数据采集第三次作业
代码链接:第三次数据采集实践作业码云链接
1 作业1
1.1 作业要求
-
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
-
务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
-
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
-
本次作业爬取了4399游戏中的图片(https://www.4399.com/flash/)
1.2 作业1 Gitee文件夹链接
1.3 代码思路和关键代码展示
1.3.1 items.py程序
- 定义Item
class Work1Item(scrapy.Item):
image_urls = scrapy.Field()
image_index = scrapy.Field()
1.3.2 game.py程序
-
限制域
-
很重要!!!由于图片的url和要爬取的页面的url的域并不一样,所以要把图片的域也加上去,否则在爬取时就会报错,血的教训!!!
allowed_domains = ["4399.com","5054399.com"]
- 限制爬取数目,爬取149张(学号后三位)
def __init__(self):
self.image_count = 0 # 初始化已爬取Item计数器
MAX_IMAGES = 149
- 爬取页面中的url
def parse(self, response):
# 提取图片链接
# 使用正则表达式匹配所有以.jpg或.png结尾的图片链接
img_pattern = re.compile(r'src="([^"]+\.(jpg))"')
image_urls = img_pattern.findall(response.text)
for url in image_urls:
if self.image_count < self.MAX_IMAGES:
url = 'https:'+str(url[0])
self.image_count += 1
print(self.image_count,url)
item = Work1Item()
item['image_urls'] = url
item['image_index'] = self.image_count
yield item
- 翻页处理,当达到限制数目或没有下一页时停止翻页
#获取下一页的链接
next_page = response.xpath('//div[@class="pag"]/a[contains(text(), "下一页")]/@href').extract_first()
if next_page is not None and self.image_count < self.MAX_IMAGES:
next_page="https://www.4399.com"+str(next_page)
yield response.follow(next_page, callback=self.parse)
1.3.3 pipelines.py程序
- 将图片下载至根目录的文件夹images中
def item_completed(self, results, item, info):
# 检查图像是否成功下载
if not results:
raise DropItem("Image download failed for {}".format(item['image_urls']))
# 确定保存路径
image_path = 'images' # 本地目录
if not os.path.exists(image_path):
os.makedirs(image_path)
# 将下载的图片保存到指定路径
image_url = item['image_urls']
image_name = image_url.split("/")[-1] # 获取文件名
