
数据采集第四次作业
代码链接:第四次数据采集实践作业码云链接
作业①
1 作业要求
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
- 候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
- 输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
- Gitee文件夹链接

1.1 作业1 Gitee文件夹链接
1.2 代码思路和关键代码展示
1.2.1 创建数据库连接和创建数据库表
- 连接到MySQL数据库。
# 创建数据库连接
cnx = mysql.connector.connect(user='root', password='123456', host='127.0.0.1', database='scrapy')
cursor = cnx.cursor()
table_names = ["hs_a_board", "sh_a_board", "sz_a_board"]
- 定义了一个SQL模板,用于创建存储股票信息的表结构。
#创建表
table_structure = """
CREATE TABLE IF NOT EXISTS `{table_name}` (
`stock_code` varchar(10) NOT NULL,
`stock_name` varchar(50) NOT NULL,
`latest_price` varchar(10) NOT NULL,
`price_change_percent` varchar(10) NOT NULL,
`price_change` varchar(10) NOT NULL,
`transaction_volume` varchar(20) NOT NULL,
`transaction_amount` varchar(20) NOT NULL,
`amplitude` varchar(10) NOT NULL,
`highest_price` varchar(10) NOT NULL,
`lowest_price` varchar(10) NOT NULL,
`opening_price` varchar(10) NOT NULL,
`previous_close` varchar(10) NOT NULL,
PRIMARY KEY (`stock_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
"""
- 遍历table_names列表中的表名(为三种不同类别的股票建立数据库),为每个表名创建对应的表。
# 为每个表名创建表
for table_name in table_names:
create_table_sql = table_structure.format(table_name=table_name)
try:
cursor.execute(create_table_sql)
cnx.commit()
print(f"表 {table_name} 创建成功。")
except mysql.connector.Error as err:
print(f"创建表 {table_name} 失败:{err}")
1.2.2 定义爬取信息的函数fetch_page()
