先判断该路径是否存在,可以使用os.path.exists()函数判断。具代码如下:
import os path = "C:\\demo\\test\\dir\\mr" # 指定要创建的目录 if os.path.exists(path): # 判断目录是否存在 os.rmdir("C:\\demo\\test\\dir\\mr") # 删除目录 print("目录删除成功!") else: print("该目录不存在!")
多学两招:使用rmdir()函数只能删除空的目录,如果想要删除非空目录,则需要使用Python内置的标准模块shutil 的rmtree() 函数实现。例如,要删除不为空的“C:\\demo\\test”目录,可以使用下面的代码:
import shutil shutil.rmtree("C:\\demo\\test") # 删除C:\demo目录下的test子目录及其内容
10.2.6 遍历目录
遍历在汉语中的意思是全部走遍,到处周游。在Python中,遍历是将指定的目录下的全部目录(包括子目录)及文件访问一遍。在Python中,os模块的walk()函数用于实现遍历目录的功能。walk()函数的基本语法格式如下:
os.walk(top[,topdown][,onerror][,followlinks])
参数说明:
- top:用于指定要遍历内容的根目录。
- topdown:可选参数,用于指定遍历的顺序,如果值为True,表示自上而下遍历(即先遍历根目录);如果值为False,表示自下而上遍历(即先遍历最后一级子目录)。默认值为True。
- onerror:可选参数,用于指定错误处理方式,默认为忽略,如果不想忽略也可以指定一个错误处理函数。通常情况下采用默认设置。
- followlinks:可选参数,默认情况下,walk()函数不会向下转换成解析到目录的符号链接,将该参数值设置为True,表示用于指定在支持的系统上访问由符号链接指向的目录。
- 返回值:返回一个包括3个元素(dirpath,dirnames,filenames)的元组生成器对象。其中,dirpath表示当前遍历的路径,是一个字符串;dirnames表示当前路径下包含的子目录,是一个列表;filenames表示当前路径下包含的文件,也是一个列表。
例如,要遍历指定目录“E:\program\Python\Code\01”,可以使用下面的代码:
import os # 导入os模块 tuples = os.walk("E:\program\Python\Code\01") # 遍历“E:\program\Python\Code\01”目录 for tuple1 in tuples: # 通过for循环输出遍历结果 print(tuple1,"\n") # 输出每一级目录的元组
……
注意:walk()函数只在Unix系统和Windows系统中有效。
实例05:遍历指定目录
……
10.3 高级文件操作
……

 浙公网安备 33010602011771号
浙公网安备 33010602011771号