image_save_path = os.path.join(image_path, image_name)
# 将图片写入本地文件
with open(image_save_path, 'wb') as f:
response = requests.get(image_url)
f.write(response.content)
return item
1.3.4 settings.py设置
-
设置多线程爬取
-
设置图片存储目录
-
开启管道
LOG_LEVEL = "WARNING"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
# 设置图片存储目录
IMAGES_STORY = './images'
DOWNLOAD_DELAY = 3
ITEM_PIPELINES = {
"work_1.pipelines.Work1Pipeline": 1,
}
1.4 结果展示
- 控制台输出:
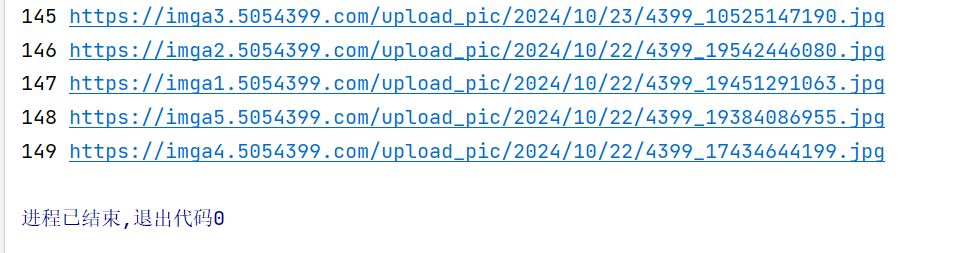
- 持久化存储:
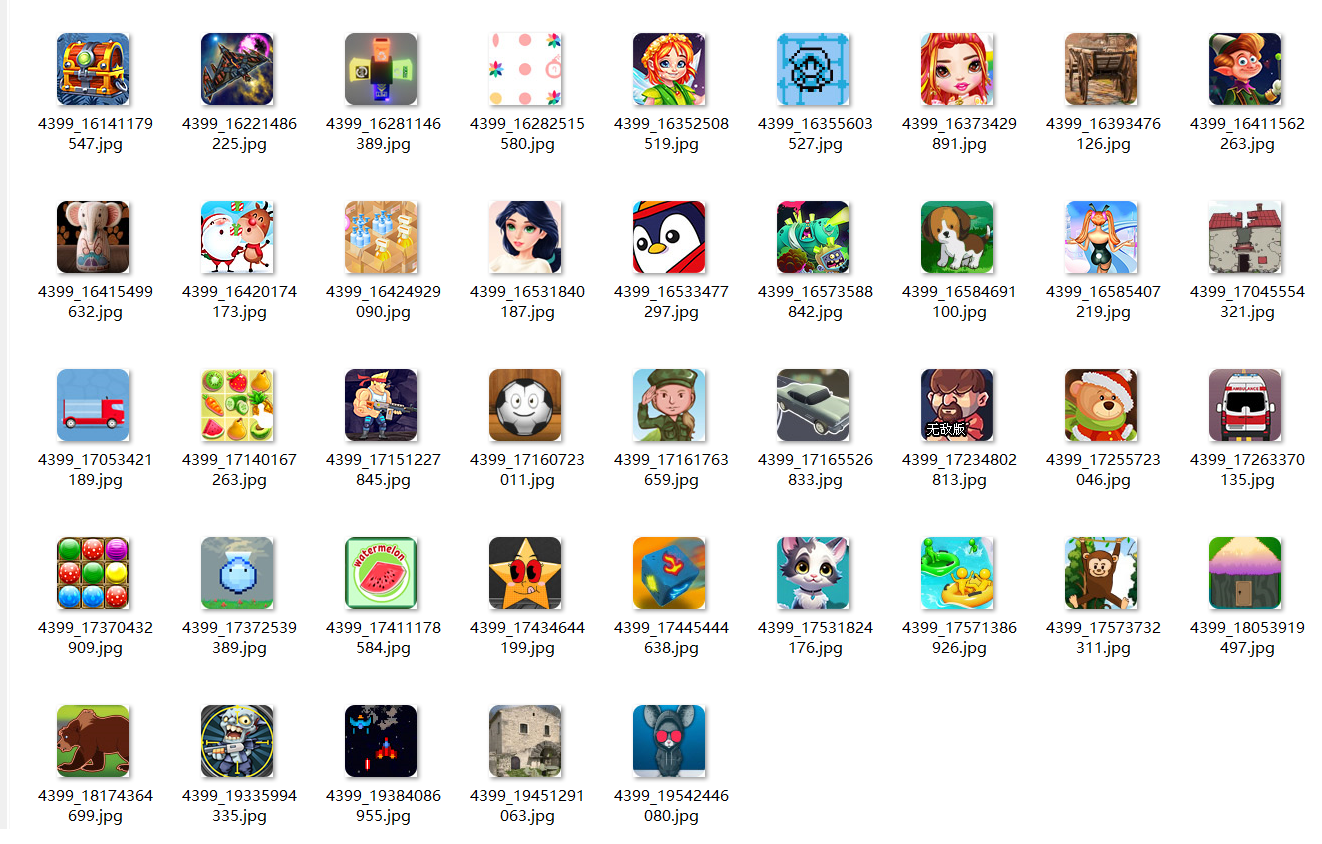
1.5 总结体会
-
爬取图片最麻烦的地方就是需要注意爬取图片时图片url的域,在爬取时要注意在限制域里进行添加,有多个不同的域就都要添加
-
翻页处理时,会发现直接使用xpth爬取下来的并不一定是直接下一页的url,需要进行一定的处理
2 作业2
2.1 作业要求
-
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
-
候选网站:东方财富网(https://www.eastmoney.com/)

- 输出信息:Gitee文件夹链接
2.2 作业2 Gitee文件夹链接
2.3 代码思路和关键代码展示
2.3.1 items.py程序
- 定义item
class Work2Item(scrapy.Item):
stock_code = scrapy.Field() # 股票代码
stock_name = scrapy.Field() # 股票名称
latest_price = scrapy.Field() # 最新价
price_change_percent = scrapy.Field() # 涨跌幅
price_change = scrapy.Field() # 涨跌额
transaction_volume = scrapy.Field() # 成交量
transaction_amount = scrapy.Field() # 成交额
amplitude = scrapy.Field() # 振幅
highest_price = scrapy.Field() # 最高
lowest_price = scrapy.Field() # 最低
opening_price = scrapy.Field() # 今开
previous_close = scrapy.Field() # 昨收
2.3.2 middlewares.py程序
- 使用selenium来处理数据
def __init__(self, driver_name='chrome', driver_executable_path=None, driver_arguments=None):
self.driver = None
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
if driver_arguments:
for argument in driver_arguments:
self.chrome_options.add_argument(argument)
service = Service(executable_path=driver_executable_path)