- 这个函数负责爬取页面上的股票信息,并将其插入到数据库中。
- 使用implicitly_wait设置隐式等待时间。
- 使用find_elements和find_element方法定位页面元素,并提取股票信息。
table = driver.find_elements(By.XPATH,'//table[@id="table_wrapper-table"]/tbody/tr')
print("————————————正在爬取新的一页————————————")
for tr in table:
stock_code = tr.find_element(By.XPATH,'./td[position()=2]/a').text
stock_name = tr.find_element(By.XPATH,'./td[position()=3]/a').text
latest_price = tr.find_element(By.XPATH,'./td[position()=5]/span').text
price_change_percent = tr.find_element(By.XPATH,'./td[position()=6]/span').text
price_change = tr.find_element(By.XPATH,'./td[position()=7]/span').text
transaction_volume = tr.find_element(By.XPATH,'./td[position()=8]').text
transaction_amount = tr.find_element(By.XPATH,'./td[position()=9]').text
amplitude = tr.find_element(By.XPATH,'./td[position()=10]').text
highest_price = tr.find_element(By.XPATH,'./td[position()=11]/span').text
lowest_price = tr.find_element(By.XPATH,'./td[position()=12]/span').text
opening_price = tr.find_element(By.XPATH,'./td[position()=13]/span').text
previous_close = tr.find_element(By.XPATH,'./td[position()=14]').text
- 将提取的信息插入到数据库中,并提交事务。
# 插入数据到 MySQL
query = f"INSERT INTO {key} (stock_code, stock_name, latest_price, price_change_percent, price_change, transaction_volume, transaction_amount, amplitude, highest_price, lowest_price, opening_price, previous_close) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