self.driver = webdriver.Chrome(service=service, options=self.chrome_options)
2.3.3 eastmoney.py程序
- 设置 ChromeOptions
def __init__(self):
# 设置 ChromeOptions
options = Options()
options.add_argument('--headless') # 无头模式
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# 初始化 WebDriver
self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
self.page = 0 # 设置页面数
- 获取页面信息
# 使用 Selenium 获取页面
self.driver.get(response.url)
time.sleep(3) # 等待页面加载
# 获取页面内容
sel = Selector(text=self.driver.page_source)
table = sel.xpath('//table[@id="table_wrapper-table"]/tbody/tr')
for tr in table:
stock_code = tr.xpath('./td[position()=2]/a/text()').extract_first()
stock_name = tr.xpath('./td[position()=3]/a/text()').extract_first()
latest_price = tr.xpath('./td[position()=5]/span/text()').extract_first()
price_change_percent = tr.xpath('./td[position()=6]/span/text()').extract_first()
price_change = tr.xpath('./td[position()=7]/span/text()').extract_first()
transaction_volume = tr.xpath('./td[position()=8]/text()').extract_first()
transaction_amount = tr.xpath('./td[position()=9]/text()').extract_first()
amplitude = tr.xpath('./td[position()=10]/text()').extract_first()
highest_price = tr.xpath('./td[position()=11]/span/text()').extract_first()
lowest_price = tr.xpath('./td[position()=12]/span/text()').extract_first()
opening_price = tr.xpath('./td[position()=13]/span/text()').extract_first()
previous_close = tr.xpath('./td[position()=14]/text()').extract_first()
- 翻页处理
try:
next_button = self.driver.find_element("xpath", '//*[@id="main-table_paginate"]/a[2]')
if "disabled" not in next_button.get_attribute("class"):
next_button.click() # 点击下一页
# 使用 WebDriverWait 等待下一页加载
WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located(("xpath", '//table[@id="table_wrapper-table"]/tbody/tr'))