data = (stock_code, stock_name, latest_price, price_change_percent, price_change,
transaction_volume, transaction_amount, amplitude, highest_price, lowest_price,
opening_price, previous_close)
cursor.execute(query, data)
cnx.commit()
#打印信息
print(stock_code,stock_name,latest_price,price_change_percent,price_change,transaction_volume,transaction_amount,amplitude,highest_price,lowest_price
,opening_price,previous_close)
1.2.3 定义翻页逻辑:
- 在fetch_page()函数中,通过点击下一页按钮来翻页,并重新调用fetch_page()函数爬取新页面的数据。
# 翻页逻辑
for i in range(page_num - 1): # 假设我们要翻页的次数
try:
next_page_button =driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]')
next_page_button.click()
driver.implicitly_wait(5)
# simulate_scroll() # 模拟鼠标慢慢滚动以加载图片
time.sleep(random.randint(3, 5))
fetch_page(key,1) # 重新爬取当前页面的商品信息
except TimeoutException:
print("下一页按钮预期时间内未出现")
break
1.2.4 定义分类爬取函数fetch_cate():
- 这个函数负责点击分类按钮,并开始爬取该分类下的股票信息。
def fetch_cate(key,value):
driver.execute_script("window.scrollTo(0, 0);")
print("="*10 + f"正在爬取{key}" + "="*10)
driver.implicitly_wait(3)
time.sleep(random.randint(3, 5))
cate_button = driver.find_element(By.XPATH, value)
cate_button.click()
driver.implicitly_wait(2)
fetch_page(key,5)
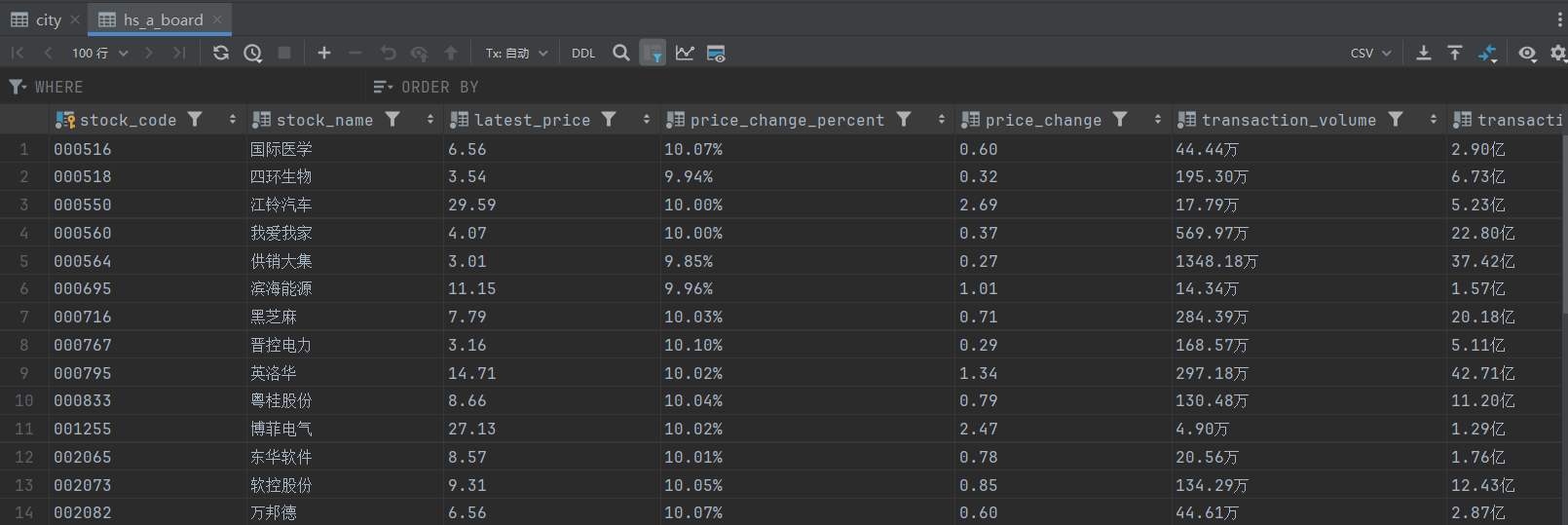
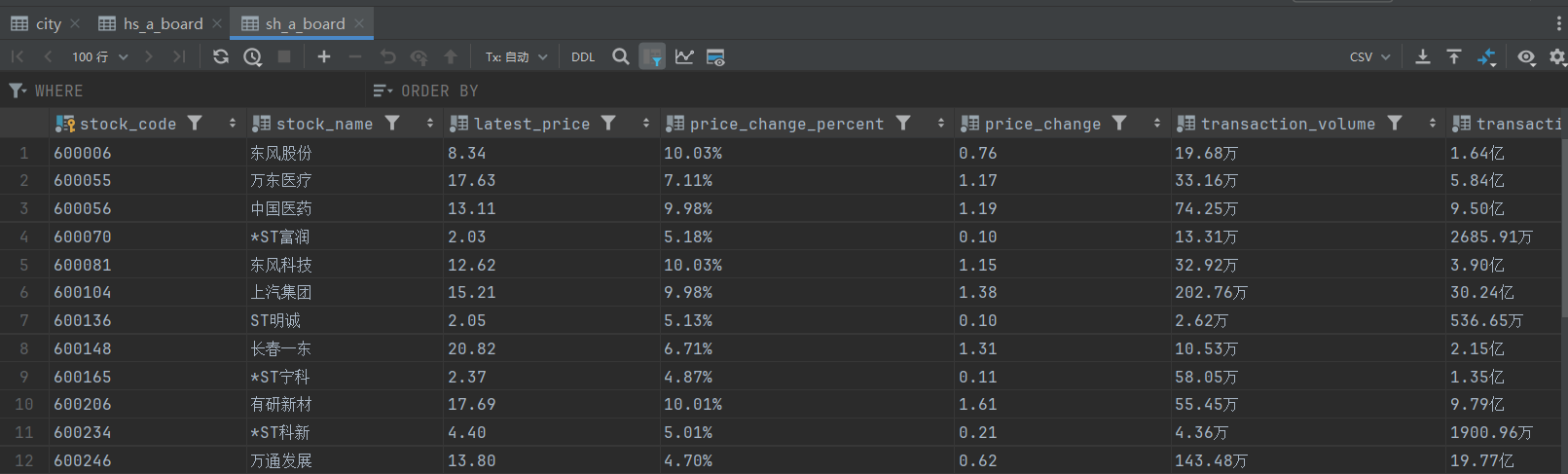
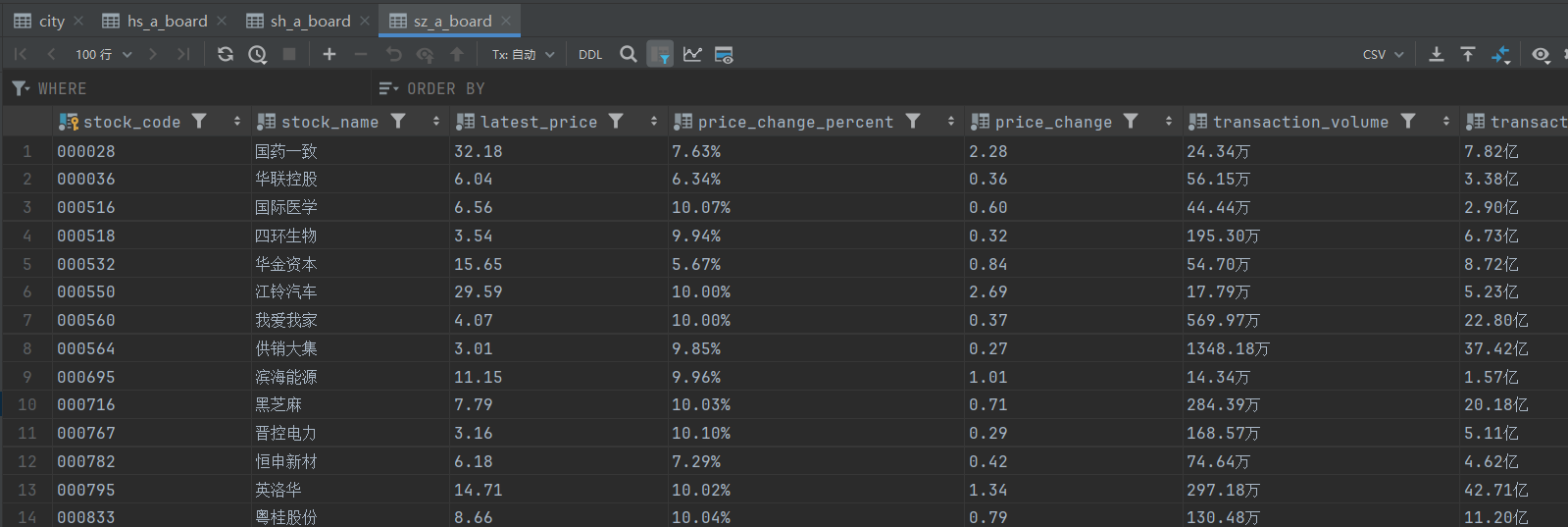
1.3 结果展示
- 控制台输出:



- 持久化存储:
1.5 总结体会
-
网页等待:由于网速的限制,需要灵活处理等待的时间,避免元素还未加载。
-
元素查找:由于爬取的数据较多,通过xpath爬取编写代码还是比较麻烦的,不过由于数据的爬取结构差不多,通过position的变换进行查找即可。
-
翻页处理:通过定位翻页的按钮,进行自动化的翻页处理,大大提高代码的爬取效率。
-
不同类别的爬取:在爬取完一个类别后,通过查找元素爬取不同的类别时,发现会有报错提示无法找到类别的路径,发现是由于翻页处理时,页面到了底部,元素可能没有加载,因此在更换类别时,保证每次页面都在顶部即可。
作业②
2 作业要求
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
- 候选网站:中国mooc网:https://www.icourse163.org
- 输出信息:MYSQL数据库存储和输出格式
- Gitee文件夹链接
2.1 作业2 Gitee文件夹链接
2.2 代码思路和关键代码展示
2.2.1 创建数据库连接和数据表:
- 连接到MySQL数据库,并创建一个游标对象用于执行SQL语句。
- 创建数据库表:
- 执行SQL语句创建一个名为mooc的表,用于存储课程信息
# 创建数据库连接
cnx = mysql.connector.connect(user='root', password='123456', host='127.0.0.1', database='scrapy')
cursor = cnx.cursor()
# # 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS mooc (
`cCourse` varchar(255) DEFAULT NULL,
`cCollege` varchar(255) DEFAULT NULL,
`cTeacher` varchar(255) DEFAULT NULL,
`cCount` varchar(255) DEFAULT NULL,
`cProcess` varchar(255) DEFAULT NULL,
`cBrief` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
''')
cnx.commit()
2.2.2 定义登录函数login():
- 通过Selenium操作模拟用户登录中国大学MOOC平台。
def login():
try:
login_button = driver.find_element(By.XPATH, '//*[@id="j-topnav"]/div')
login_button.click()
time.sleep(3)
iframe = driver.find_element(By.XPATH,'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
account=driver.find_element(By.XPATH,'//*[@id="phoneipt"]')
password=driver.find_element(By.XPATH,'//*[@id="login-form"]/div/div[4]/div[2]/input[2]')
account.send_keys("")
password.send_keys("")
password.send_keys(Keys.RETURN)
time.sleep(1)
WebDriverWait(driver, 60).until(EC.url_changes(driver.current_url))
driver.switch_to.default_content() # 切回主内容