)
yield scrapy.Request(self.driver.current_url, callback=self.parse)
else:
break # 如果“下一页”按钮不可用,停止翻页
except Exception as e:
break # 如果发生异常,停止翻页
2.3.4 pipelines.py程序
- 链接mysql,并插入到数据库中
def process_item(self, item, spider):
"""处理爬取到的项并插入数据库"""
sql = """
INSERT INTO stocks (stock_code, stock_name, latest_price, price_change_percent, price_change,
transaction_volume, transaction_amount, amplitude, highest_price,
lowest_price, opening_price, previous_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
values = (
item['stock_code'],
item['stock_name'],
item['latest_price'],
item['price_change_percent'],
item['price_change'],
item['transaction_volume'],
item['transaction_amount'],
item['amplitude'],
item['highest_price'],
item['lowest_price'],
item['opening_price'],
item['previous_close']
)
self.cursor.execute(sql, values)
self.connection.commit() # 提交事务
return item
2.4 结果展示
- 控制台输出:

- 持久化存储:
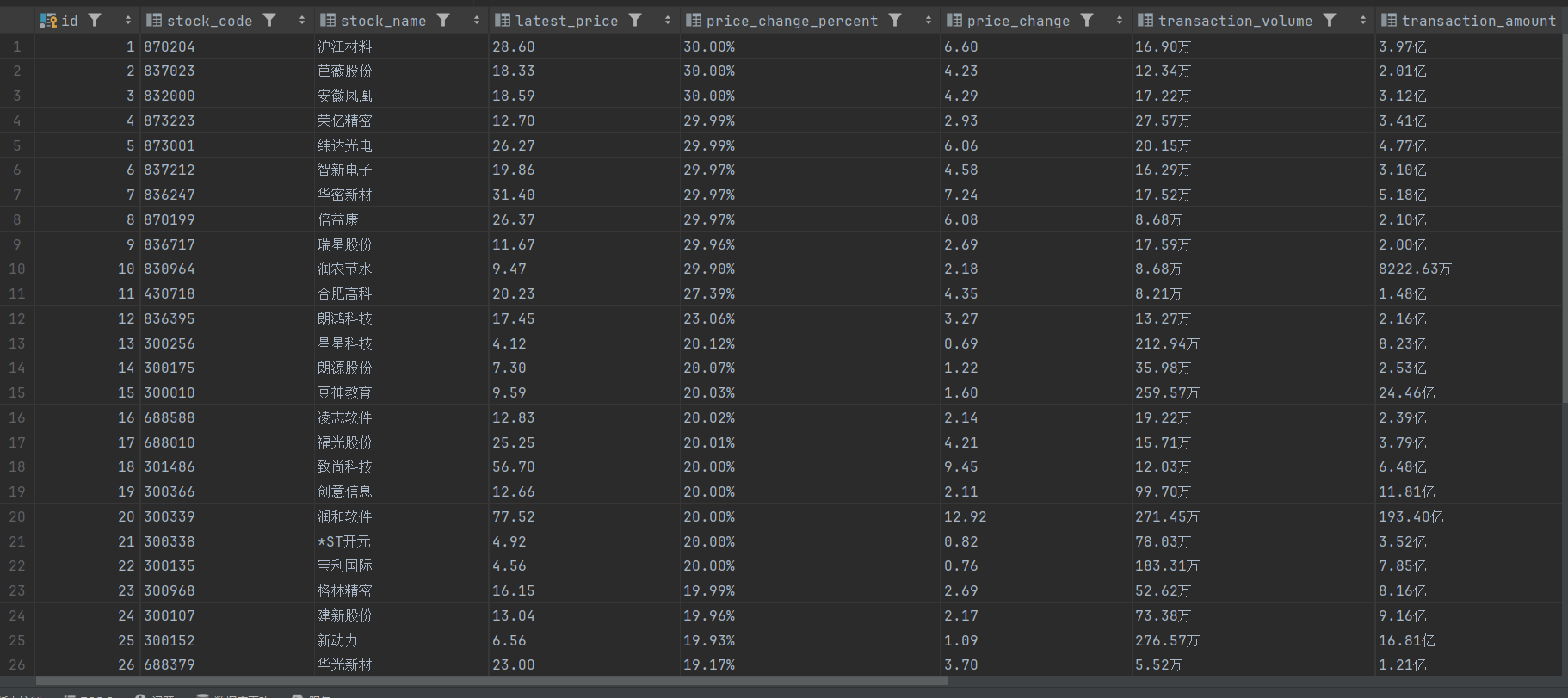
2.5 总结体会
-
使用selenium和scrapy框架进行爬取,可以处理一些动态数据。
-
由于该网站在翻页处理时,本身的url并没有发生变化,原来处理翻页的方法不在奏效,但使用selenium的鼠标点击可以处理该类情况。
-
pipelines1爬取后的数据与数据库进行连接并存储,方便数据的保存和可视化。
3 作业3
3.1、作业要求
-
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
-
输出信息:Gitee文件夹链接
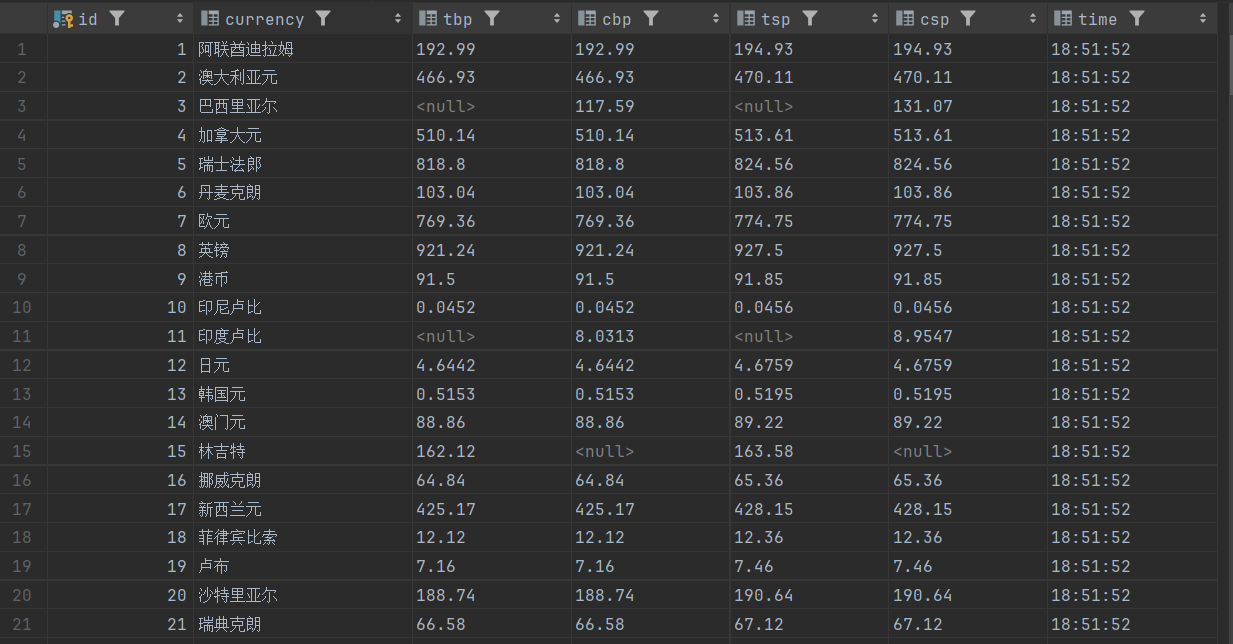
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 阿联酋迪拉姆 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
3.2 作业3 Gitee文件夹链接
3.3 代码思路和关键代码展示
3.3.1 items.py程序
- 定义item
class Work3Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
3.3.2 middlewares.py程序
- 使用selenium处理数据
def __init__(self, driver_name='chrome', driver_executable_path=None, driver_arguments=None):
self.driver = None
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