time.sleep(2)
except Exception as e:
print("登录失败:", e)
2.2.3 定义搜索函数search()
- 输入课程关键词并执行搜索
def search(course):
try:
time.sleep(10)
# 等待搜索框可点击
input = WebDriverWait(driver, 10, 0.5).until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[1]/div/div[1]/div[1]/span/input'))
)
except TimeoutException:
print("输入框预期时间内出现")
# 输入信息
input.send_keys(course)
# 输入商品后,使用Enter键登录
input.send_keys(Keys.RETURN)
time.sleep(5) #等待5秒
2.2.4 定义模拟滚动函数simulate_scroll()
- 模拟用户滚动页面以加载更多的课程信息。
#模拟鼠标慢慢滚动以加载商品图片
def simulate_scroll():
# 获取页面高度
page_height = driver.execute_script("return document.body.scrollHeight")
# 定义滚动步长和间隔时间
scroll_step = 5 # 每次滚动的距离
scroll_delay = 5 # 每次滚动的间隔时间(秒)
# 模拟慢慢滚动
current_position = 0
while current_position < page_height:
# 计算下一个滚动位置
next_position = current_position + scroll_step
# 执行滚动动作
driver.execute_script(f"window.scrollTo(0, {next_position});")
# 等待一段时间
driver.implicitly_wait(scroll_delay)
# 更新当前滚动位置
current_position = next_position
2.2.5 定义爬取信息函数fetch()
- 爬取课程信息,包括课程名称、学校名称、主讲教师、参加人数、课程进度和课程简介。
- 将爬取的信息插入到MySQL数据库中。
#爬取信息
def fetch(page_num):
driver.implicitly_wait(5)
simulate_scroll() # 模拟鼠标慢慢滚动以加载图片
time.sleep(random.randint(3, 5))
courses = driver.find_elements(By.XPATH,'/html/body/div[4]/div[2]/div[2]/div[2]/div/div[6]/div[2]/div[1]/div/div/div')
print(len(courses))
for cor in courses:
# 使用 find_elements 来获取元素列表
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[1]/a[1]/span')
cCourse = elements[0].text if elements else None # 课程名称
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[2]/a[1]')
cCollege = elements[0].text if elements else None # 学校名称
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[2]/a[2]')
cTeacher = elements[0].text if elements else None # 主讲教师
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[3]/span[2]')
cCount = elements[0].text if elements else None # 参加人数
elements = cor.find_elements(By.XPATH, './div[2]/div/div/div[3]/div/span[2]')
cProcess = elements[0].text if elements else None # 课程进度
elements = cor.find_elements(By.XPATH, './div[2]/div/div/a/span')
cBrief = elements[0].text if elements else None # 课程简介
print(cCourse, cCollege, cTeacher, cCount, cProcess, cBrief)
cursor.execute(
'INSERT INTO mooc (cCourse, cCollege, cTeacher, cCount, cProcess, cBrief) VALUES (%s, %s, %s, %s, %s, %s)',
(cCourse, cCollege, cTeacher, cCount, cProcess, cBrief)
)
cnx.commit()
2.2.6 定义翻页逻辑
- 在fetch函数中,通过点击下一页按钮来翻页,并重新调用fetch函数爬取新页面的课程信息。
# 翻页逻辑
for i in range(page_num - 1): # 假设我们要翻页的次数
try:
next_page_button =driver.find_element(By.XPATH, '//*[@id="j-courseCardListBox"]/div[2]/ul/li[10]/a')
next_page_button.click()
driver.implicitly_wait(5)
# simulate_scroll() # 模拟鼠标慢慢滚动以加载图片
time.sleep(random.randint(3, 5))
fetch(1) # 重新爬取当前页面的商品信息
except TimeoutException:
print("下一页按钮预期时间内未出现")
break
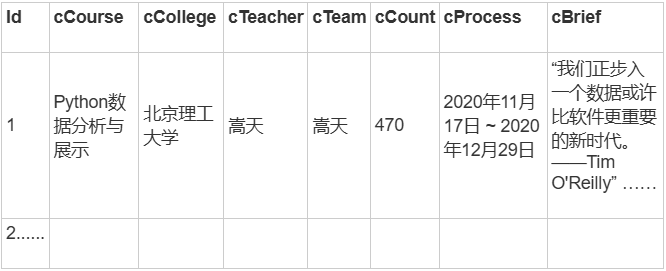
2.3 结果展示
- 控制台输出:


- 持久化存储:
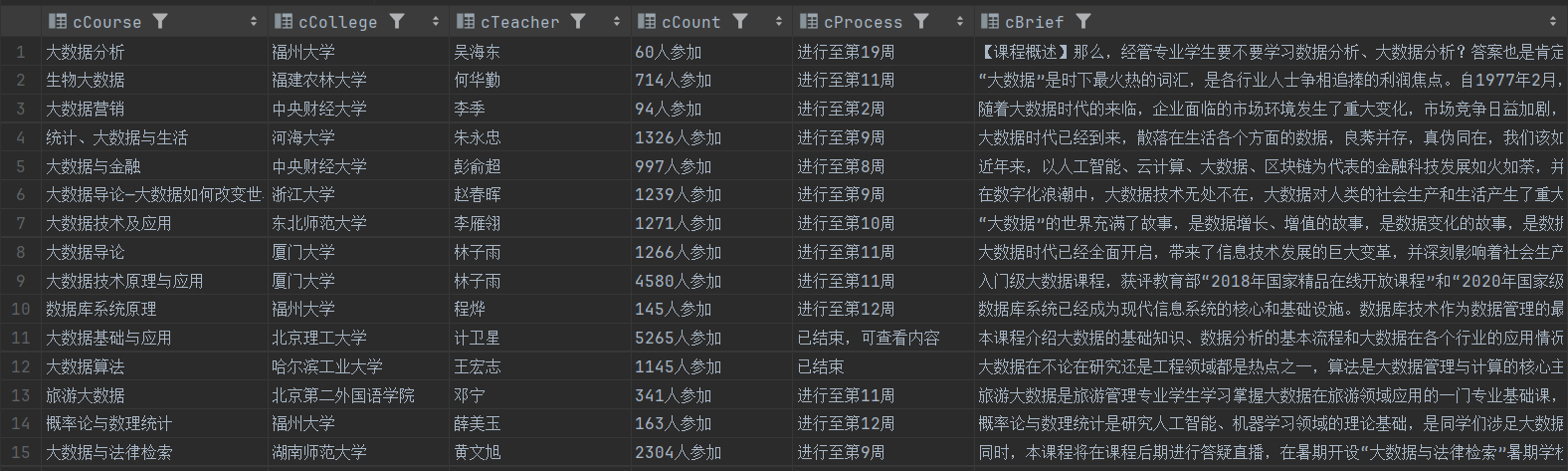
2.4 总结体会
-