if driver_arguments:
for argument in driver_arguments:
self.chrome_options.add_argument(argument)
service = Service(executable_path=driver_executable_path)
self.driver = webdriver.Chrome(service=service, options=self.chrome_options)
3.3.3 boc.py程序
- 数据处理
def parse(self, response):
table = response.xpath('//div/table/tbody/tr')
for tr in table[2:-1]:
Currency = tr.xpath('./td[position()=1]/text()').extract_first()
TBP = tr.xpath('./td[position()=2]/text()').extract_first()
CBP = tr.xpath('./td[position()=3]/text()').extract_first()
TSP = tr.xpath('./td[position()=4]/text()').extract_first()
CSP = tr.xpath('./td[position()=5]/text()').extract_first()
Time = tr.xpath('./td[position()=8]/text()').extract_first()
print(Currency,TBP,CBP,TSP,CSP,Time)
- 翻页处理
# 翻页处理
next_page = response.xpath('//div[@class="turn_page"]/ol/li[@class="turn_next"]/a/@href').extract_first()
next_page = "https://www.boc.cn/sourcedb/whpj/" + str(next_page)
print(next_page)
self.page +=1
if next_page is not None and self.page < 11: # 直到页面没有或超过10页
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
else:
self.logger.info(f'Reached maximum page limit: {self.page}')
3.3.4 pipelines.py程序
- 将数据存储到mysql中
def process_item(self, item, spider):
sql = """
INSERT INTO work3_data (currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
try:
self.cursor.execute(sql, (
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
))
self.connection.commit()
except mysql.connector.Error as e:
self.connection.rollback()
raise DropItem(f"Error processing item {item!r} - {e}")
return item
3.5 结果展示
- 控制台输出
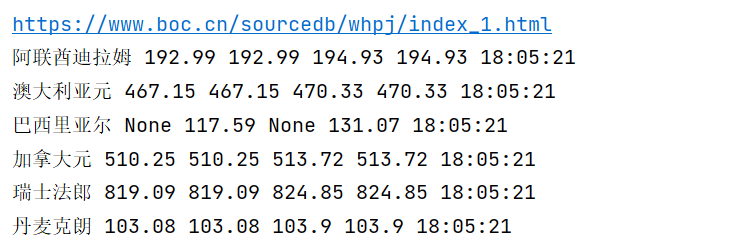
- 持久化存储
3.6 总结体会
- 与作业2相差不大,在翻页处理上比作业二更加简单

 浙公网安备 33010602011771号
浙公网安备 33010602011771号