总的来说,这道题和上一道题相差不大,唯一区别是,该道题需要处理用户的登录问题(虽然不登录也可以爬取),还有就是在爬取课程信息时,并不一定每个课程的信息都是完整的,因此在爬取时需要考虑是否存在该页面元素。
-
处理用户登录:先通过selenium点击登录按钮,进入登入界面,然后这里的登录页面需要先切换到一个iframe窗口中,才可以进行账号和密码的输入,同时还需要使用FULL xpath对iframe对窗口进行定位,不然有可能会报错,可能是由于一开始是使用id进行定位的,而网页的id信息时变换的。最后登录后,需要切换到主页面中。
-
元素查找:首先在定位课程时,也是需要通过fullXpath进行定位,因为id是变换的,最后在爬取课程的各项内容时,在爬取第三页时,会报错无法定位到元素,原因是不是所有的课程信息都是完整的,因此需要增加一个,元素为空的处理,如过找到的元素为空,这让该项内容为Null即可。
-
页面滚动:在爬取页面时,我在这里加载了一个页面滚动的函数,用于保证页面的元素加载完整,不过此次爬取不滚动也可以正常加载。
作业③
3 作业要求
- 掌握大数据相关服务,熟悉Xshell的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
- 任务一:开通MapReduce服务
实时分析开发实战:
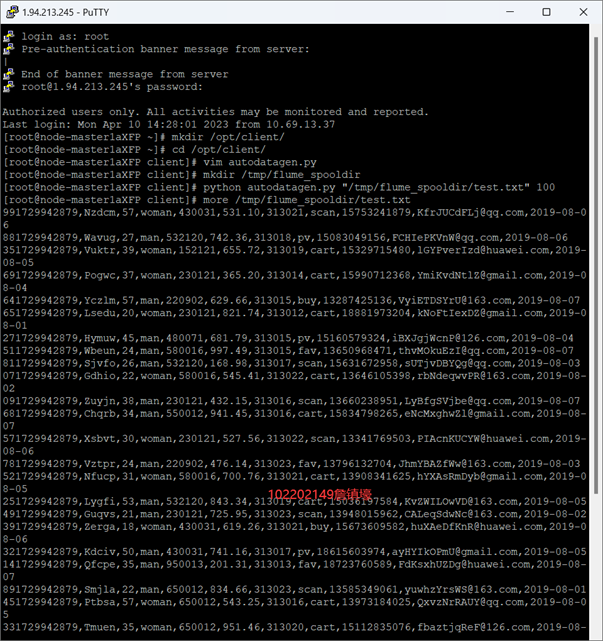
- 任务一:Python脚本生成测试数据
- 任务二:配置Kafka
- 任务三: 安装Flume客户端
- 任务四:配置Flume采集数据
输出:实验关键步骤或结果截图。
3.1 实验关键步骤和结果截图
3.1.1 环境搭建——开通MapReduce服务
- 申请弹性公网IP
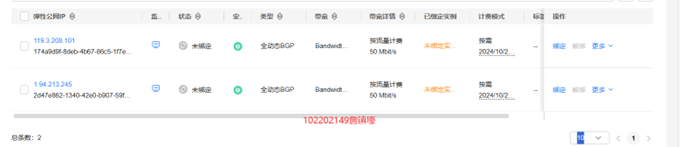
- 开通MapReduce服务


3.1.2 Python脚本生成测试数据

3.1.3 下载安装并配置Kafka

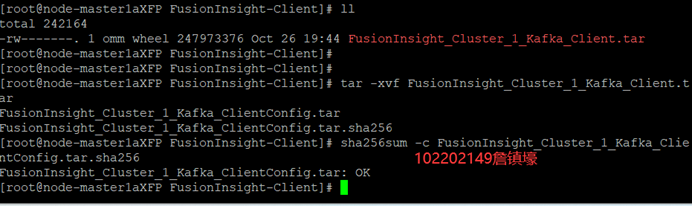

3.1.4 安装Flume客户端


- 安装Flume运行环境
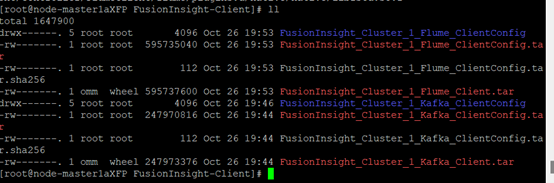
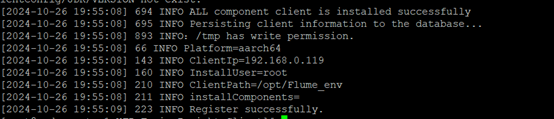
- 安装Flume客户端
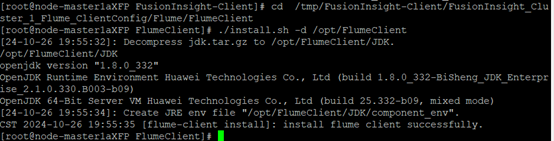
- 重启Flume服务
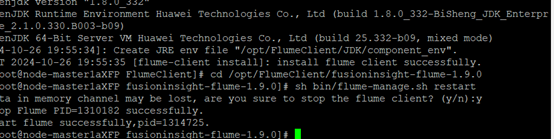
3.1.5 配置Flume日志采集

3.2 总结体会
- 配置Flume采集数据是整个实验中最具挑战性的部分。在这个过程,我学会了如何根据数据源和目标系统的需求来配置Flume。这不仅提高了我对Flume配置文件的理解,也让我对数据流的采集、处理和传输有了更深入的认识。
- 通过完成这些任务,我对大数据实时分析处理有了更全面的认识。从环境搭建到数据生成,再到数据的采集和传输,每一步都是大数据项目成功的关键。这些任务不仅提高了我的技术能力,也加深了我对大数据生态系统中各个组件如何协同工作的理解。通过实践,我更加确信大数据技术在现代数据处理中的重要性和潜力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号